1. 概述编辑
1.1 版本说明
| FineDataLink 版本 | 功能变动 |
|---|---|
| 4.0.17 |
|
1.2 应用场景
定时任务开发过程中,为了提高开发效率,需要在配置过程中通过预览判断运算结果是否正确,提前发现错误。
1.3 功能简介
支持自定义设置预览数据量。
支持通过预览判断运算结果是否正确。
2. 功能说明编辑
1)FineDataLink 支持在「数据转换」的输入型算子中进行「样本设置」,即在预览界面,设置用多少数据去参与运算,便于进行计算后的预览结果校验。

默认使用前 5000 条数据进行后续计算,所以会出现以下问题:
同样的查询条件,节点中预览数据时,数据条数不一致。
在数据库中写 SQL 能预览出数据,但 FineDataLink 中「数据过滤」算子中预览时没有数据。
「数据比对」算子预览结果与实际结果不符,实际数据左右表是相同的,但「数据比对」算子显示新增。
SparkSQL 计算结果只有 5000 条。
用户可在「样本设置」中选择「全量数据」,后续算子的预览结果将为全量数据的;但若数据量过多,比如有 1000w 数据,不建议「样本设置」中设置「全量数据」,不然会导致前端无响应。
「样本设置」中的数据量只控制后续算子的预览结果,定时任务实际运行时,将使用所有数据进行计算。
2)FineDataLink 「数据同步」、「参数赋值」、「数据转换」支持预览数据量默认显示 1000 行,同时支持显示字段数据类型,便于用户进行数据处理和计算。注:「数据转换」中只有输入型算子显示预览 1000 行。

从数据库解析至 FineDataLink 的字段类型如下所示:
| FineDataLink 的字段类型 | 数据库的字段类型 |
|---|---|
| 文本 | varchar |
| 数值 | int、long、float、double |
| 时间 | date、timestamp |
| 其他 | binary、boolean |
3)在进行任务开发时,数据输入首先会进行数据解析,解析后的数据根据「样本设置」量计算后通过数据预览展示结果。
不同输入源数据解析量逻辑如下表所示:
| 场景 | 逻辑 |
|---|---|
| 数据同步\参数赋值 | 文件数据集(解析首行)、API取数解析(解析整段)、MongoDB取数(前100行) |
| 数据转换 | 文件数据集(解析首行)、API取数解析(解析整段)、MongoDB取数(前100行)、文件输入(前5000行) JSON解析(解析选择字段的首行)、XML解析(解析选择字段的首行) |
3. 示例编辑
示例数据:DEMO_CONTRACT.xlsx、CUSTOMER.xls
用户需要将文件数据通过「客户ID」字段进行关联,让合同信息带上客户数据。
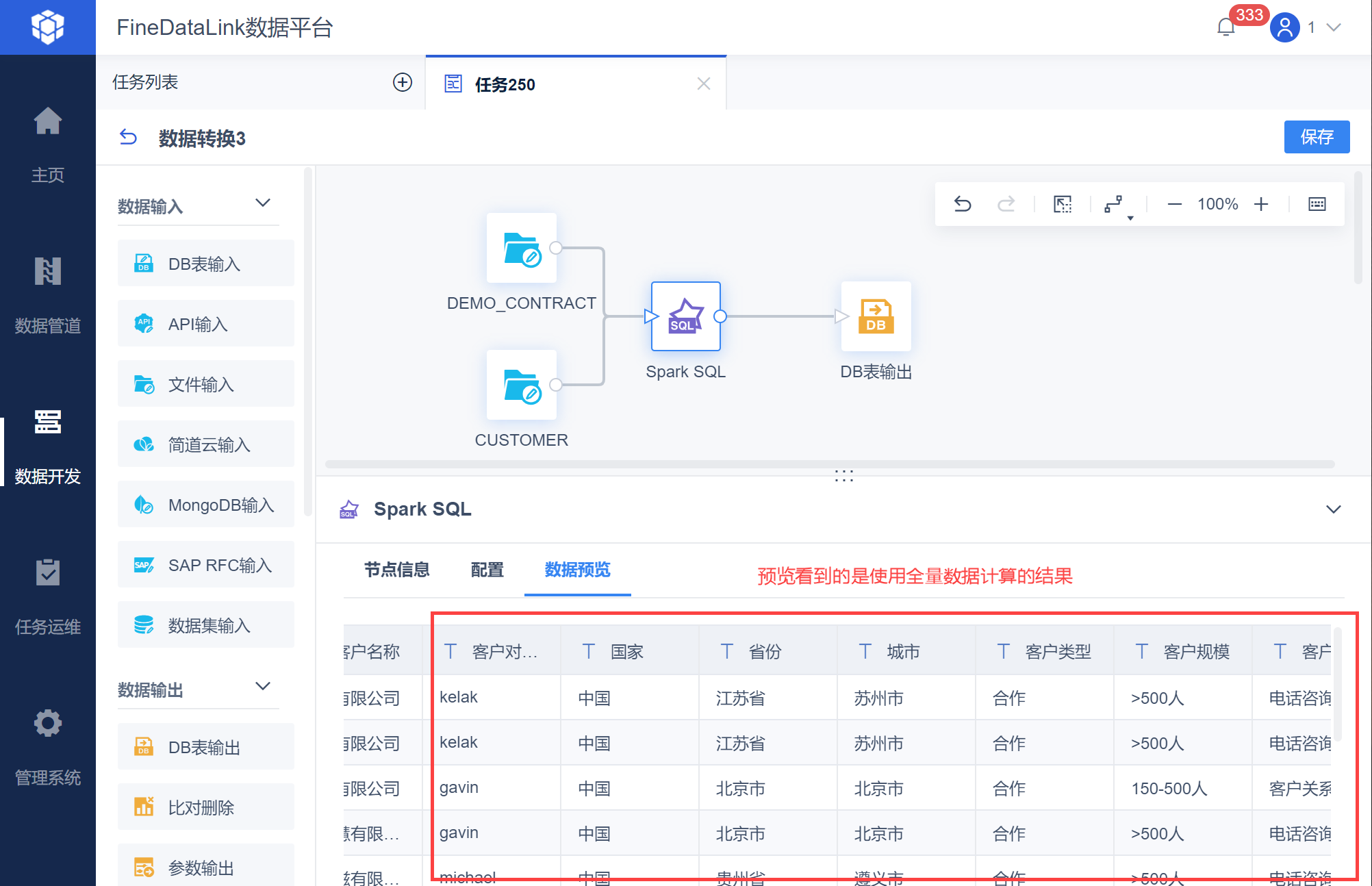
使用文件输入进行数据源输入,然后使用「Spark SQL」进行数据计算,如下图所示:
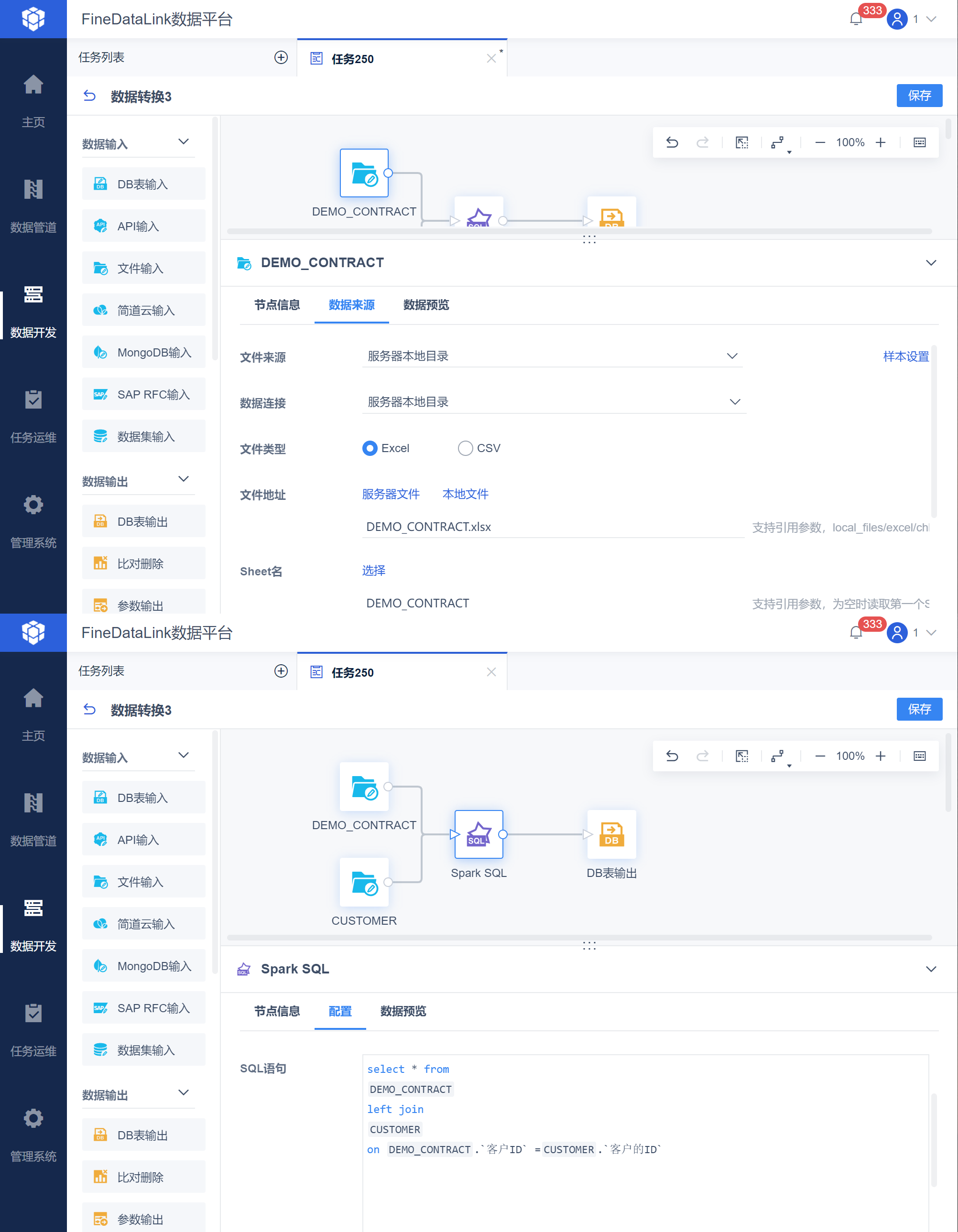
由于「CUSTOMER」数据表数据量较大,此时「样本设置」默认采样量为「5000」,即预览界面用5000数据去参与运算。在数据关联后「CUSTOMER」表中 5000 行之后的数据不参与计算,在数据结果预览中就不能很好的确认计算是否正确,如下图所示:
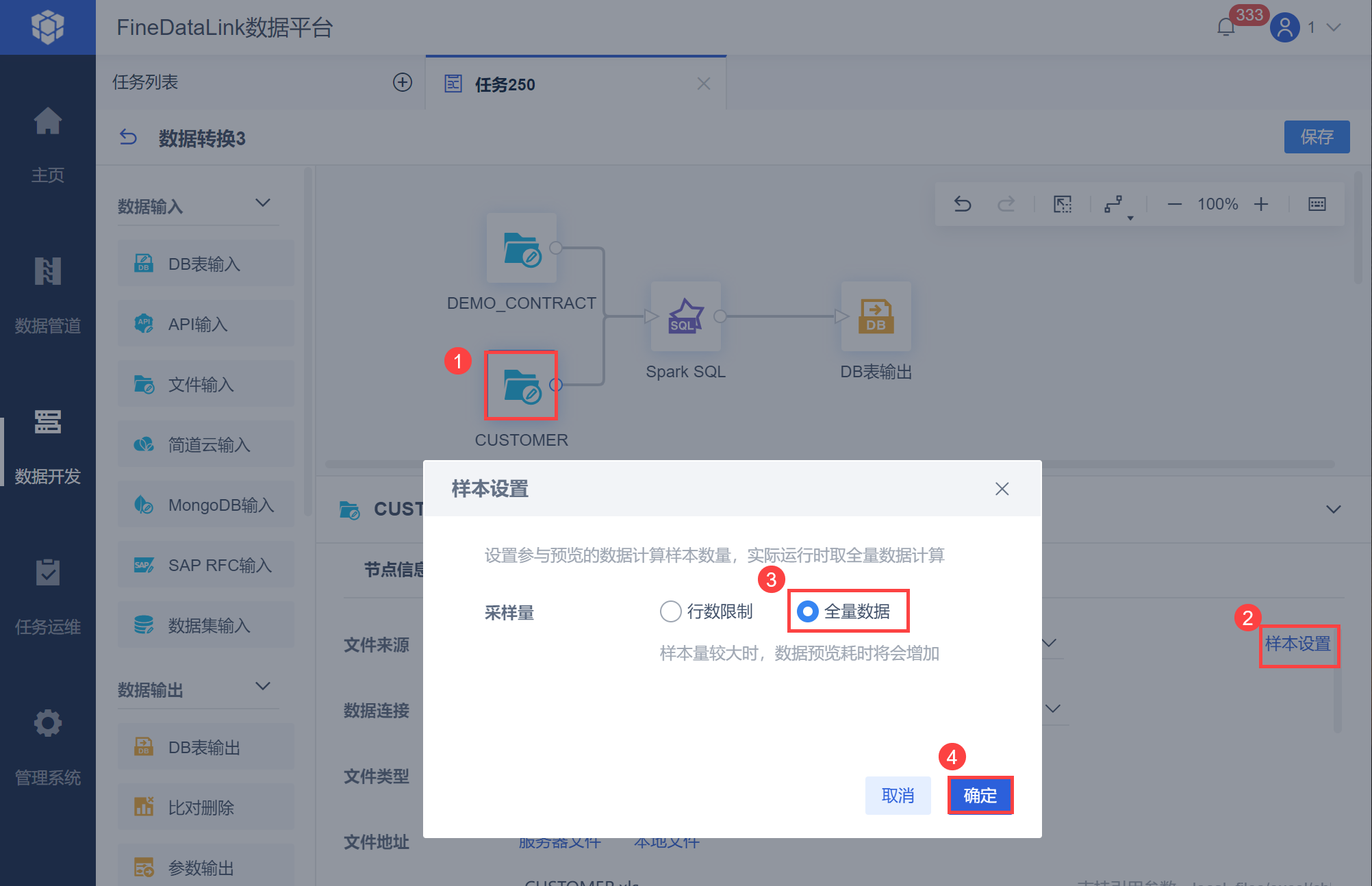
为了避免这种情况,可以选择「CUSTOMER」文件输入算子,点击「样本设置」,设置采样量为「全量数据」,即在数据预览时使用全量数据去进行计算,如下图所示:
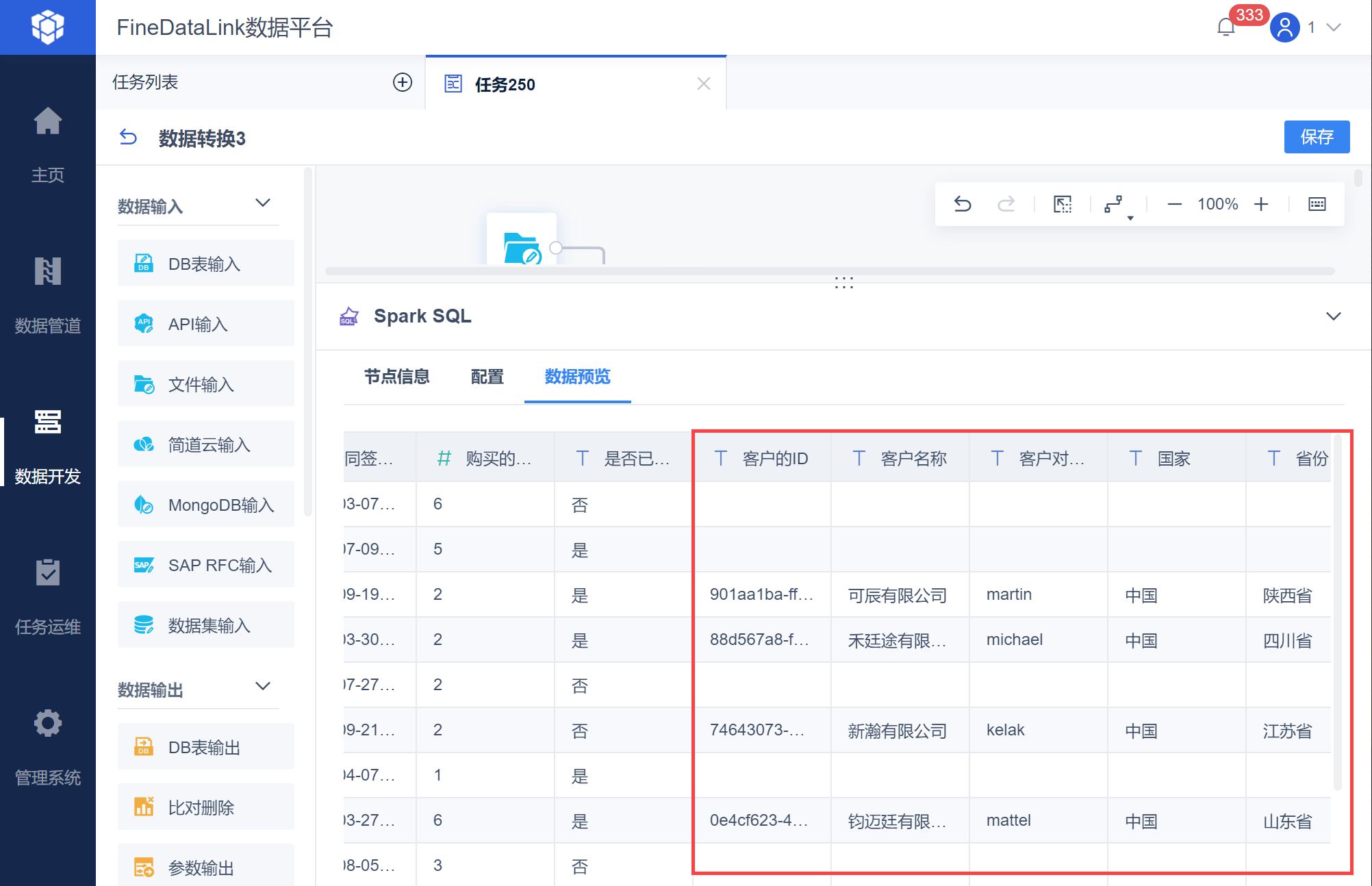
得到计算后的数据预览结果,看到的是使用全量数据计算后的结果,如下图所示: