

1. 概述编辑
1.1 应用场景
在直连数据模式下,加速引擎可以提高大数据场景下数据应用的效率,实现更高的性能和满足大规模数据处理的需求。
如要使用加速引擎,可以在「加速引擎」功能下配置加速库,并监控加速库中的数据性能 。
1.2 功能简介
加速引擎主要有三个功能:
加速引擎:配置一个数据库作为加速库,并监控加速库的状态(仅支持 StarRocks 数据库作为加速库);
SQL分析:监控 FineBI 中 SQL 的执行速度和性能;
Excel 上传记录:查看 Excel 的上传情况;
1.3 使用前提
该功能是 BI 6.0 的可选模块,需要购买并注册该功能点后才可使用。
2. 加速引擎编辑
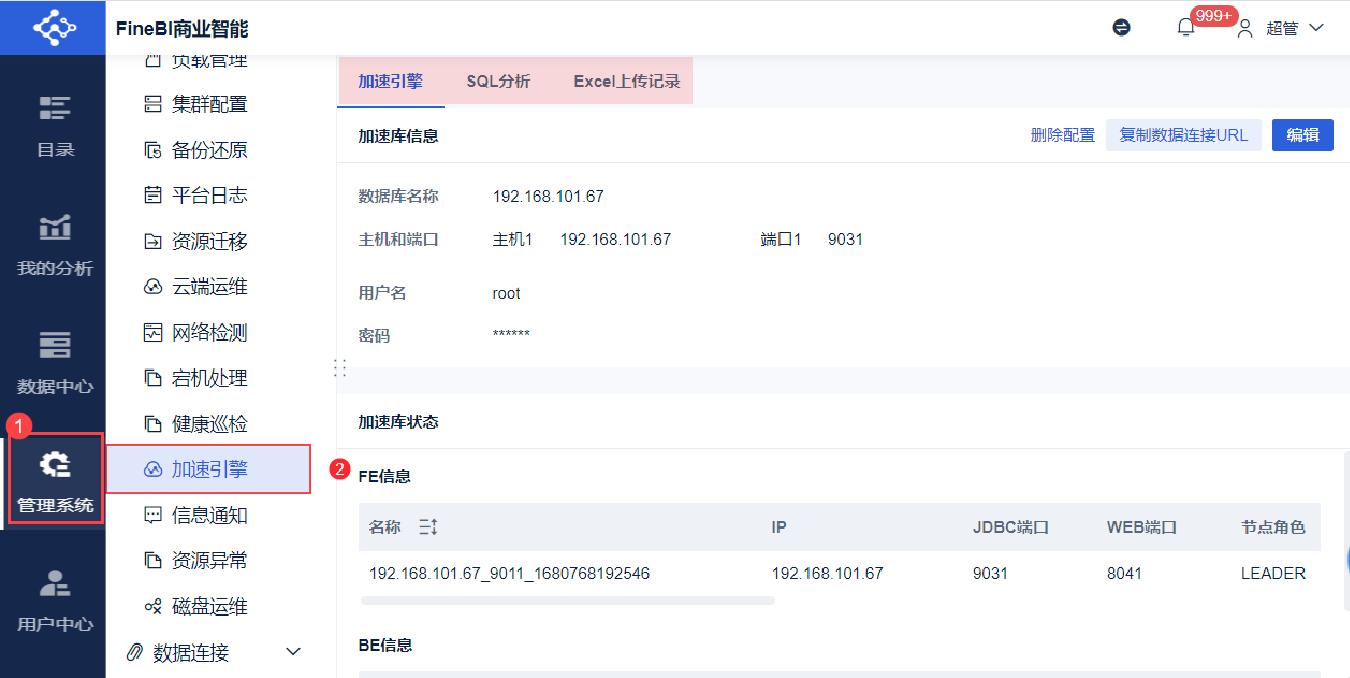
2.1 配置加速库
1)点击「加速引擎>添加加速库连接」,输入数据库的连接信息。连接成功后可保存,如下图所示:
注1:仅支持 StarRocks 数据库作为加速库。
注2:需要开放 StarRocks 中 FE 节点的 query_port ( 默认 9030) 、 http_port ( 默认 8030 ) 以及 BE 节点的 http_port ( 默认 8040 )。
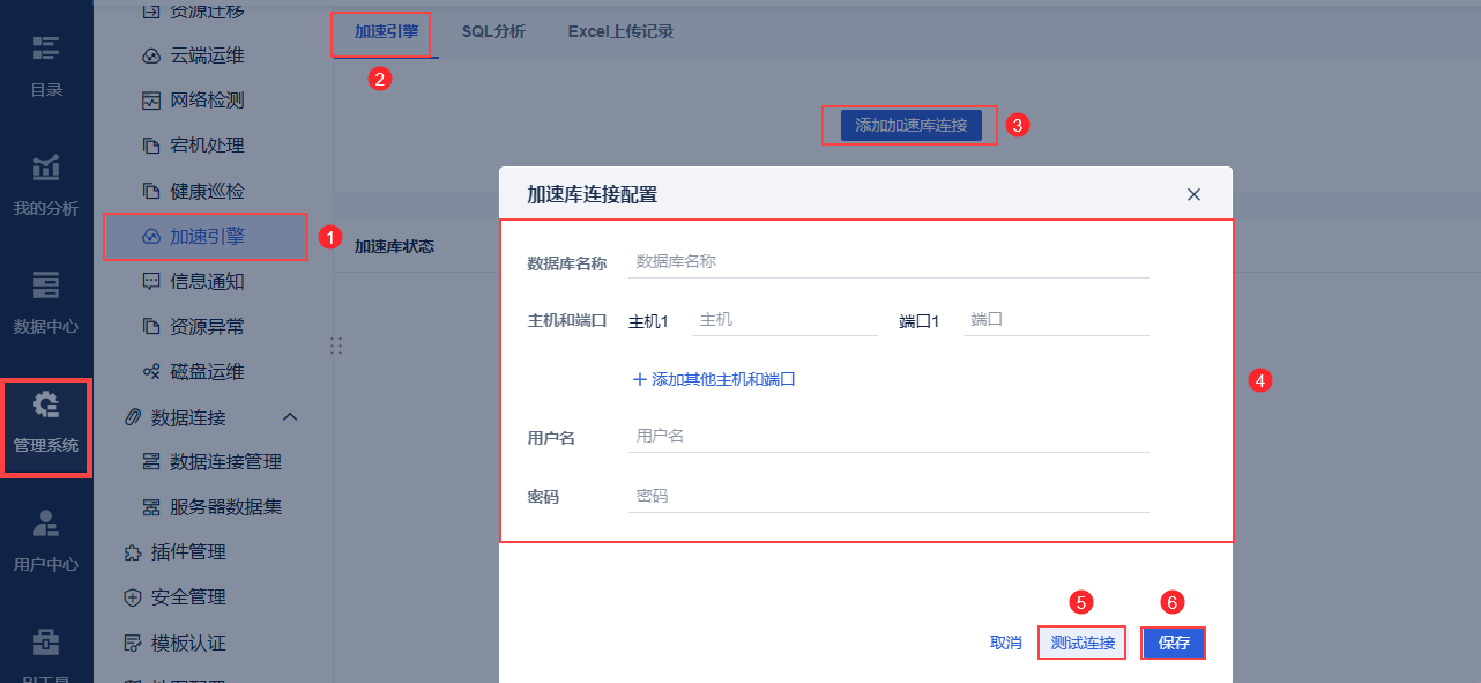
| 配置项 | 描述 |
|---|---|
| 数据库名称 | 输入数据库的名称 |
| 主机和端口 | 输入数据库所在的主机以及端口;若是集群,可以添加多个主机和端口 |
| 用户名/密码 | 输入数据库的用户名和密码 注:低于StarRocksV3.0:使用 root 用户; StarRocksV3.0及以上:用户需要拥有 OPERATE 权限。授权方式:GRANT OPERATE ON SYSTEM TO USER 'user_name'@'%' |
2)连接成功后,用户可以直接「复制数据连接 URL」,去「数据连接」中,输入该加速库的信息再新建一个数据连接。详情请参见:StarRocks 数据连接
3)若要对已配置好的加速库「删除」或「编辑」,也可以点击右上方按钮。
2.2 监控加速库状态
连接后, FineBI 会从加速库中获取节点状态信息,主要分为两个模块:
展示「加速库」集群中不同 FE 节点的状态信息:FE 负责处理和接收客户端的查询请求,并将这些查询请求转发给后端(BE)进行执行。FE 还负责查询解析、优化、权限控制、结果集返回等任务。
展示「加速库」集群中不同 BE 节点的状态信息:BE是负责实际执行查询操作的组件。它负责与存储引擎进行交互,读取和加载数据,执行查询计划,进行聚合和计算等操作,并将最终的结果返回给 FE 进行处理和返回给客户端。
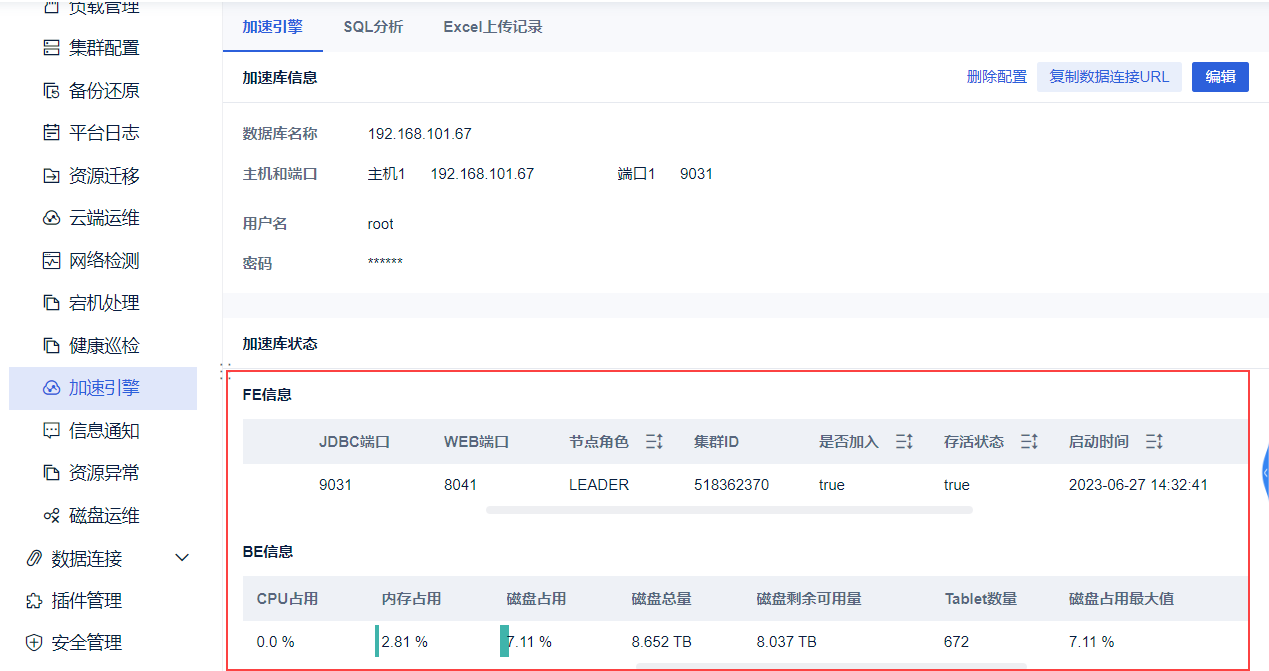
加速库状态展示如下信息
FE信息:名称、IP、JDBC端口、WEB端口、节点角色、集群ID、是否加入、存活状态、启动时间、最近心跳时间、错误信息
BE信息:BE ID、IP、启动时间、最近心跳时间、存活状态、CPU核心数、CPU占用、内存占用、磁盘占用、磁盘总量、磁盘剩余可用量、Tablet数量、磁盘占用最大值、数据文件占用大小、错误信息
3. SQL分析编辑
在 FineBI 分析数据时, FineBI 会发送查询的 SQL 给加速库。如果有 SQL 查询耗时较长(超过3s)或执行错误,就会被系统自动记录到「SQL分析」界面。帮助管理员/运维人员去定位问题,优化性能。
使用「SQL 分析」功能,需要提前在数据库中开启以下参数:
set global enable_profile = true;
ADMIN SET FRONTEND CONFIG ("enable_collect_query_detail_info" = "true");
-- 注意:FE 重启后参数会恢复成 fe.conf 文件中的配置或者默认值。
-- 若需要配置长期生效,建议设置完之后同时修改 fe.conf 文件,防止重启后修改失效。进入「加速引擎>SQL分析」 界面,用户可以对 SQL 按「状态、开始时间、耗时、用户」去进行筛选,如下图所示:
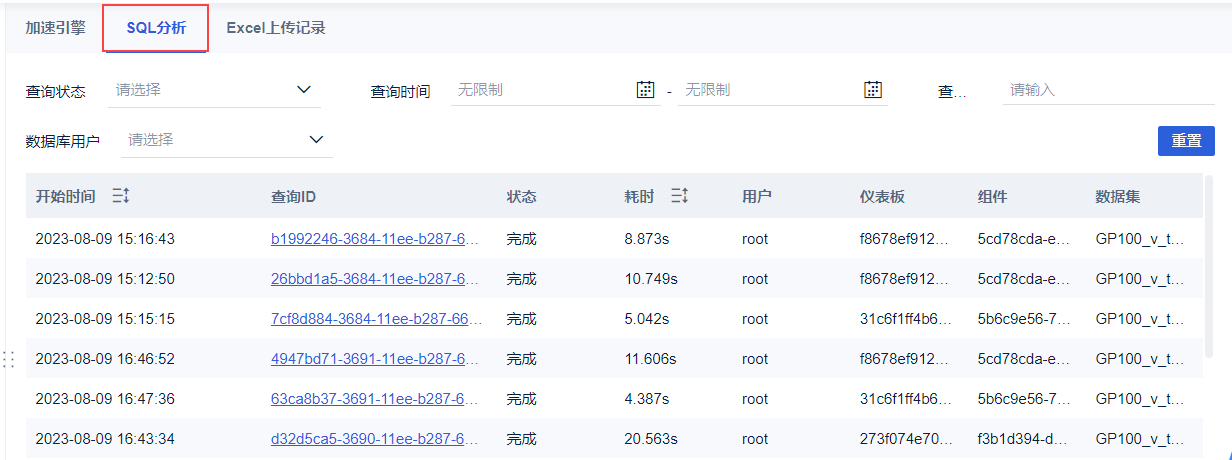
1)例如,我们筛选查询时间超过 10s 的 SQL。其中有一个耗时 57 秒的,我们可以双击「仪表板id、组件id、数据集id」后右键复制 id。再去「BI工具>查询>表名查询」中依据 ID 找到对应的数据表,或者去 配置数据集 中依据 ID 找到具体的仪表板、组件和数据集。
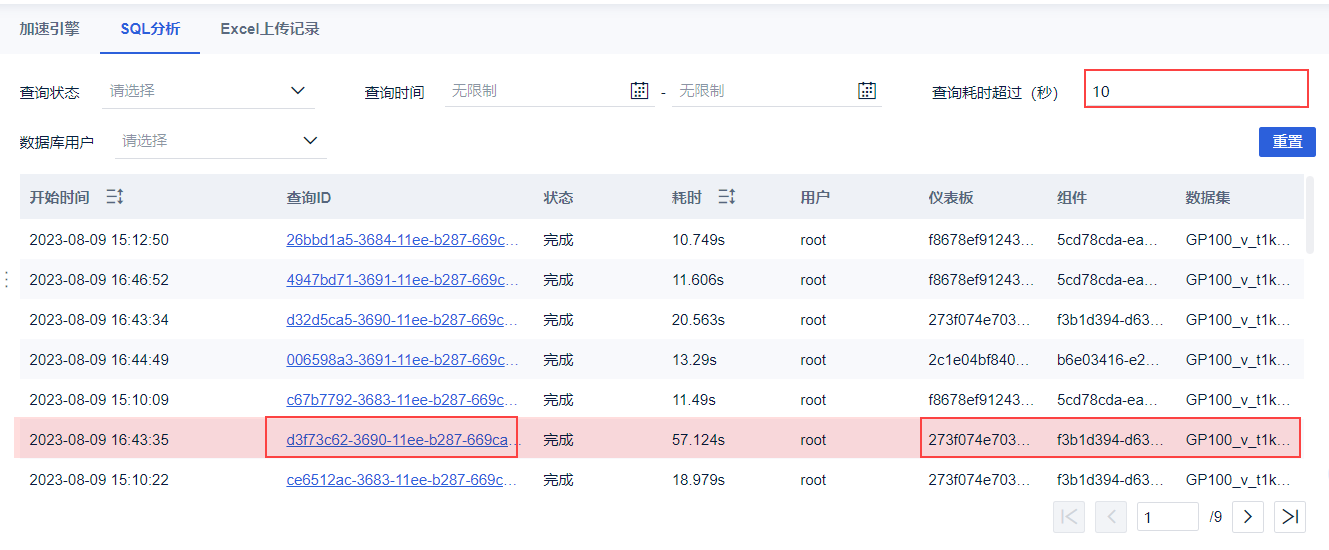
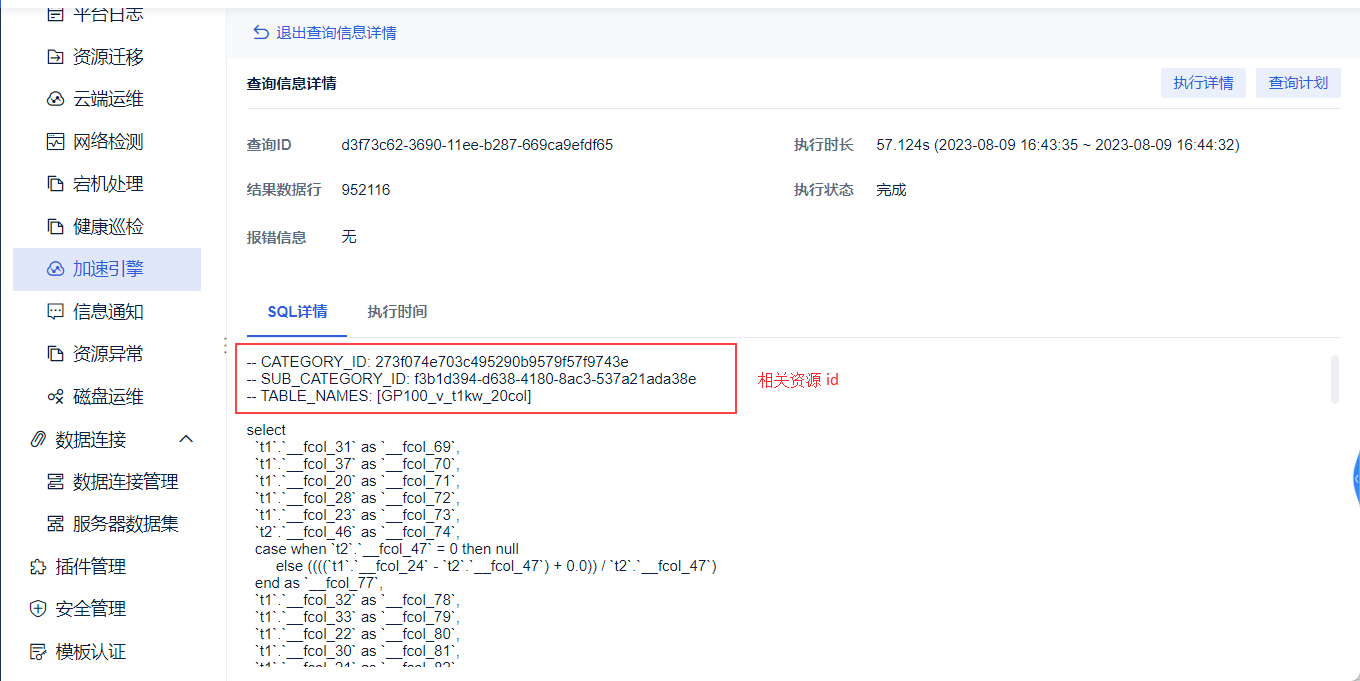
2)点击「查询 ID」进入查询信息详情界面。我们在「SQL详情」还可以看到这条 SQL 具体执行的语句。
在 SQL 语句的最上方,也标注了 BI 相关的资源。
| 资源 id 名字 | 含义 |
|---|---|
| CATEGORY_ID | 仪表板id |
| SUB_CATEGORY_ID | 组件id |
| TABLE_NAMES | 数据集id |
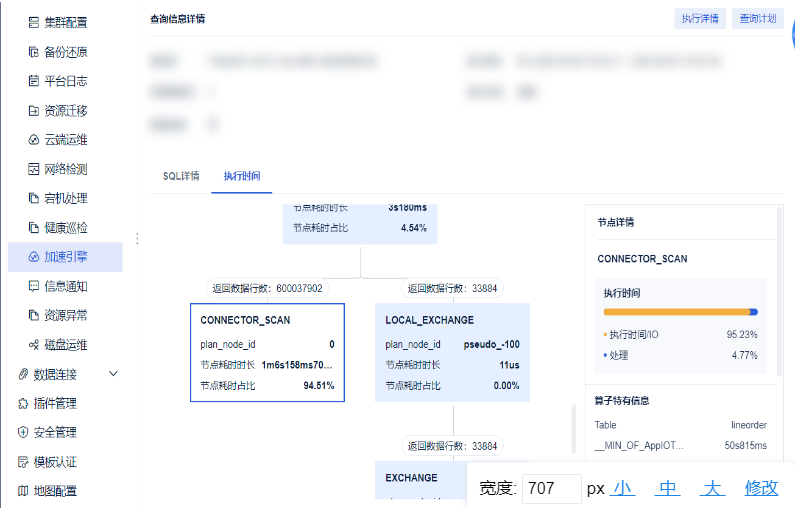
3)点击「执行时间」,即可看到每个算子的类型、耗时、耗时占比以及每个节点返回的数据行数,帮助我们排查慢速的原因。
比如说我们点击一个耗时占比比较大的算子之后,即可看到具体的节点详情。
「执行时间 I/O」与「处理」占该算子总时间的占比
该算子特有信息
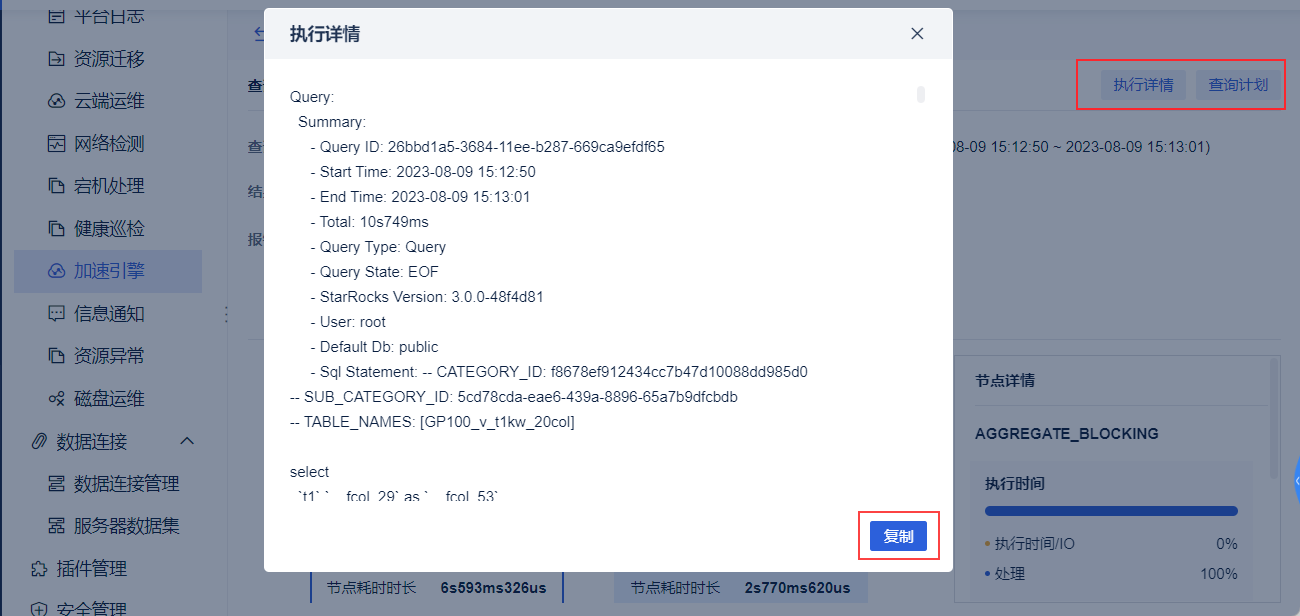
4)查看「执行详情」和「查询计划」
执行详情:是「执行时间」的语句化,可以复制到文本文件进行查看。比如说一些内网用户需要让外网人员帮忙排查执行速度,就可以复制「执行详情」的语句发送给外网人员。
查询计划:主要提供给 DBA 查看,查看「查询计划」可以帮助 DBA 深入了解查询的执行细节和性能特征,帮助进行性能优化、资源管理和故障排除,以提高数据库系统的整体性能和稳定性。
4. Excel上传记录编辑
正常直连数据模式下,上传到 FineBI 的 Excel 与数据库表的融合分析会受到限制:
原先使用 Insert Into 方式上传 Excel ,上传性能不佳,上传速度慢。
Excel 数据不能超过 1w 条,分析受限。
管理员无法知道哪些 Excel 已被使用,哪些上传的 Excel 未被使用,不方便对 Excel 管理。
对此, FineBI 优化了 Excel 与加速库中的数据库表联合分析的体验。
只要在 FineBI 中配置了加速库,系统会自动在 加速库 里创建 fine_bi_crossdata 库。这时候我们在 FineBI 中上传直连Excel 时,系统会自动使用 Excel 文件在 fine_bi_crossdata 中建表 。如此,我们在使用加速库中的数据库表与 Excel 进行融合分析时,不再受到上面三条限制项影响。
用户可以进入「Excel上传记录」查看「源文件、数据库表、FineBI表名」三者之间的对应关系。
并且可以根据「表名」和「更新时间」查找自己想要的表。
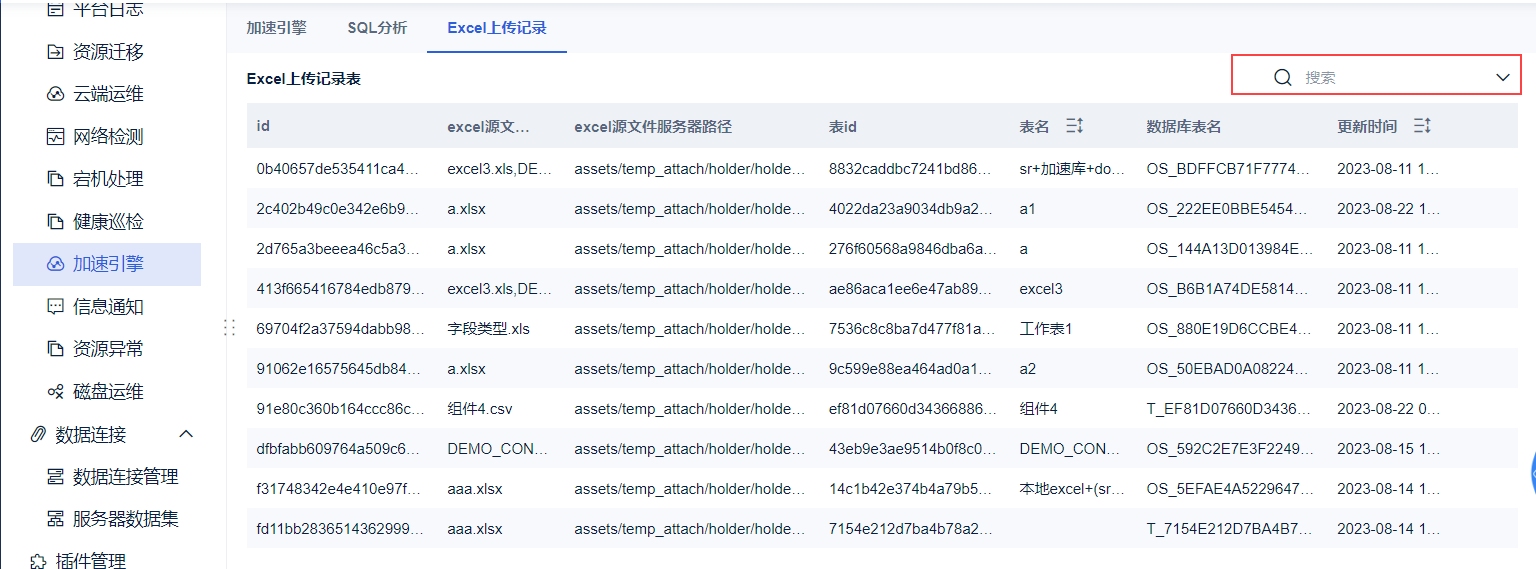
| 表头 | 描述 |
|---|---|
| excel源文件名 | Excel 源文件的名字 |
| Excel源文件服务器路径 | Excel 上传 FineBI 后,源文件在服务器的存储地址 |
| 表id | Excel 在 FineBI 中的表 id |
| 表名 | Excel 在 FineBI 中的名字 |
| 数据库表名 | 系统用该 Excel 在 fine_bi_crossdata 中建立的表名 |
| 更新时间 | Excel 在 FineBI 的更新时间 |