

1. 概述编辑
1.1 版本
| FineDataLink 版本 | 功能变动 |
|---|---|
| 4.0.24 | - |
| 4.1.3 | 数据写入星环 TRANSWARP INCEPTOR 数据库时,支持创建、写入分区表 |
1.2 应用场景
企业使用星环 TRANSWARP INCEPTOR 数据库存储业务数据,希望 FineDataLink 定时任务的读写支持星环 TRANSWARP INCEPTOR。
2. 准备工作编辑
2.1 版本和驱动
下载驱动,并将其上传至 FineDataLink,如何上传可参见:驱动管理
| 支持的数据库版本 | 选择驱动 | 驱动包 |
|---|---|---|
| V4.6 | org.apache.hive.jdbc.HiveDriver | |
| V4.6、V4.9.2、V5.2.1、V6.0.2 | inceptor-sdk-transwarp-6.1.0-SNAPSHOT.jar |
2.2 收集连接信息
在连接数据库之前,请收集以下信息:
数据库所在服务器的 IP 地址和端口号;
数据库的名称;
数据库的用户名和密码;
3. 具体连接步骤编辑
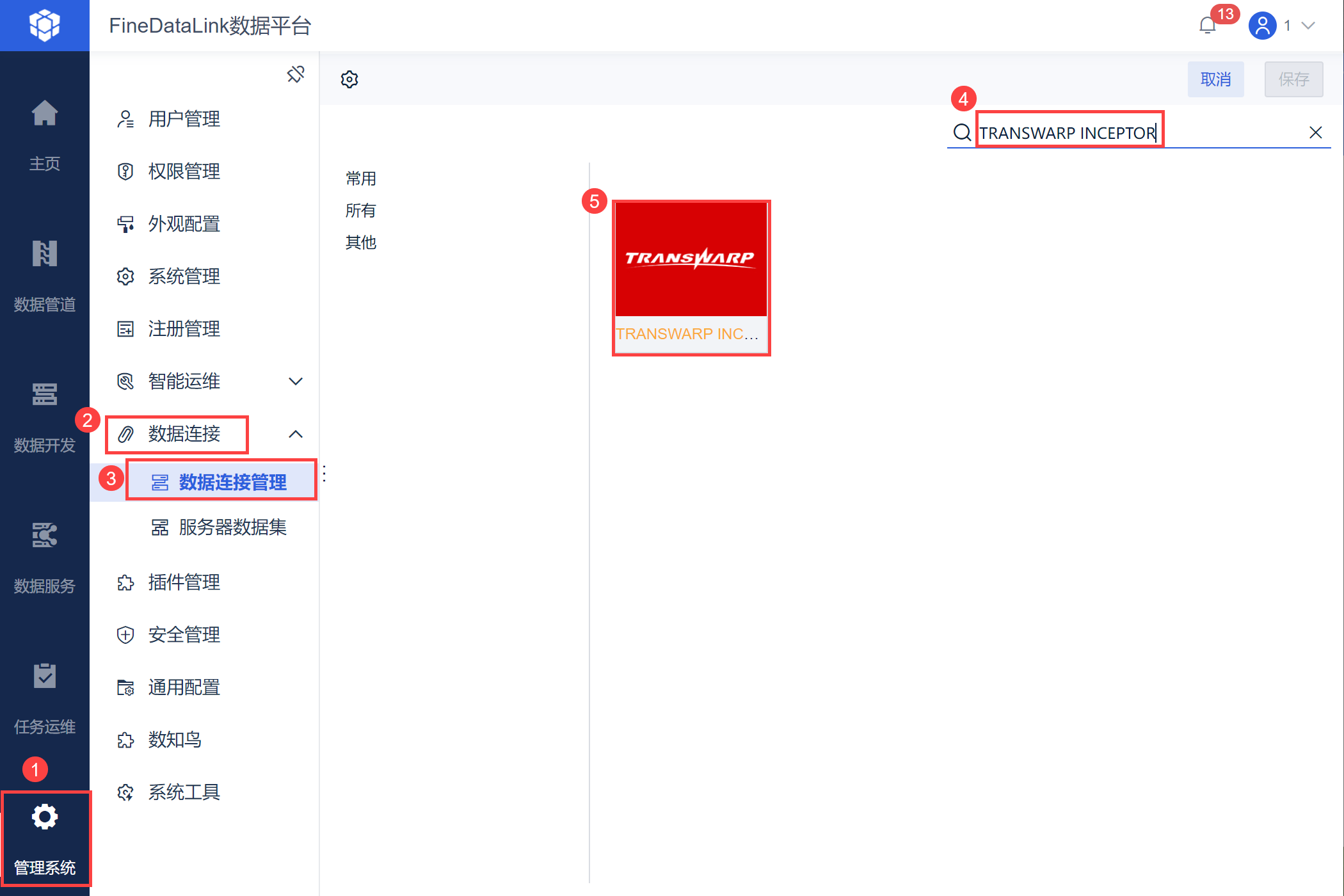
1)登录 FineDataLink,选择「管理系统>数据连接>数据连接管理」,点击「新建数据连接」,找到 TRANSWARP INCEPTOR,如下图所示:
注:如果非管理员用户想要配置数据连接,需要管理员给其分配管理系统下数据连接节点的权限,具体操作请查看 数据连接管理权限
3)驱动切换为「自定义」选择 2.1 节上传的驱动,然后输入 2.2 节的连接信息。
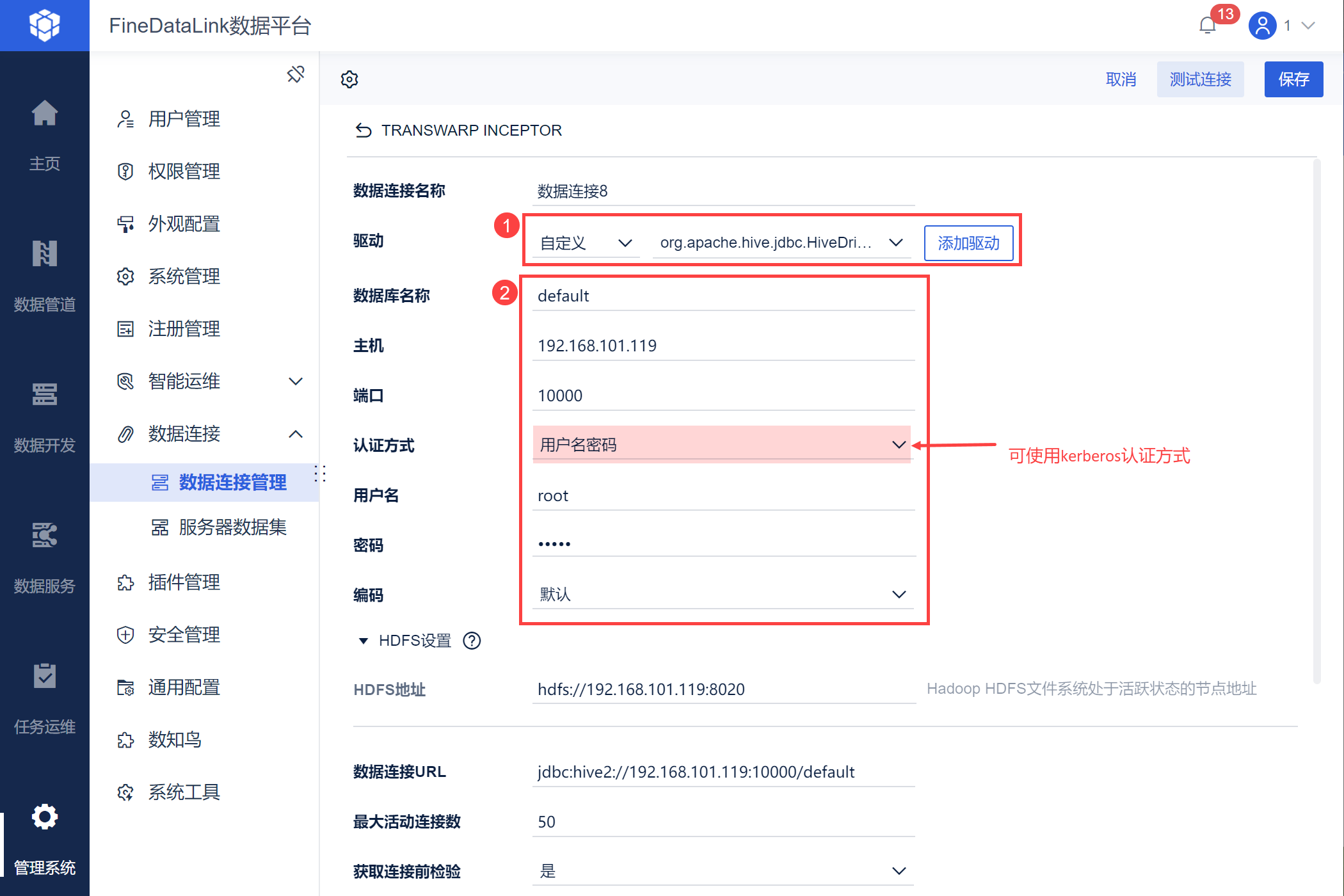
星环支持 Kerberos 认证,Kerberos 认证方式详情可参见:数据连接 Kerberos 认证。连接前请:
检查 /etc/hosts 中的机器名对应 IP 是否为局域网 IP;
检查 /etc/hostname 中机器名设置和 /etc/hosts 中是否配置一致;
检查 FineDataLink 所在机器 hosts 配置的 IP+ 机器名是否正确;
检查本地连接时需要配置 /etc/hosts 文件,添加远端映射:IP+机器名,例如: 192.168.5.206 centos-phoenix 。
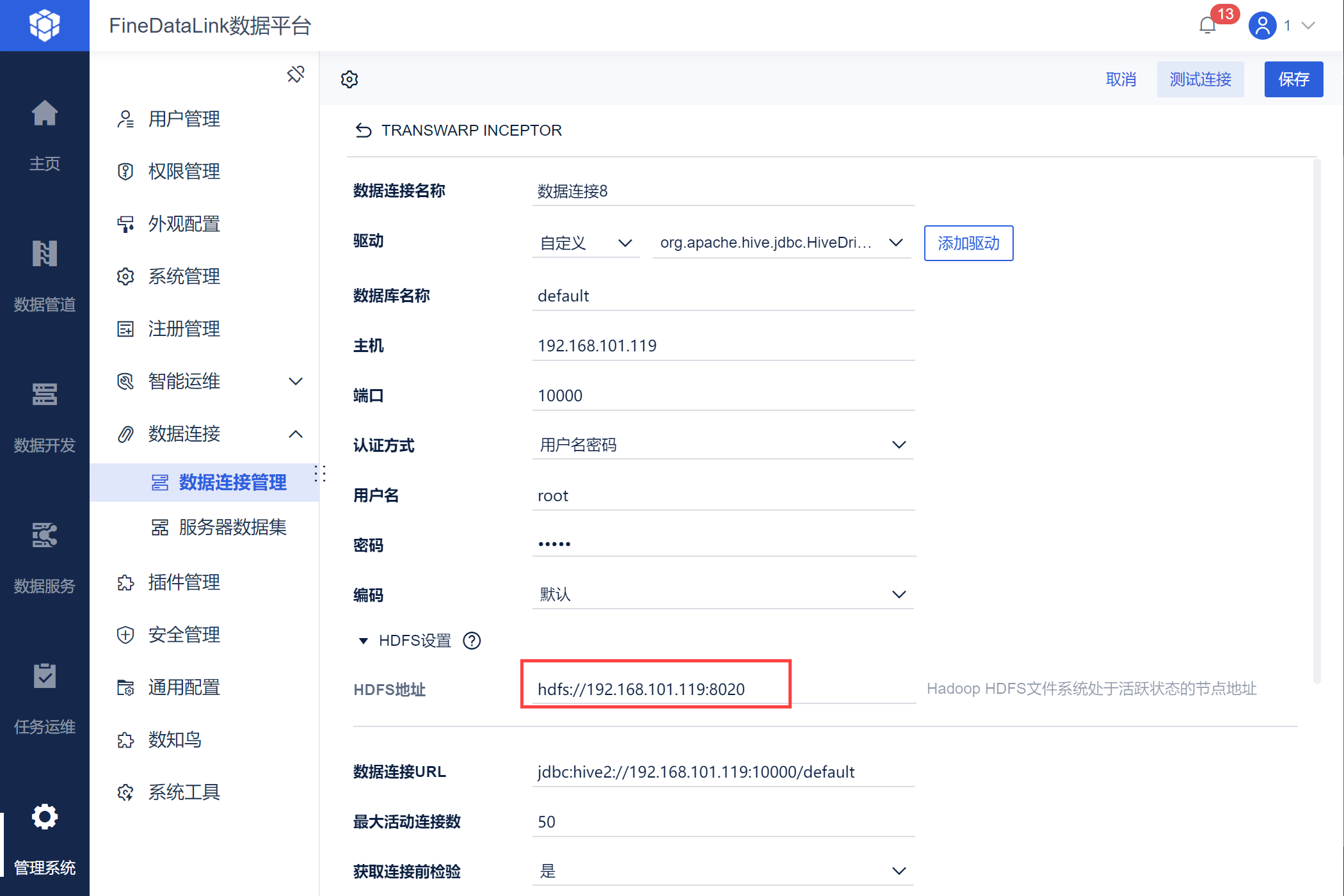
4)如果 TRANSWARP INCEPTOR 作为数据写入端时使用,则需要配置 HDFS 地址,配置说明如下:
由于 inceptor 基于 hive 改写,为了提高写入速度,先建外表到HDFS,再装载到目标表。
配置项 | 提示说明 | 配置项解释 |
|---|---|---|
| HDFS 地址 | 填写IP地址或主机名以及端口号 | Hadoop HDFS文件系统处于活跃状态的节点地址 格式为 "hdfs://ip:port"。 例如:hdfs://192.168.101.119:8020 确定 HDFS 地址中 IP 和端口的方法请参见:确认HDFS地址中的IP和端口 |
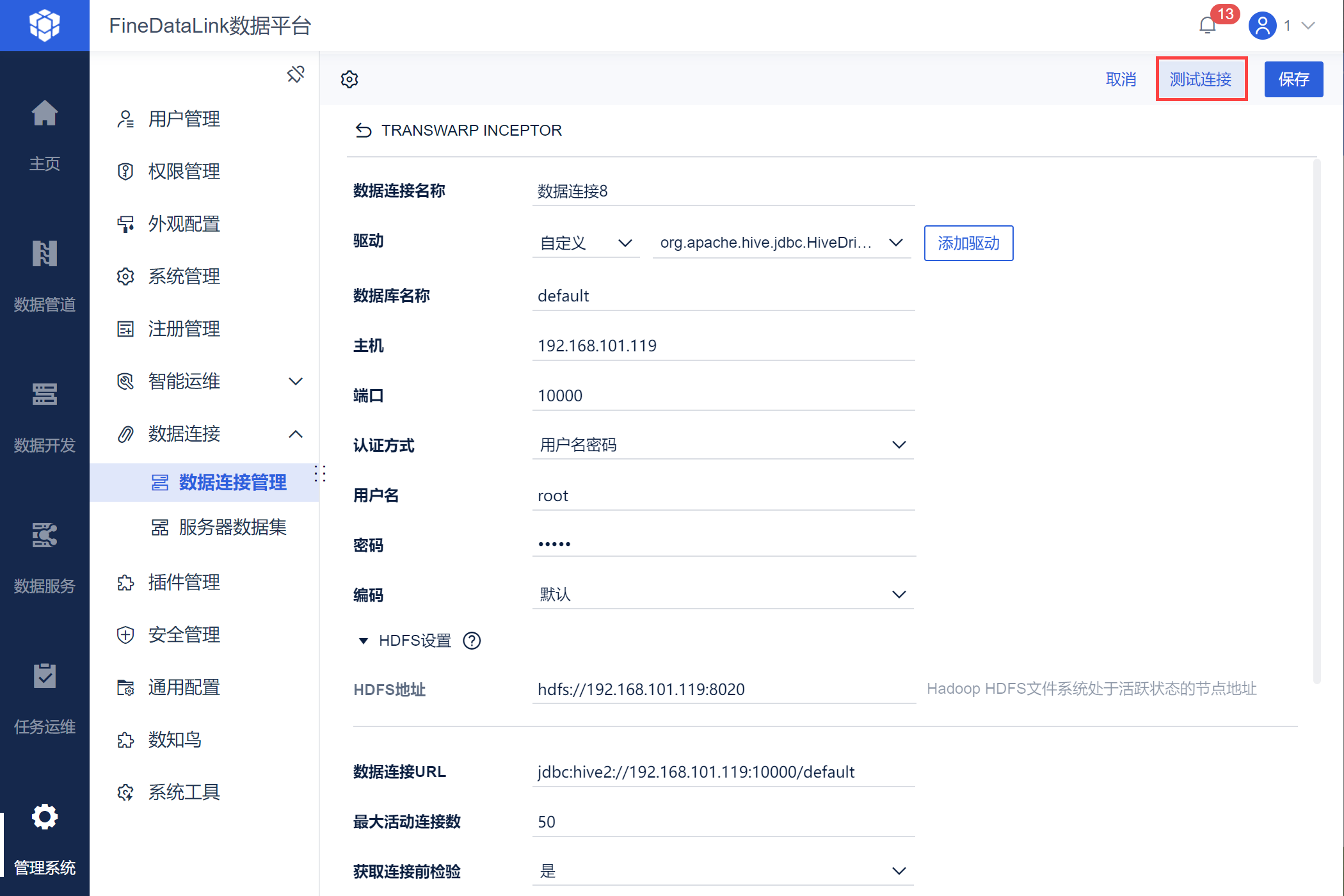
5)进行测试连接,如下图所示:
4. 使用数据源编辑
4.1.3 及之后版本,数据写入星环 TRANSWARP INCEPTOR 数据库时,支持创建、写入分区表。详情请参见:读取、创建、写入分区表
更多 TRANSWARP INCEPTOR 数据库相关内容详情参见:TRANSWARP INCEPTOR数据源使用说明