1. 概述编辑
1.1 版本
| 版本 | 功能变动 |
|---|---|
| 4.0.20.1 | 支持0.10.2以上的Kafka版本 |
1.2 应用场景
用户需要将存在 Kafka 中的数据实时取出同步到数据库,并使用取出的数据。
1.3 功能说明
FineDataLink 数据管道支持用户通过配置 Kafka 消费者的方式,实时读取数据至指定数据库。
FineDataLink 会将从 Kafka 读取的字符串,尝试转换成 JSON 格式,如果能进行转换的数据,就会视为有效数据,不能转换的数据会忽略并且不计入脏数据,也不影响任务运行,在日志中会有类似 value is not json format 的报错,且这些数据不会统计在读取和输出的行数里。
2. 前提条件编辑
在使 Kafka 进行实时数据同步前,需要首先建立 Kafka 数据连接,详情参见:配置Kafka数据源
3. 操作步骤编辑
3.1 选择数据来源
选择「数据管道>任务列表>新建管道任务」,如下图所示:
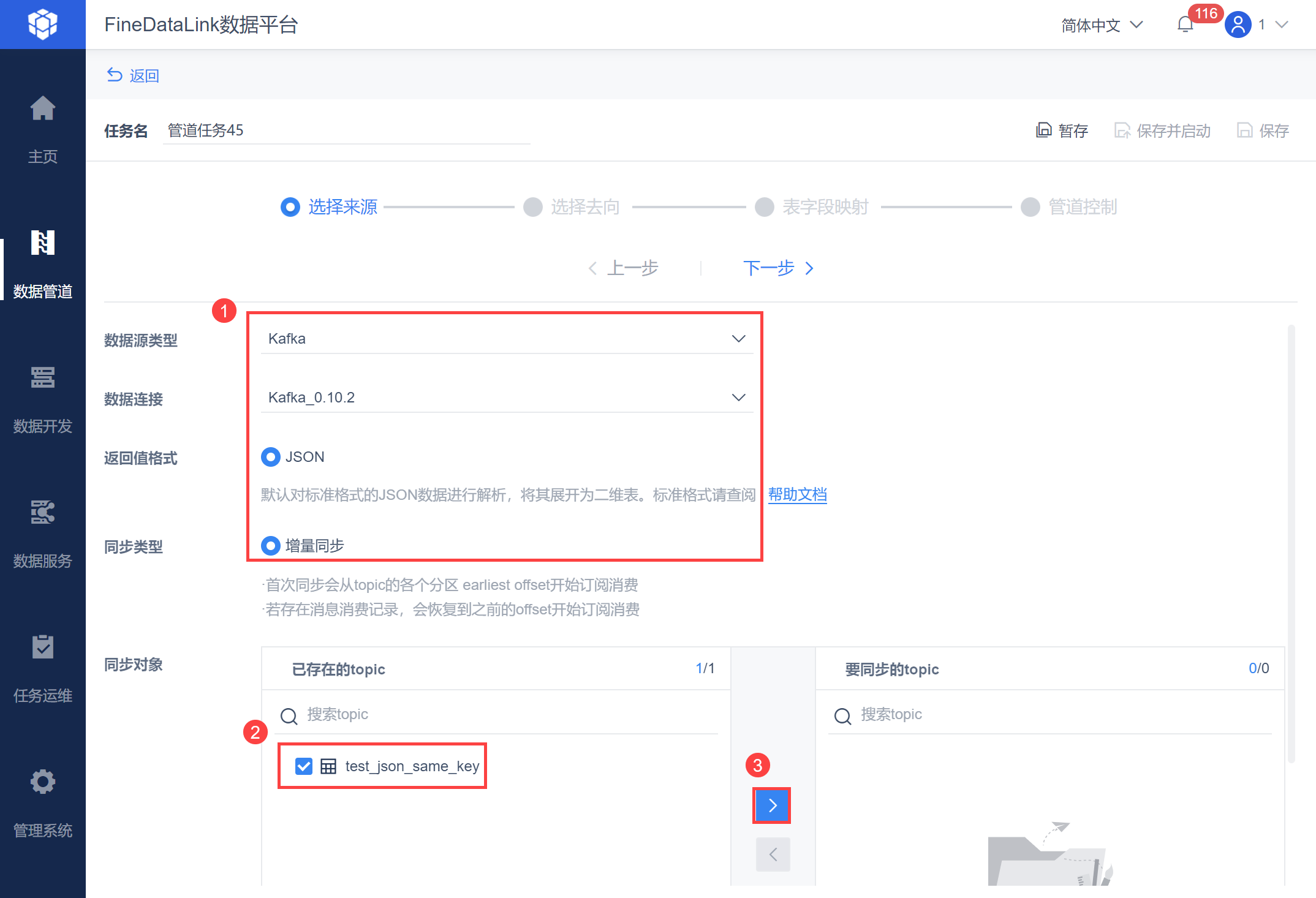
选择需要数据同步的来源数据。
选择 Kafka 数据源类型,并设置指定的数据连接,返回值格式选择JSON ,也就是将从 Kafka 读取的字符串,尝试转换成 JSON 格式,如果能进行转换的数据,就会对标准格式的 JSON 数据解析,转换为二维表进行实时同步。
同时同步类型为存量+增量同步,并选择需要同步的对象,如下图所示:
数据来源配置项说明如下:
配置项 | 配置说明 |
|---|---|
| 数据源类型 | 下拉所有可选的数据源类型。 |
| 数据连接 | 下拉所有可选的对应上述数据源类型的数据连接。 |
| 返回值格式 | 默认为JSON 默认对标准格式的 JSON 数据进行解析,将其解析为二维表 例如: {"id":1, "name": "张三"} [ {"name": "张三"}, {"name": "bbb"}] 注:不支持解析多层嵌套格式的JSON。 |
| 同步类型 | 默认存量+增量同步
|
| 同步对象 |
注:单个任务限制最多选取5000个topic,达到限制时不允许新增选择。 |
3.2 选择数据去向
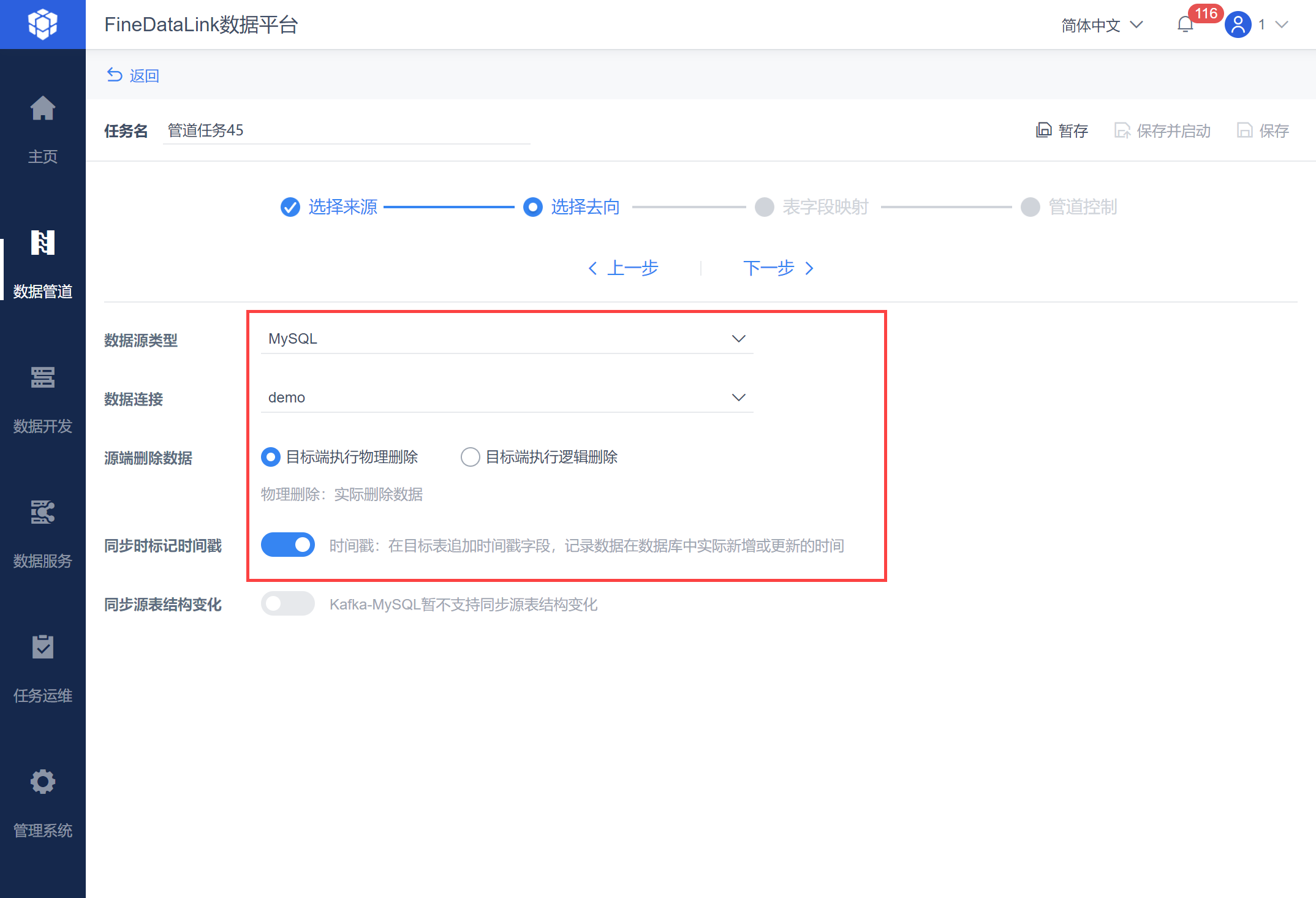
设置实时同步写入数据库,例如选择 MySQL 数据库,并设「目标端执行物理删除」,勾选「同步时标记时间戳」,如下图所示:
注:关于时间戳和逻辑删除标识字段说明,详情参见:设置时间戳和逻辑删除标识字段。
3.3 设置表字段映射
点击下一步进入字段映射设置界面。可以设置目标表名称;对来源表同步至目标表的字段映射进行设置。
注:目标数据库数据表物理主键不为空,以此保证写入数据的唯一性
目标数据表即已经读取并能转换为 JSON 格式的数据解析生成的字段。
可以设置目标表表名,并手动指定有效的主键,如下图所示:
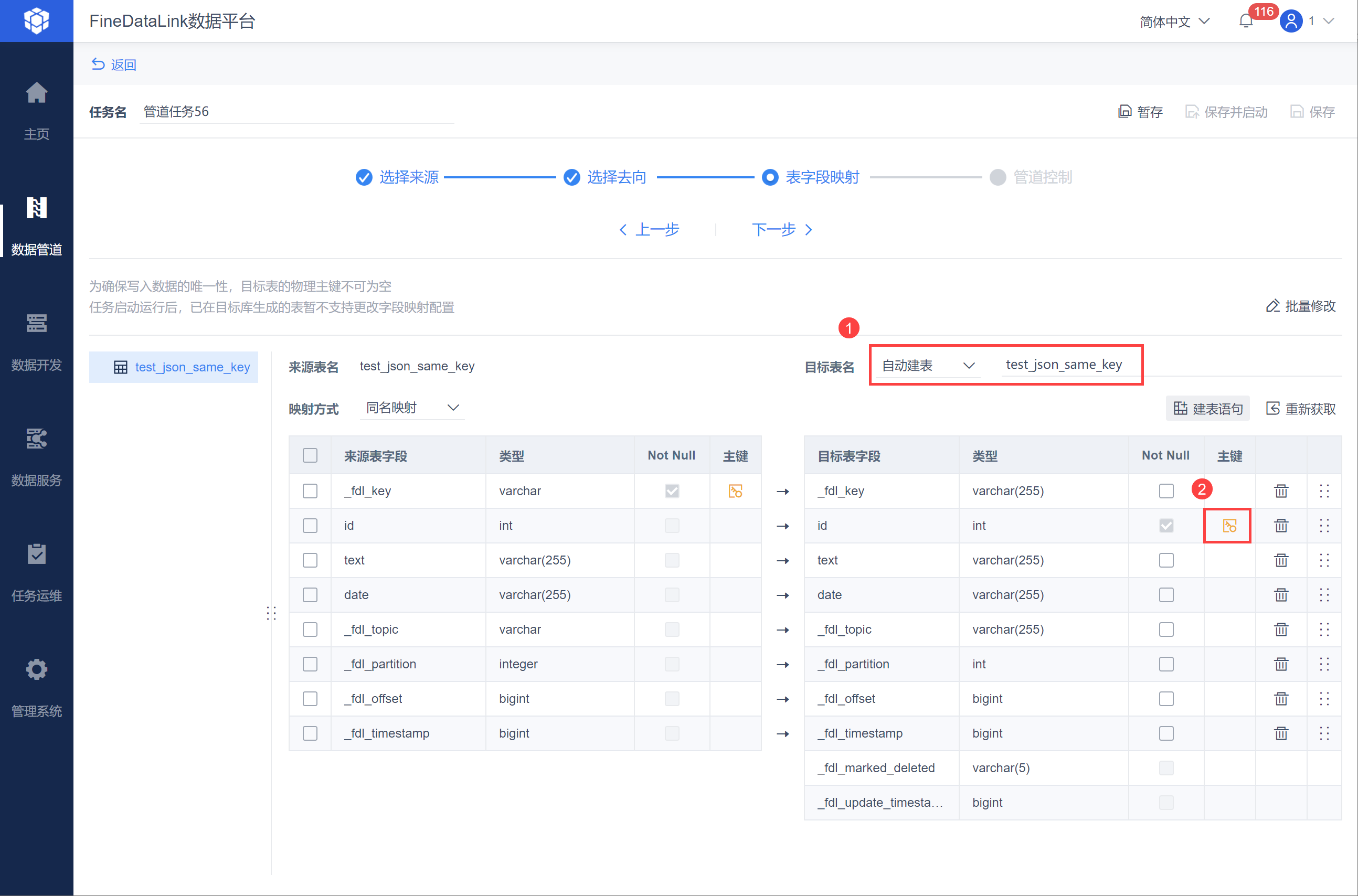
注:对与目标表,由于_fdl_key 值可能为空,所以不提供默认主键,用户可自行选择主键。
解析后的目标表字段说明如下:
| 获取的字段 | 字段说明 | FDL中的字段类型 |
|---|---|---|
| _fdl_key | 消息的key | STRING |
| 数据格式为Json的解析后的字段 | Message记录的headers反序列化得到的二维表数据 | 根据用户表结构获取二维表字段 |
| _fdl_topic | 消息的Topic名称 | STRING |
| _fdl_partition | 当前消息所在分区 | INTEGER |
| _fdl_offset | 当前消息的偏移量 | LONG |
| _fdl_timestamp | 当前消息的时间戳 | LONG |
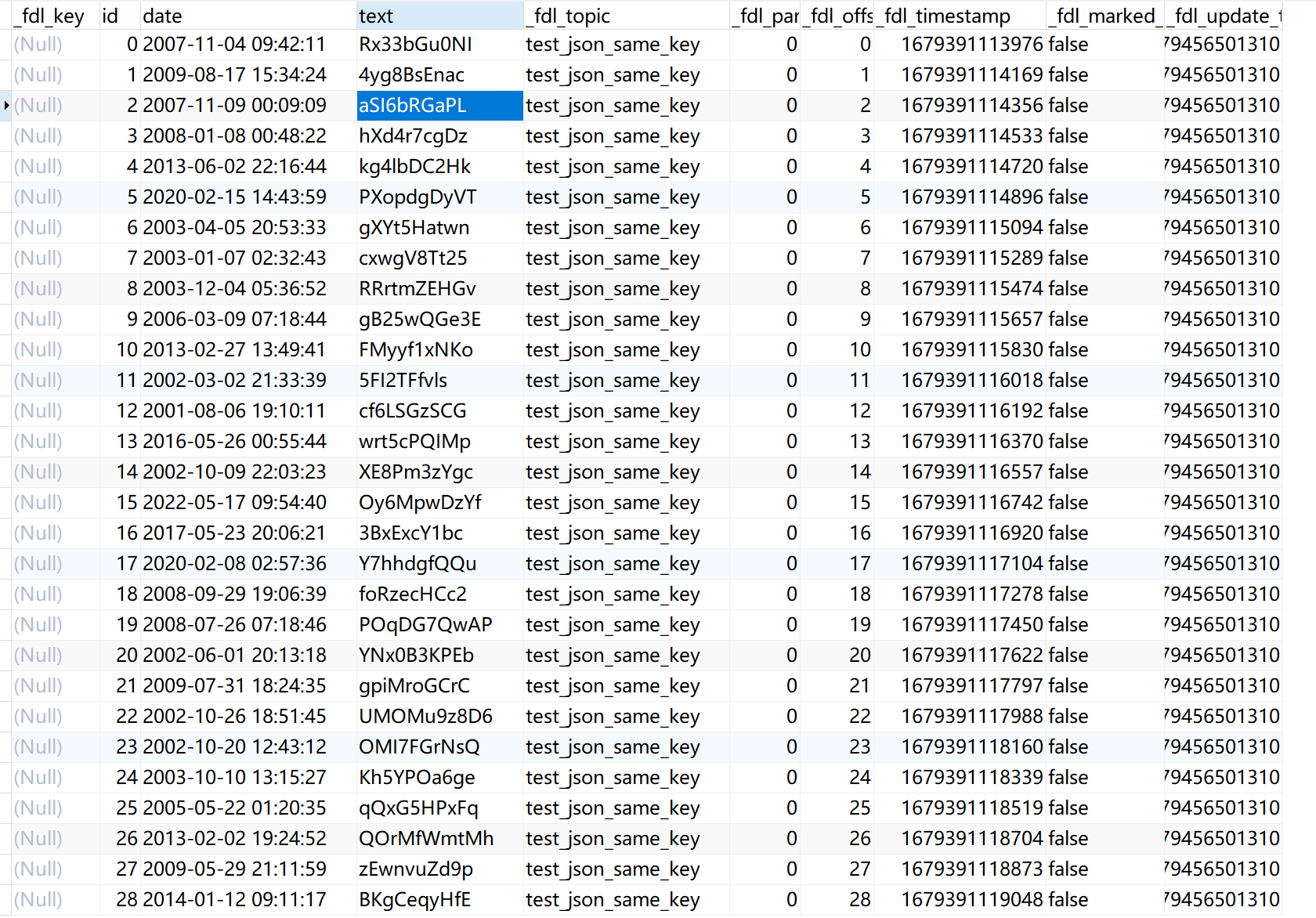
比如来源端读取字符串数据,并解析成的 JSON 数据格式为 {"id": 14, "text": "HhMLQDAGGN", "date": "2010-04-27 06:56:49"}
则解析后目标表字段数据为 id、text、date,如下图所示:
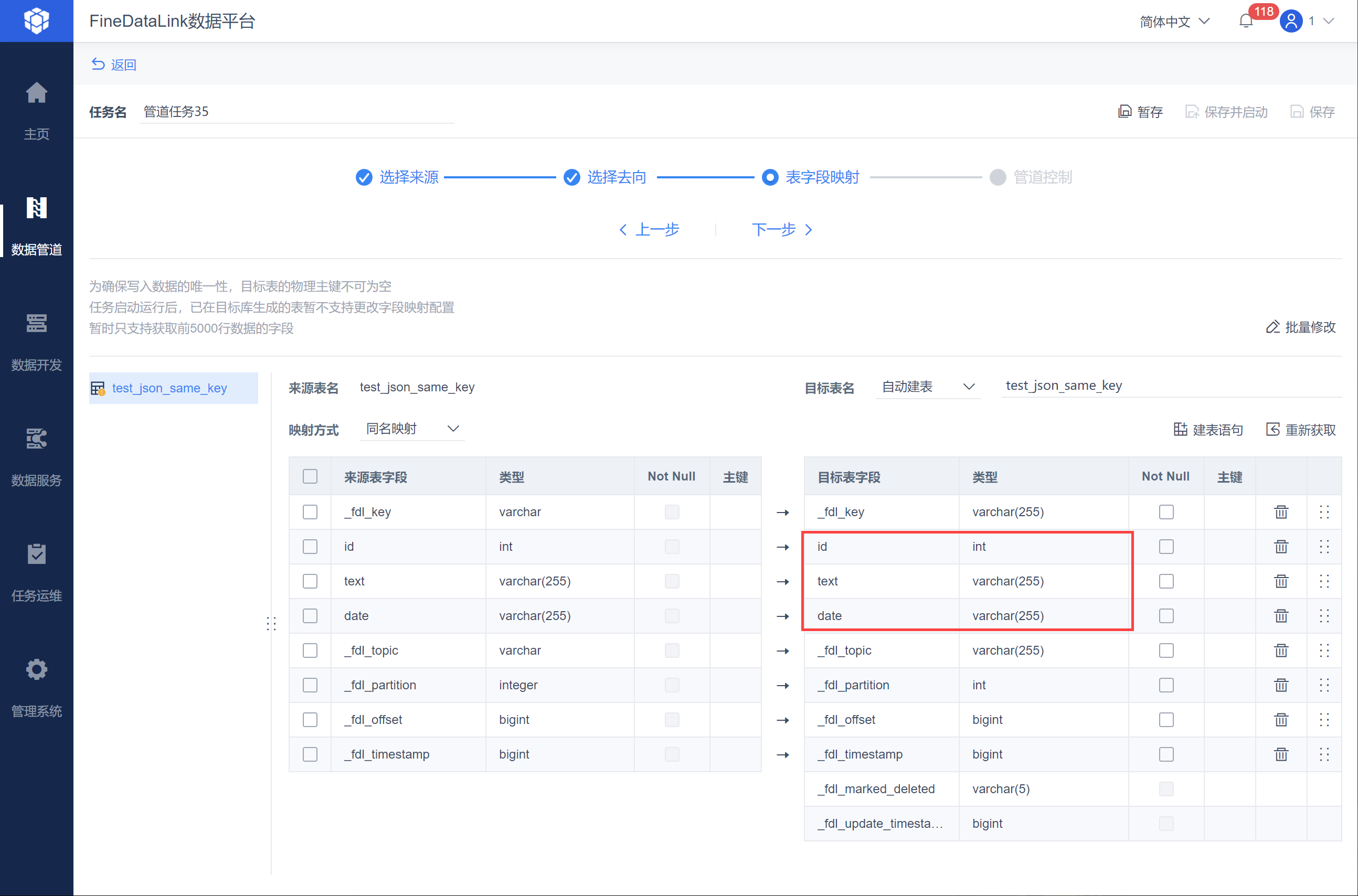
注:目前仅支持获取前 5000 行字段和字段类型,如果某字段在 5000 行之后出现,则在字段映射建表时不会出现该字段。字段类型同理。
3.4 设置管道控制
点击下一步进行数据管道的任务设置。
数据同步允许一定的容错,比如字段类型、长度不匹配、主键冲突等等问题,可以设置产生的脏数据上限,达到上限则自动终止管道任务。
注:限制最多10w行,且重启任务后,会重置阈值统计。
当源表结构变化时,可以将消息通知给指定用户,如下图所示:
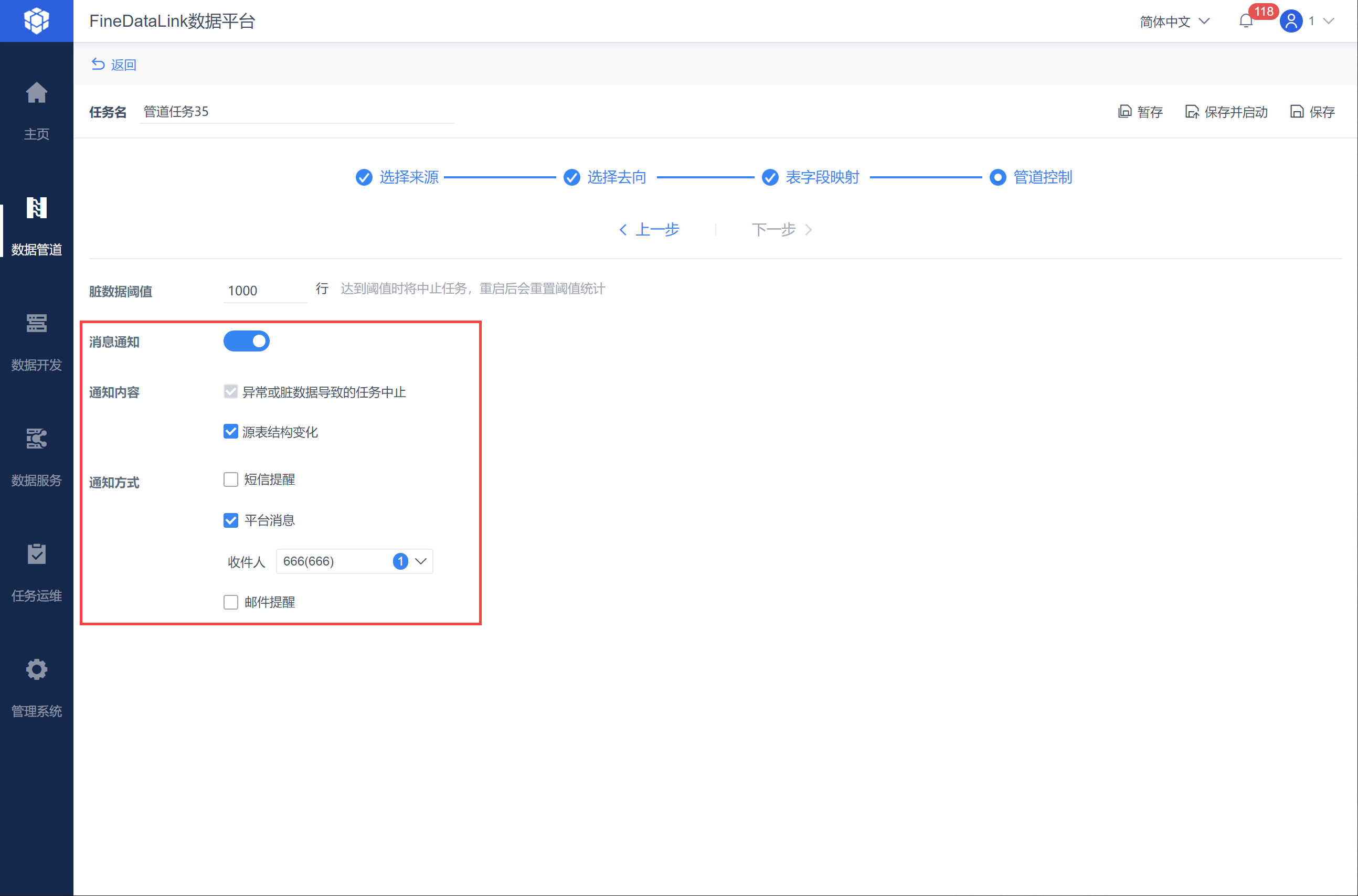
3.5 保存并运行任务
点击「保存并启动」,即可保存并运行任务,如下图所示:
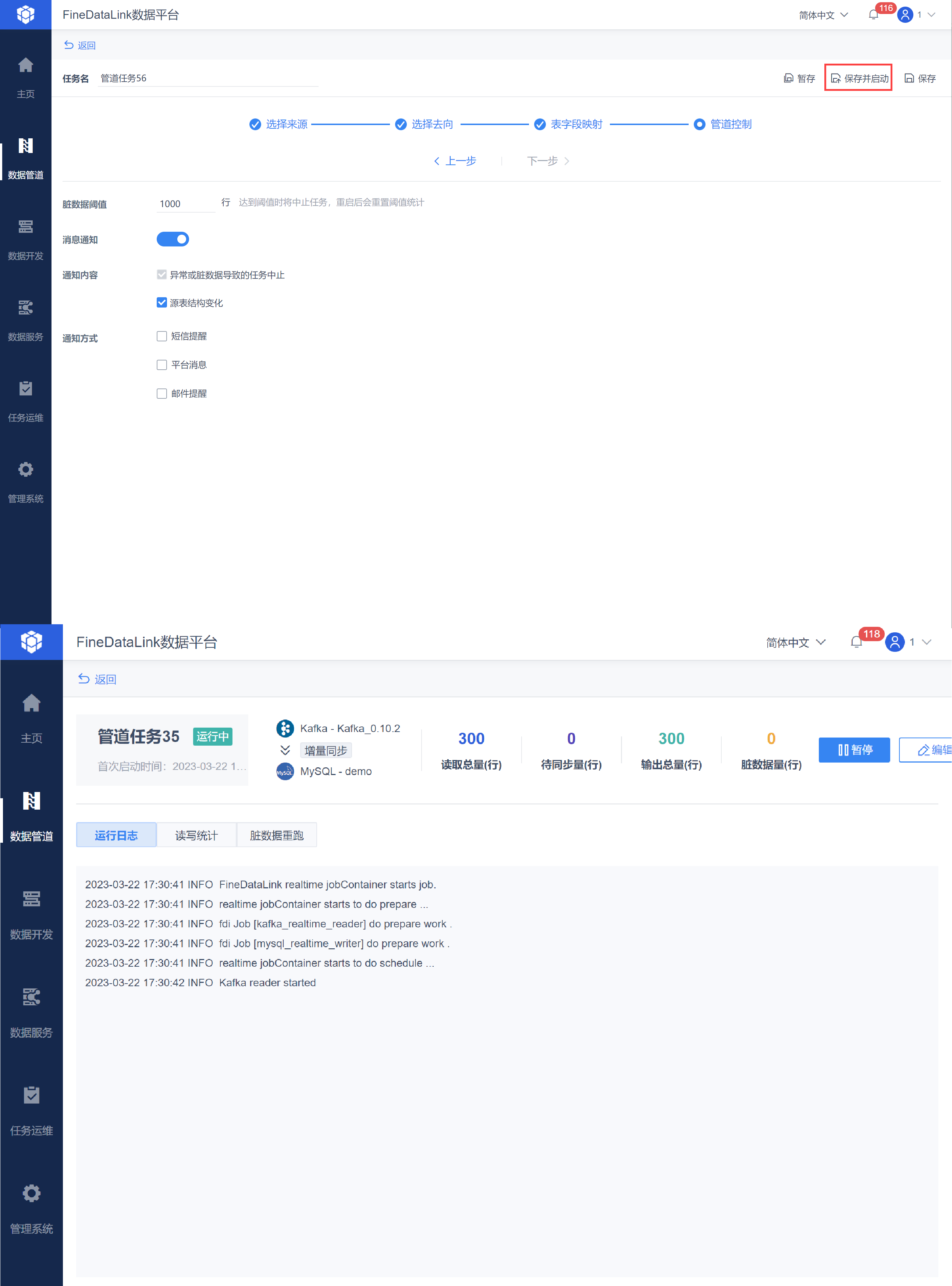
3.6 效果查看
此时即可在目标数据库 已经实现了数据表的实时同步,如下图所示: