1. 概述编辑
本文将介绍主题模型区别于左右合并最重要的合并逻辑。
在这里,我们将它总结为以下两个规则:
主题模型是逻辑连接,不会产生一张固定的结果表。只有组件分析中使用到的字段才会参与主题合并
主题模型先执行聚合再合并
接下来跟随笔者一起用例子来了解以上两个规则
2. 左右合并的合并逻辑编辑
左右合并是行级别的合并,通过共享特定列的值来连接表格。我们来看一下左右合并是怎样合并数据的。
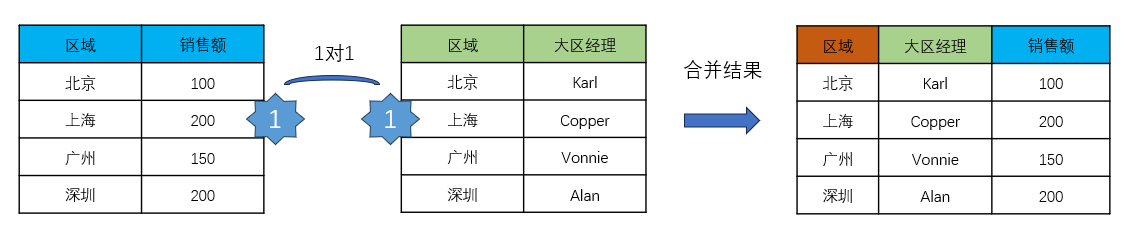
1对1的时候很简单,我们只需要将两张表按「区域」字段将左右两张表拼接起来。如下图所示:
那 N 对 1 是如何合并的呢?左侧表由于有了「分店」字段的加入,北京和广州分别有了两条数据。
右表为了能和左表按「区域」进行拼接,则需要将北京和广州的数据也复制成两条数据。合并结果中我们可以看到大区经理字段膨胀了,标黄单元格就是被复制出来的数据。
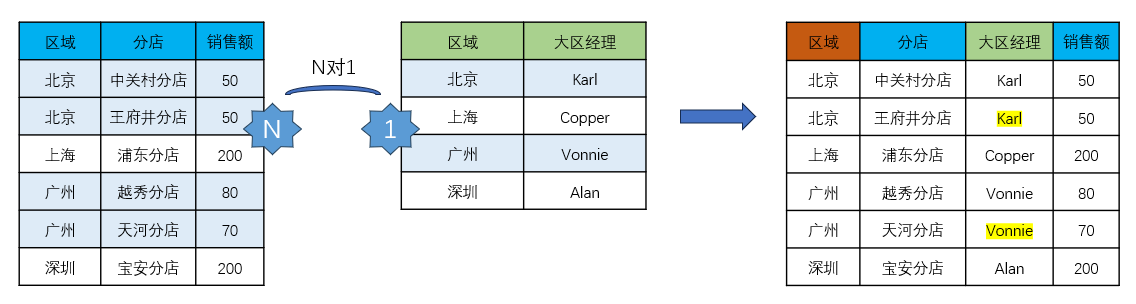
维度字段,比如说上面的「大区经理」被复制后,并不会影响我们的分析。
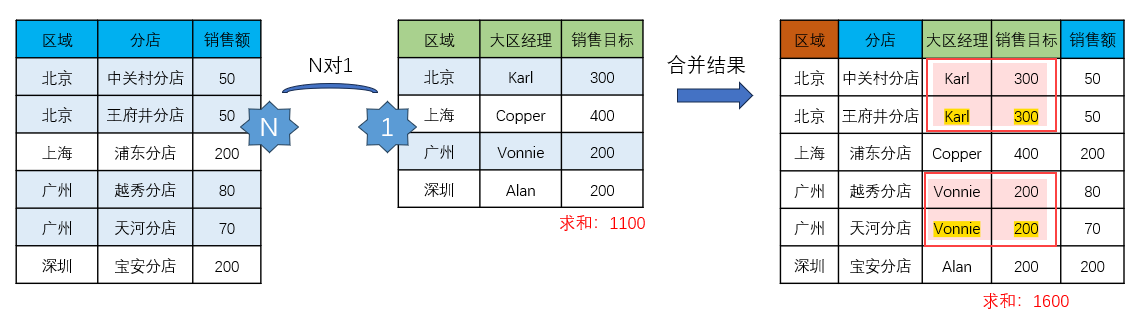
但若是数值字段被复制,就会影响我们之后的计算。比如下图,「销售目标」字段为了能够进行匹配,也进行了复制。
这时候如果我们再对结果表的「销售目标」列进行汇总,会发现求和结果已经是错误值了。
总结一下:维度信息复制不会对结果造成影响,但指标数据被复制,就会造成数据膨胀计算出现问题。
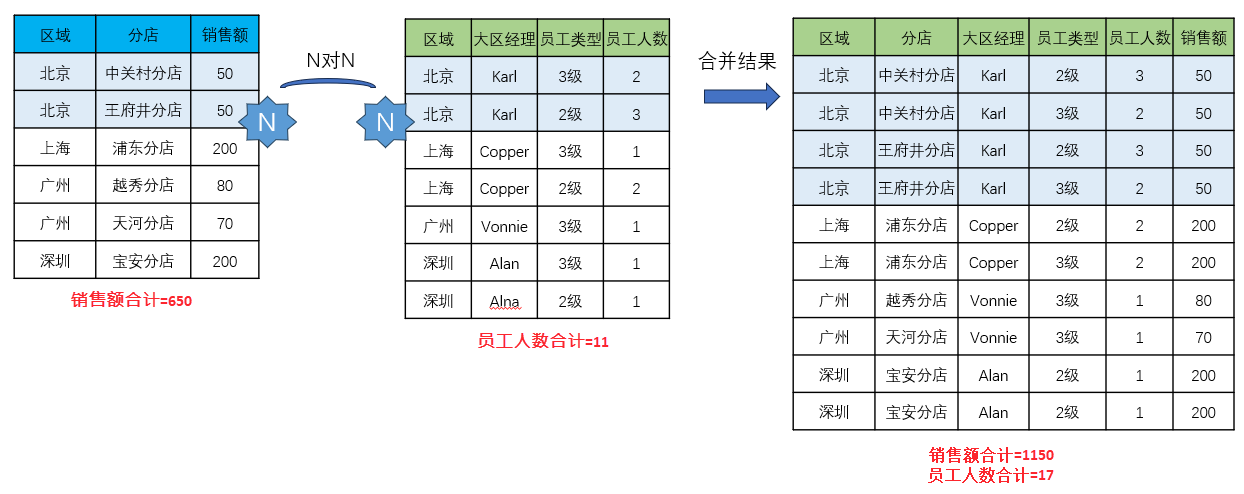
这种指标字段的复制,在 N 对 N 的时候就带来了彻底的混乱。
按「区域」字段进行左右合并,北京字段膨胀为 4 行,指标字段也随之被复制,合计值得到都是错误值。
3. 主题模型的合并逻辑编辑
左右合并(类似于 SQL 语句 join)这种行级别的合并,会造成数据复制和膨胀。
那么主题模型是怎样一个合并逻辑呢?以上左右合并的 N对1 和 N对N 都出现了计算问题,我们来看看主题模型是如何处理的。
先聚合再合并:按我们分析时拖入的维度先对数据表进行聚合,再把聚合后的表进行合并。
来看系统要做哪些步骤:
① 系统判断用户在组件中拖入了哪些字段,只有拖入的字段和关联字段参与主题模型合并;
② 将数据表先后按「关联字段」和「组件中拖入的维度」对表进行聚合
③ 将聚合后的表进行合并
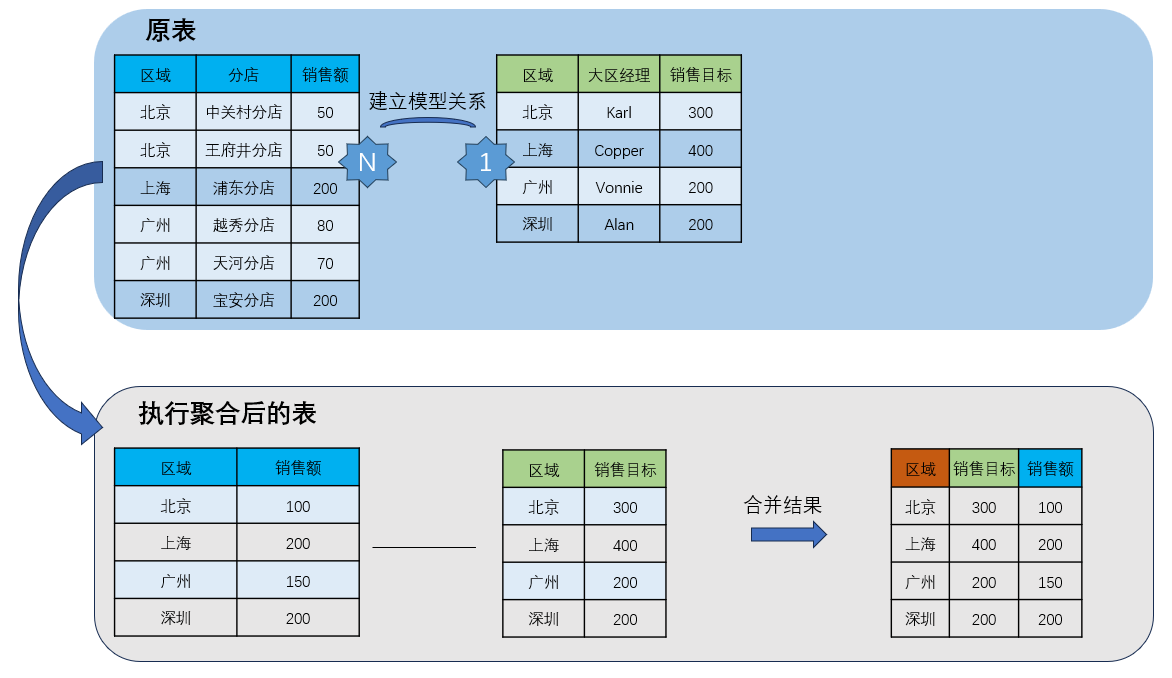
例如下面这个案例:
想要看各区域的销售额是否达成目标,我们在组件中需要使用的字段就是「区域、销售额、销售目标」:
① 系统只取「区域、销售额、销售目标」这三个字段参与主题模型;
② 将建立模型的两张表按组件中拖入的维度按「区域」进行聚合;
③ 将聚合得到的两张表按「区域」进行合并,得到结果表;
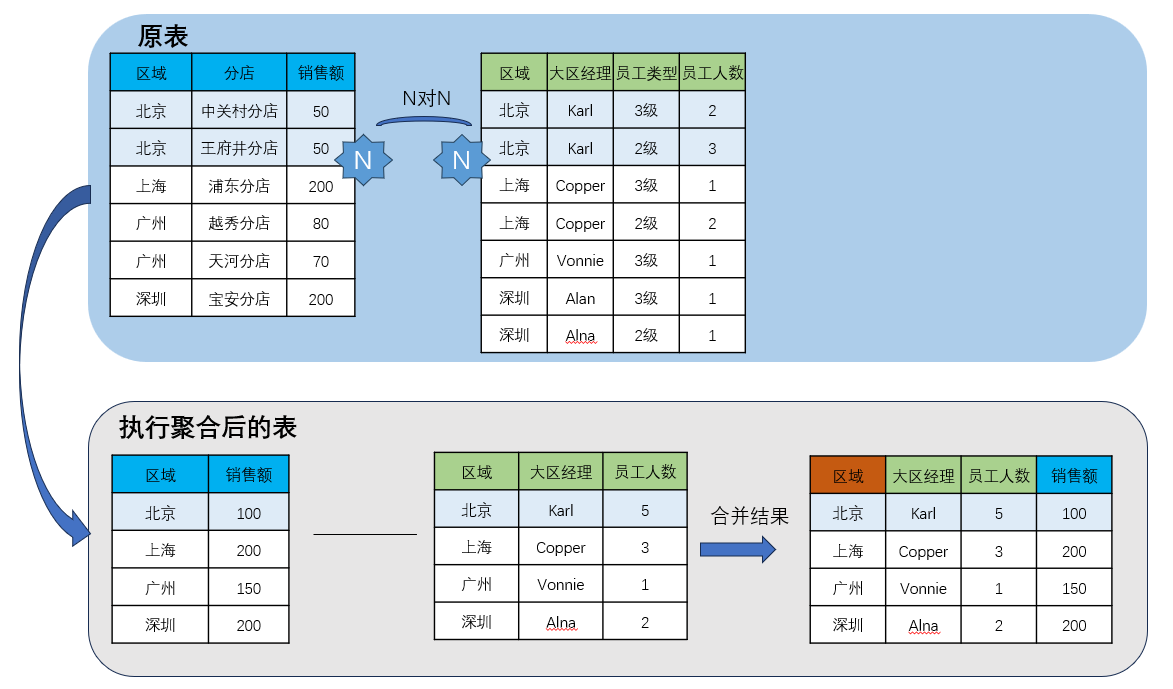
再来看一个 N对N 的案例:
想要知道各大区经理团队的人均销售额,我们在组件中需要使用的字段就是「大区经理、销售额、员工人数」
① 系统只取「大区经理、销售额、员工人数」以及关联字段「区域」参与主题模型;
② 将建立模型的两张表按组件中拖入的维度「大区经理」进行聚合;
③ 将聚合得到的两张表按关联字段「区域」进行合并,得到结果表;
得到结果后,我们在组件中使用 sum_agg(销售额)/sum_agg(人数) 就可以求得人均销售额。