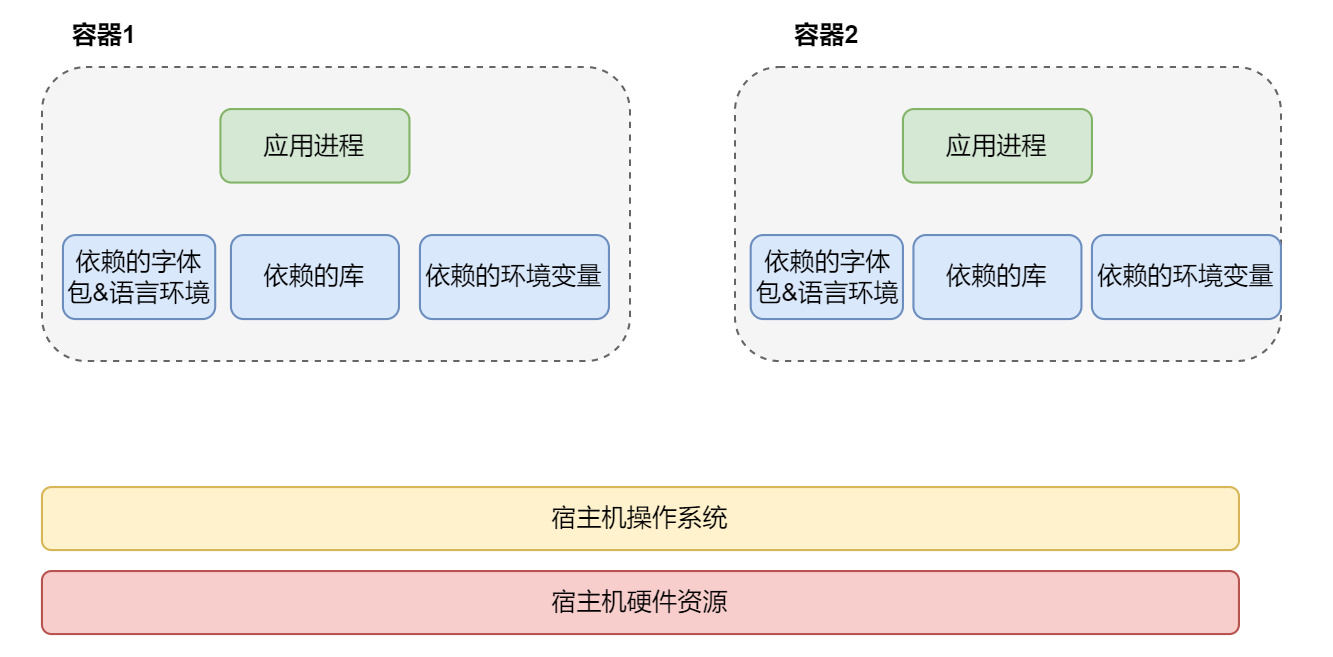
如果将 Linux 比作一个厨房,那么Docker技术就像是预制菜品。
厨房可以从中央厨房(云镜像仓库)订购真空包装的食品(镜像),并存储在自己的冰柜中(本地镜像仓库)。
厨师(运维人员)可以将这些预制的真空包装食品(镜像)经过简单的操作变成一道道菜品(容器),供顾客“享用”(服务)。
Docker的三大特色1)镜像(Image):类似于一个安装包,通过这个安装包来创建容器。
2)容器(Container):利用容器技术,独立运行一个或一组应用,可以通过镜像创建多个容器。容器可以理解为一个简易的Linux系统。
3)仓库(Repository):存放镜像的地方,分为公有仓库和私有仓库,如Docker Hub、阿里云、Harbor等。
通过Docker,企业可以实现更加高效和灵活的系统管理,提升服务的稳定性和可维护性。