

1. 概述编辑
1.1 版本说明
| FineBI 版本 | 功能变更 |
|---|---|
| 6.0 | - |
1.2 应用场景
当用户需要将数据从一个数据库抽取到另一个数据库时,就可以使用「数据同步」节点。如下图所示: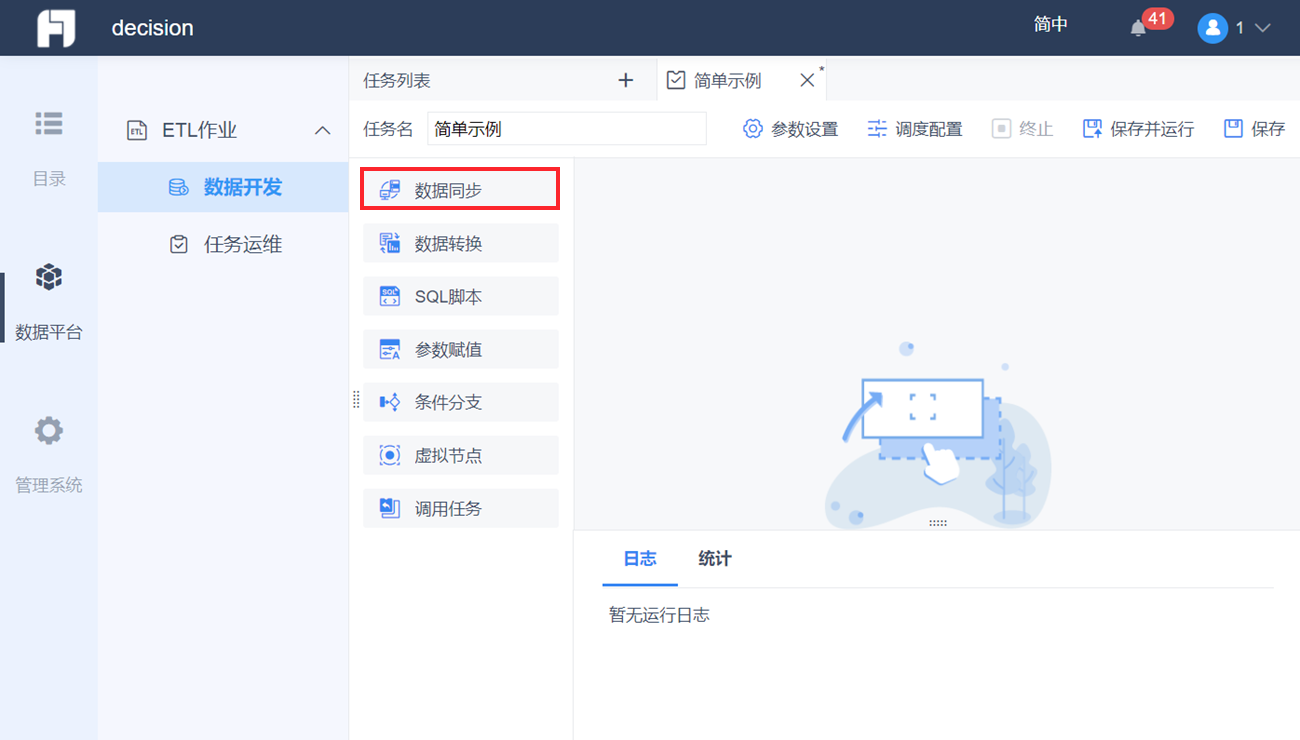
1.3 功能简介
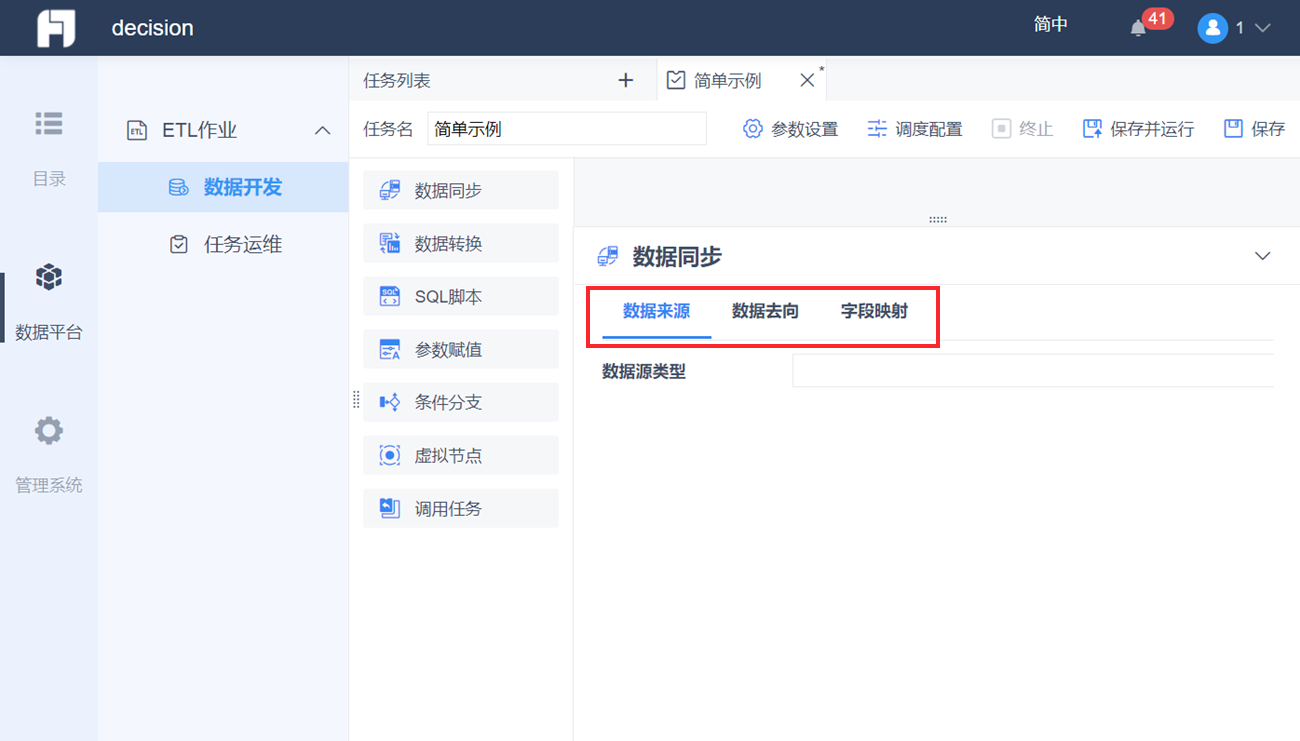
节点从左侧列表拖到设计界面,再点击该节点即可在下方显示所有设置项。数据同步节点有三个设置项,其具体的作用分别如下:
数据来源:设置源表,从哪个数据库的哪张表抽取数据,可写 SQL 语句
数据去向:设置目标表,抽取的数据保存到哪个数据库的哪张表下,可存放到已有的表,也支持自动新建一个表
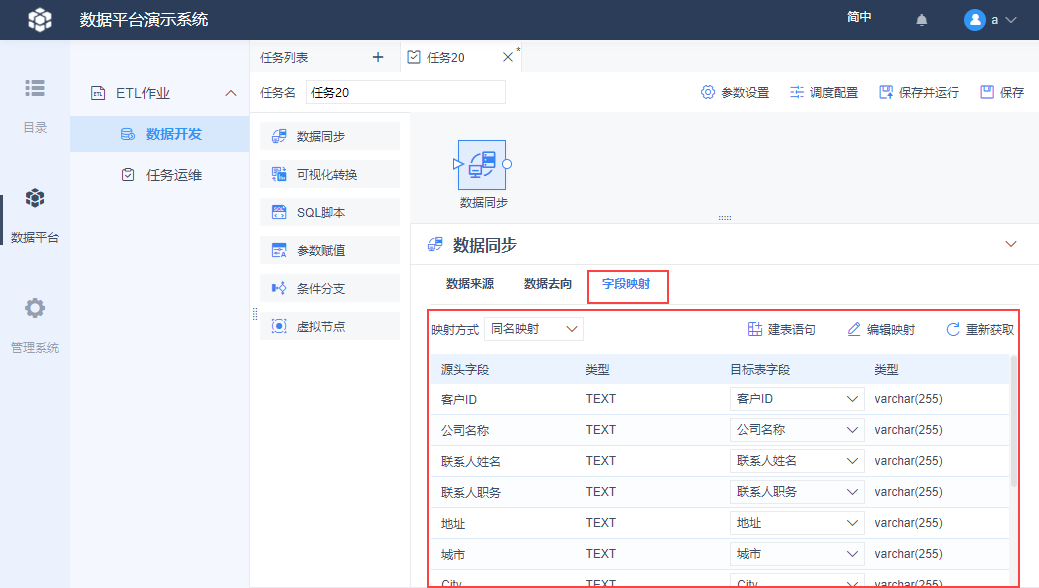
字段映射:设置源表跟目标表之间的字段映射关系,支持手动调整映射关系
2. 示例编辑
此处给出一个示例,演示从一个 SQLite 数据库的客户表中将华北地区的所有数据,抽取到另一个 MySQL 数据库中去。
2.1 创建任务
新建一个 ETL 任务,将一个「数据同步」节点拖到设计界面,点击该节点进行设置。
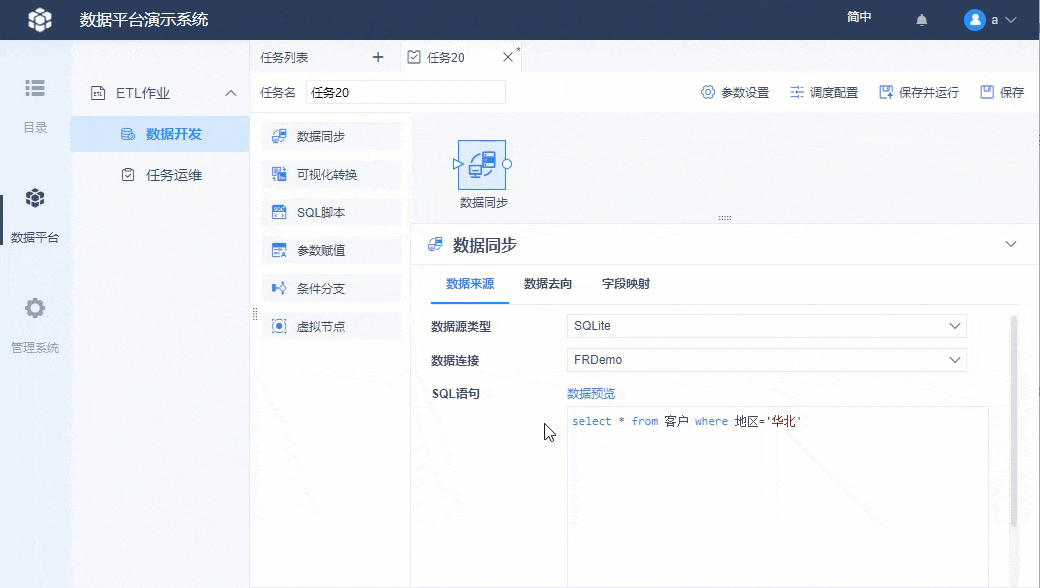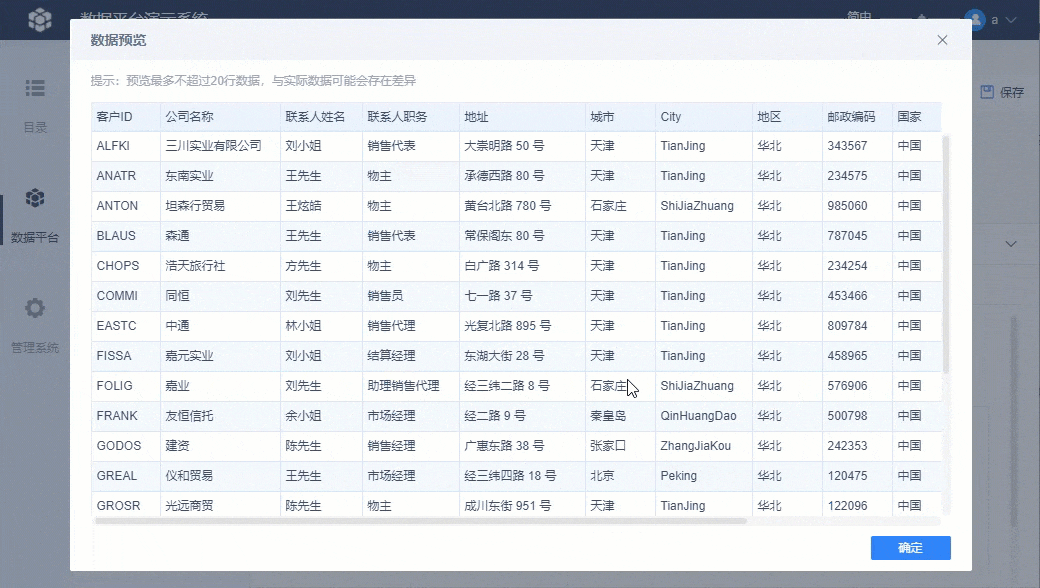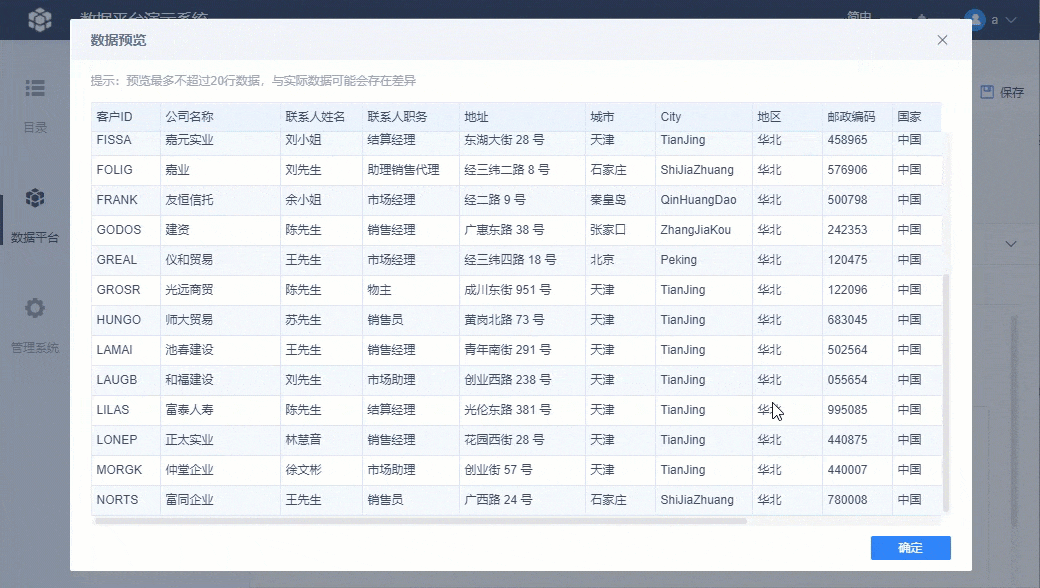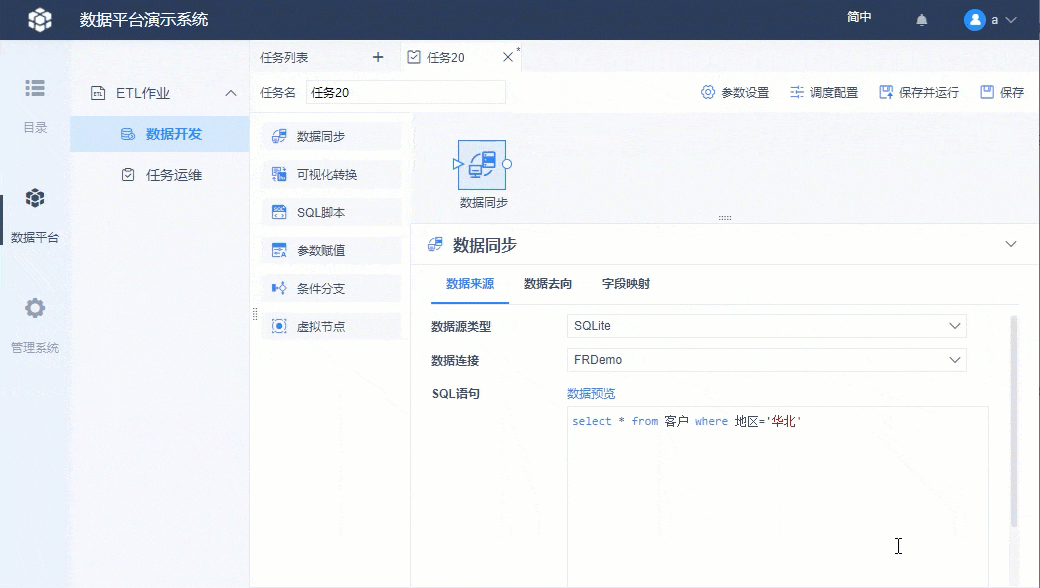
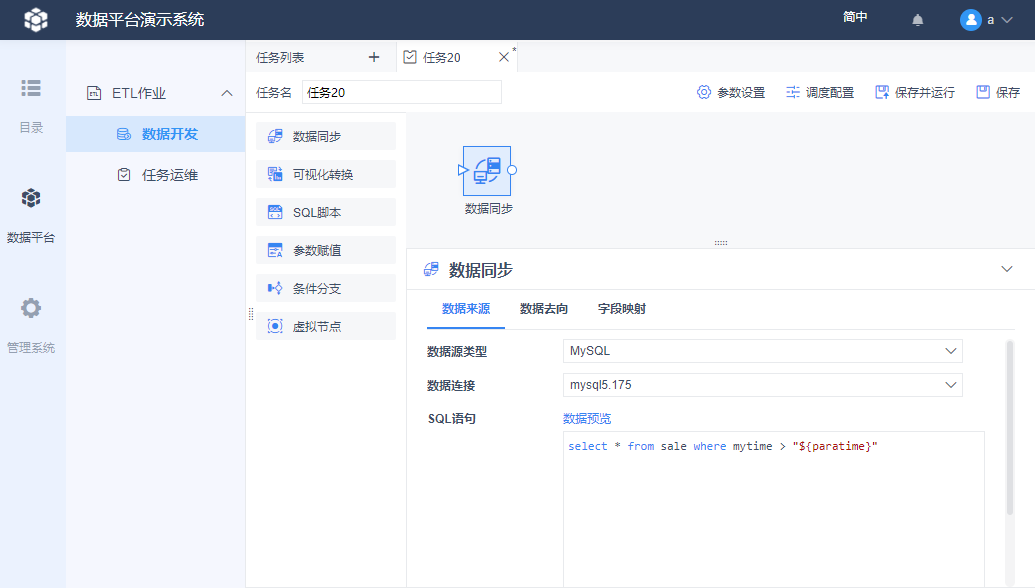
2.2 设置数据来源
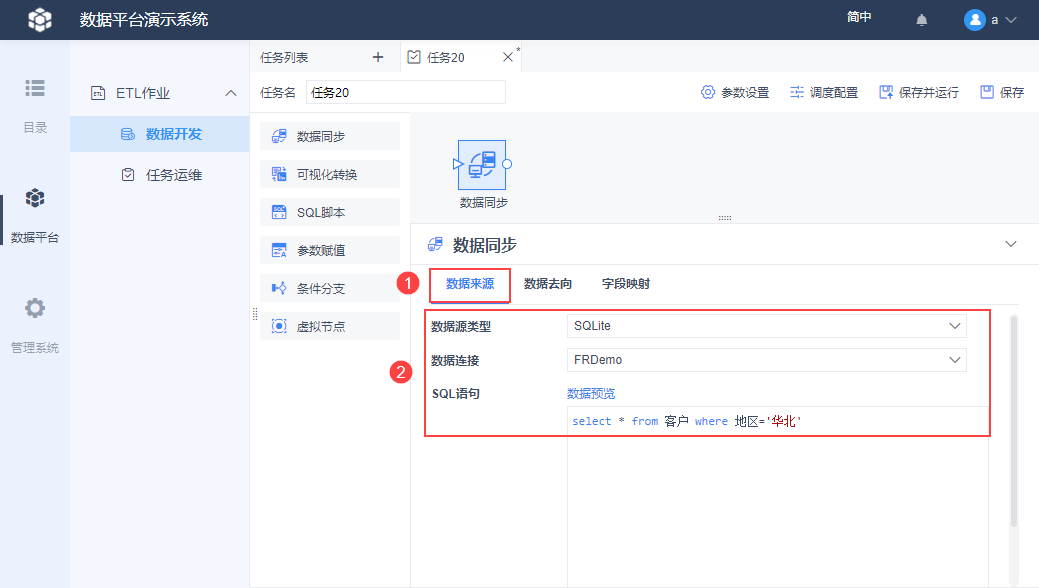
数据源类型选择「SQLite」,数据连接选择「FRDemo」,SQL 语句填写:select * from 客户 where 地区='华北'
此时可以先用「数据预览」看下取数效果,如下图所示:
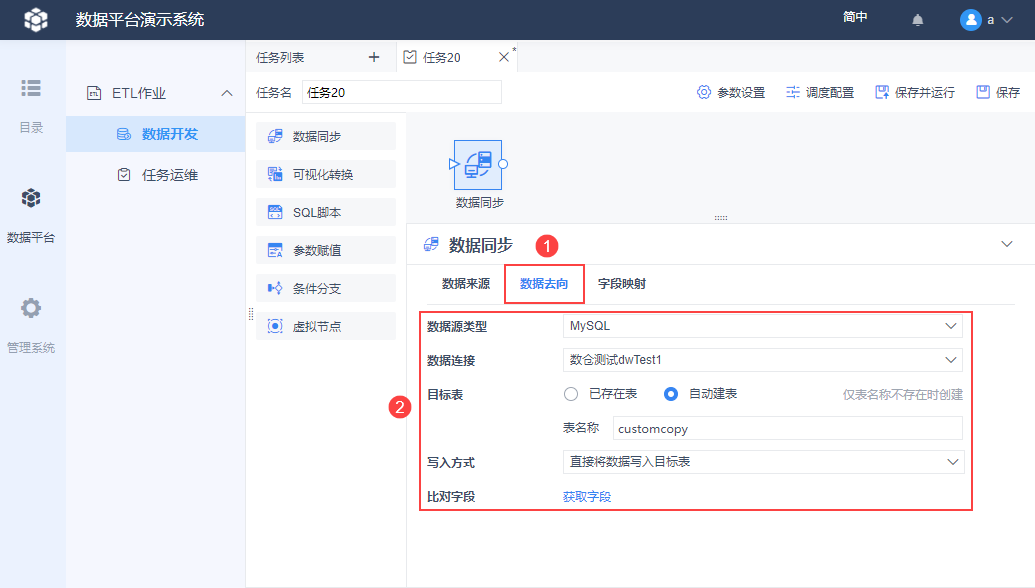
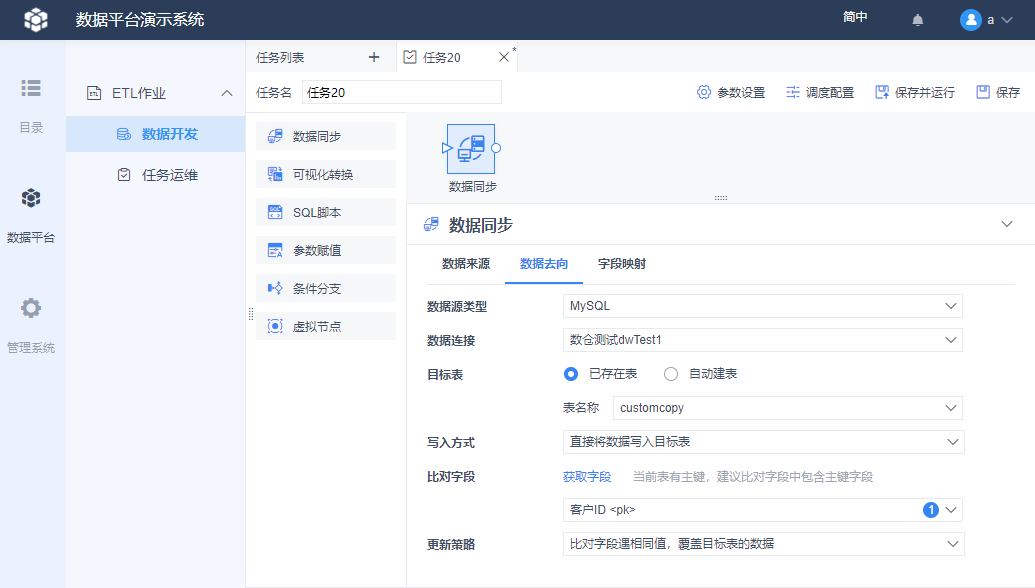
2.3 设置数据去向
数据源类型选择「MySQL」,数据连接选择「数仓测试dwTest1」,由于没有事先建表,所以目标表选择「自动建表」,并给表命名为「customcopy」。
导入方式和比对字段此处无需设置,采用默认的即可,具体它们什么情况下会用到参见本文第 3 节的介绍。
2.4 设置字段映射
字段映射就是查看或修改源表跟目标表的字段关系的,此处用默认的即可,该设置项更详细的介绍参见本文第 3 节。
2.5 运行节点
右键节点后选择「运行节点」,下方运行日志出现执行成功信息即表示节点执行成功。
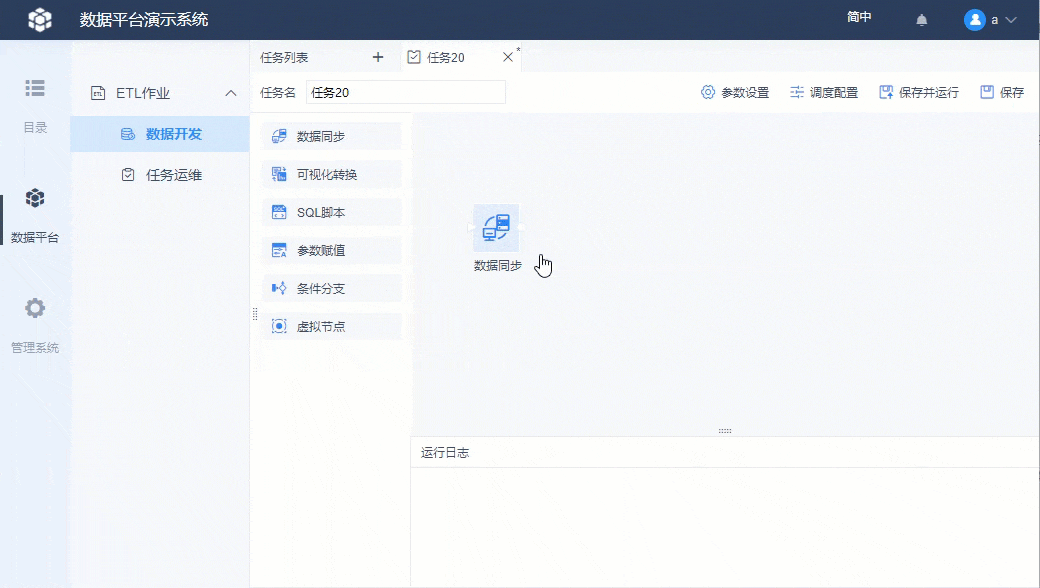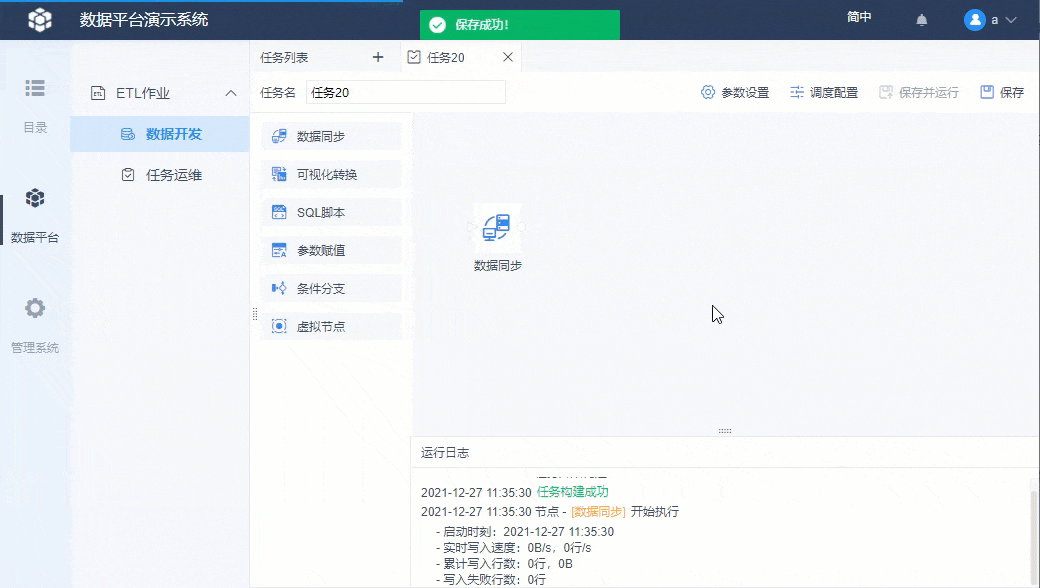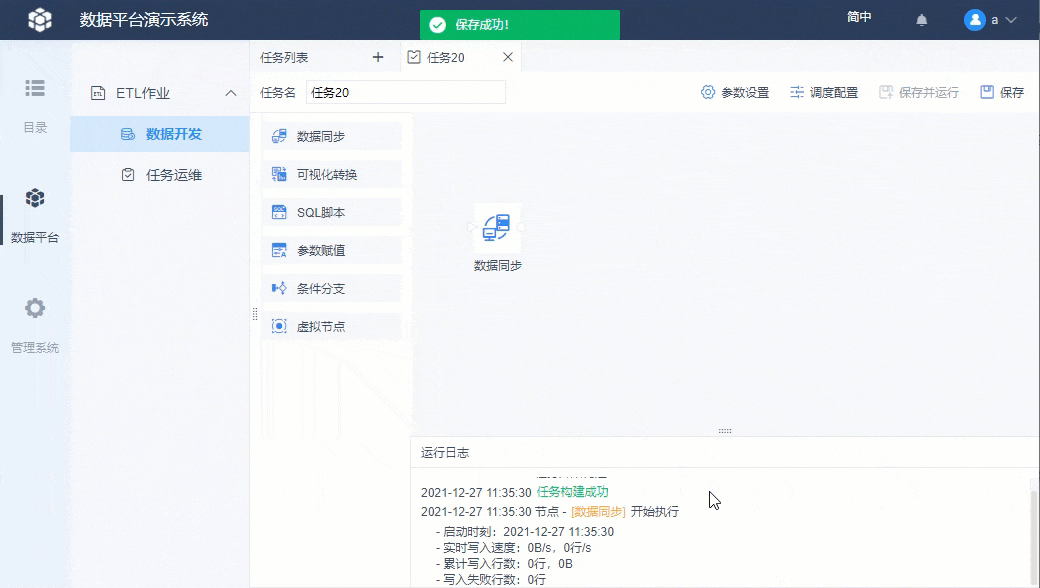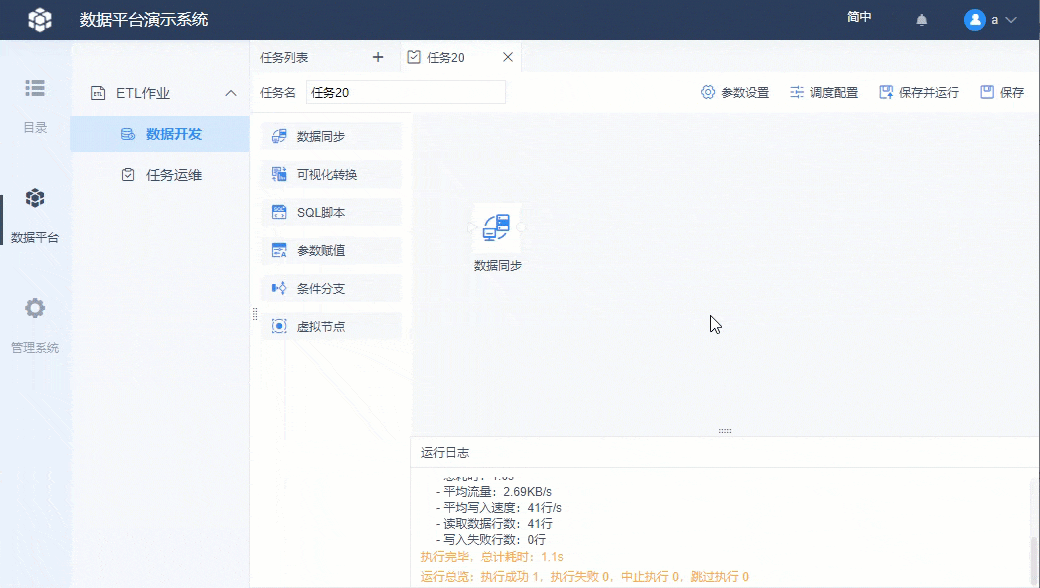
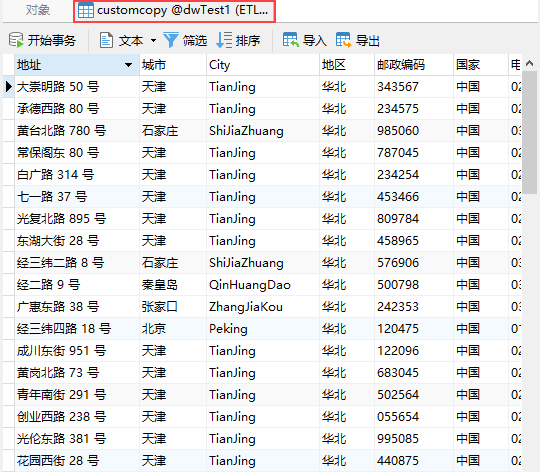
节点运行成功后,可以看到 MySQL 数据库中多了一张表 customcopy,如下图所示:
3. 功能介绍编辑
3.1 数据来源
数据来源一些设置的介绍如下:
数据源类型:请参见:支持的数据源 文档第二章表格(支持数据读取的数据库)。
SQL语句:通过 SQL 从源数据库的表中查询取数,且支持引用 ETL 任务中的参数,参数的定义和使用方式可参见文档 自定义参数
数据预览:可查看当前语句对应的数据,一般用来检查语句写得对不对,预览时最多只显示 20 行且与实际数据可能存在差异
3.2 数据去向
数据去向一些设置的介绍和注意事项如下:
数据源类型:请参见 支持的数据源 文档第二章表格(支持数据写入的数据库)。
数据连接:连接到目标数据库,配置数据连接的方法参见文档 配置数据连接
目标表:「已存在表」是选择目标数据库中已有的表来存放数据,「自动建表」是直接在目标数据库中新建一张表来存放
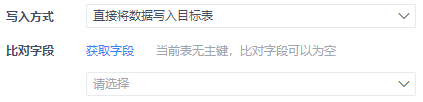
写入方式:数据写入目标数据库表的方式,可以选择「直接将数据写入目标表」或者「清空目标表再写入数据」
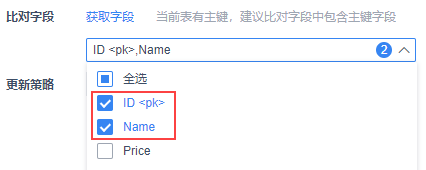
比对字段:允许指定一个或多个字段作为比对字段,来更新目标表中的数据,实现增量写入。目标表有主键时该项必须设置,否则节点运行会报错
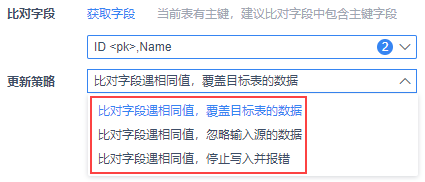
更新策略:上面「比对字段」选择之后( 选择框里不为空 ),就会显示改设置项,可以根据选择的字段,选择数据的更新策略,是覆盖、忽略还是直接报错
写入方式、比对字段、更新策略 3 个设置项某种程度上具有关联性,此处给一个详细的介绍:
1)写入方式
| 写入方式 | 介绍 |
|---|---|
| 直接将数据写入目标表 | 直接将数据写入到目标表中:
|
| 清空目标表再写入数据 | 直接先把目标表清空掉,然后再写入数据 |
注:数据量较大情况下,「直接将数据写入目标表」会比「清空目标表再写入数据」的执行效率更高,因为后者方案需要先清空目标表数据,再将来源表的数据全量抽取至目标表中;而前者方案直接利用目标表的主键,将来源表数据和目标表数据进行比对,若数据有变化即更新,若数据无变化则不更新,相比后者方案,更新的数据会更少,所以抽数速度更快。
2)比对字段和更新策略
| 目标表 | 比对字段 | 更新策略 |
|---|---|---|
| 如果目标表设置了主键 | 目标表有主键,也就是对数据唯一性有约束 有增量数据要写到目标表中时,就要判断是插入目标表中没有的新数据,还是更新目标表中已有的数据,判断就要用到「比对字段」
点击「比对字段」后,主键字段会自动选中
主键字段可以取消,但是建议保留,在此基础上还可以选择其他字段:
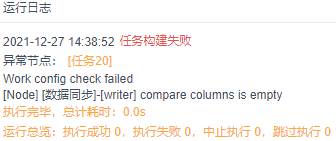
这样有更新的数据过来后,就可以根据这些比对字段来实现数据更新,但是要结合更新策略来判断,是覆盖掉、忽略掉还是直接报错 注:目标表有主键,比对字段必须要选,选择框里不能空着,否则会有报错: compare columns is empty
| 只要设置了比对字段,就会显示「更新策略」这个选项 因为目标表有主键时,必须要选择比对字段 所以在点击「比对字段」后,更新策略必定出现 可选项有 3 个,分别如下:
增量数据和目标表中比对字段有相同的,也就是更新操作,那么直接将这些相同字段对应的记录覆盖到目标表中去
增量数据和目标表中比对字段有相同的,那么直接忽略掉这些相同字段对应的记录,只插入目标表中没有的数据
增量数据和目标表中比对字段有相同的,那么停止写入并报错
|
| 如果目标表没有主键 | 目标表没有主键,也就是对数据唯一性没有约束 那么此时点击「比对字段」后,可以不选择字段,如果不选,不会显示更新策略,那么增量数据都是直接插入到目标表里,没有更新数据这一说
当然也可以选择比对字段,这时就会出现更新策略,可以区别是插入目标表中没有的新数据,还是更新目标表中已有的数据
| 不选比对字段,不出现更新策略 选择了比对字段,更新策略同上 |

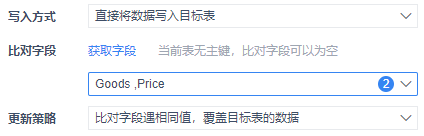
注1:如果字段映射里目标表中缺少比对字段,那么写入数据时就会找不到比对字段。所以字段映射时必须包含比对字段。
注2:若目标表中的字段包含约束,则写入的字段需要满足约束。
注3:当选择比对字段为主键时,若目标表中未写入的字段存在约束,那么写入数据会出现失败,这种场景仅在 MySQL 和 Postgre SQL 中出现。
注4:字段中若有 null 则不能作为比对字段;不能选择字段类型为 float 的字段作为比对字段。
3.3 字段映射
数据映射一些设置的介绍和注意事项如下:
映射方式:可选择源表字段跟目标表字段的映射方式,有两种分别是「同名映射」和「同行映射」
建表语句:如果设置「数据去向」时是「自动建表」的,那么就会有这个入口,点开后可查看和复制建表语句,如果自动建表不满足要求,可粘贴到 SQL脚本 修改并建表
编辑映射:用户能够选择性地使用获取到的来源字段,不想写入的字段删除映射字段即可
重新获取:源表的字段、字段类型发生改变时,点击该按钮可重新获取,并初始化字段映射界面
注1:「数据去向」中若选择「自动建表」,「字段映射」Tab下可删除表字段、修改表字段展示顺序、修改表字段长度、修改字段类型。
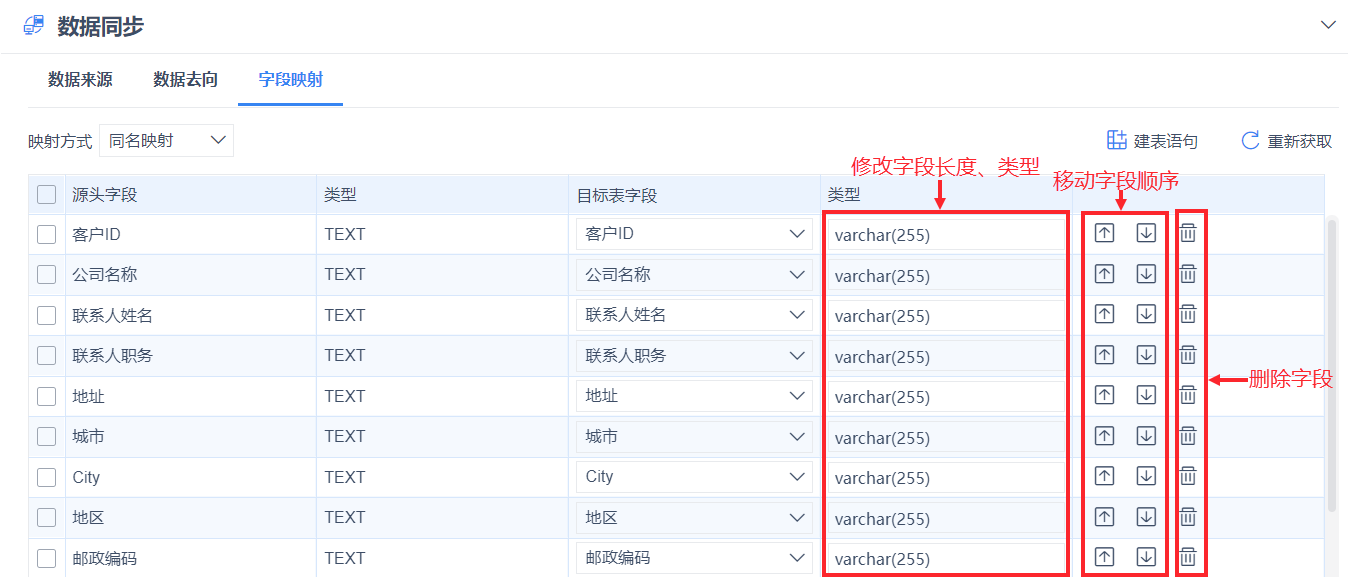
注2:「数据去向」中若选择「自动建表」,「字段映射」Tab下修改表字段展示顺序的方式,从点击调整字段顺序调整为拖拽调整字段顺序。

两种映射方式的匹配逻辑如下:
| 映射方式 | 匹配逻辑 |
|---|---|
| 同名映射 | 按照目标表字段与来源表字段字符重合的情况匹配,整体逻辑为: 1)根据来源字段,在目标表中寻找同名(字符完全相同)字段对其进行匹配 2)没有同名字段时:
3)如果在目标表中找不到同名或者包含目标表字段字符的字段,则右侧映射字段显示为空 |
| 同行映射 | 源头字段和目标表字段按顺序匹配:同行则建立映射关系 |
使用时一些需要注意的点:
1)映射时删除了一些来源表字段,那么切换映射方式后,还是会根据剩下来的这些字段进行调整
2)手动将映射方式从默认项「同名映射」切换到「同行映射」,点击「重新获取」字段,获取的字段将按照「同行映射」的方式自动匹配
3)以下两种场景会出现目标表无字段可匹配源头表的情况,在这两种情况下,右侧目标表字段可展示为空:
同名映射:目标表不存在包含源头表字段的字段
同行映射:源头表字段数量大于目标表字段数量
4)映射时,如果右侧目标表有空字段,会出现提示图标,悬浮在其上方提示:目标表字段存在空值,如下图所示:
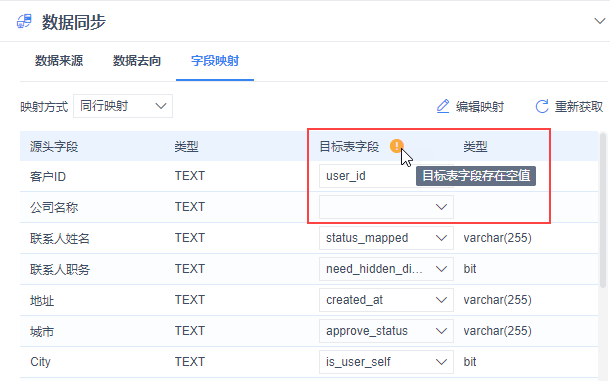
注:如果字段映射里目标表中缺少比对字段,那么写入数据时就会找不到比对字段。所以字段映射时必须包含比对字段。
4. 功能变动编辑
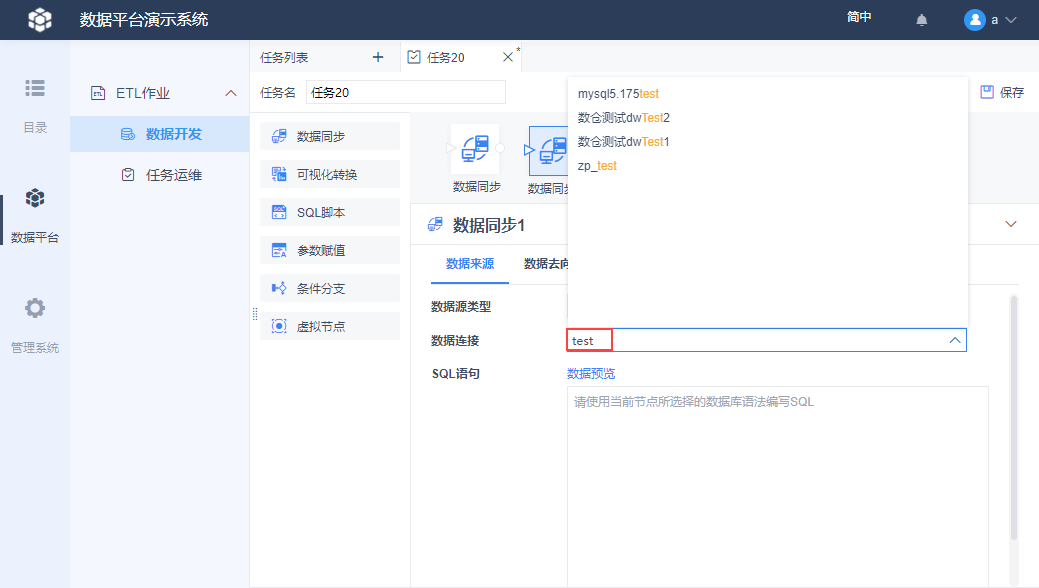
4.1 下拉框支持模糊搜索
设置「数据来源」和「数据去向」时,下拉框可直接编辑,输入内容后可模糊搜索,如下图所示:
4.2 数据来源支持服务器数据集
直接上传或者配置固定路径下 CSV、Excel 文件作为数据来源是比较常见的。为了满足用户直接从文件读取数据的需求,数据来源支持服务器数据集。
使用方式:
1)按照文档 服务器数据集 在设计器中新建数据集。
2)ETL 任务的「数据同步」节点中,将数据源类型设置为「服务器数据集」,然后选择对应的「数据集类型」,再选择该类型下的那个「数据集」即可。
具体的配置流程参见文档:数据源类型为Excel
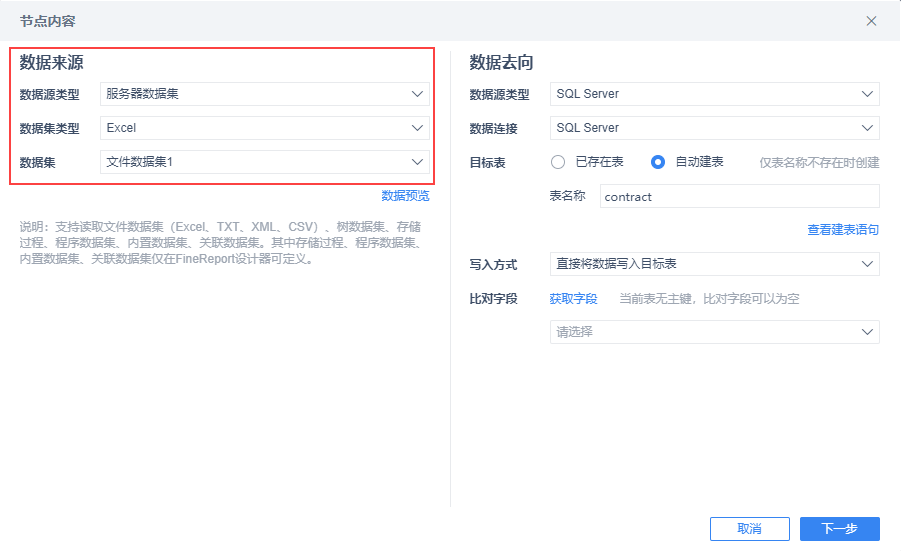
注1:暂不支持读取 SQL 数据集,TSV 数据集会自动识别为 CSV 数据集
注2:添加 CSV 数据集需要安装插件,详情参见文档:CSV数据集
注3:如果存储过程可以生成多个数据集,默认只取第一个数据集
注4:文件数据集地址中包含参数,那么参数可以被解析使用,例如:
用户定义了文件的 URL 为:https://fanruan-market.oss-cn-shanghai.aliyuncs.com/fine_data_prep_test/${today}.xls ,如果 ${today} 在 ETL 任务内被定义过,那么支持正常解析。