

1. 概述编辑
1.1 版本
| FineBI 版本 | 功能变动 |
|---|---|
| 6.0.7 | - |
1.2 应用场景
场景一:处理脏数据
在处理脏数据,去除重复行时,该功能非常有用。
例如:有的订单数据不小心触发了两次,一个订单有两个订单数据,这就形成脏数据,我们可以通过删除重复行功能只保留一行。如下图所示:

场景二:保留部分数据
用户需对机器状态进行数据采集,但由于是随机采集,数据分布不均匀,每分钟可能采集了 10-20 条不等。可以使用「删除重复行」,每分钟只保留一条数据。
场景三:去除重复行
若需要的数据在一张宽表之中,比如,我需要对以下宽表中的用户数据进行分析。
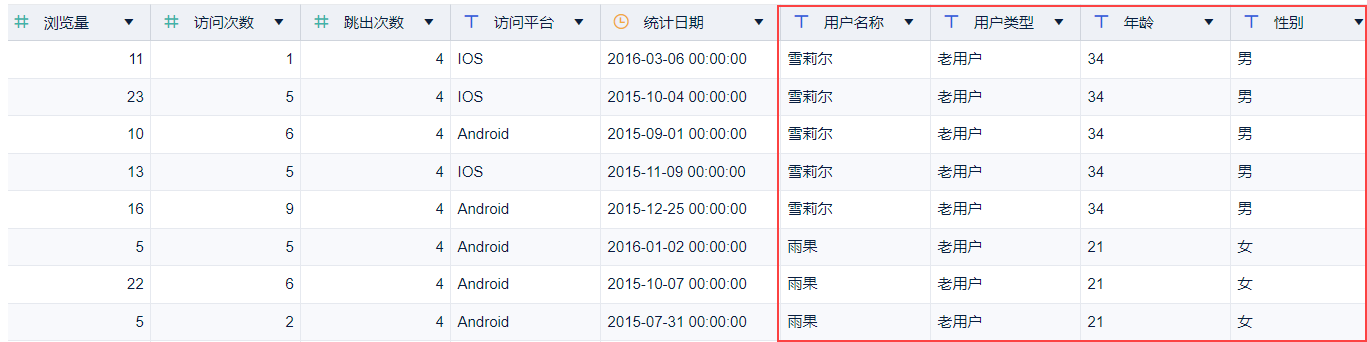
可以通过字段设置,删除掉其他字段。再通过「删除重复行」,对用户数据进行去重。如下图所示:
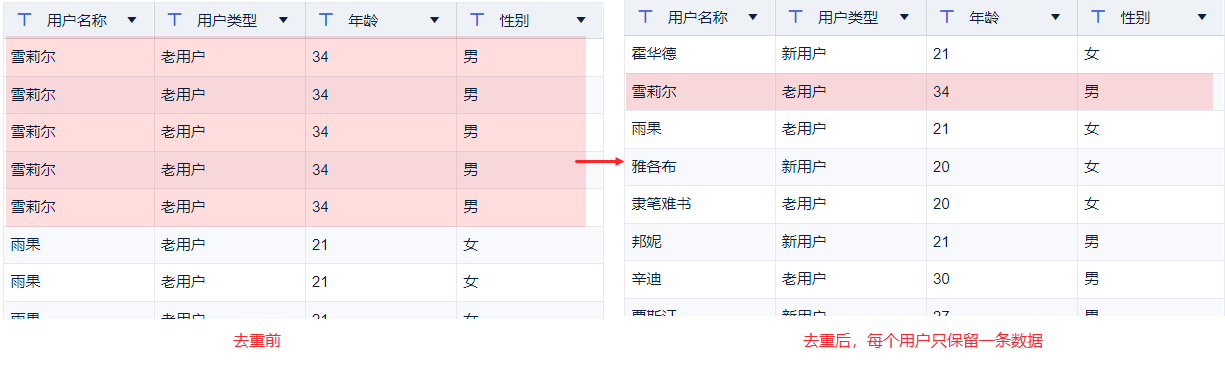
1.3 功能简介
系统通过用户所选的去重字段,去判断数据有没有重复行。若去重字段选择「全选」,则按照所有字段去判断是否有重复行。
重复行,保留靠前的第一行数据。
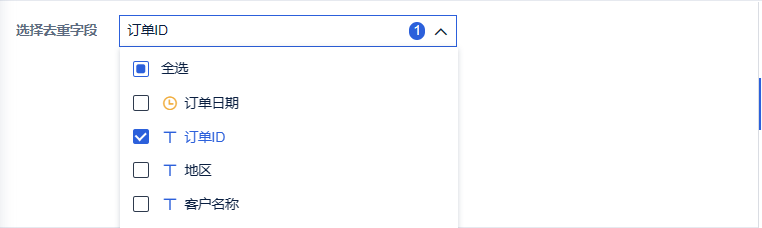
2. 示例编辑
下载示例数据:订单数据.xlsx
1)将示例数据添加进分析主题,如下图所示:

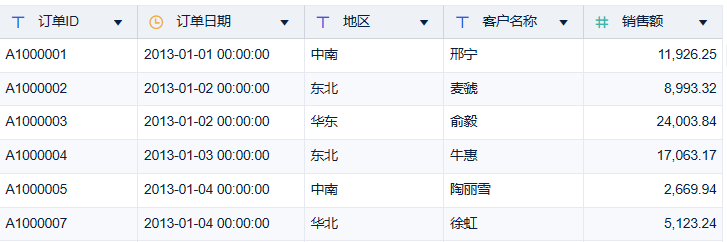
从该表的数据中,可以看到有订单计入了两次数据,且数据是重复的,只有订单 ID 不同。
2)添加「删除重复行」,如下图所示:

3)系统按照所选的去重字段判断是否有重复行。若订单日期相同、客户名称相同、订单金额相同,我们基本可以确定这是同一个订单了。
所以选择「订单日期、客户名称、销售额」三个字段作为判断是否重复的依据,如下图所示:
注:判断重复后,系统默认保留第一行的数据。例如 A1000005 与 A1000006 重复,只保留第一个 A1000005 的数据。

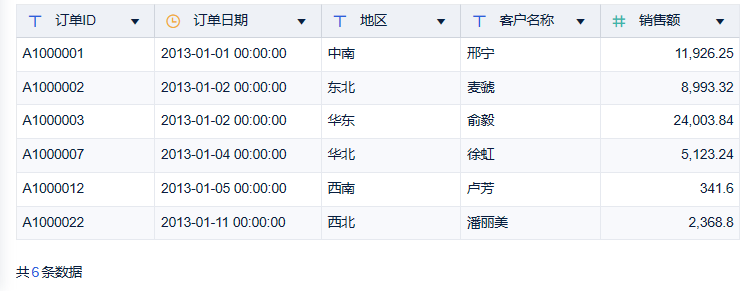
4)点击「保存并更新」,就能得到没有重复值的数据。
这里也给大家列举下,选择不同的去重字段,会得到什么样的结果:
| 去重字段 | 结果 |
|---|---|
| 只选择「地区」 | 各个地区只保留一条订单数据:
|
| 只选择「客户名称」 | 每个用户只保留一条订单数据:
|
3. 使用建议编辑
判断哪些行重复后,系统会默认保留排在前面的第一行数据。
所以在不同的步骤去做「删除重复行」操作,可能会导致系统选择保留的第一行数据不相同。建议用户尽量将「删除重复行」最为最后一个步骤来做。