

1. 概述编辑
1.1 版本
| 版本 | 功能变动 |
|---|---|
| 6.0 | - |
| 6.0.12 |
|
1.2 应用场景
人类的家谱,记录了人们之间的亲属关系;那 FineBI 的血缘分析,记录的是数据表、组件之间的亲属关系。
假设我们有一张数据表「门店销售数据分析」,我们可以在血缘分析中看到该表从哪里来的(父表是那些),以及用该表做了产物(子资源:包括子表、组件、仪表板等)。
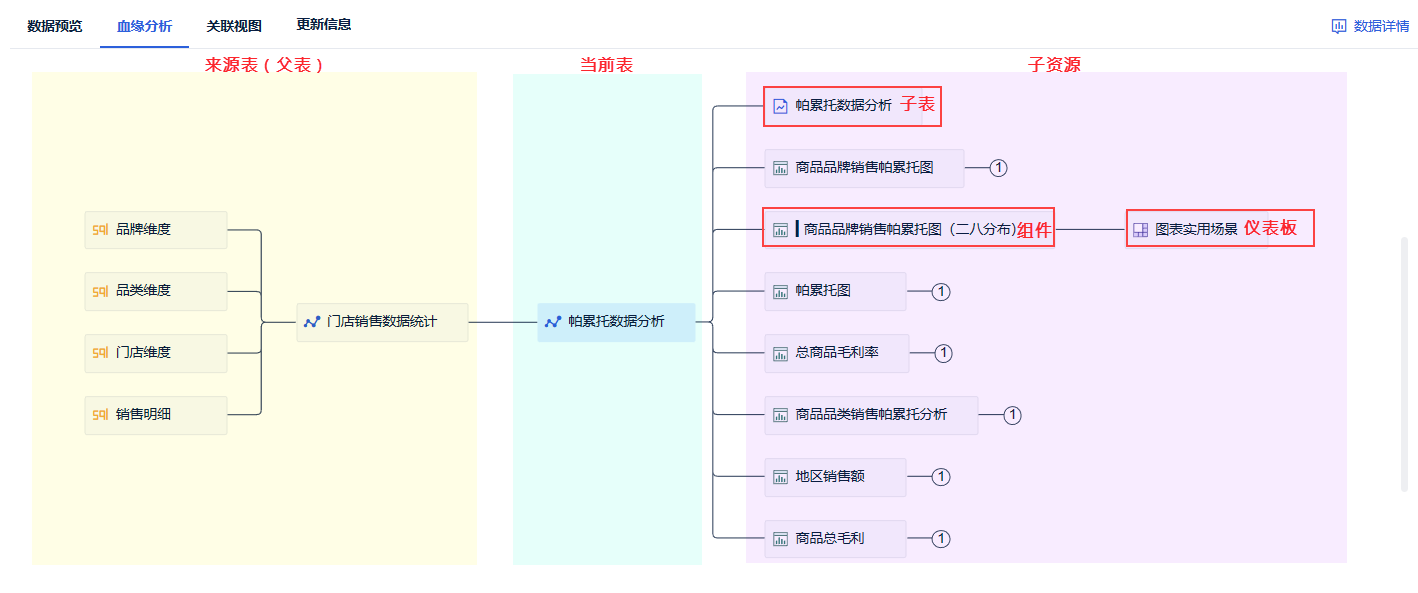
血缘分析可以帮助我们:
数据来源追溯:跟踪当前表的原始来源表,方便我们确定数据的准确性和可信度。
故障排查:当当前表出现质量问题、分析结果异常或更新错误时,用户可以通过血缘分析,追溯数据的来源及更新情况,定位问题的根源,并采取相应的纠正措施。
查看当前表的影响范围:若当前表拥有众多子资源,则说明它的影响很大。我们需要谨慎对当前表进行修改或删除操作。
1.3 功能简介
查看影响在血缘分析界面可以查看该数据表的来源表和使用它制作的子孙表、组件和仪表板;
用户在血缘分析页面点击对应的数据表或仪表板,可以直接跳转到数据表和仪表板处;
2. 血缘分析功能介绍编辑
2.1 查看血缘分析
点击「公共数据」,选择需要查看的数据表,点击「血缘分析」。如下图所示:
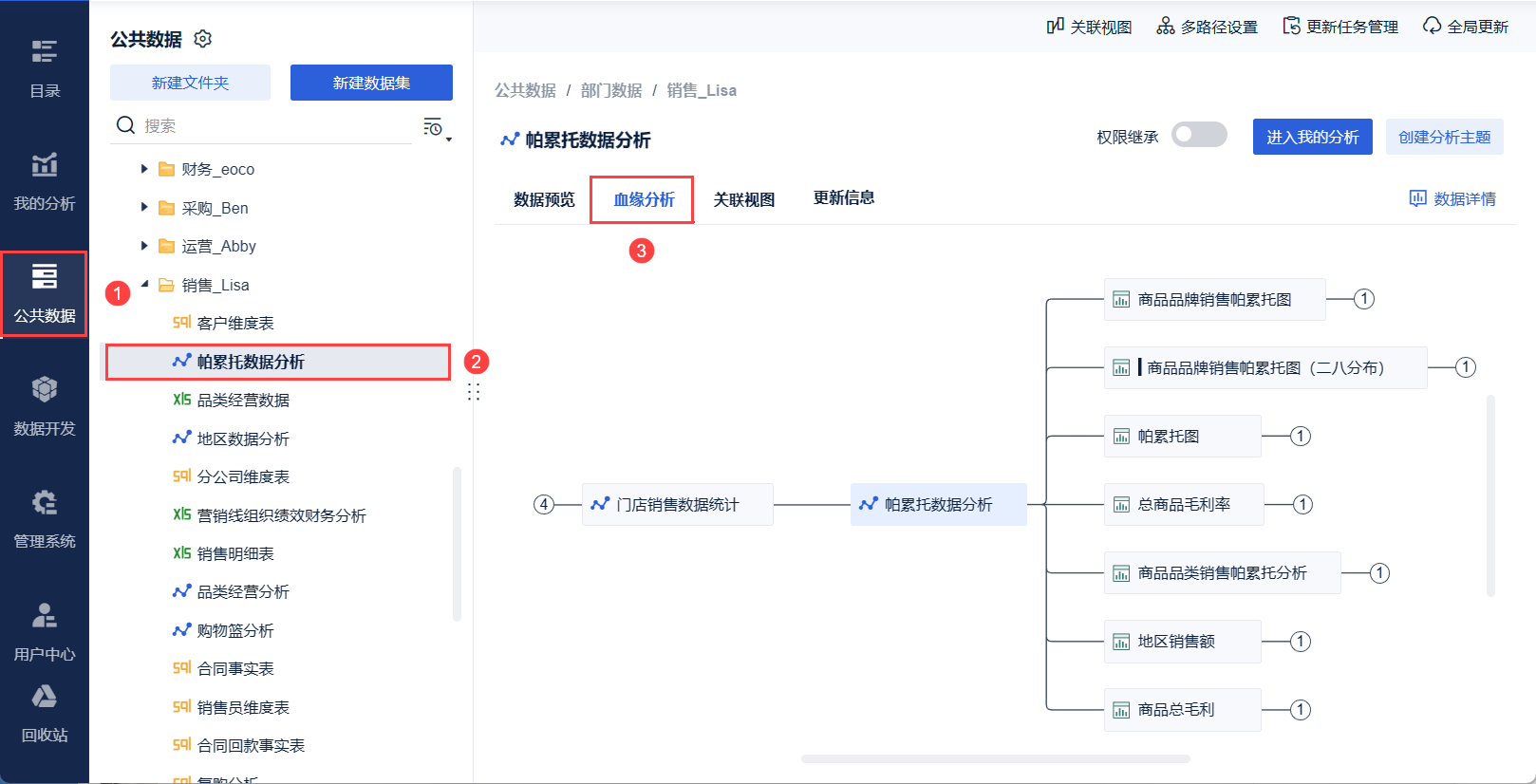
若想了解「创建者、位置、更新时间等」,用户可将鼠标悬浮在对应的标签上。如下图所示:
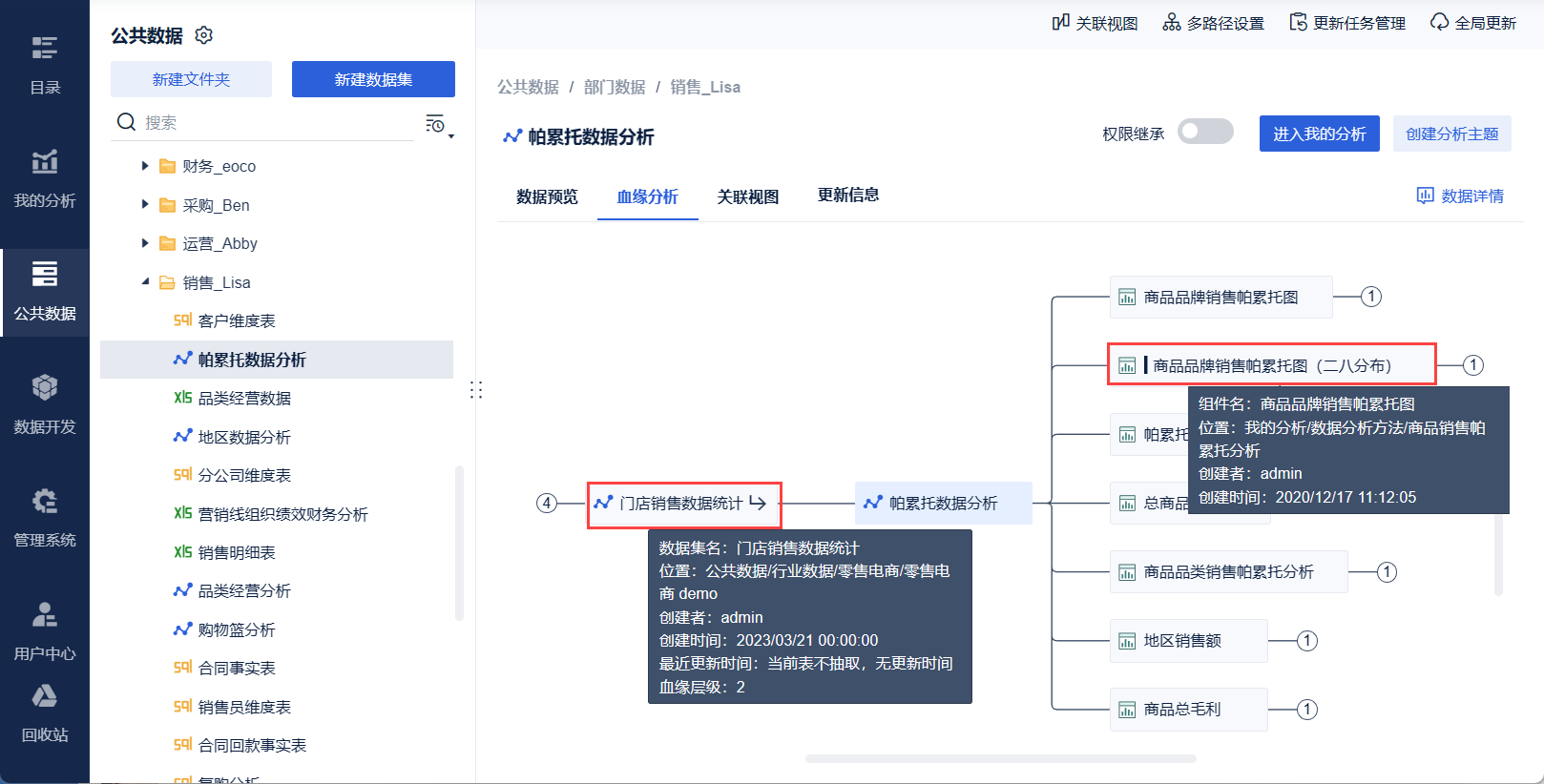
在数据表的详细信息中,显示了数据表的血缘层级,血缘层级代表数据表在血缘中的层次级别:
若数据表的血缘层级为 1 ,说明该数据表没有父表,是这条血缘线的祖宗或祖宗之一。
若数据表的血缘层级为 2 ,说明该数据表上面有 1 层父表。
若数据表的血缘层级为 13,说明该数据表有 12 层父表。这 12 层上所有的表都是它的来源表,这些来源表的变化都会对此表产生影响。我们应该要尽量避免出现这种血缘层级很深的情况,详细可参见本文第 3 节。
注:为了避免血缘层级过深带来的维护问题,6.0.12 及之后的新工程所有数据表默认最大层级限制为 16。
若来源表本身还有来源表,子孙表本身有子孙表和仪表板,组件也有仪表板,就会继续做血缘分析。下一层的血缘分析默认折叠,用户可手动设置展开折叠,如下图所示:

2.2 点击跳转到对应位置
点击表跳转按钮,可以跳转到表对应位置。如下图所示:
注:当数据表无使用权限,仪表板无查看权限时,它们的标签会灰化显示,点击标签不能跳转。

点击跳转按钮可跳转到组件或仪表板的编辑界面。
注:仅支持组件和仪表板的创建人在血缘分析界面点击跳转,其他用户不支持点击跳转到对应位置。

3. 避免创建血缘层级深的数据表编辑
3.1 深血缘层级的危害
我们可以从下图中看到「当前表」存在无数个父表,每个父表又有无数个父表,形成了深层次的血缘层级。所以当「当前表」出现问题时,追溯问题的来源变得非常困难。我们很难从这些父表中找出问题,增加了故障排查和溯源的复杂性。
更令人担心的是:当这几千上万个父表中的任何一个出现问题时,都可能导致「当前表」变得不可用。这样的依赖关系使得整个数据表的稳定性和可用性极其脆弱。
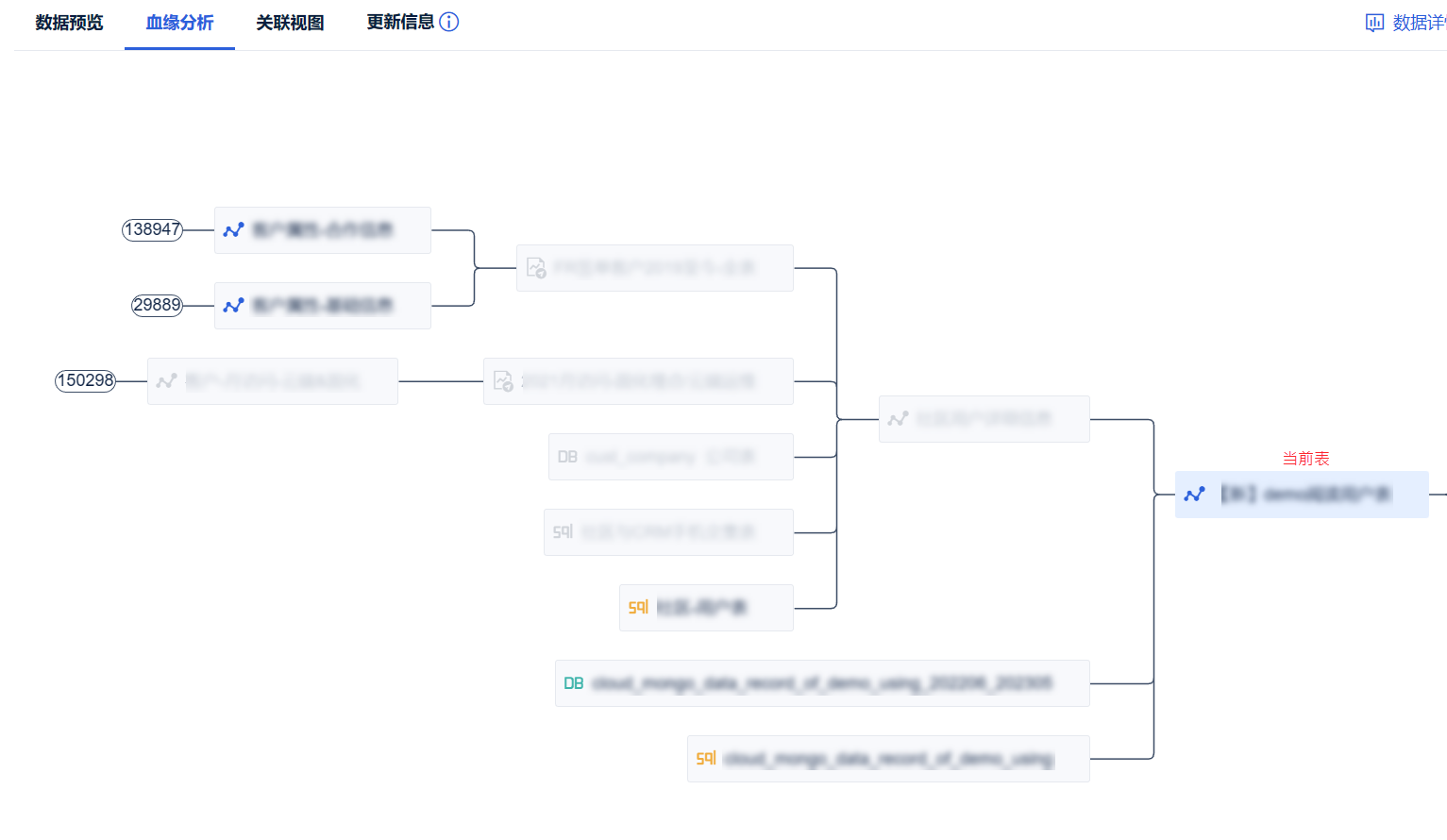
以上我们展示了一个极端情况,此例也告诫我们避免创建以及依赖深层次血缘层级的数据表:
难以理解和维护: 当表结构层级很深时,数据元素之间的关系会变得复杂,阅读和理解表结构的逻辑会变得困难。对于数据维护人员和开发者来说,难以准确理解表中数据的来源和去向,增加了维护工作的复杂性。
容易引发错误和风险: 深层次的表容易同时被成千上万的数据表同时影响,只要父表中有一个表错误,当前表就无法使用。
效率低下: 当表的层级很深时,查询和操作数据的效率可能会降低。由于需要跨越多个层级获取所需的数据,查询性能和数据访问效率可能会受到影响,对数据表更新的影响也很大,占用很多无谓的更新资源。
3.2 如何优化(浅化)血缘
我们可以通过以下方式让 FineBI 中的血缘关系变得更简单:
3.2.1 公共数据库中的数据尽量由 IT 准备
我们先来看一下「公共数据」和「我的分析」的定位:
公共数据:是存放公共数据的地方,并不是个人区域,所以就类似于车站、公园这种公共场所。在公共场所中,我们的设备、配套都是由专门的市政机构准备的。所以说我们的公共数据最好也由专业的 IT 人员准备,对公共数据进行管理,可以保证公共数据空间有序、高效、以及数据可靠。
我的分析:是我们每个人自己的分析空间。相当于我们自己的家,可以随意布置,但如果布置整洁,我们住的也会更舒服。
那 IT 人员准备公共数据,为什么能优化血缘呢:
IT 人员多使用专业 ETL 工具(比如FineDataLink)进行数据治理,再通过 SQL 数据集 或 DB表 将数据添加到 FineBI 的公共数据中。这样得到的表质量高,且没有父表,用它们进行分析不会引发复杂的血缘关系。
IT 人员对数据的处理和规划质量更高,不容易产生问题,影响之后用该表做的子资源。
3.2.2 避免分布深血缘层级的数据
虽然我们不推荐将编辑数据中的表发布为公共数据表,但如果您确实有这个需求,我们建议您选择较低层级的数据表发布到公共数据中。
例如,如果将层级为 12 的数据表发布到公共数据中,其他用户使用该数据表创建的新分析资源的血缘层级将大于12。
相比之下,如果将层级为 2 的数据表发布到公共数据中,其他用户使用该数据表创建的新分析资源的血缘层级将大于2,相对于前一种情况来说,这种选择要好得多。
4. 注意事项编辑
4.1 血缘中数据集无权限无法点击
当前数据集无权限:此数据集无使用权限,需要管理员分配 数据权限;
当前仪表板/组件无权限:不是本人制作的仪表板/组件,所以没有权限;
当前数据集/仪表板/组件不可用:数据更新失败,导致不可用,需要检查更新状况;
当前数据集/仪表板/组件丢失:内容被删除了,或者已发布或分享的内容被取消发布或分享;
4.2 血缘层级超出限制
系统默认数据表的最大血缘层级为 16 ,若数据表的层级超过 16 ,则会报错:当前数据集超出血缘层级限制。
说明当前表的父表层级过高,用户可以重新选用层级较低的表作为父表,重新进行数据编辑。
111s
当前。数据集超出血缘层级限制当