

1. 概述编辑
定時任務運行時若遇到髒數據,任務會報錯并終止。本文說明如何查看髒數據産生的原因及如何處理髒數據。
注:實時管道任務的髒數據說明請參見:實時管道任務處理髒數據
2. 髒數據産生常見原因编辑
| 原因 | 說明 |
|---|---|
| 主鍵沖突 | 當寫入方式-主鍵沖突策略爲「主鍵相同,記錄爲髒數據」時,主鍵沖突的數據将被視爲髒數據 |
| 字段長度超出限制 | 需注意,字段長度還與編碼有關 PostgreSQL 數據庫的 varchar(60) 和 SQLServer 的 varchar(60) 長度定義是不一樣的,SQLServer表示最多存儲 60 字節,PostgreSQL 是标識,最多存儲 60 個字符 根據編碼的不同,字符占的字節也不一緻,60 個字符計算後肯定超過 60 個字節 |
| 字段類型不匹配 | - |
| 目标字段缺失 | 字段映射中的目标表字段被删除,所以來源表的該字段無法同步,變爲髒數據 |
| 違反目标字段非空約束 | 來源表某個字段值爲空,插入到不能爲空的目标表字段中 |
| 目标表的表空間不足 | - |
| 暫時性原因 | 網絡不穩定,重新運行定時任務即可 |
3. 查看髒數據條數及原因编辑
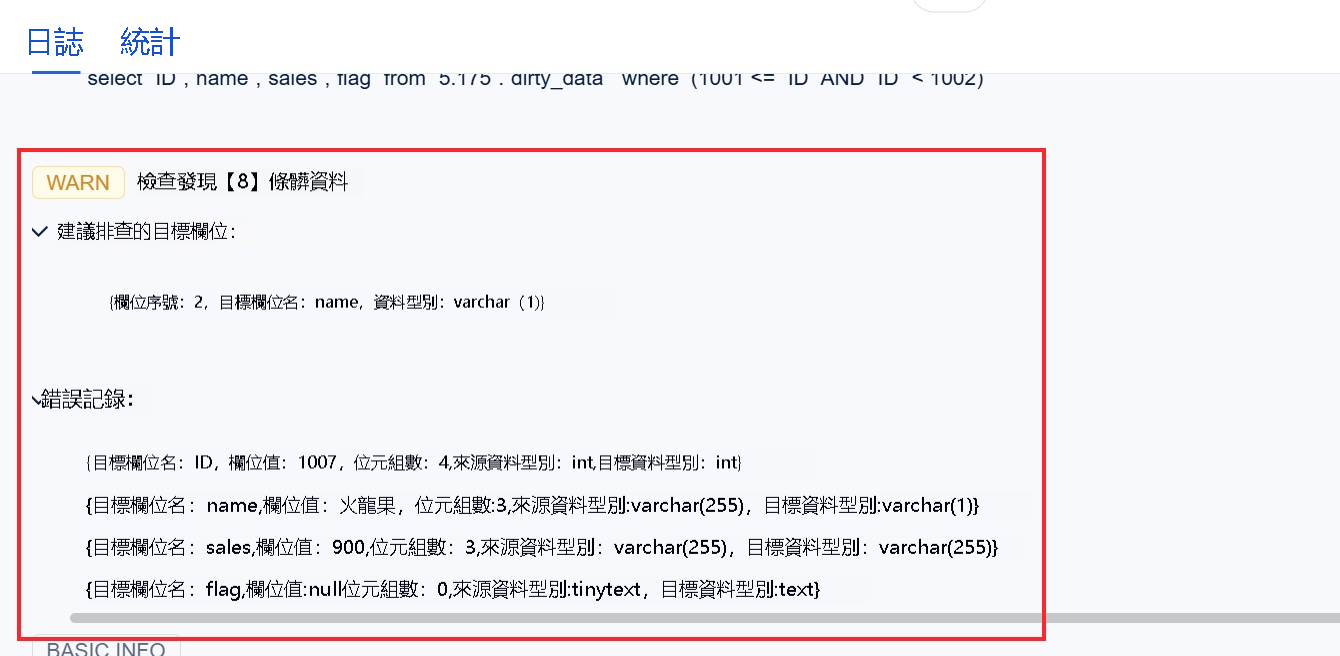
1)定時任務運行時,若存在髒數據,日志中将會報錯。如下圖所示:
注:建議将 日志等級 設置爲 INFO,日志信息會更加詳細。

「統計」Tab頁下,可看到髒資料具體條數,點選條數,可看到錯誤類型和錯誤原因。如下圖所示:


2)用戶若想查看到所有髒數據的所有信息,可到%FDL_HOME%\logs\fanruan.log文件中進行查看。
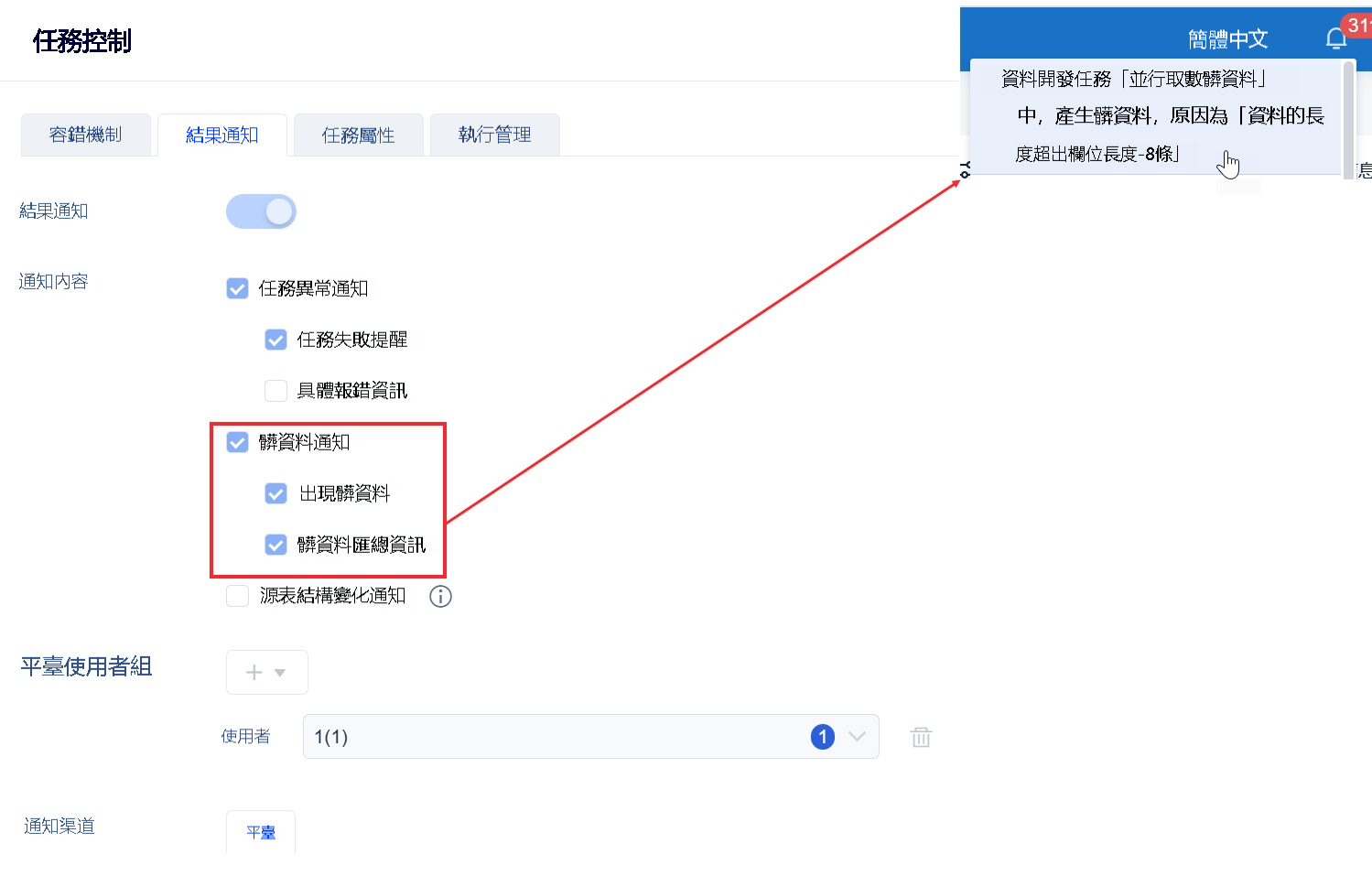
3)用戶若想遇到髒數據就通知給指定用戶,可在結果通知中勾選「髒數據通知」按鈕。如下圖所示:
詳情請參見:任務控制-結果通知
4. 處理髒數據编辑
4.1 忽略髒數據
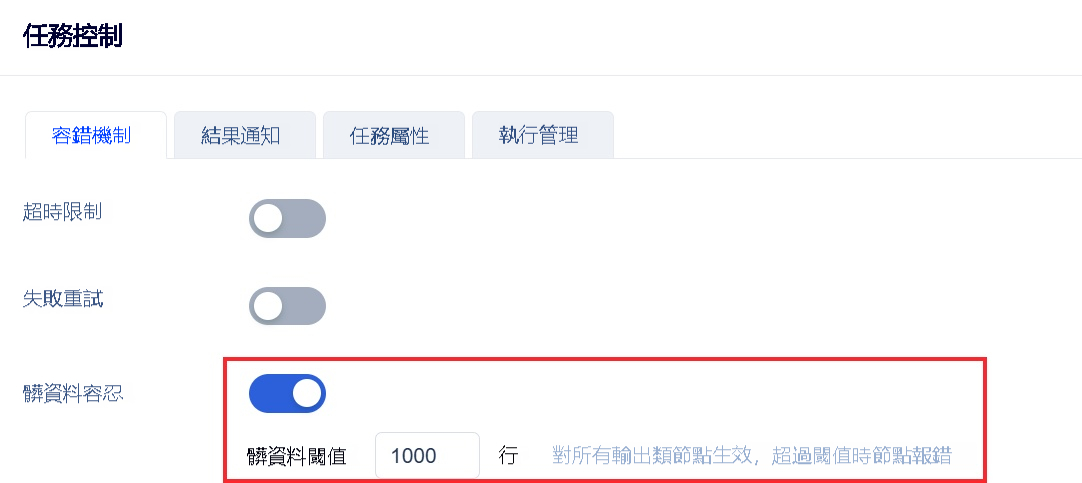
若用戶希望任務具有一定容錯性,即遇到髒數據任務繼續運行,不進行報錯,運行狀态爲成功,且髒數據不寫入到目标表中(正常的數據會順利寫入到目标表中),可設置髒數據阈值(輸入範圍爲1~1萬)。如下圖所示:
詳情請參見:任務控制-容錯機制
注:若不配置「髒數據容忍」,只要遇到髒數據就會導緻任務失敗。
若髒數據條數未超過阈值(最大可設置爲10000),日志信息如下:
髒數據條數超出髒數據阈值後,任務會報錯。
4.2 髒數據處理後寫入到目标表
用戶若希望髒數據寫入到目标表,需要根據日志排查髒數據出現原因,修正後重新運行任務或者 重試任務
産生髒數據後,重試任務的處理場景:
| 場景 | 增量同步的方式 | 重試後是否會存在數據問題 | 建議處理措施 |
|---|---|---|---|
| 全量同步 | - | 否 | - |
| 增量同步-使用時間戳 | 動态參數:如:配置 now-1 作爲數據範圍,每次更新前一天數據 | 是 | 在重試時,用戶可以指定本次運行的臨時任務參數值 且用戶的任務設計需要支持幂等,即同一數據範圍的定時任務需要支持多次運行 |
| 獲取目标表的最新數據時間戳 如:每次任務先從目标表獲取最大的時間戳,作爲本次同步的起始時間 | 是 | 用戶需要手動删除目标表大於本批次的數據,以進行重試 且用戶的任務設計需要支持幂等,即同一數據範圍的定時任務需要支持多次運行 | |
自定義配置表存儲斷點 如:每次任務最後一步存儲本次同步的最大時間至一張表存儲 | 是 | 用戶需要手工修改斷點值,以進行重試 且用戶的任務設計需要支持幂等、即同一數據範圍的定時任務需要支持多次運行 | |
| 全表比對 | - | 否 | - |