

1. 概述编辑
1.1 版本说明
| FineDataLink 版本 | 功能变动 |
|---|---|
| 4.0.13 | - |
1.2 应用场景
参数赋值 可以将上游节点的结果输出至下游节点使用,但有些数据需要进行进一步处理才能作为参数输出,参数赋值未提供复杂解析和处理的功能,因此只能先在「数据转换」里做处理数据并取至数据库后,再使用「参数赋值」输出为参数,使用成本较高。
用户期望能够对数据进行处理后直接输出参数,不需要将处理结果输出数据库。
1.3 功能说明
FineDataLink 支持在「数据转换」中直接进行参数输出。

注:参数使用的约束限制与「参数赋值」相同,详情参见:参数赋值
2. 操作步骤编辑
示例为将 API 数据进行解析处理后,将满足条件的数据设置为参数,并将数据库表中满足参数条件的数据取出至指定数据库。
http://fine-doc.oss-cn-shanghai.aliyuncs.com/book.json 数据需要进行解析并取出isbin 不为空的数据,将这些数据中的 author 作为参数输出,并输入给 book 数据表中,从中取出满足参数条件的数据,输出至 boook_out 数据表中。
2.1 数据处理
新建定时任务,将数据转换拖入画布中,如下图所示:
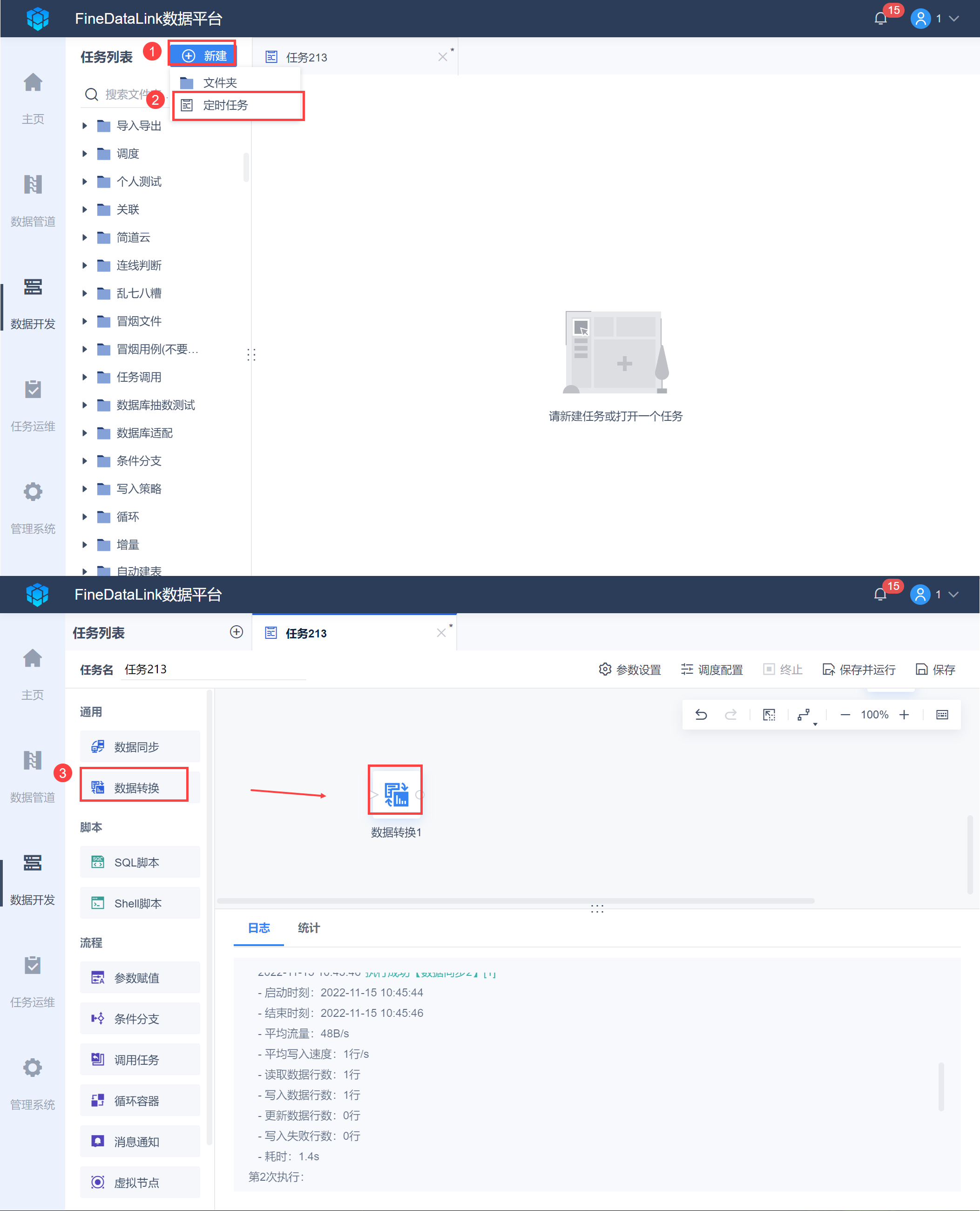
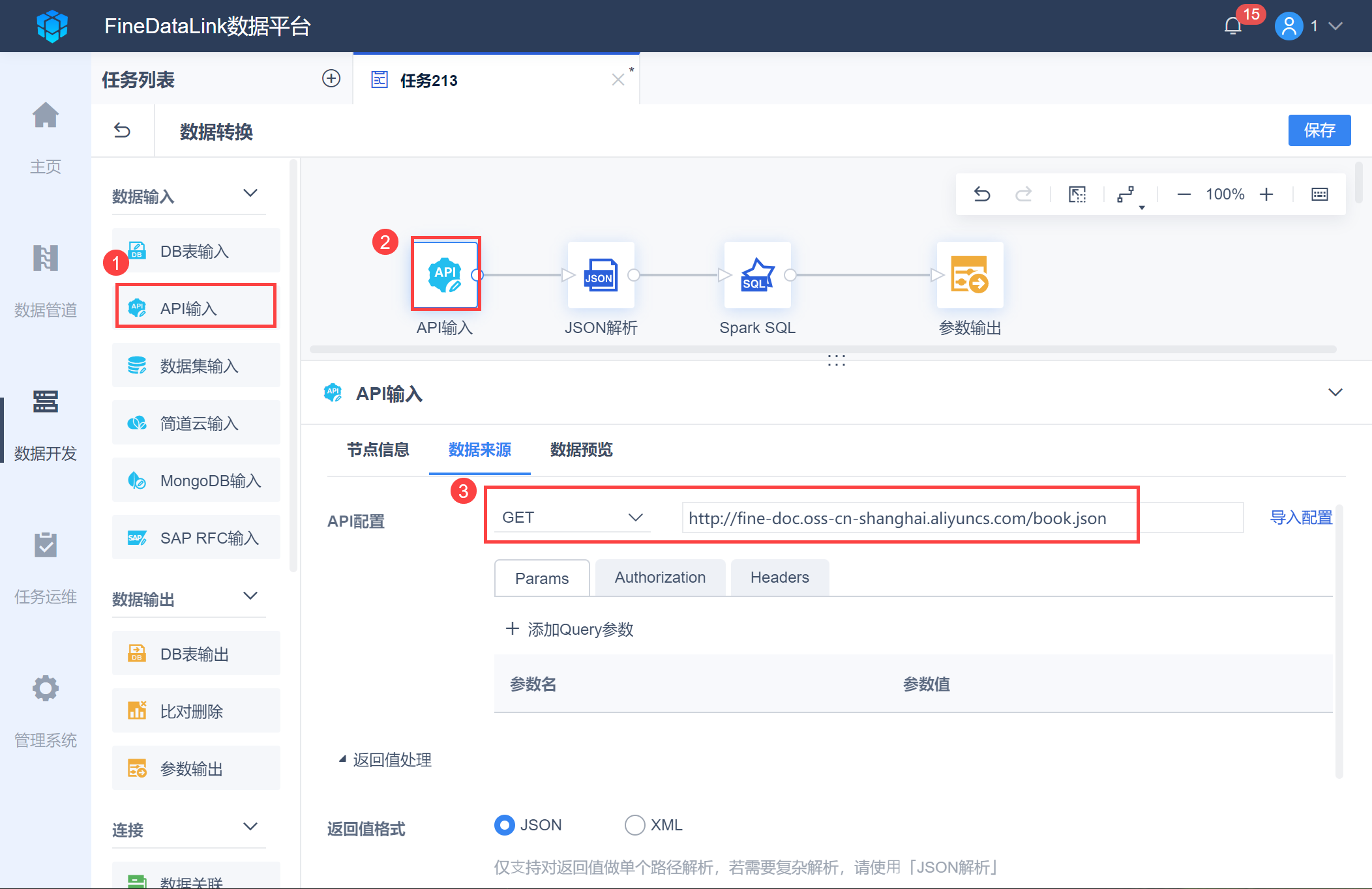
进入「数据转换」节点编辑界面,将「API输入」功能拖入画布,并进行取数设置,示例中使用了http://fine-doc.oss-cn-shanghai.aliyuncs.com/book.json,如下图所示:
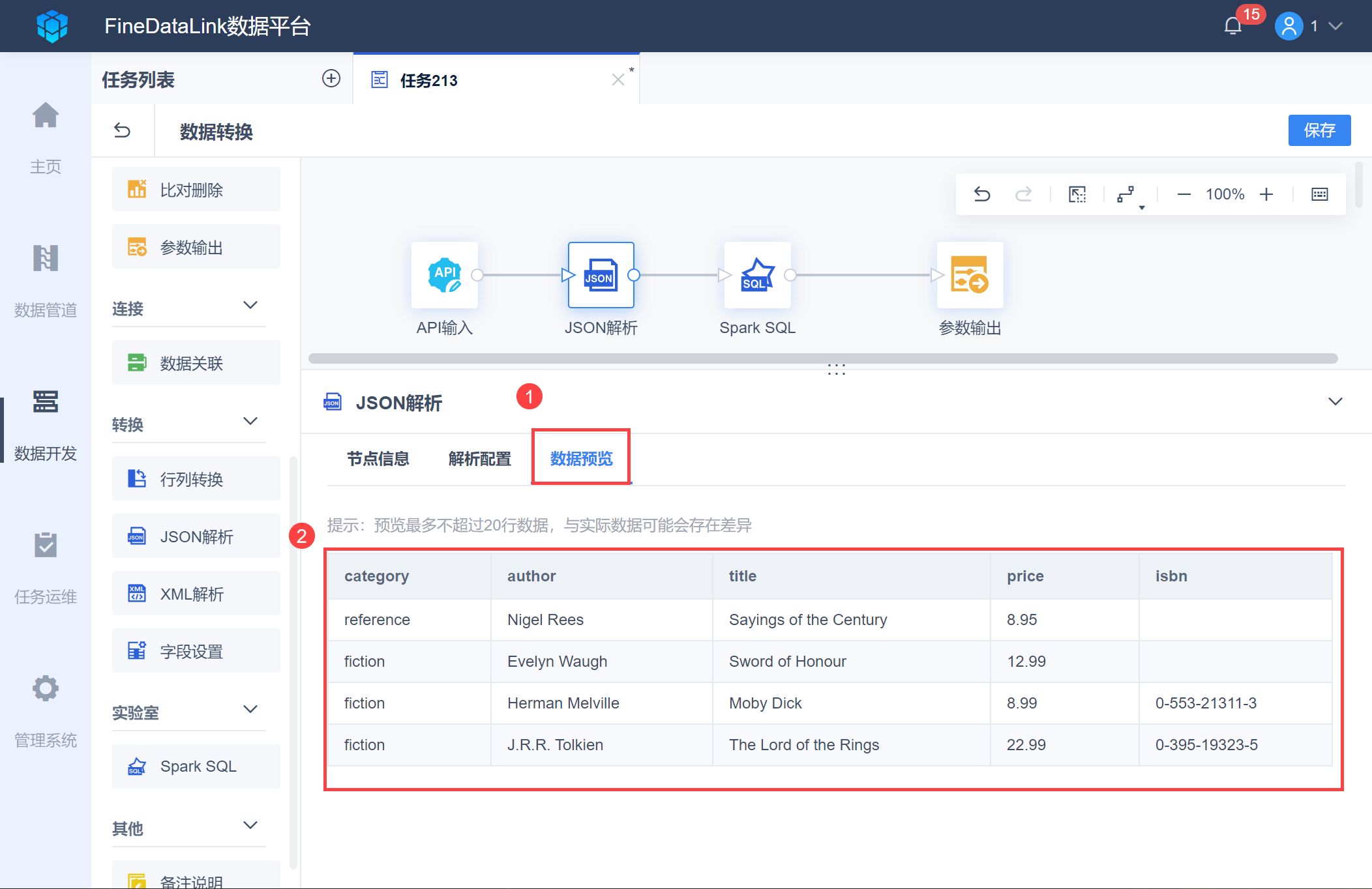
选择「JSON解析」节点,和 API输入节点连接,并选择需要的节点,示例中选择了book相关内容,如下图所示:

点击「数据预览」即可看到解析好的数据,如下图所示:
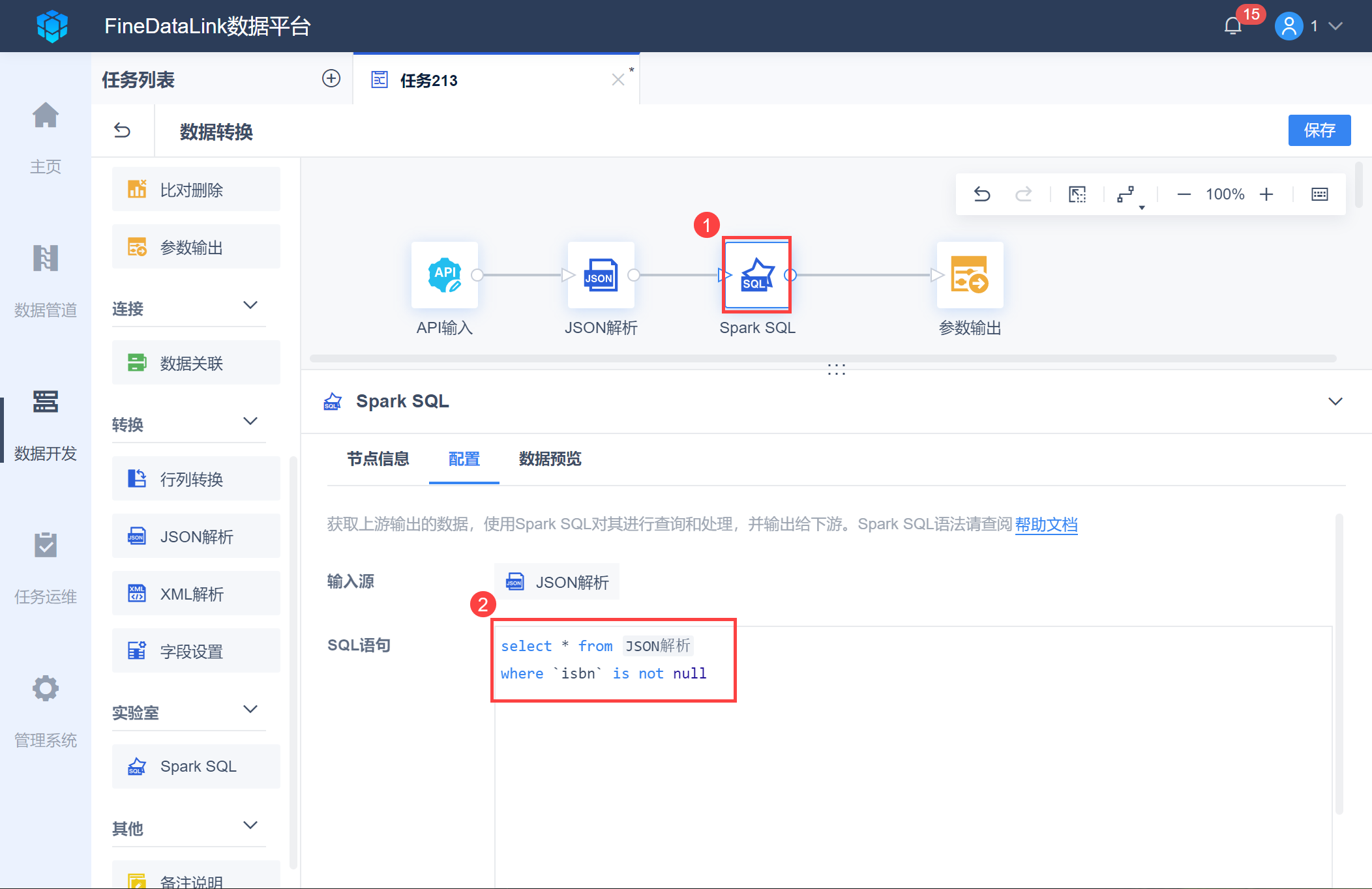
使用「SparkSQL」取出 isbn 不为空的数据,如下图所示:
select * from JSON解析
where `isbn` is not null
注:sql 语句需要手动选择输入源。
此时即可在预览界面看到经过解析的 isbin 不为空的 book 层级数据,如下图所示:
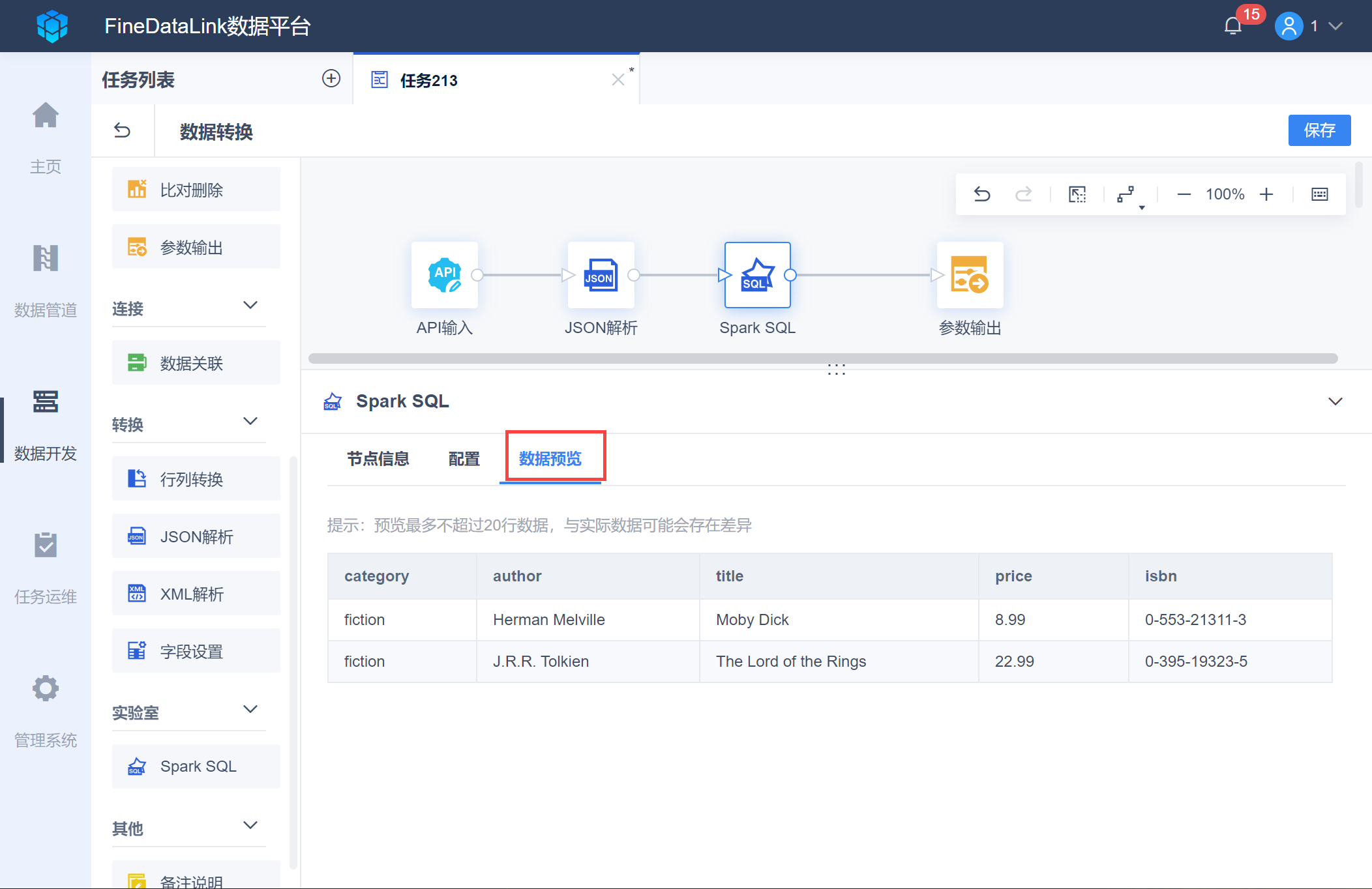
2.2 输出参数
选择「参数输出」功能,将 author 设置为参数,参数名命名为「author」,如下图所示:
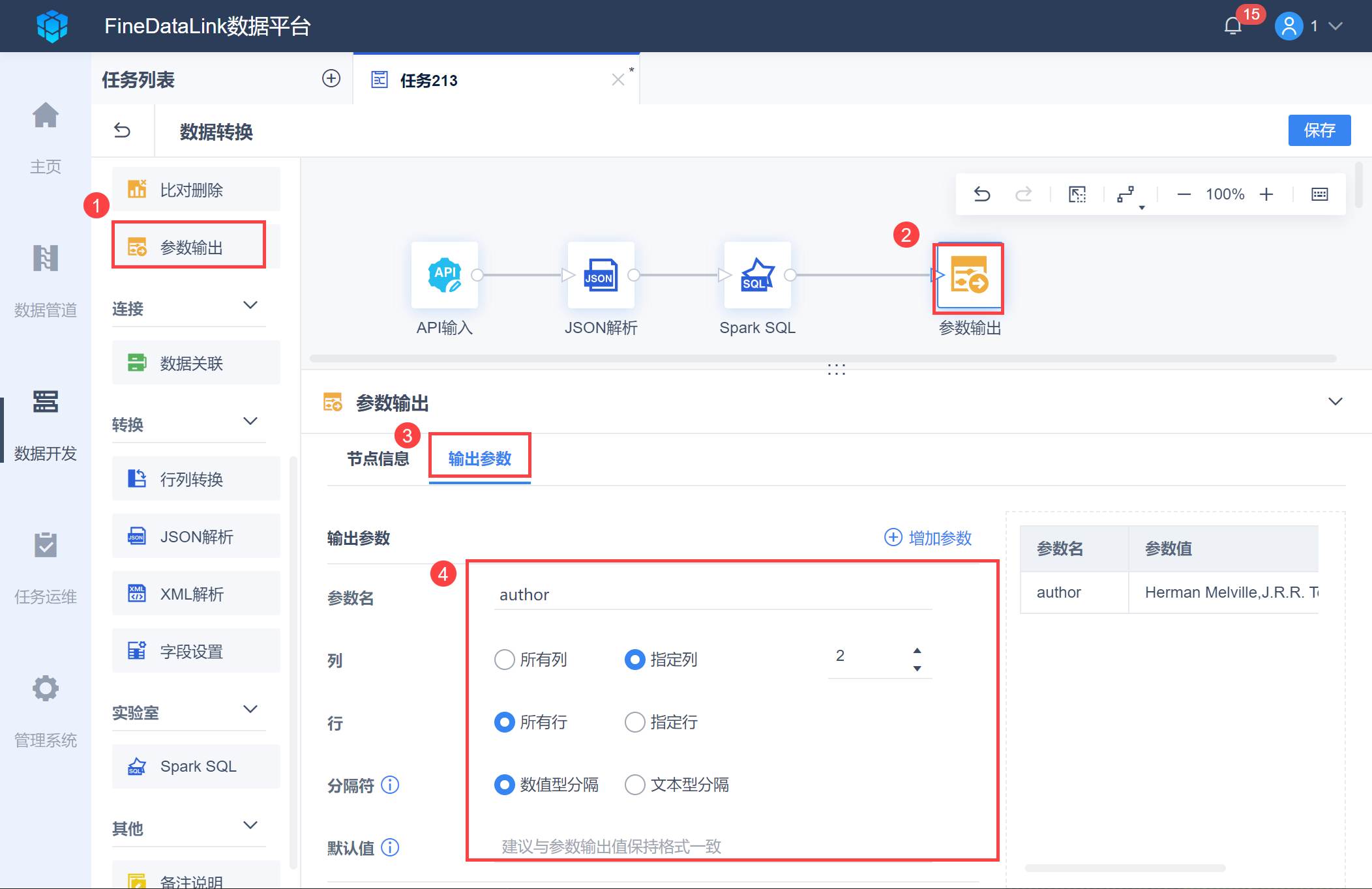
2.3 使用参数同步数据至数据库
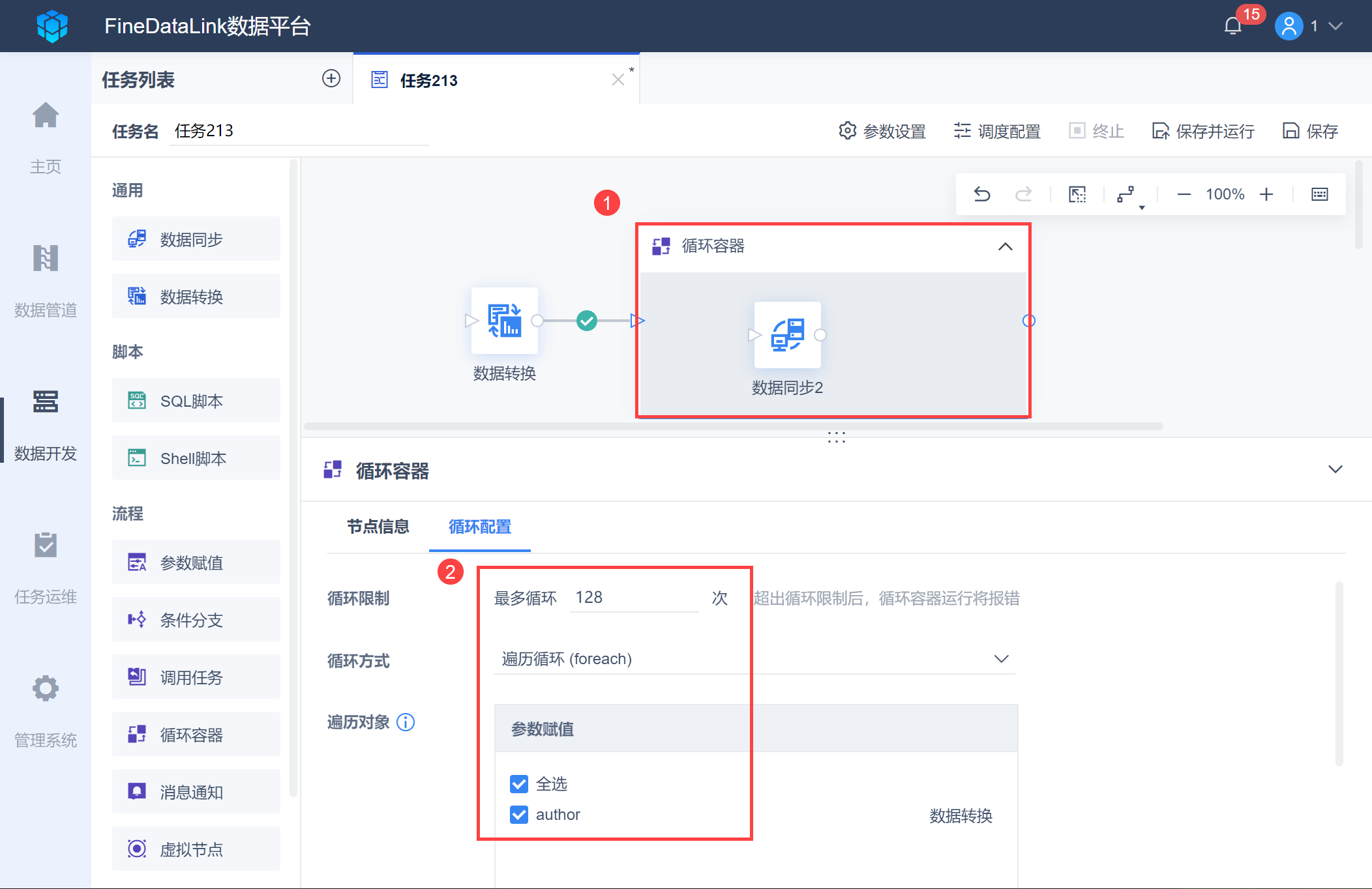
由于 2.2 节输出的参数有多个参数值,因此需要使用循环容器功能,将多个参数值一个个传入数据同步中。
新增循环容器节点,并将数据同步节点拖入循环容器,然后与上一个节点数据转换连接,如下图所示:
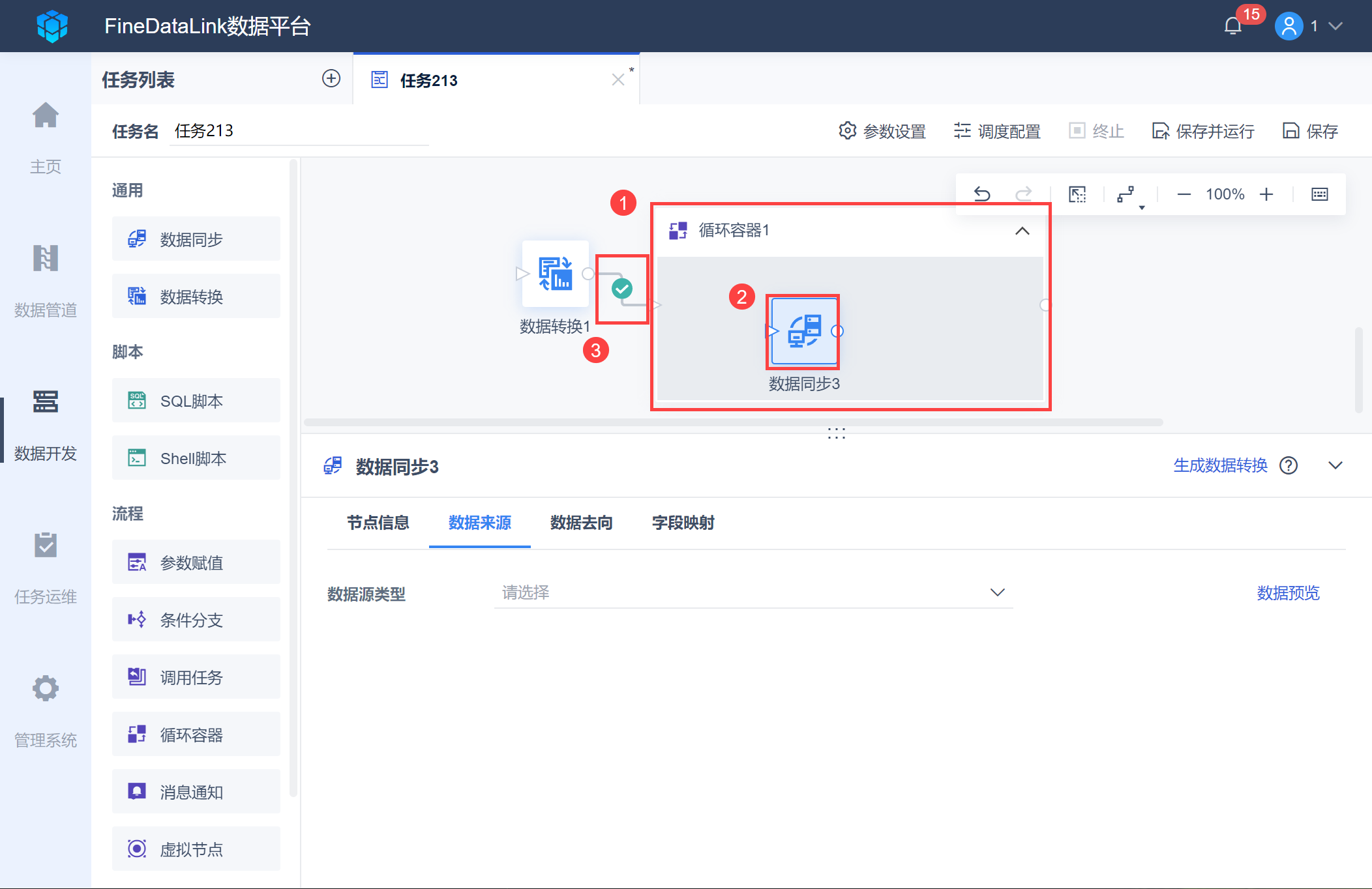
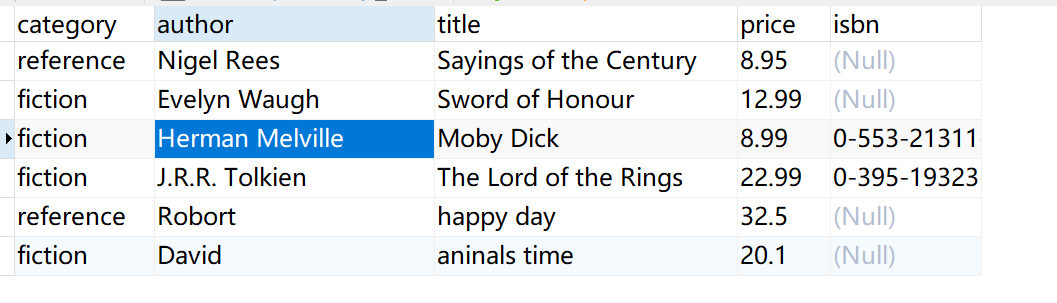
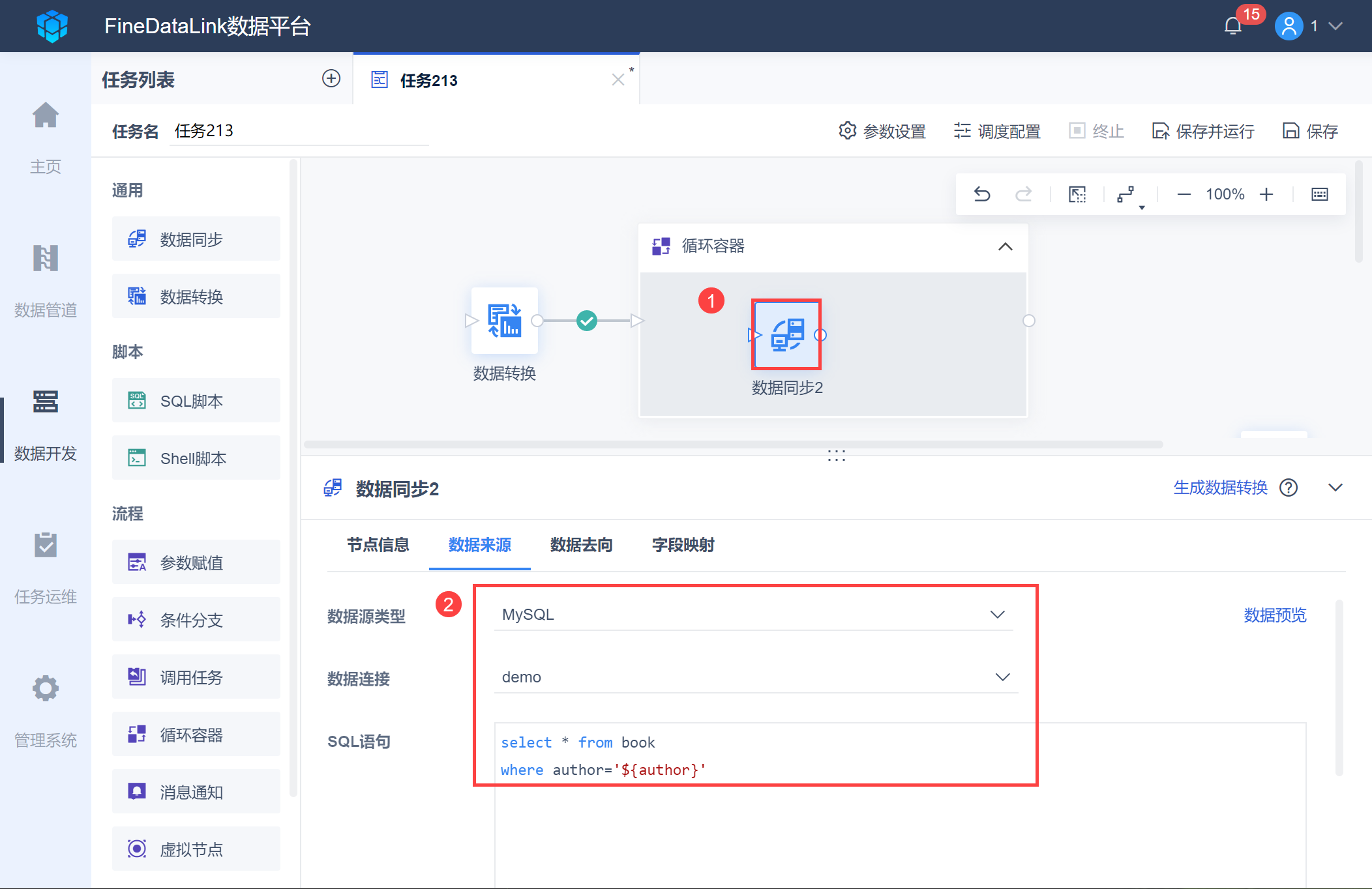
在数据同步节点,在数据表 book 中取出满足参数条件 author 的数据。
book 数据表如下图所示:
SQL 语句为:select * from book where author='${author}',如下图所示:
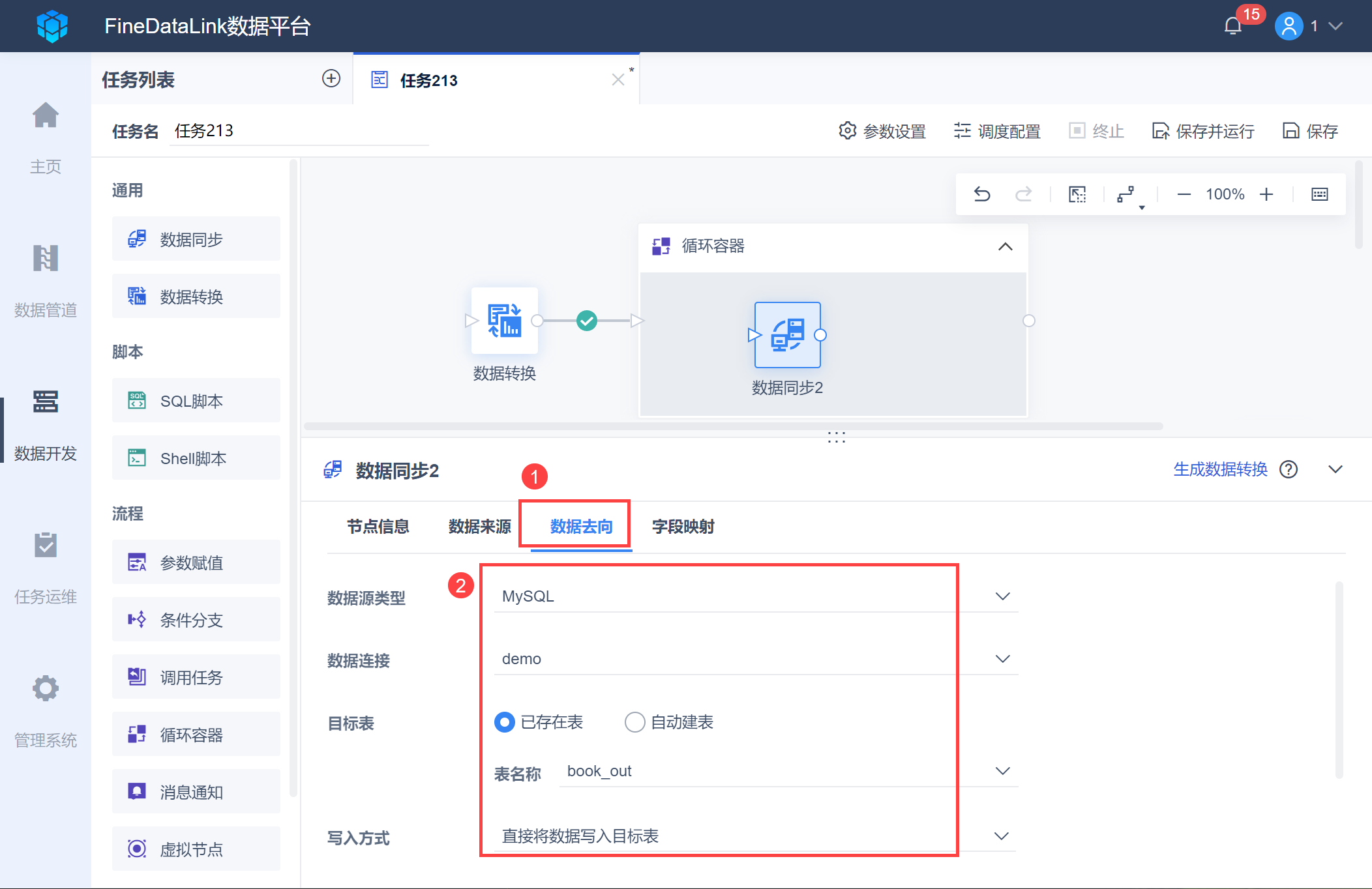
选择数据去向,设置输出数据表为 book_out,如下图所示:
选中循环容器,选择遍历对象为「author」,设置循环方式和循环限制,如下图所示:
2.4 执行任务
保存并运行,可以看到数据表 book_out 中取出了满足参数条件的 author 数据,如下图所示:
