1. 概述编辑
1.1 应用场景
公司内部使用北森系统进行人员管理。
希望将 根据时间窗滚动查询变动的员工与单条任职信息 中的人员信息数据取出,以便进行数据分析。
1.2 接口说明
接口文档详情参见:根据时间窗滚动查询变动的员工与单条任职信息
1.3 实现思路
1)获取 access_token,并设置为参数,便于后续认证使用。
2)设置开始时间和结束时间作为参数,便于后续进行接口取数。
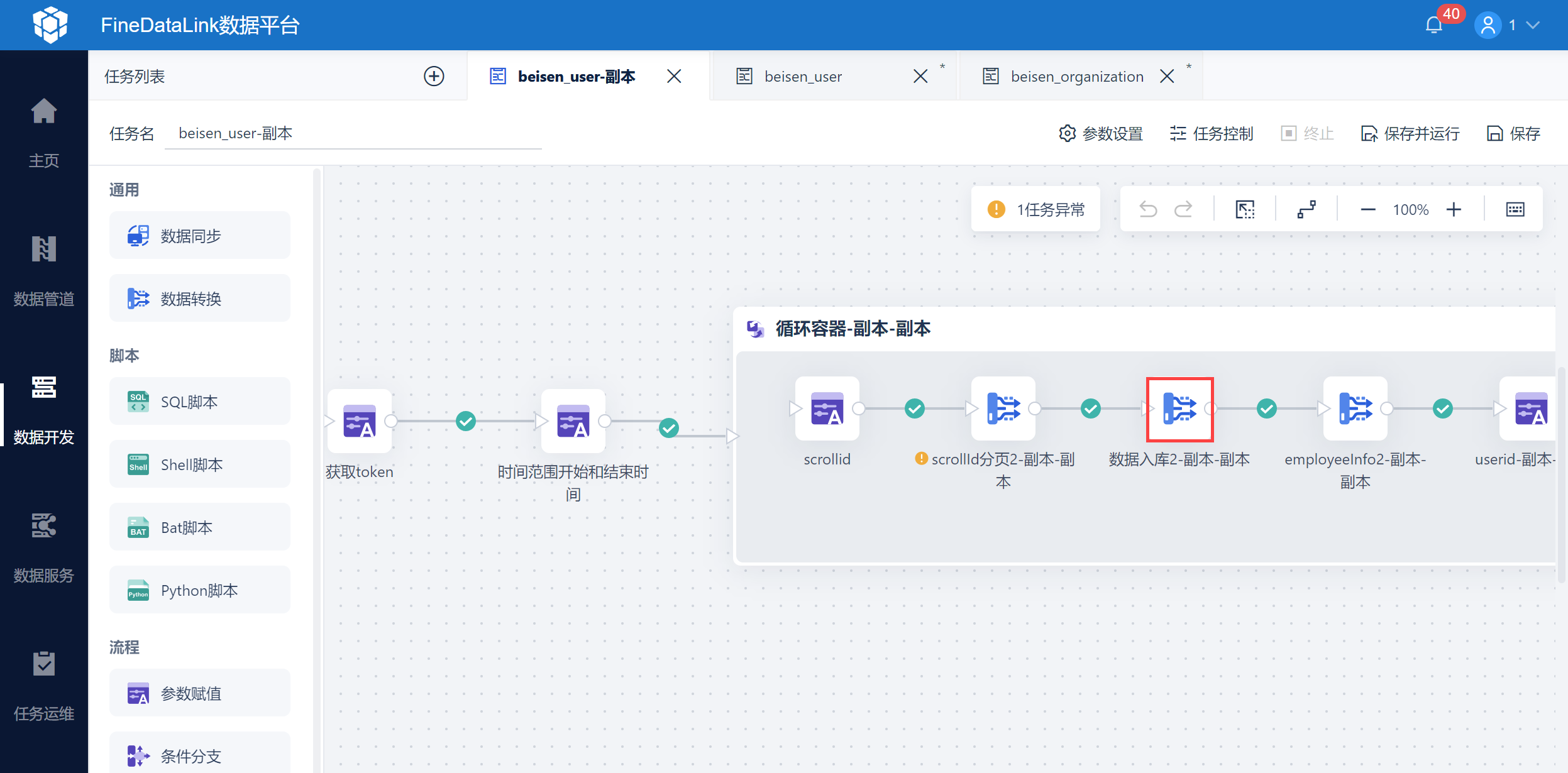
3)循环容器滚动取数,由于北森用户接口一次只返回100条数据,因此需要通过分页参数 scrollid 查询下页数据,先使用接口取出 scrollId 分页数据到中间表中。
使用分页参数再次调用接口取出员工的任职信息;
再次调用接口,获取用户 userid 作为循环取数的停止条件,即当 userid 为空时,停止循环取数。
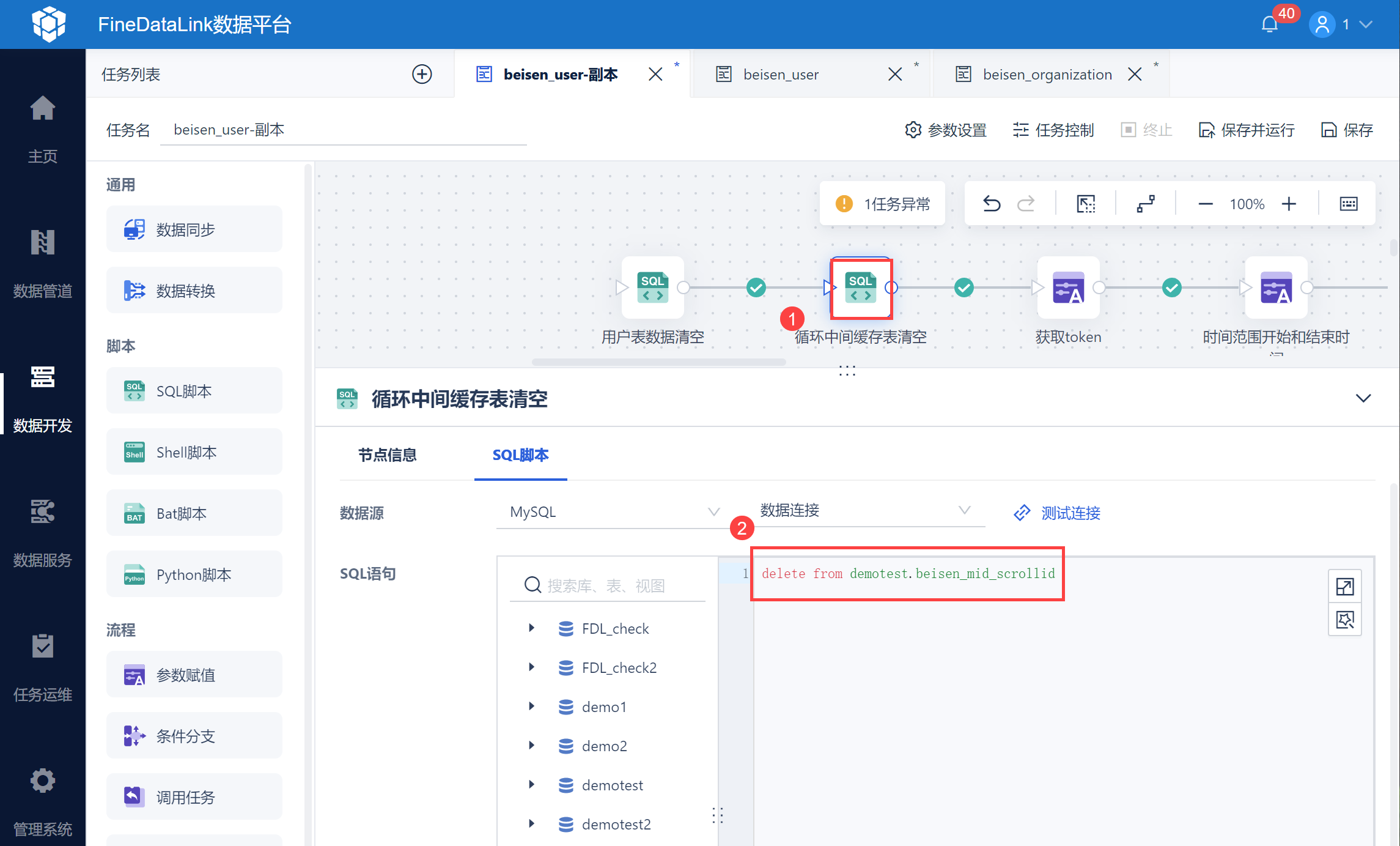
4)最后,由于每次同步都需要全量同步,因此需要在任务的最前面新增两个脚本。清空用户表 beisen_user 和中间表 beisen_mid_scrollid。
2. 操作步骤编辑
2.1 获取 access_token
access_token是调用北森API接口的唯一凭证,相当于创建了一个登录凭证,其它的业务API接口,都需要依赖于access_token来鉴权调用者身份,使用Key和Secret可获取access_token。
参考北森接口文档:https://open.italent.cn/#/open-document
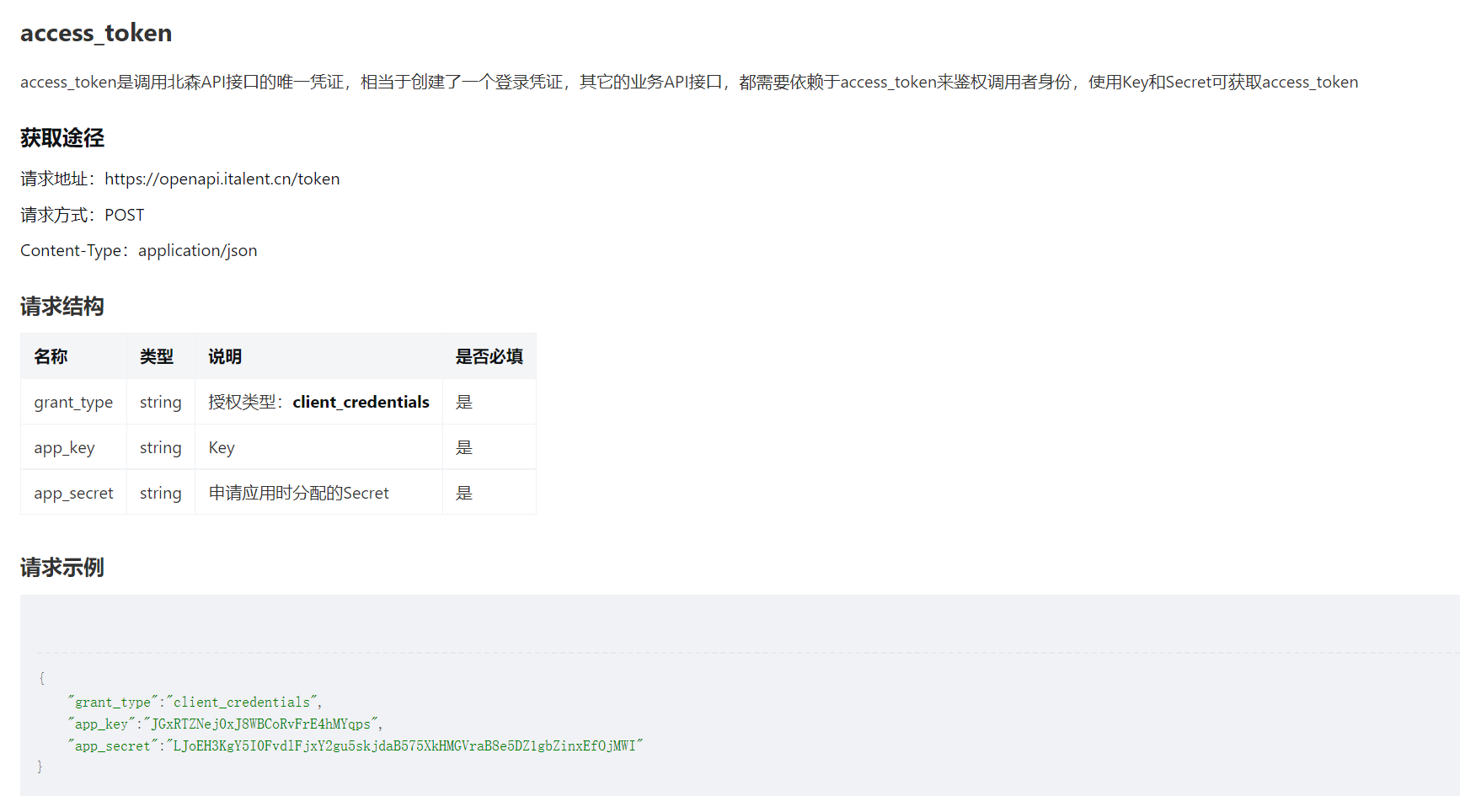
因此需要调用北森获取 token 接口,便于在后续调用获取用户信息接口时使用。
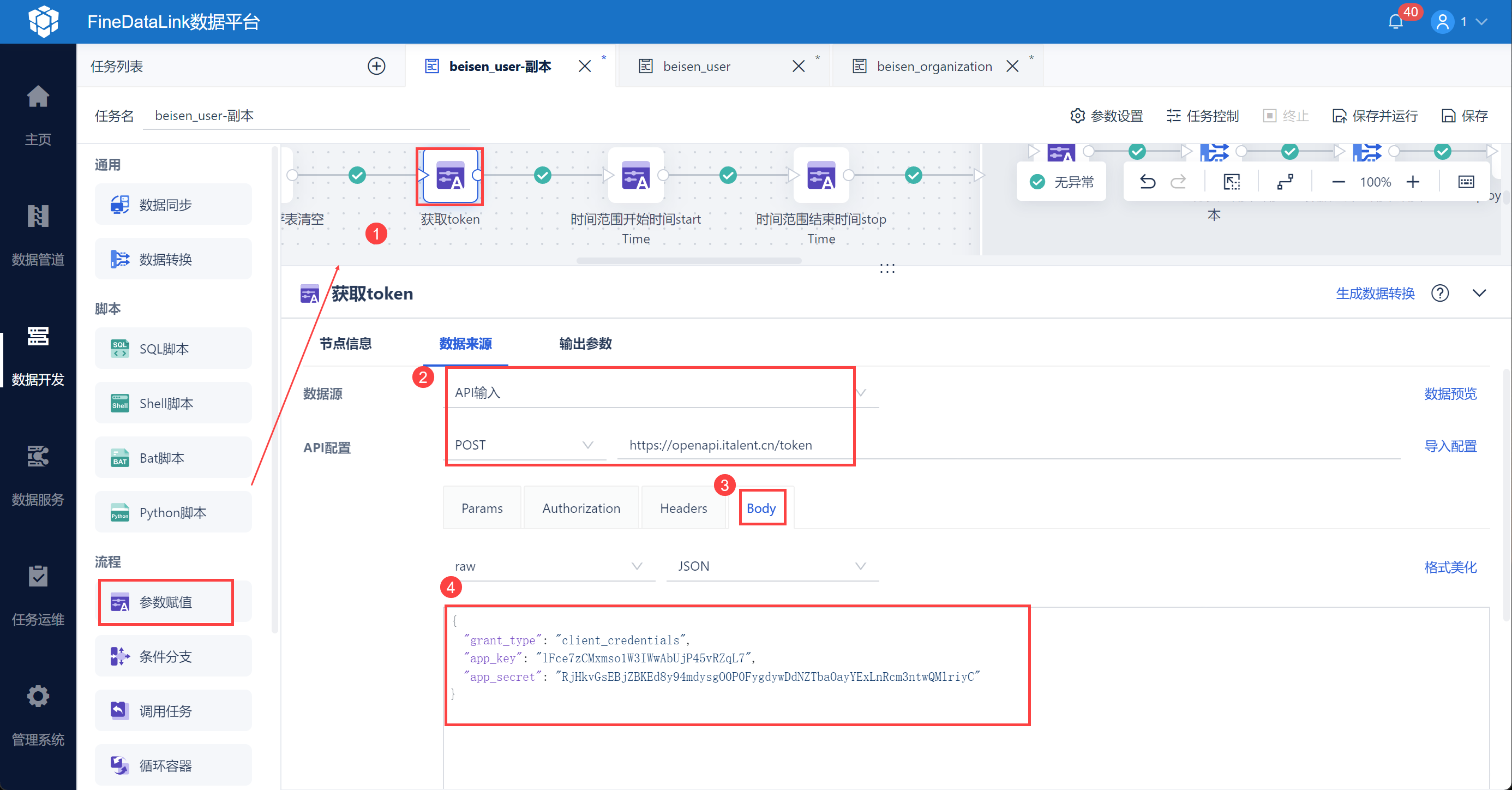
使用「参数赋值」节点,输入按照接口文档选择请求方式、输入 URL、在 Body 中输入请求,如下图所示:
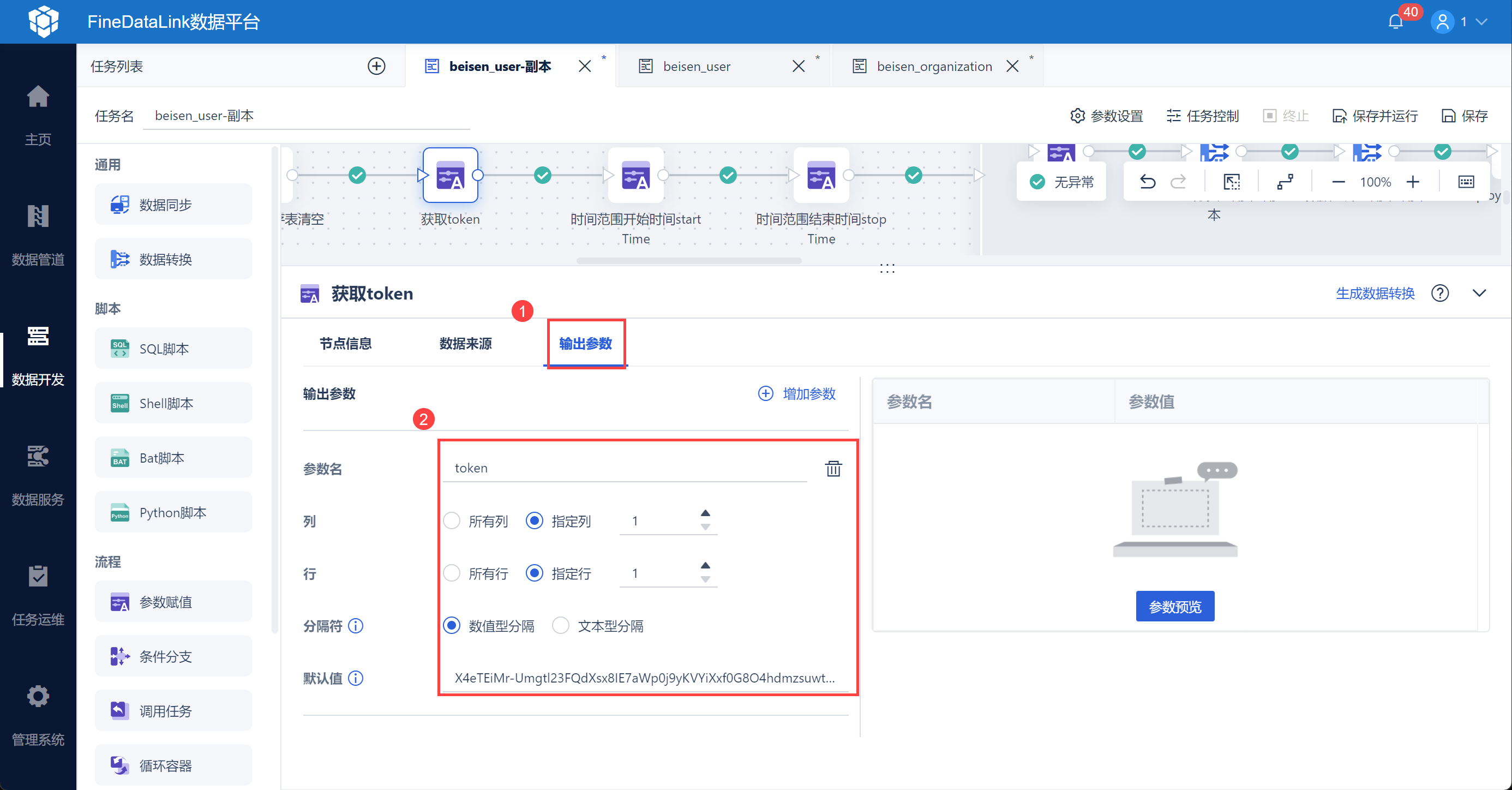
将获取到的 token 设置为参数,便于后续使用,如下图所示:
2.2 设置时间参数
由于根据时间窗滚动查询变动的员工与单条任职信息接口有「startTime」和「stopTime」必填请求参数,因此需要设置时间参数,动态生成时间,开始时间默认前 60 天(可自定义),结束时间为当天,保证每次查询用户数据为全量。
使用「参数赋值」设置时间范围开始时间为当前时间前 60 天(可自定义),结束时间为当天,如下图所示:
注:示例使用 MySQL 数据库,用户需要根据实际情况修改 SQL 语句。
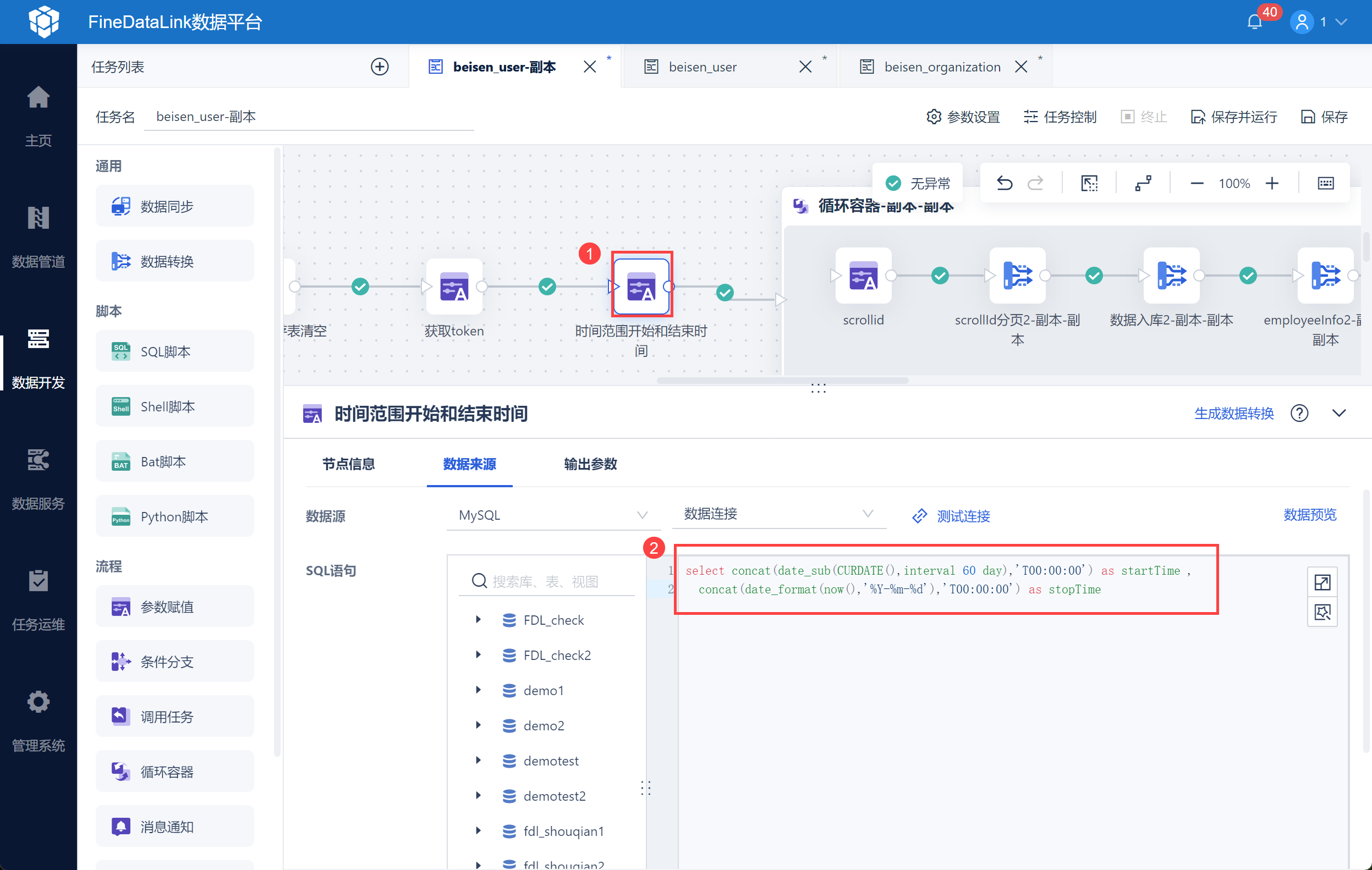
select concat(date_sub(CURDATE(),interval 60 day),'T00:00:00') as startTime ,
concat(date_format(now(),'%Y-%m-%d'),'T00:00:00') as stopTime
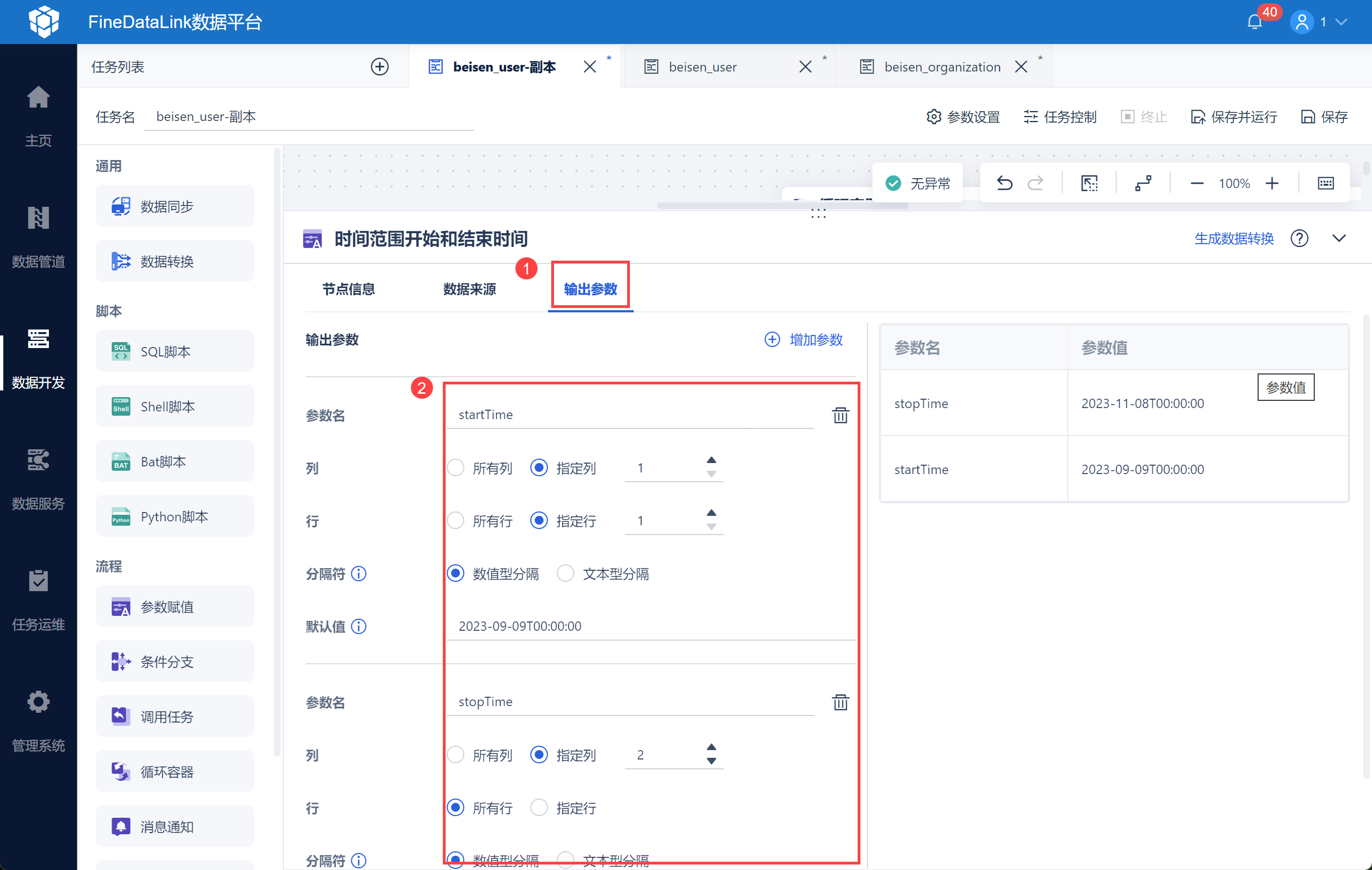
然后分别「startTime」和「stopTime」将设置为参数,如下图所示:
2.3 循环容器滚动查询全量数据
2.3.1 设置 scrollId 分页参数和中间表
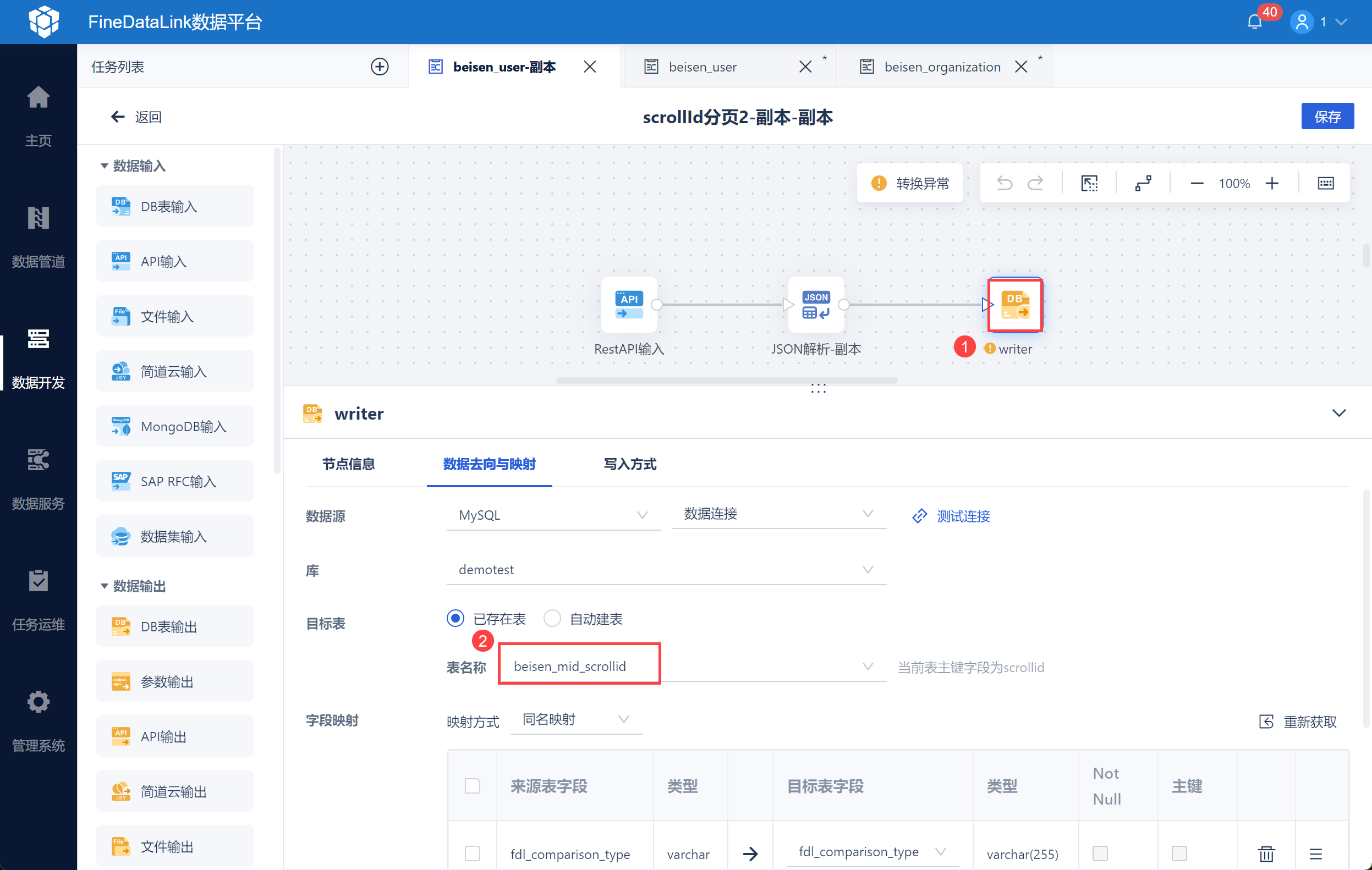
由于北森用户接口一次只返回 100 条数据,因此需要通过分页参数 scrollid 查询下页数据,使用中间表 beisen_mid_scrollid 将 scrollid 记录下来。
因此需要在数据库中新建中间表 beisen_mid_scrollid ,设置文本字段 code、scrollid、userid。
然后查询 scrollId,中间表中的 scrollId 数据,其中第一次循环 scrollId 为空,与接口取数逻辑一致。
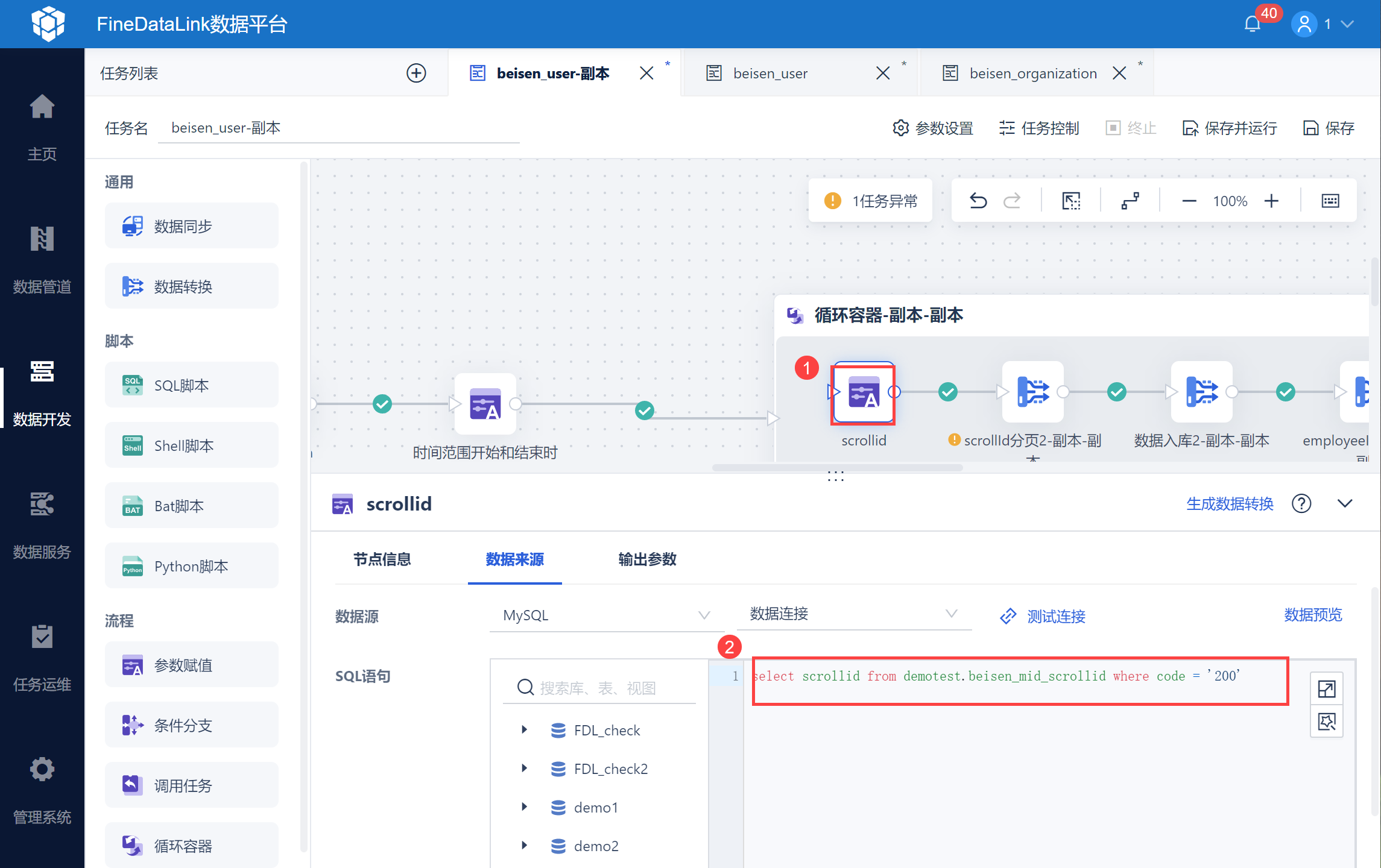
然后将滚动查询中的 scrollId 分页参数写入到中间表中,以便滚动循环取数。
在循环容器中拖入「数据转换」,并进入编辑界面,如下图所示:
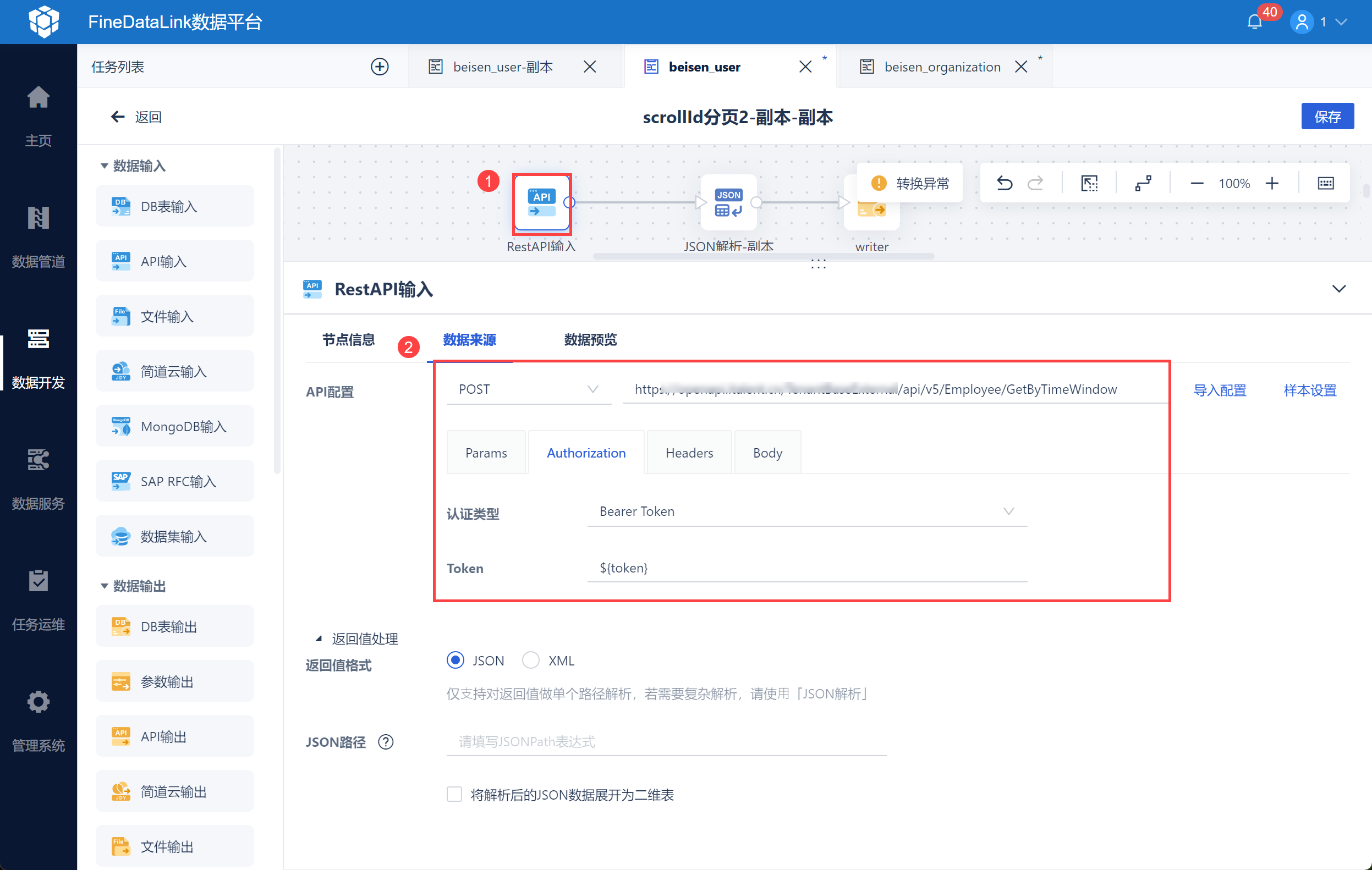
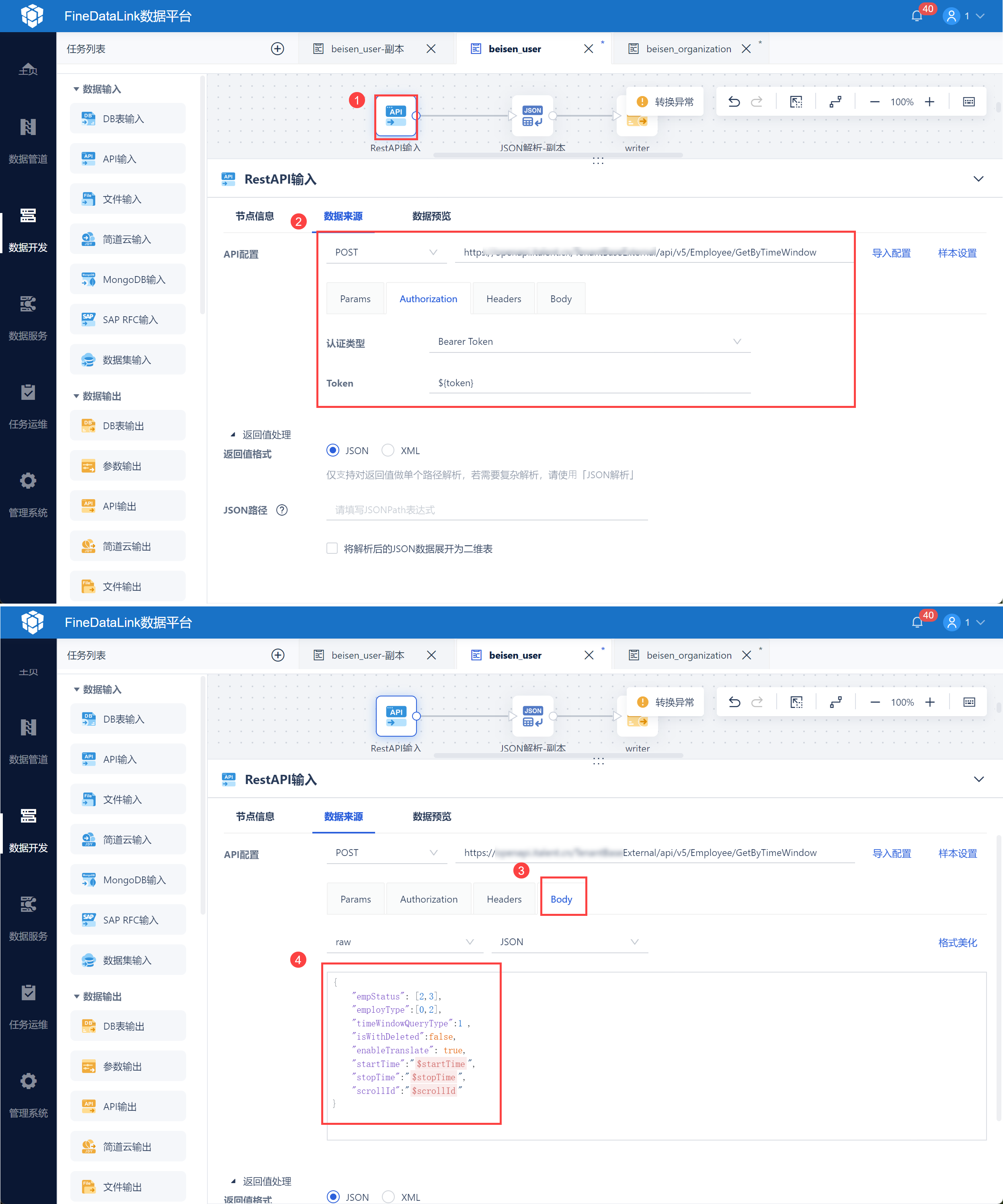
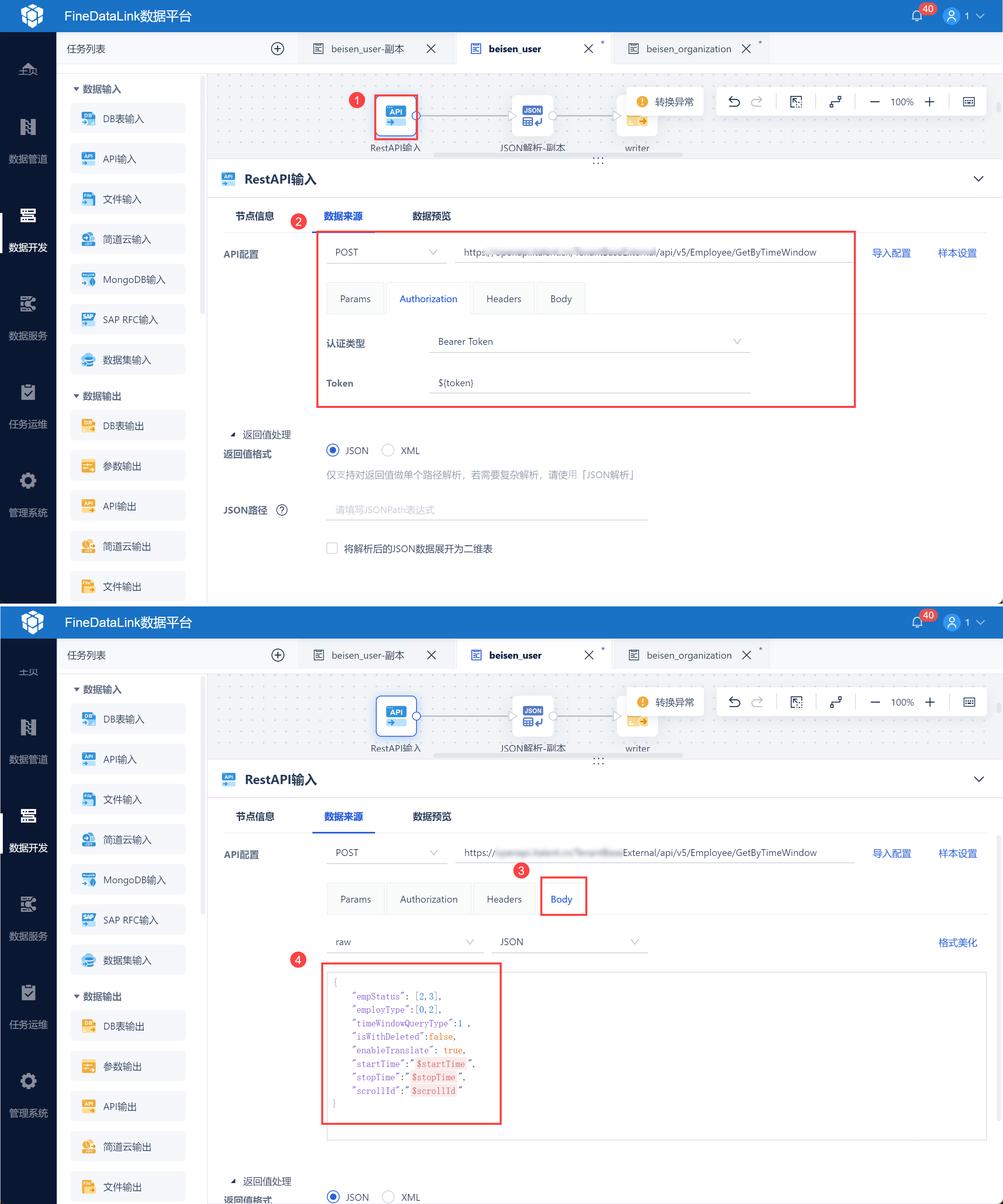
使用 API 输入,输入用户信息接口 url,并设置认证类型,引用 2.1 节获取的 access_token 参数,如下图所示:
然后再 Body 中输入请求参数,如下图所示:
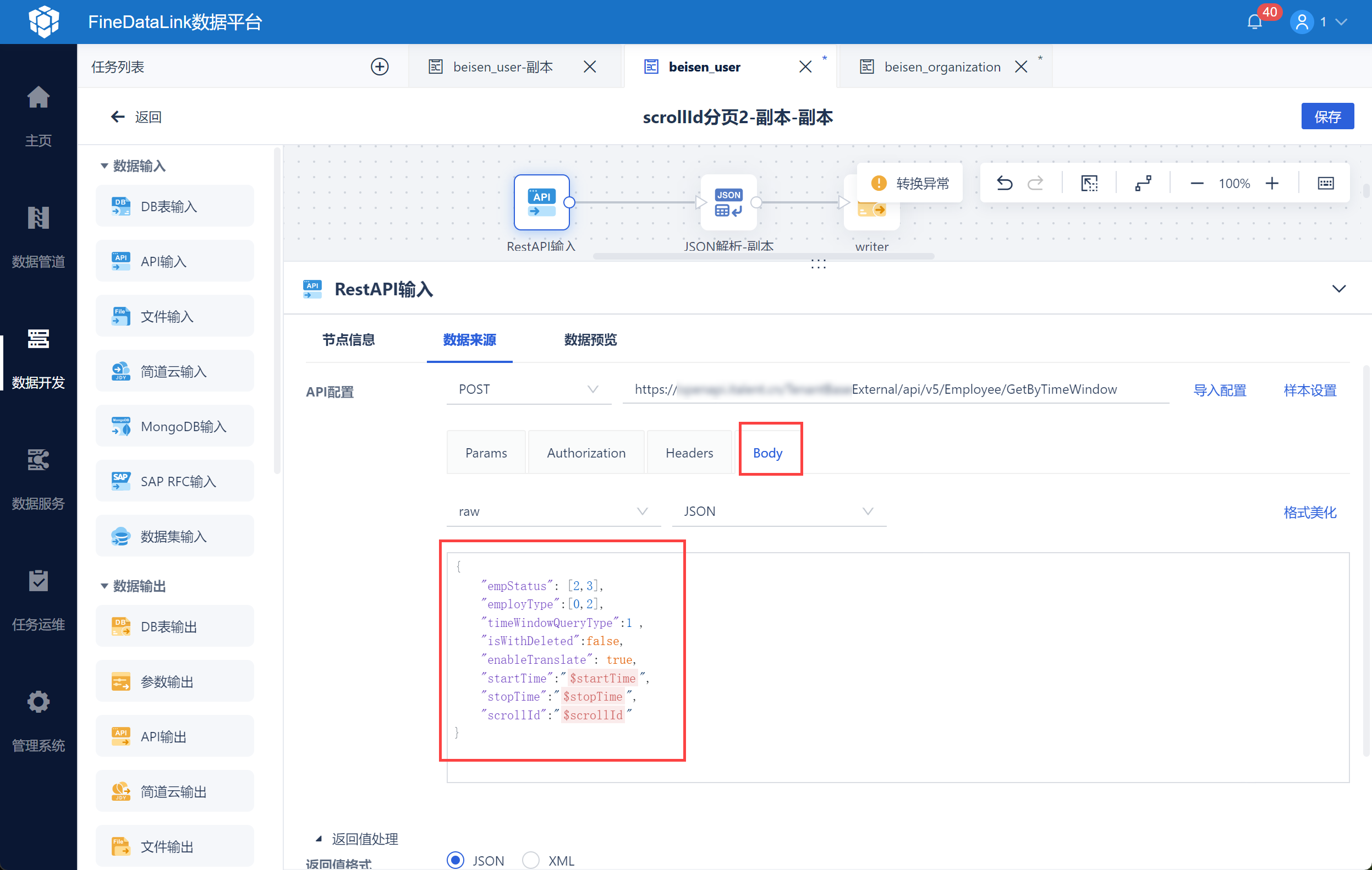
{
"empStatus": [2,3],
"employType":[0,2],
"timeWindowQueryType":1 ,
"isWithDeleted":false,
"enableTranslate": true,
"startTime":"${startTime}",
"stopTime":"${stopTime}",
"scrollId":"${scrollId}"
}
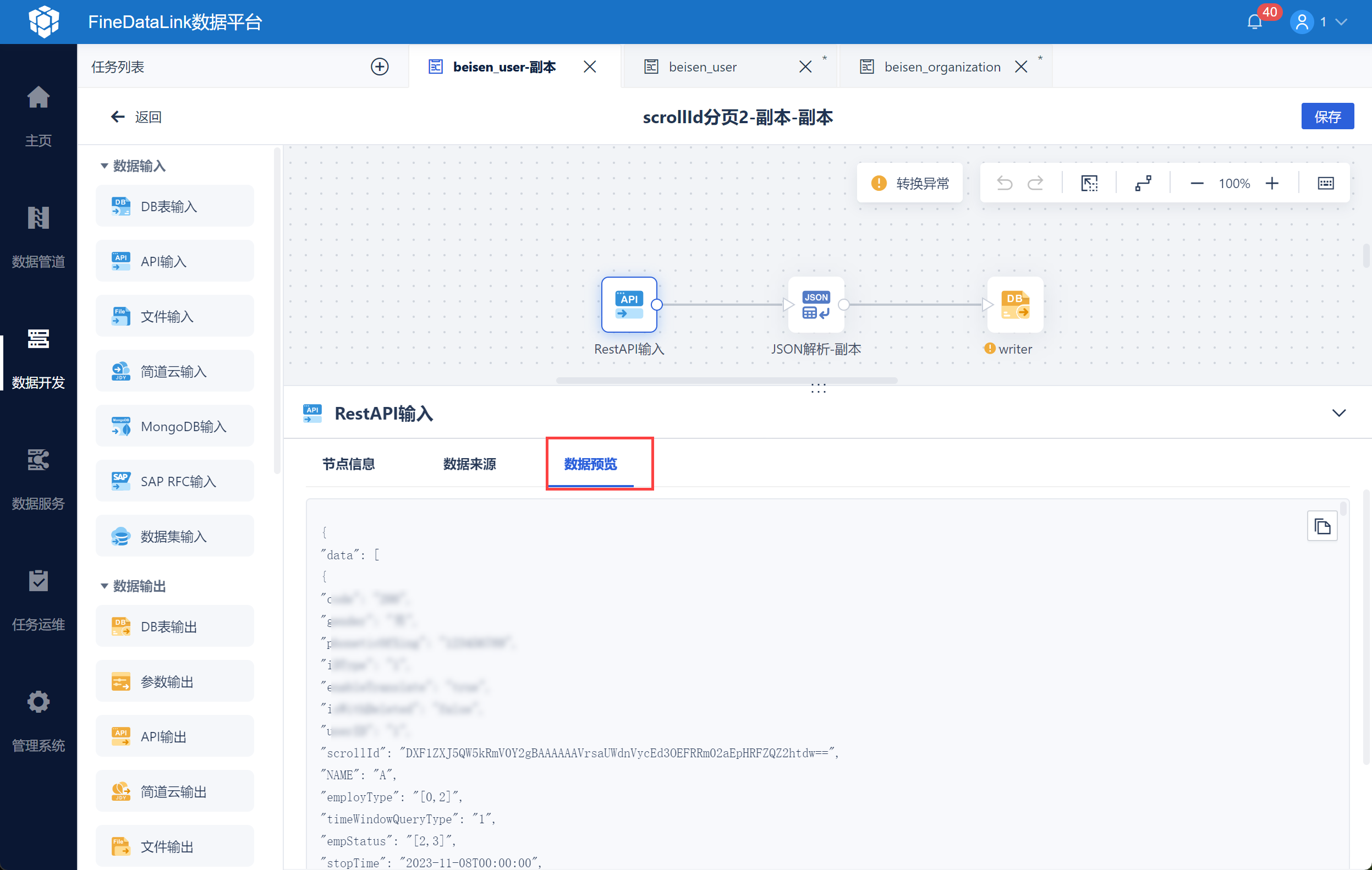
点击数据预览即可看到取出的数据,如下图所示:
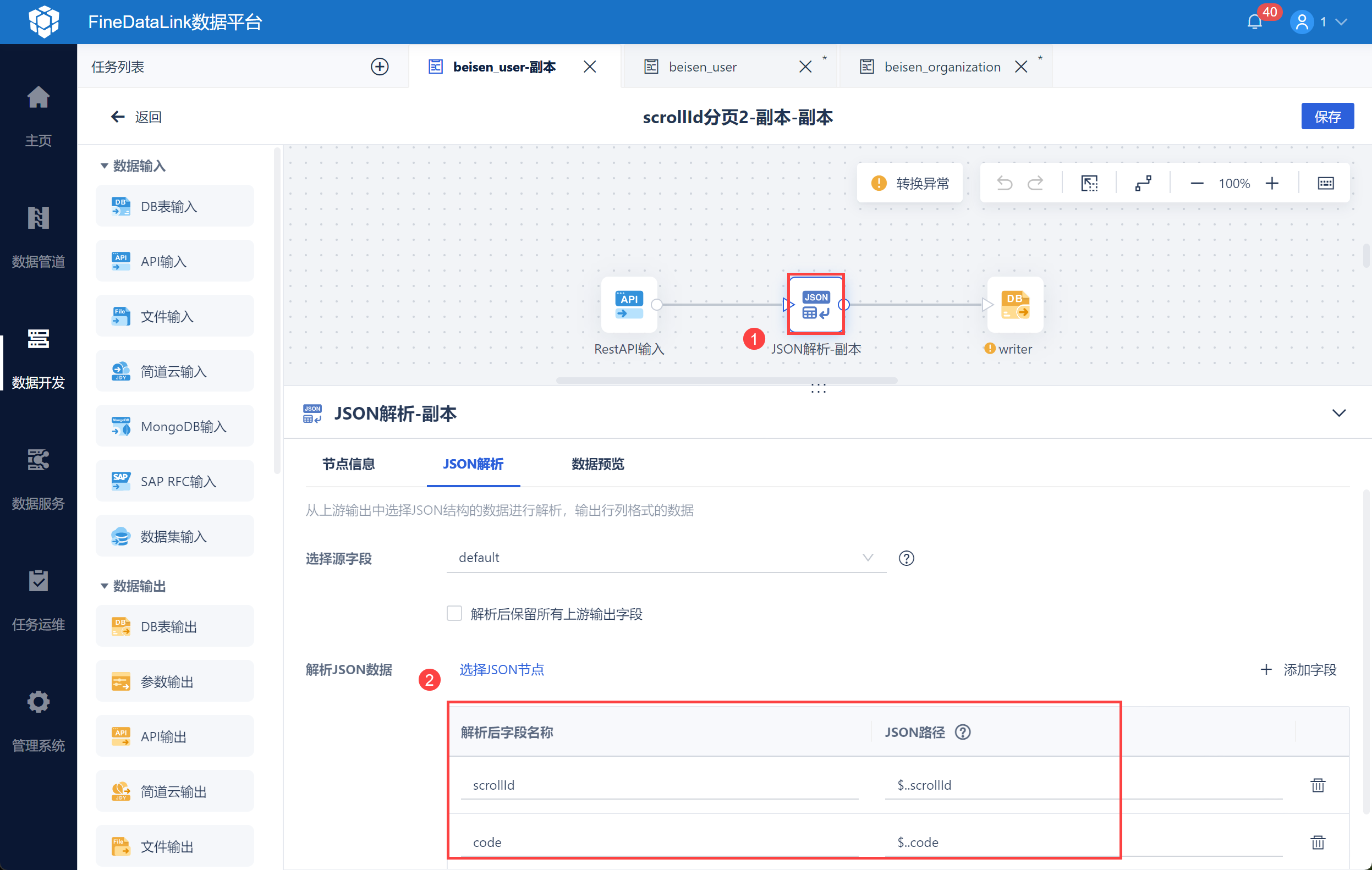
然后使用 JSON 解析,将分页数据 scrollId 和 code 字段解析,并写入至中间表 beisen_mid_scrollid 中,便于后续使用分页参数获取下一页的 scrollId,如下图所示:
然后使用将数据写入中间表「beisen_mid_scrollid」,如下图所示:
2.3.2 使用分页参数取出用户数据
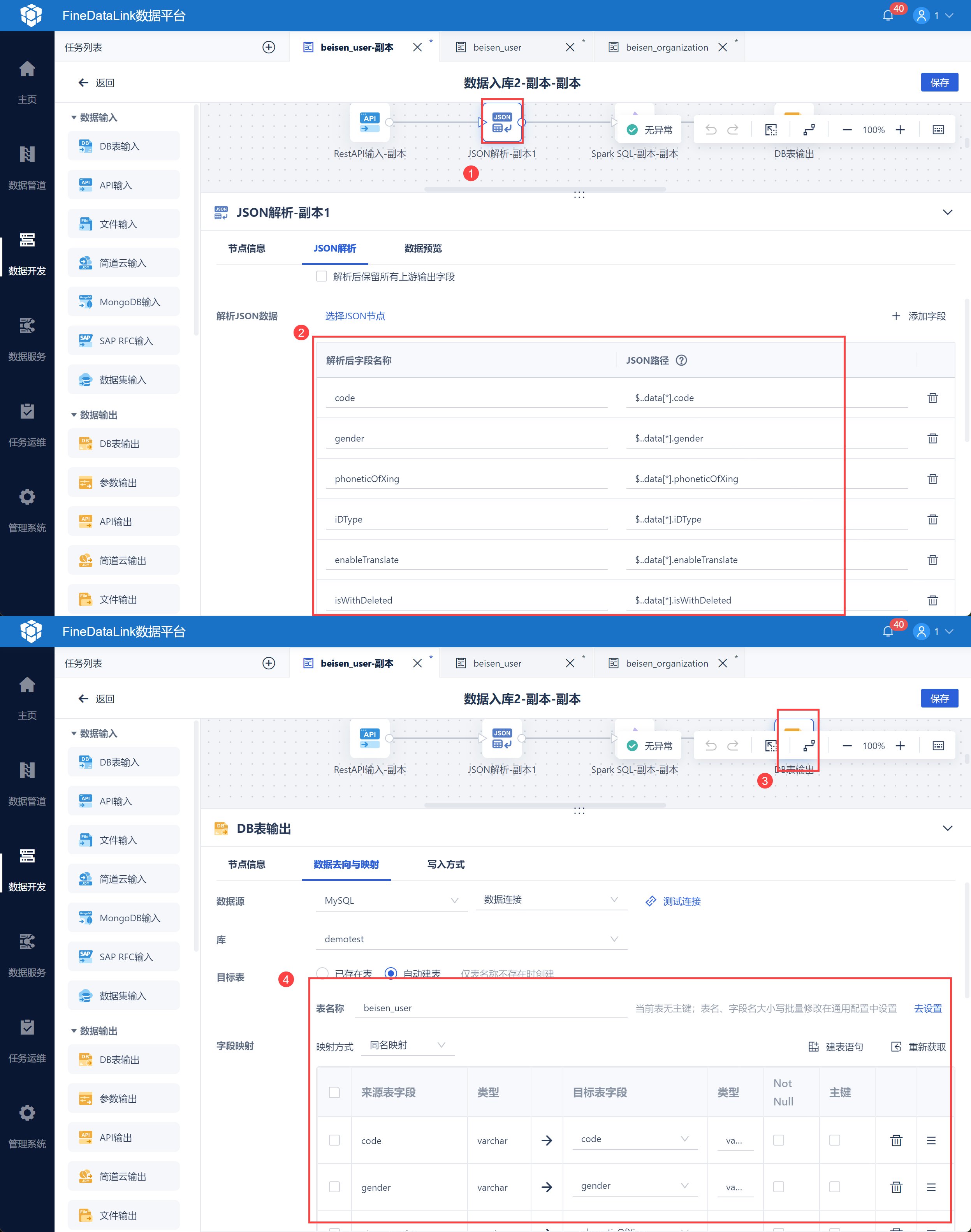
查询北森用户接口,将数据写入到用户表 beisen_user 中。
在循环容器中新建数据转换,如下图所示:
同 2.3.1 节的 API 输入,将token和请求写入,如下图所示:
使用 JSON 解析,将用户的员工信息数据解析并写入最终的数据库中,如下图所示:
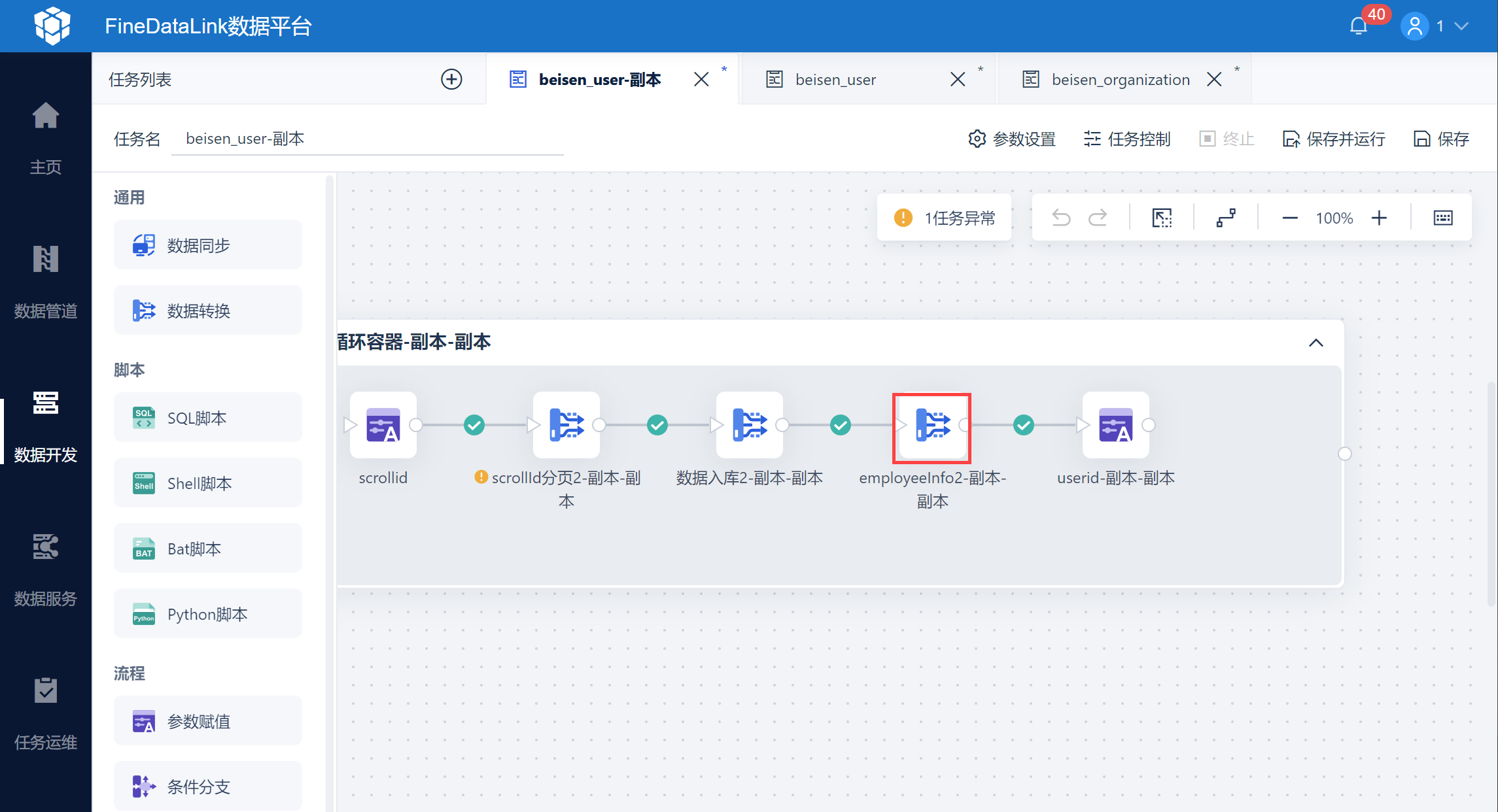
2.3.3 获取 userid 作为判断是否停止循环取数的依据
将用户名 userid 字段更新到中间表中,用户 userid 作为循环结束的标志,若用户id为空,则代表循环结束。
在循环容器中拖入数据转换,如下图所示:
同 2.3.1 节的 API 输入,将 token 和请求写入,如下图所示:
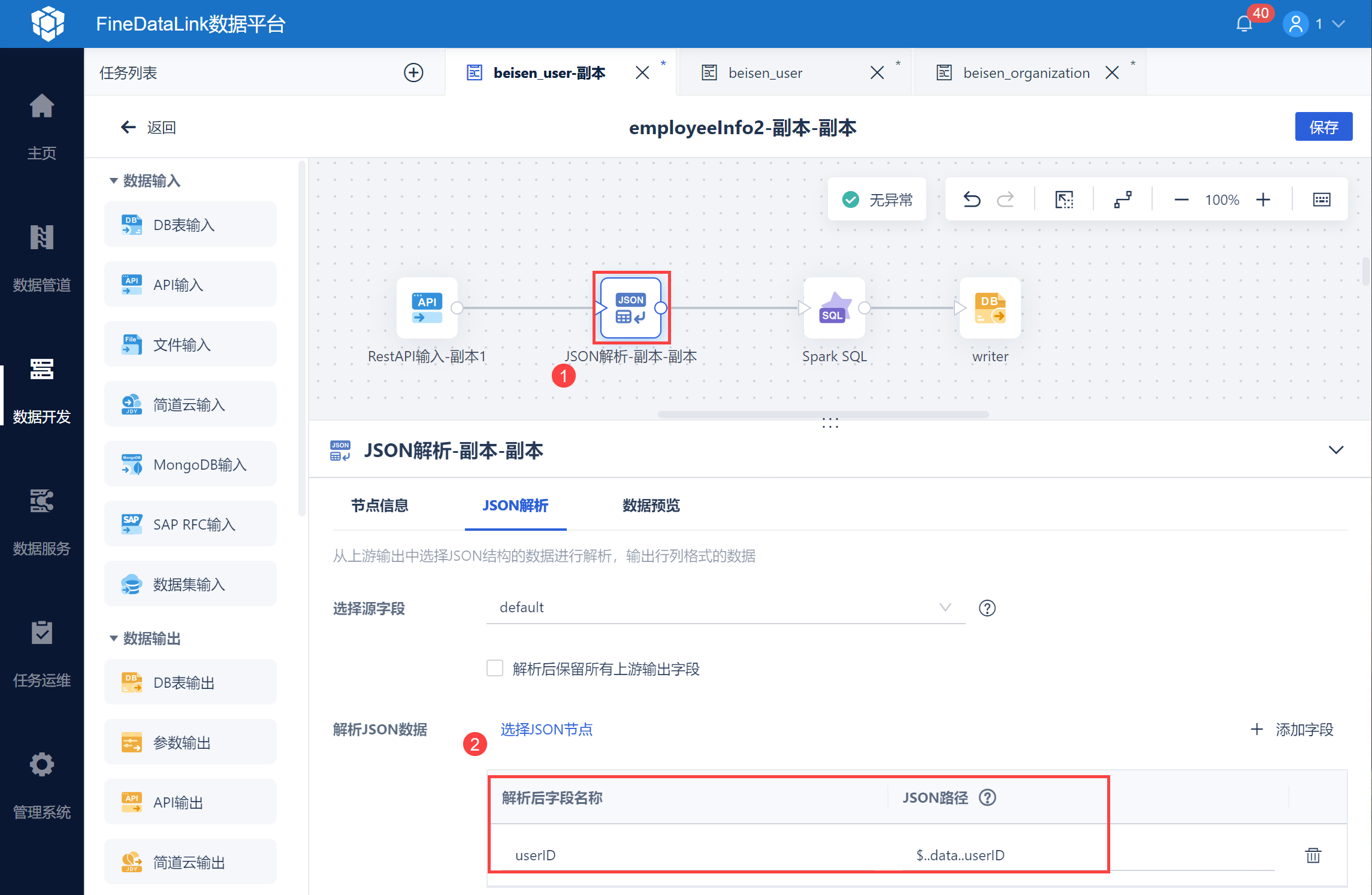
使用 JSON 解析将 用户 userid 解析出来,并写入中间表 beisen_mid_scrollid ,如下图所示:
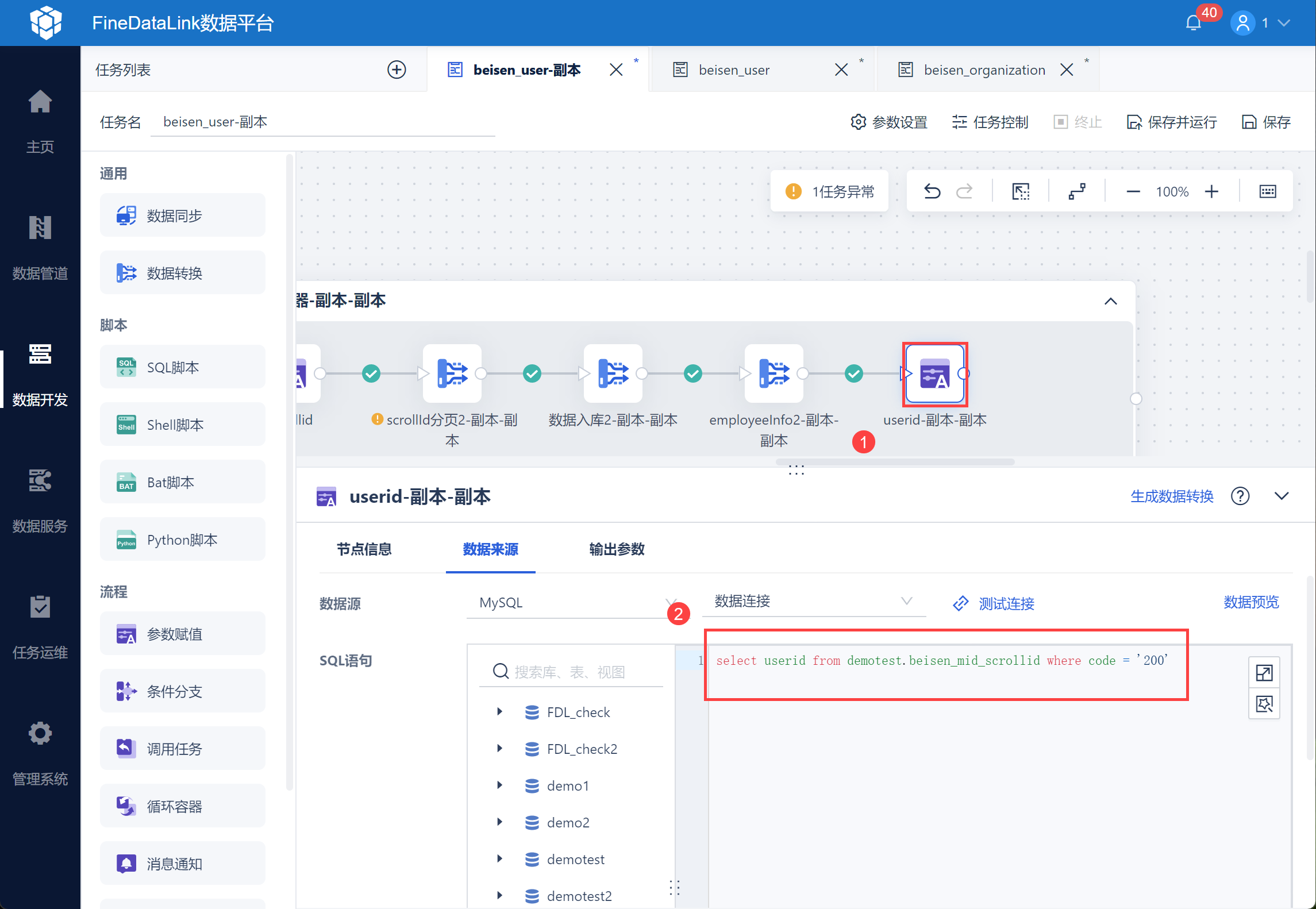
将写入到中间表中的用户 userid,作为参数输出,以便后续在循环容器中判断是否用户 userid 为空。
设置为参数:
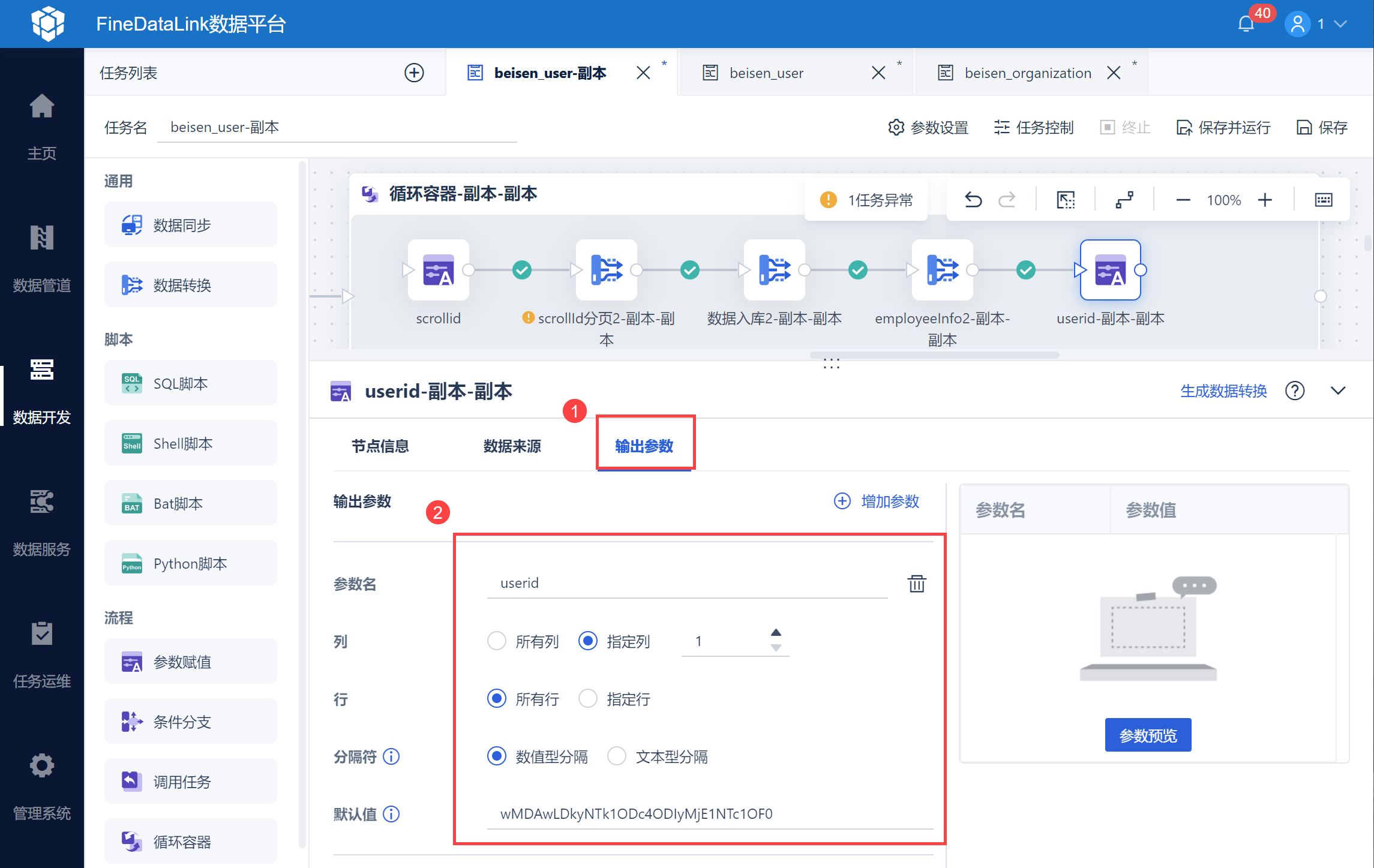
2.3.4 设置停止循环条件
选中循环容器,设置条件循环,并设置执行条件为「userid参数不为空」,如下图所示:
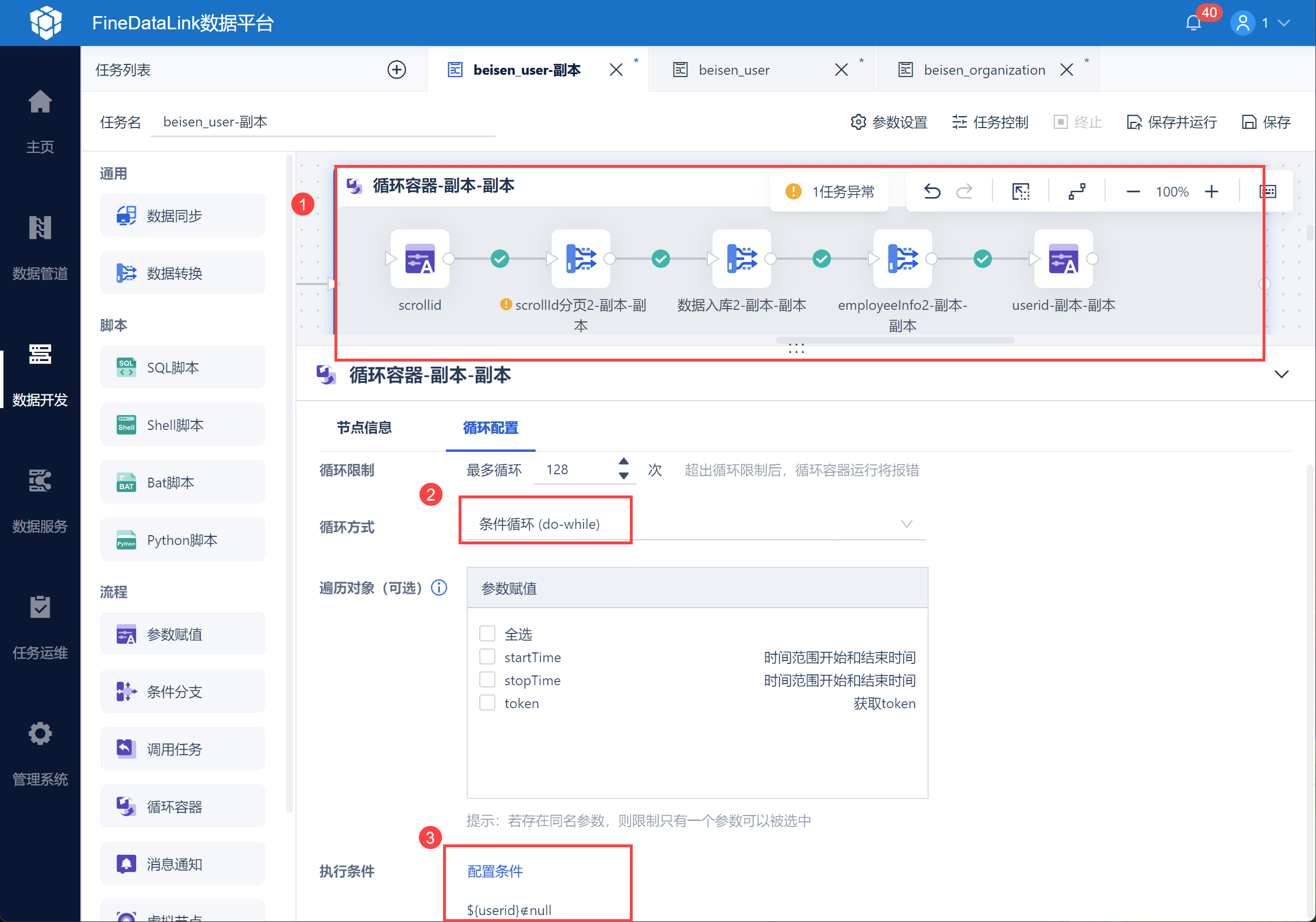
2.4 设置前置清空
由于每次同步都需要全量同步,因此需要在任务的最前面新增两个脚本。
用户表 beisen_user 数据清空,删除历史数据,保证每次同步数据都是最新得,全量同步。
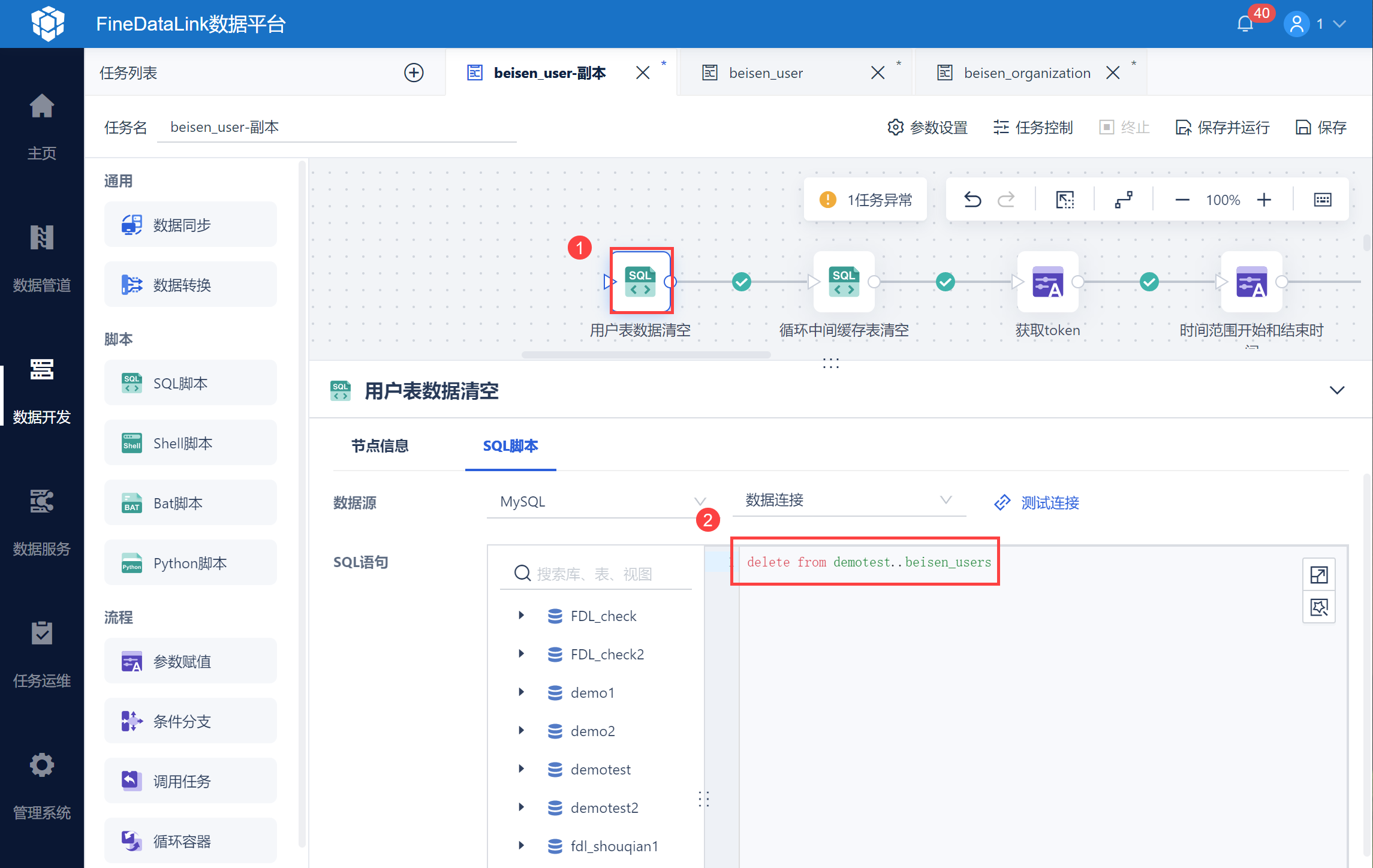
清空循环中间表,由于北森用户接口一次只返回100条数据,通过分页参数 scrollid 查询下页数据,通过中间表将 scrollid 记录下来,因此每次执行任务的时候也要将中间表清空,如下图所示: