1. 概述编辑
1.1 版本
| FineDataLink 版本 | 功能变更 |
|---|---|
| 3.6.2 | 数据转换节点 新增算子「Spark SQL」算子,可实现较灵活的数据转换功能 |
| 4.0.17 |
|
1.2 应用场景
面对文件数据源、API数据源等非关系型数据的加工处理,我们往往需要将对应数据抽取到数据库后,再利用sql进行加工处理,导致目标数据库产生冗余数据;
Spark SQL算子可实现在FDL产品内便完成对各类数据源的加工处理,包括左右关联、上下关联、分组汇总、排序等;
同时在数据转换可视化算子不够丰富时,可使用Spark SQL算子应对各类数据处理场景。
用户在接入API数据源时,需要进行加密认证,此时可以使用 Spark SQL 加密相关函数和变量获取 token 等。
1.3 功能简介
通过使用 Spark SQL 算子,用户可以获取上游输出的数据,使用 Spark SQL 对其进行查询和处理,并输出给下游。
4.0.17 版本 Spark SQL 算子支持作为输入型算子,可以输入参数或常量,便于进行加密认证等,相关示例详情参见:API取数-加密身份验证&按页数取数。
注1:Spark SQL 兼容通用 SQL 。
注2:Spark SQL 常用语法及介绍请参见:Spark SQL语法
如下图所示:

2. 示例编辑
用户想对文件数据源「订单数据」和数据库数据源「客户数据」进行数据关联,并筛选部分数据。
2.1 创建任务
新建任务,将一个「数据转换」节点拖到设计界面。如下图所示:

2.2 设置数据输入
点击「数据转换」节点,进入编辑界面,参考读取本地数据,将本地 Excel 数据上传到 FineDataLink 系统中,如下图所示:
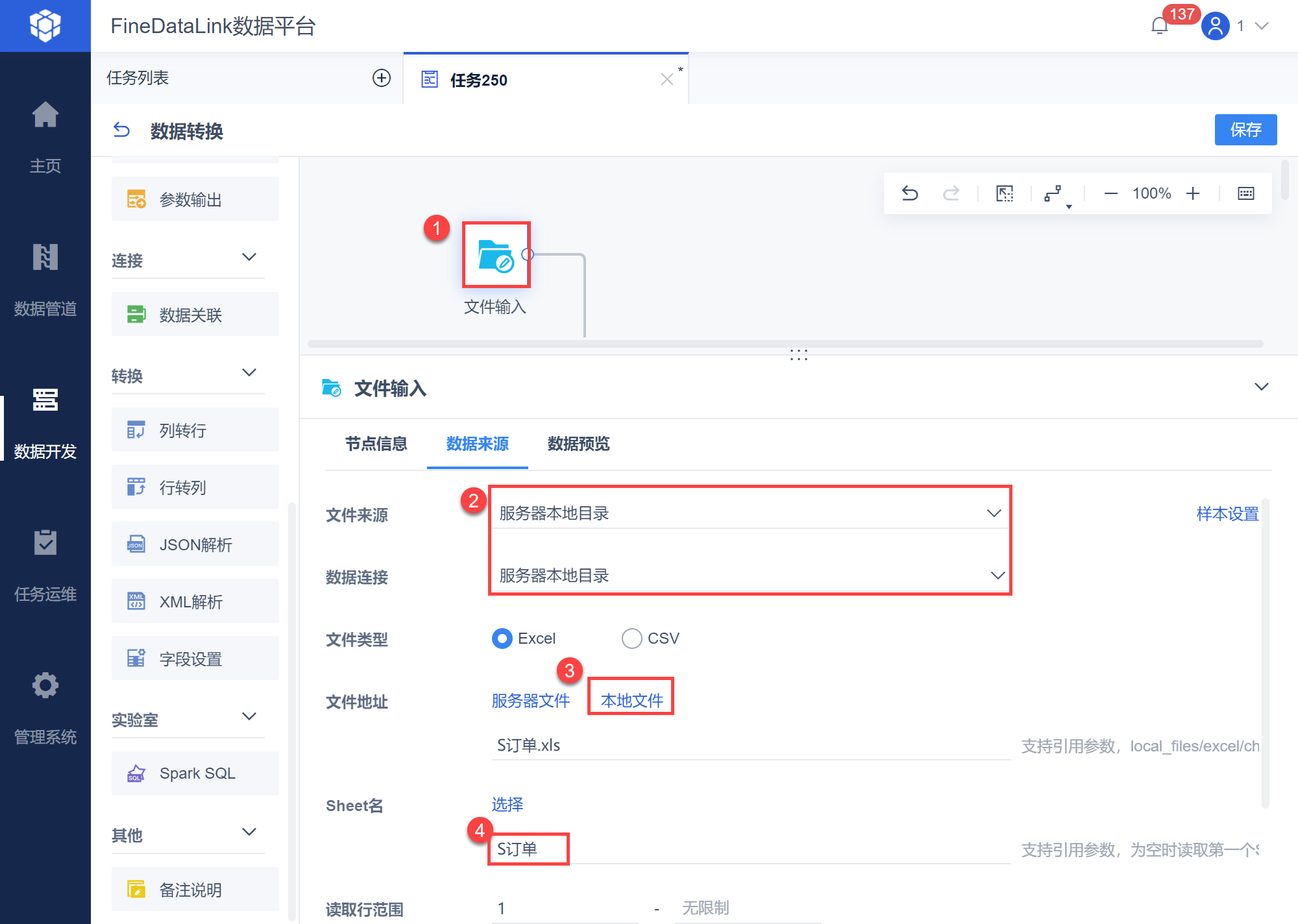
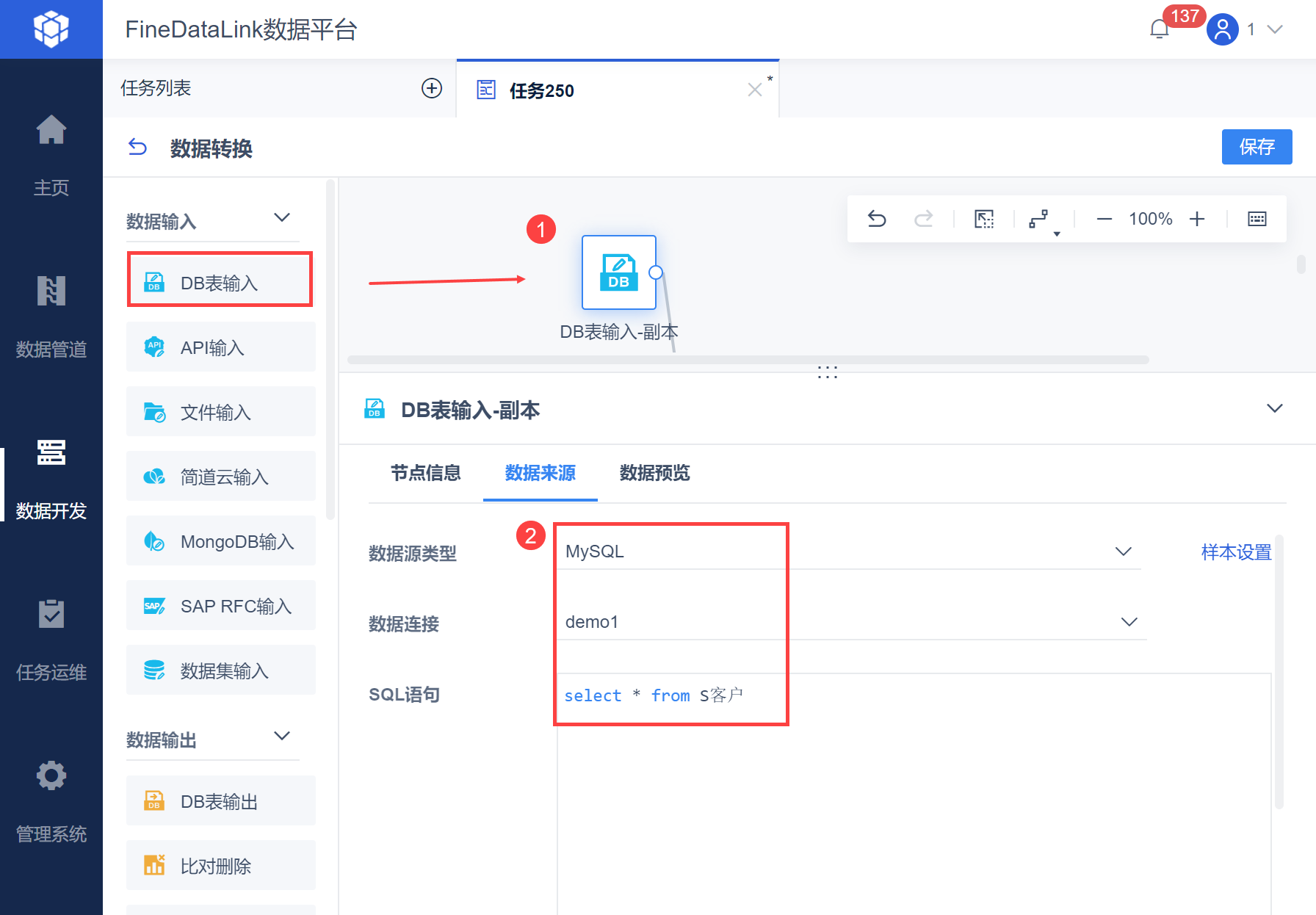
将一个「DB表输入」算子拖到数据转换的设计界面,SQL 语句取出「S客户」表中所有数据。如下图所示:
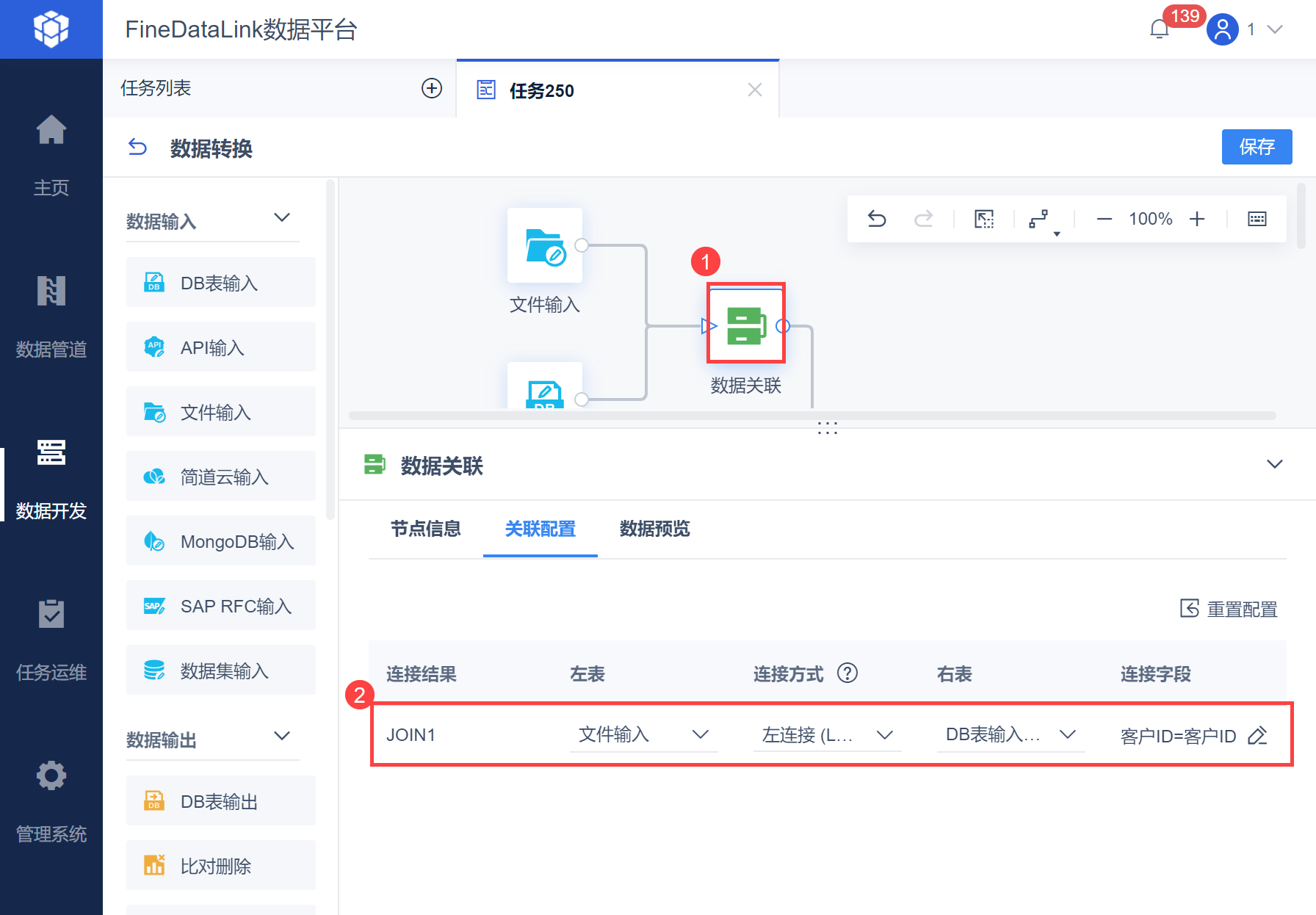
2.3 设置数据关联
设置数据关联,将「订单数据」和「客户数据」根据「客户ID」左连接数据关联,如下图所示:
2.4 设置 Spark SQL 算子
将 Spark SQL 算子拖到数据转换的设计界面,并使用线条跟它的上游「DB表输入」算子相连。配置 Spark SQL ,语句为:
select * FROM 数据关联 where `传真` is not null and `货主城市` ='北京'。如下图所示:
注:表名为上游节点的名称;语句不能直接复制,「数据关联」需点击生成。
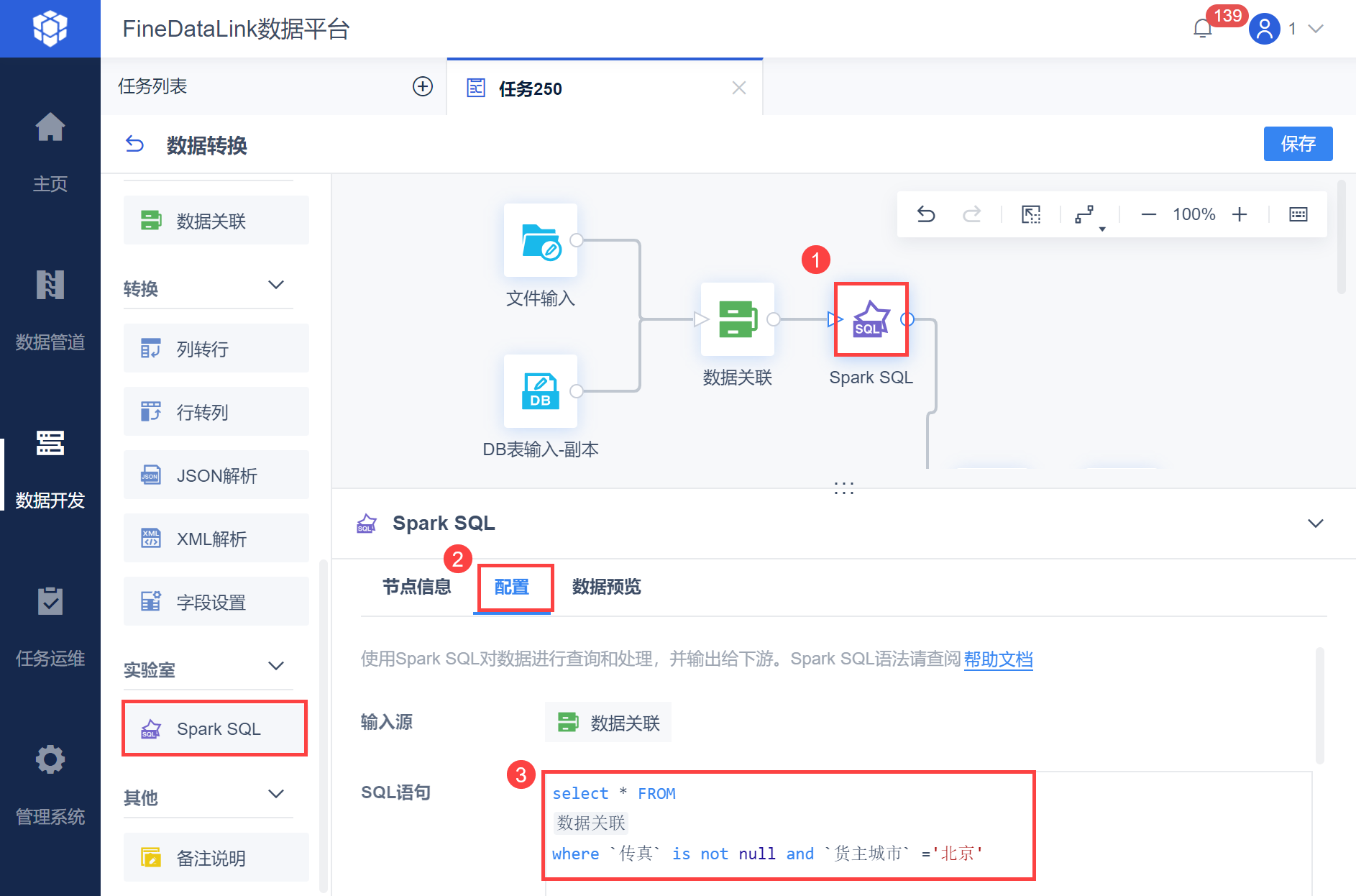
需要注意 SQL 语句的写法,如下图所示:

界面具体设置项介绍如下表所示:
| Tab 页 | 设置项 | 介绍 |
|---|---|---|
| 配置 | 输入源 | 与上游算子相连后,自动获取上游的节点作为输入表,表名即为上游节点的名称 可以接入两类算子:
如果上游算子为空,提示:请接⼊⾄少⼀个节点作为Spark SQL的输⼊源 |
| SQL 语句 | 由用户自定义输入 在输入 SQL 语句时,有联想功能,例如:表名加.就能联想字段名:
| |
| 数据预览 | - | 「配置」界面设置好之后,点击「数据预览」Tab,可预览 Spark SQL 转换后的数据 |

点击「数据预览」,效果如下图所示:

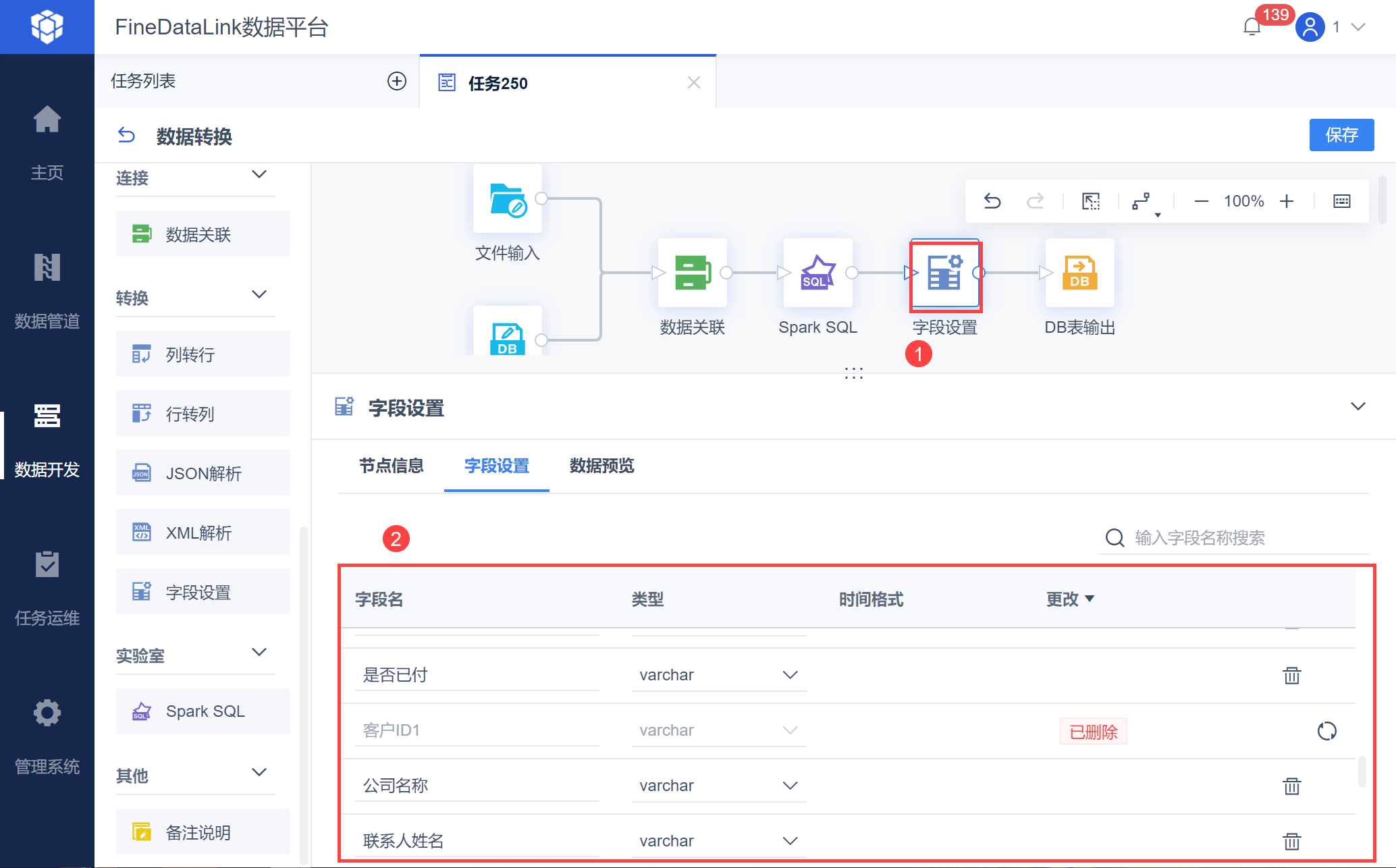
2.5 字段设置
新增「字段设置」算子,可以删减和修改字段名称、类型等,如下图所示:
2.6 设置DB表输出
再将一个「DB表输出」算子拖到设计界面,并使用线条跟它的上游「Spark SQL」算子相连。
点击「DB表输出」算子对它进行设置。如下图所示:

2.7 运行任务
1)点击右上角「保存」按钮。点击右上角「保存并运行」,日志有执行成功信息表示任务成功运行。如下图所示:

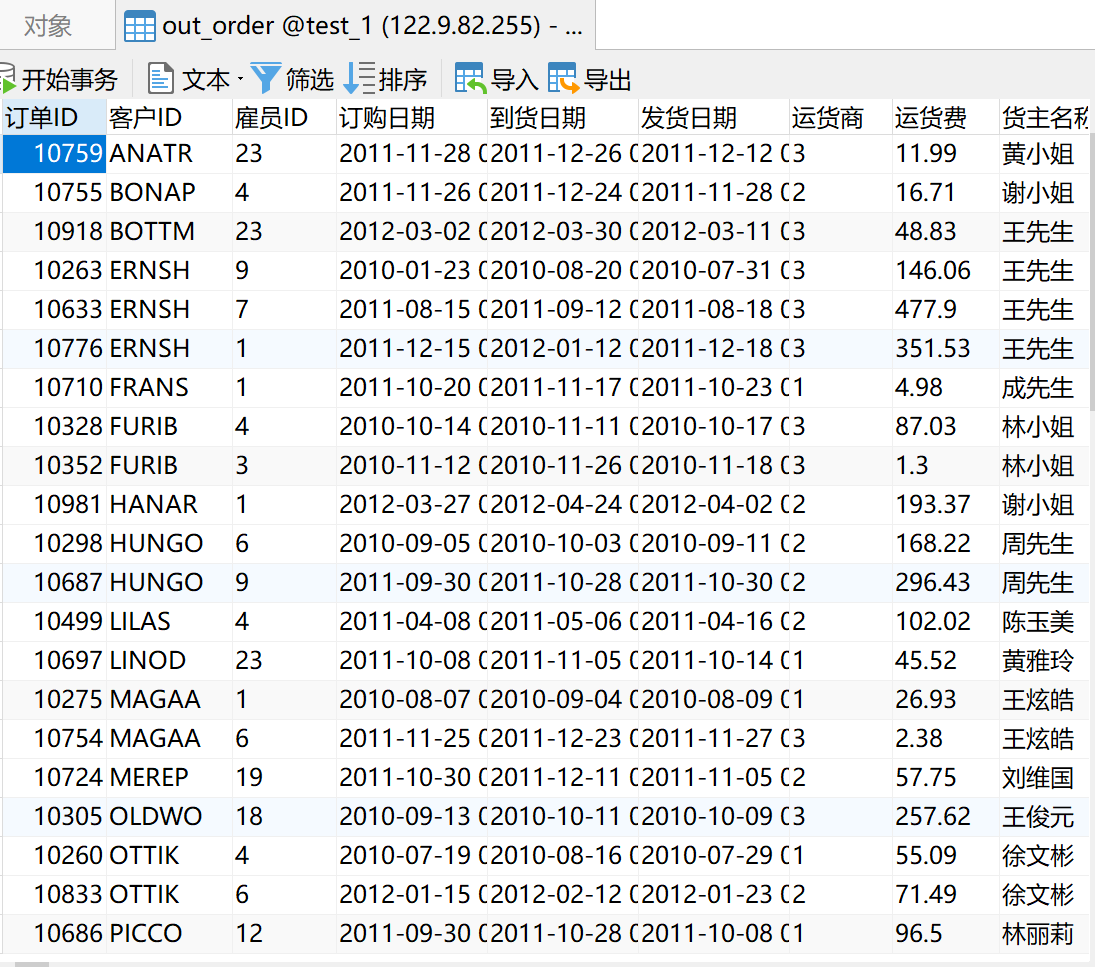
可以看到数据库中新增了一张输出后的数据表「out_order」,如下图所示: