

1. 概述编辑
1.1 版本
| FineDataLink 版本 | 功能变更 |
|---|---|
| 3.6.2 | 数据转换节点 新增算子「Spark SQL」算子,可实现较灵活的数据转换功能 |
| 4.0.17 |
|
1.2 说明
本文介绍常用的 Spark SQL 语法。
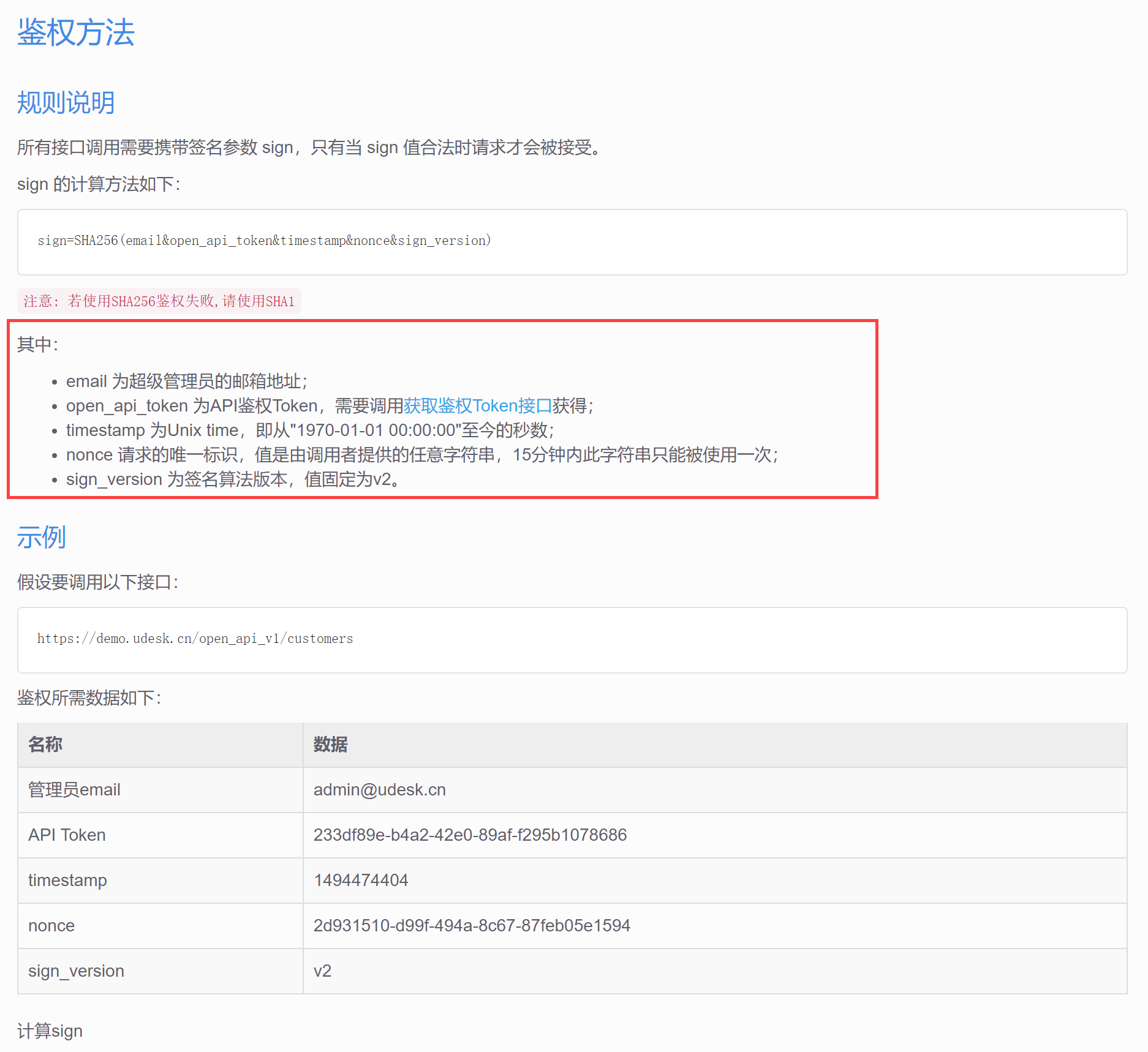
其中「编码函数」、「加密函数」、「签名函数」等常用于进行API加密认证取数,文档示例详情参见:API取数-加密身份验证&按页数取数
注:Spark SQL 算子具体用法请参见:Spark SQL算子
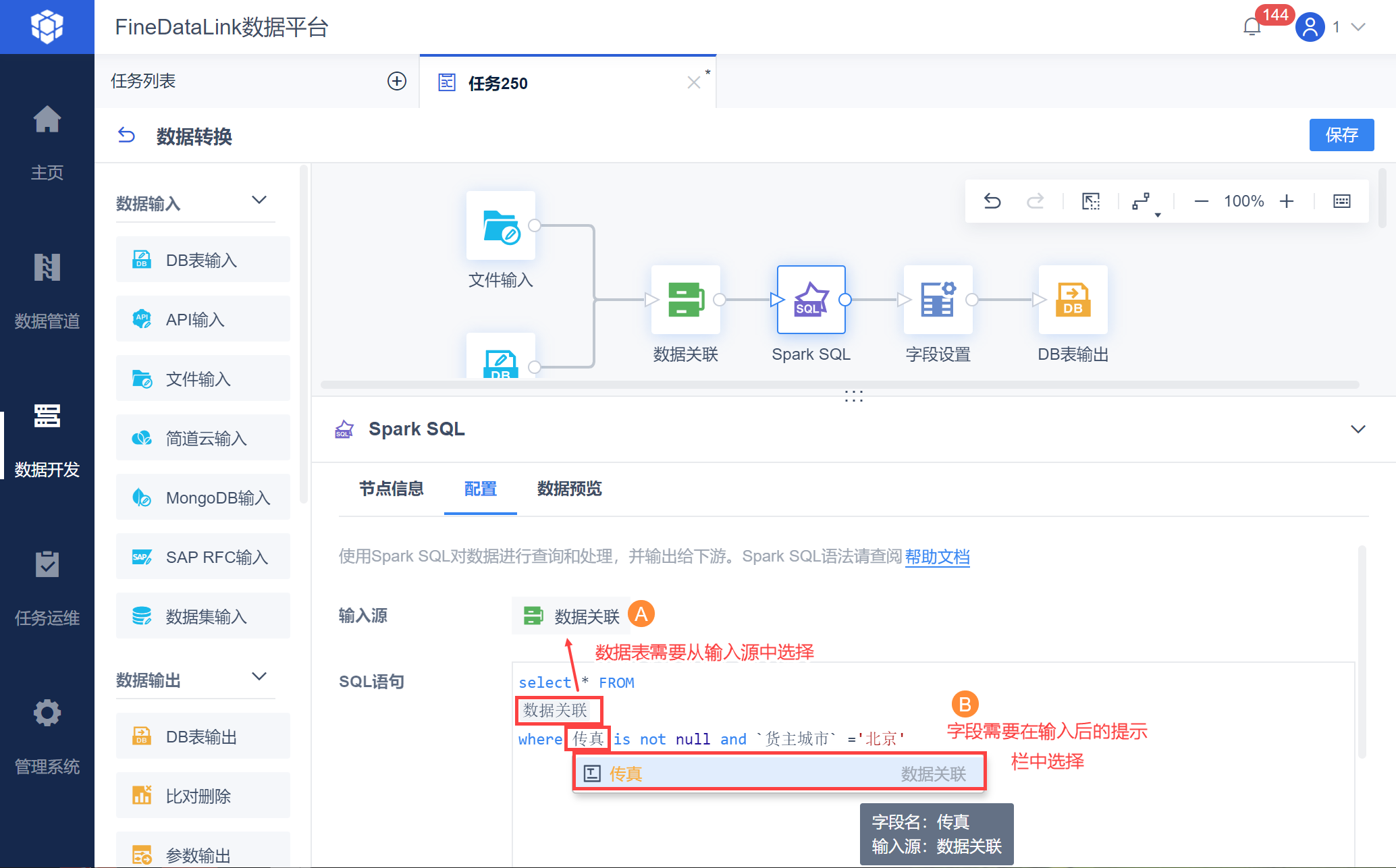
2. 常用语法编辑
示例提供一张数据表,后续展示不同的 SparkSQL 语法取数后的效果。
2.1 group by分组
注:尽量避免使用 DISTINCT 进行排重,特别是大表操作,用 GROUP BY 代替。
示例:select id from ab group by id
结果如下图所示:

2.2 sum
sum(col):对指定列求和(包含重复值)。
sum(DISTINCT col):对指定列求和(不包含重复值)。
示例 1:select id,sum(math) from ab group by id
示例 2:select id,sum(distinct math) from ab group by id
结果如下图所示:

2.3 count
个数统计。
count(*):统计检索出的行的个数,包括 NULL 值的行。
count(expr):返回指定字段 expr 的非空值的个数。
count(DISTINCT expr[, expr_.]):返回 expr 是唯一的且非 NULL 的行的数量。
示例 1:select count(*) from ab
示例 2:select count(english) from ab
示例 3:select count(distinct english) from ab
结果如下图所示:

2.4 max
注:数值类型的数据才能使用 max ,所以本节示例需把 math 列改为 int 类型。
max(col):返回指定列的最大值。
示例:select max(math) from ab

2.5 min
注:数值类型的数据才能使用 min ,所以本节示例需把 math 列改为 int 类型。
min(col):返回指定列的最小值。
示例:select min(math) from ab
结果如下图所示:

2.6 union
注:本节只讲 union 语法的使用,ETL 任务完整设计请参见:Spark SQL算子
用于合并两个或多个 SELECT 语句的结果集。
UNION:会去除完全重复的。如果不为了去除重复行,建议使用 UNION ALL,并且效率会更高。
示例: SELECT `name` FROM a1 UNION SELECT `name` FROM a2
UNION ALL :对查询的数据集取并集,不会去除重复行。
示例: SELECT `name` FROM a1 UNION ALL SELECT `name` FROM a2
2.6.1 数据准备
本节不用本文第二章的表,所使用的表数据如下所示:

2.6.2 设计界面
1)新建任务,将一个「数据转换」节点拖到设计界面。
拖入两个DB表输入算子,重命名为 a1,a2,使用 SQL 与筛选出表a1,a2的全部数据:select * from a1、select * from a2。
再拖入Spark SQL 算子,与两个DB表输入算子连线。如下图所示:
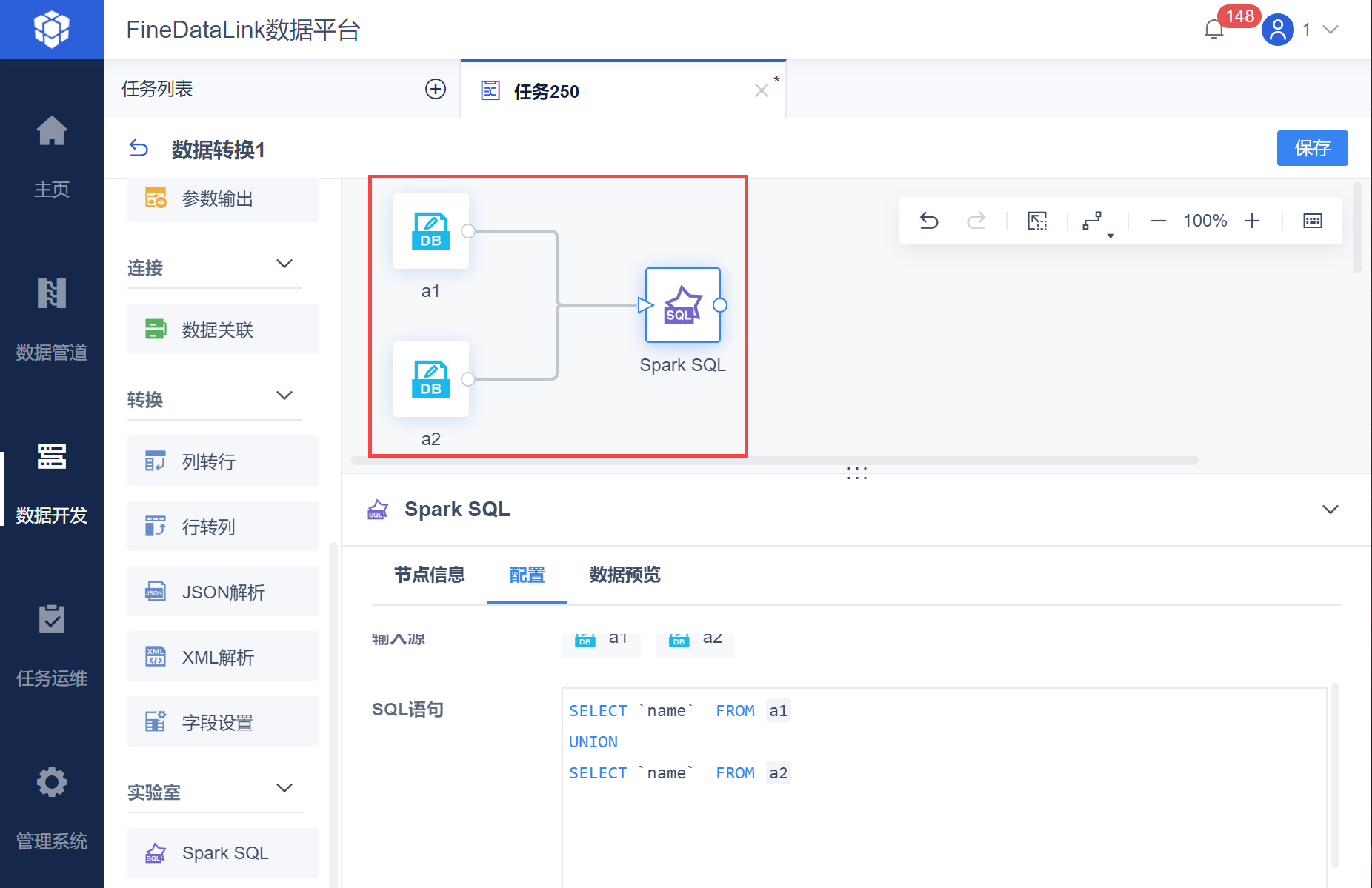
2)Spark SQL 算子的 SQL 语句为:SELECT `name` FROM a1 UNION SELECT `name` FROM a2 ,效果如下图所示:
注:语句不能直接复制,a1、a2需点击生成。

Spark SQL 算子的 SQL 语句为:SELECT `name` FROM a1 UNION ALL SELECT `name` FROM a2,效果如下图所示:

2.7 新增列
本节提供两种方案。
1)方案一:将某个固定的常量定义为一个新字段
新增 type 列,值为测试 。SQL 语句为:select `name` ,'测试' AS type from ab
结果如下图所示:

2)方案二:利用已有字段通过数学计算方式增加一个字段
新增 biaoji 列,数学成绩大于 90 标记为 1,否则标记为 0。SQL 语句为:select `math` ,if(`math` >90,1,0) AS biaoji from ab

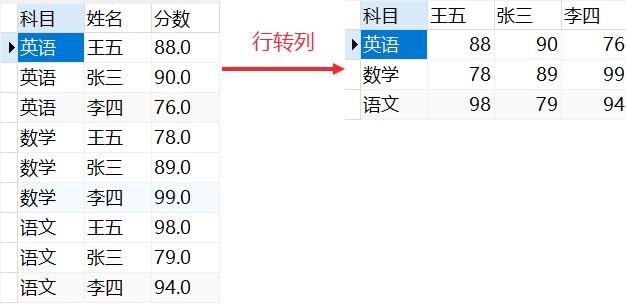
2.8 行转列
推荐您直接使用「行转列」算子。
3. 环境变量编辑
注1:相关函数默认大写。
注2:如需要引入字符串,字符串不区分单双引号:。
| 名称 | FDL的SparkSQL算子内用法 | SparkSQL是否有内置函数 | SparkSQL的内置函数用法示例 | SparkSQL的文档 |
|---|---|---|---|---|
| 随机字符串 | UUID() 示例:SELECT UUID() | 是 | SELECT uuid() 注:不支持改变长度 | https://spark.apache.org/docs/latest/api/sql/#uuid |
| 时间戳(Timestamp) | UNIX_TIMESTAMP() 示例:SELECT UNIX_TIMESTAMP() | 是 | SELECT unix_timestamp() | https://spark.apache.org/docs/latest/api/sql/#unix_timestamp |
示例:
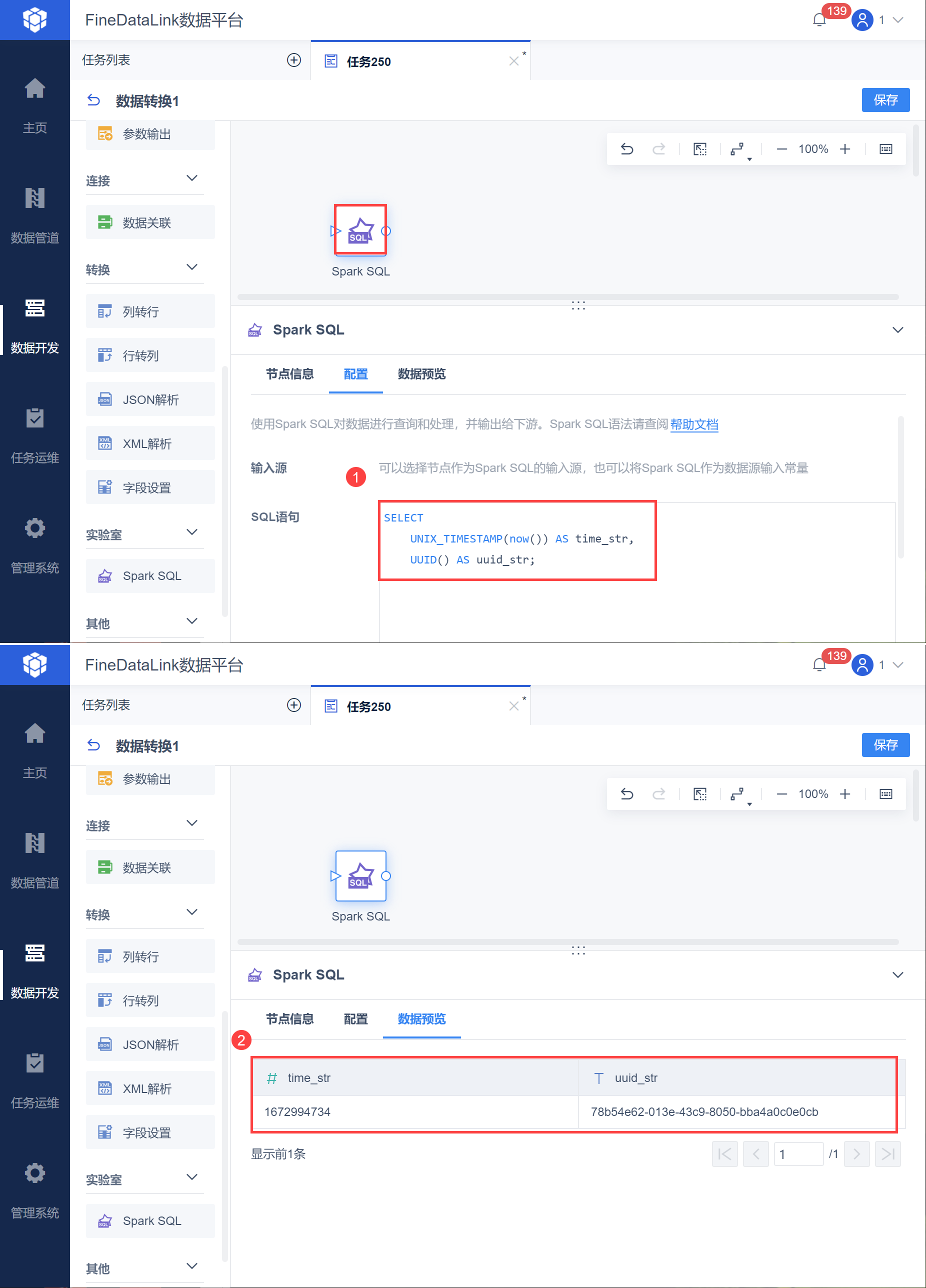
例如,用户需要使用「沃丰接口」取数,接口鉴权方式需要使用 unix time,nonce 为请求的唯一标识,值是由调用者提供的任意字符串,15分钟内此字符串只能被使用一次;在这里我们使用 SQL 的 uuid 函数生成。因此需要使用上述两个环境变量。
直接将 SparkSQL 作为输入源,输入 SQL 语句:
SELECT UNIX_TIMESTAMP(now()) AS time_str, UUID() AS uuid_str;
即可使用环境变量,取出两个指定的值,如下图所示:
4. 编码函数编辑
注1:相关函数默认大写。
注2:如需要引入字符串,字符串不区分单双引号:。
| 名称 | FDL的SparkSQL算子内用法 | SparkSQL是否有内置函数 | SparkSQL的内置函数用法示例 | SparkSQL的文档 |
|---|---|---|---|---|
| Base16Encode | BASE16(expr) 示例:SELECT BASE16('FineDataLink') | 否 | / | / |
| Base64Encode | BASE64(expr) 示例:SELECT BASE64('FineDataLink') | 是 | SELECT base64('Spark SQL') | https://spark.apache.org/docs/latest/api/sql/#base64 |
| URLEncode | URLENCODE(expr) 示例:SELECT URLENCODE('FineDataLink') | 否 | / | / |
5. 加密函数编辑
注1:相关函数默认大写。
注2:如需要引入字符串,字符串不区分单双引号:。
| 名称 | FDL的SparkSQL算子内用法 | SparkSQL是否有内置函数 | SparkSQL的内置函数用法示例 | SparkSQL的文档 |
|---|---|---|---|---|
| MD5 | MD5(expr) 示例:SELECT MD5('FineDataLink') | 是 | SELECT md5('Spark') | https://spark.apache.org/docs/latest/api/sql/#md5 |
| SHA | SHA(expr) 示例:SELECT SHA('FineDataLink') | 是 | SELECT sha('Spark') | https://spark.apache.org/docs/latest/api/sql/#sha |
| SHA1 | SHA1(expr) 示例:SELECT SHA1('FineDataLink') | 是 | SELECT sha1('Spark') | https://spark.apache.org/docs/latest/api/sql/#sha1 |
| SHA2 | SHA2(expr, bitLength) 注:bitLength为SHA2的位数,支持SHA-224、SHA-256、SHA-384和 SHA-512,默认为SHA256。 示例:SELECT SHA2('FineDataLink',256) | 是 | SELECT sha2('Spark', 256) 注:支持SHA-224, SHA-256, SHA-384, and SHA-512,默认为SHA256 sha2('Spark', 224)代表SHA224加密,sha2('Spark')代表SHA256加密 | https://spark.apache.org/docs/latest/api/sql/#sha2 |
| RSA | RSA(expr,secretKey,keyFormat) 注:secretKey为输入的秘钥、格式为base64编码,keyFormat为秘钥格式、值为'PKCS1'和'PKCS8'(不区分格式的大小写),本函数返回值格式也为base64编码 示例:SELECT RSA( 'FineDataLink' , 'MIIBCgKCAQEAnLdoA3ba57YHBAenYbLGTcdC48VVvVVDXV6N/W+1FztBRjvNPV1D | 否 | / | / |
示例:
本文第三节中获取了timestamp、nonce 两个值,签名 sign 为 email 、open_api_token、timestamp、nonce、sign_version 共同组合生成 sign=SHA256(email&open_api_token×tamp&nonce&sign_version),使用了加密函数。
紧接着本文第三节的算子,新增 SparkSQL 并输入
SELECT SHA2(CONCAT("email&open_api_token",time_str,"&",uuid_str,"&v2") ,256) as sign_str,
time_str,
uuid_str
from SparkSQL
6. 签名函数编辑
注1:相关函数默认大写。
注2:如需要引入字符串,字符串不区分单双引号:。
| 名称 | FDL的SparkSQL算子内用法 | SparkSQL是否有内置函数 | SparkSQL的内置函数用法示例 | SparkSQL的文档 |
|---|---|---|---|---|
| HMAC-MD5 | HMACMD5(expr,secretKey) 其中,secretKey为输入的秘钥 示例:SELECT HMACMD5( 'FineDataLink' , 'Im a secret key' ) | 否 | / | / |
| HMAC-SHA1 | HMACSHA1(expr,secretKey) 其中,secretKey为输入的秘钥 示例:SELECT HMACSHA1( 'FineDataLink' , 'Im a secret key' ) | 否 | / | / |
| HMAC-SHA256 | HMACSHA256(expr,secretKey) 其中,secretKey为输入的秘钥 示例:SELECT HMACSHA256( 'FineDataLink' , 'Im a secret key' ) | 否 | / | / |
7. 字符串处理函数编辑
注1:相关函数默认大写。
注2:如需要引入字符串,字符串不区分单双引号:。
| 名称 | FDL的SparkSQL算子内用法 | SparkSQL是否有内置函数 | SparkSQL的内置函数用法示例 | SparkSQL的文档 |
|---|---|---|---|---|
| 小写转大写 | UPPER(expr) 示例:SELECT UPPER('FineDataLink') | 是 | SELECT upper('SparkSql') | https://spark.apache.org/docs/latest/api/sql/#upper |
| 大写转小写 | LOWER(expr) 示例:SELECT LOWER('FineDataLink') | 是 | SELECT lower('SparkSql') | https://spark.apache.org/docs/latest/api/sql/#lower |
| 字符串拼接 | CONCAT(expr1, expr2, ..., exprN) 示例:SELECT CONCAT('Fine','Data','Link') | 是 | SELECT concat('Spark', 'SQL') | https://spark.apache.org/docs/latest/api/sql/#concat |
| 左截断 | LEFT(expr, len) 示例:SELECT LEFT('FineDataLink',4) | 是 | SELECT left('Spark SQL', 3) | https://spark.apache.org/docs/latest/api/sql/#left |
| 右截断 | RIGHT(expr, len) 示例:SELECT RIGHT('FineDataLink',8) | 是 | SELECT right('Spark SQL', 3) | https://spark.apache.org/docs/latest/api/sql/#right |
| 字符串截取 | SUBSTR(expr, pos, len) 示例:SELECT SUBSTR('FineDataLink',5,4) | 是 | SELECT substr('Spark SQL', 5, 1) | https://spark.apache.org/docs/latest/api/sql/#substr |