1. 概述编辑
1.1 版本说明
| FineDataLink 版本 | 功能变动 |
|---|---|
| 4.0.27 |
|
1.2 功能说明
在设置好管道任务后,FineDataLink 支持对数据实时同步进行监控,查看任务运行情况,快速查看和处理脏数据。
2. 任务运行状况编辑
点击任务列表中的任务,可以看到任务是否在运行中。同时可以手动停止任务,或者是进入任务编辑界面,如下图所示:
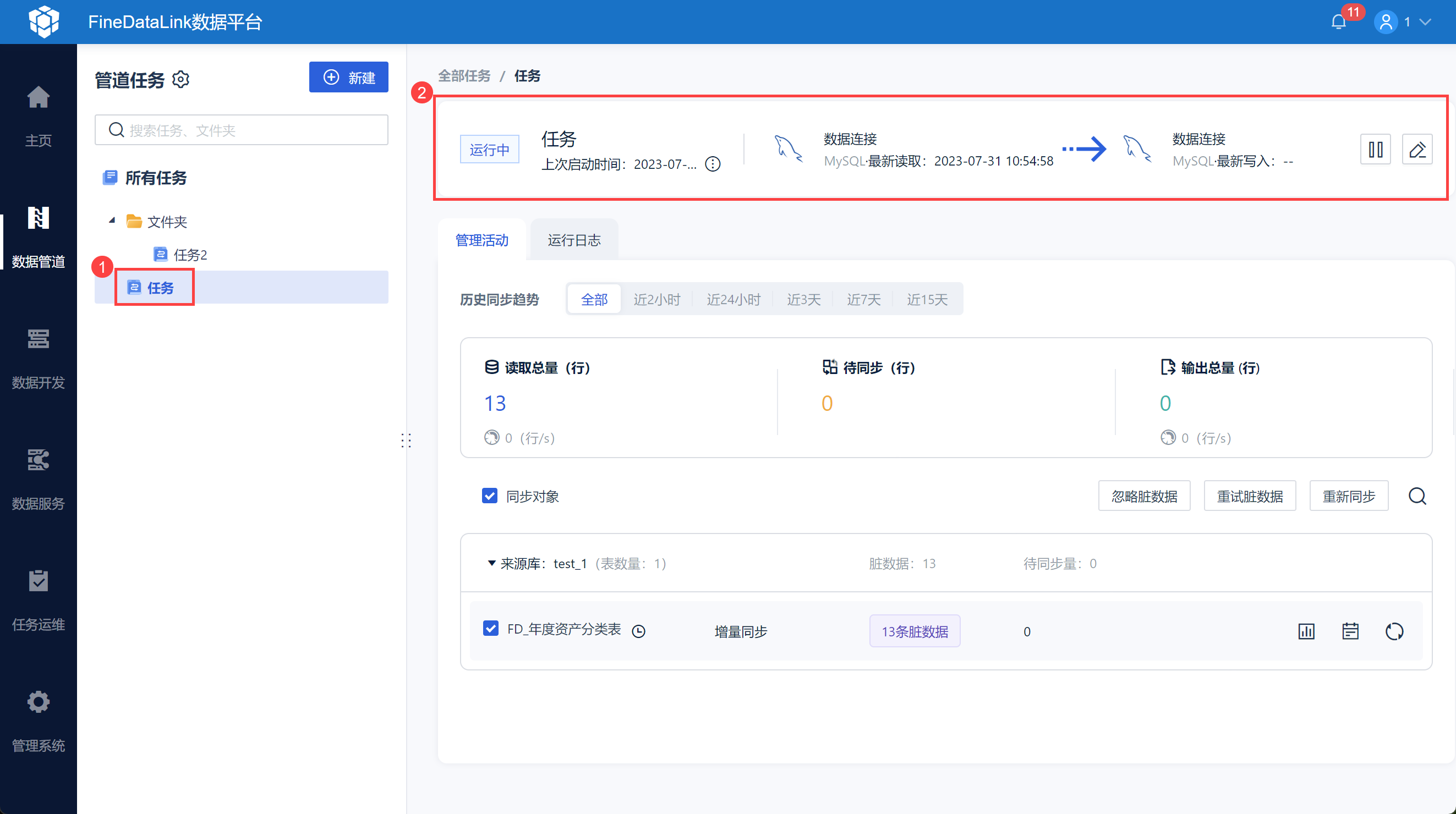
| 任务运行状况展示内容 |
|---|
| 运行状态 |
| 任务最近一次启动时间 |
来源端数据读取时间 目标端数据读取时间 |
来源端数据类型 目标端数据类型 |
| 启动/暂停任务 |
| 进入任务编辑界面 |
3. 统计日志编辑
3.1 时间维度查看实时同步情况
点击「管理活动」即可看到当前任务的历史同步趋势。
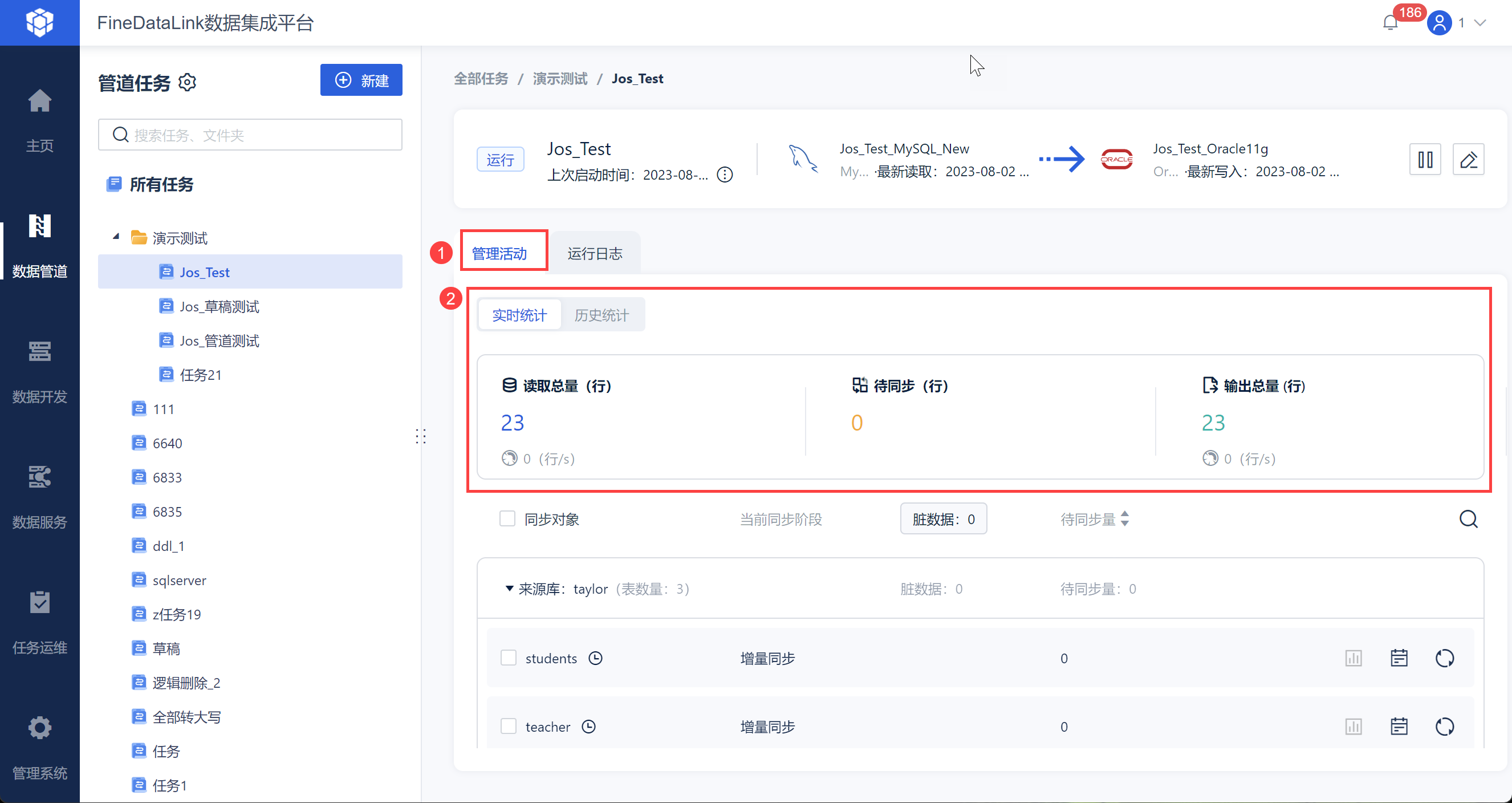
3.1.1 实时统计
点击实时统计,即可查看任务历史读取总量,即任务从首次运行开始一共读取、输出的数据总量、待同步数据量、读取和输出数据的实时速率。
注:若使用了重新同步,单表的读取和写入会被重新计算,「重新同步的数据量」不会累加进「实时统计」的读取总量和输出总量里,但是会累加进「历史统计」中。
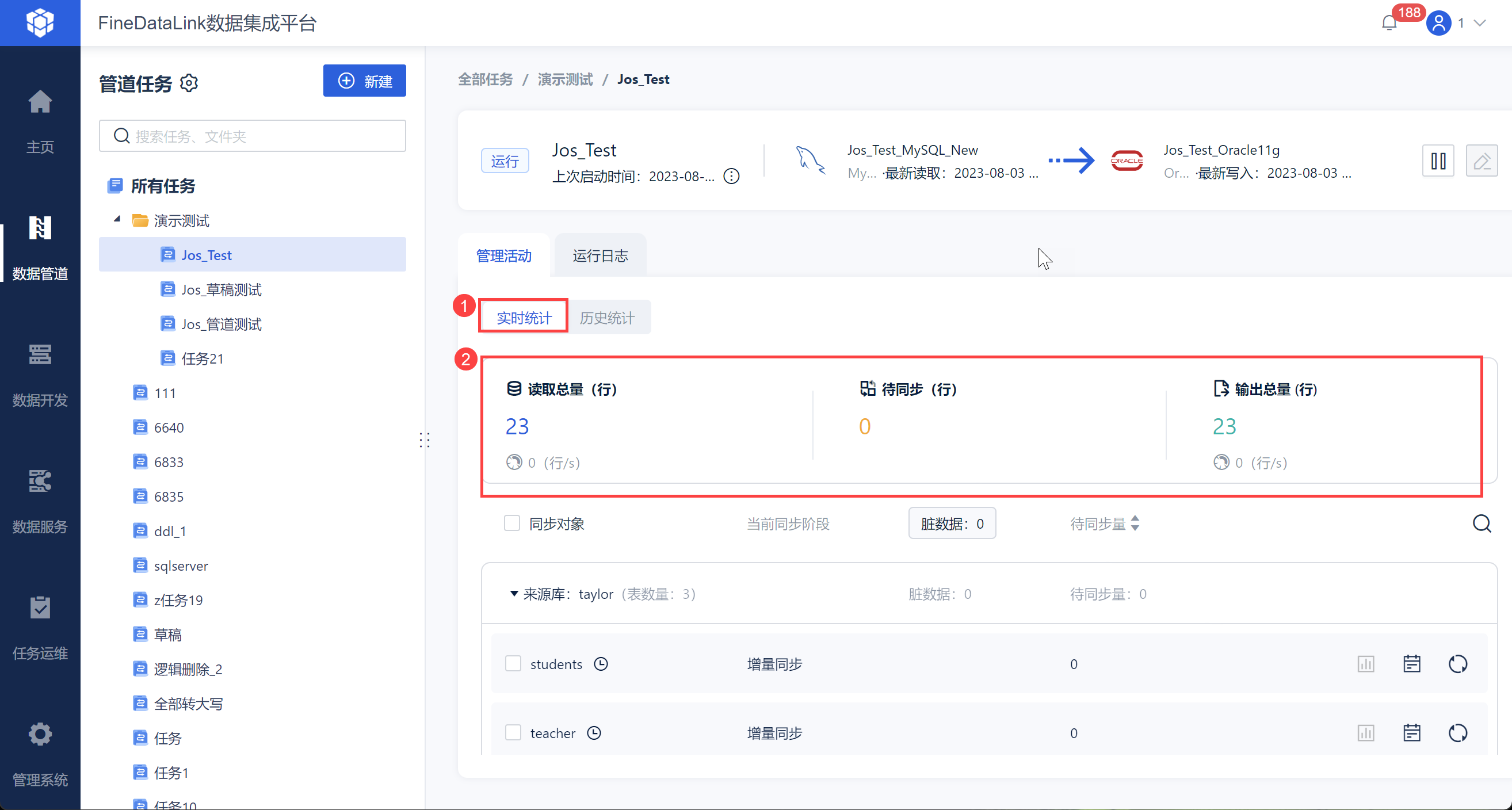
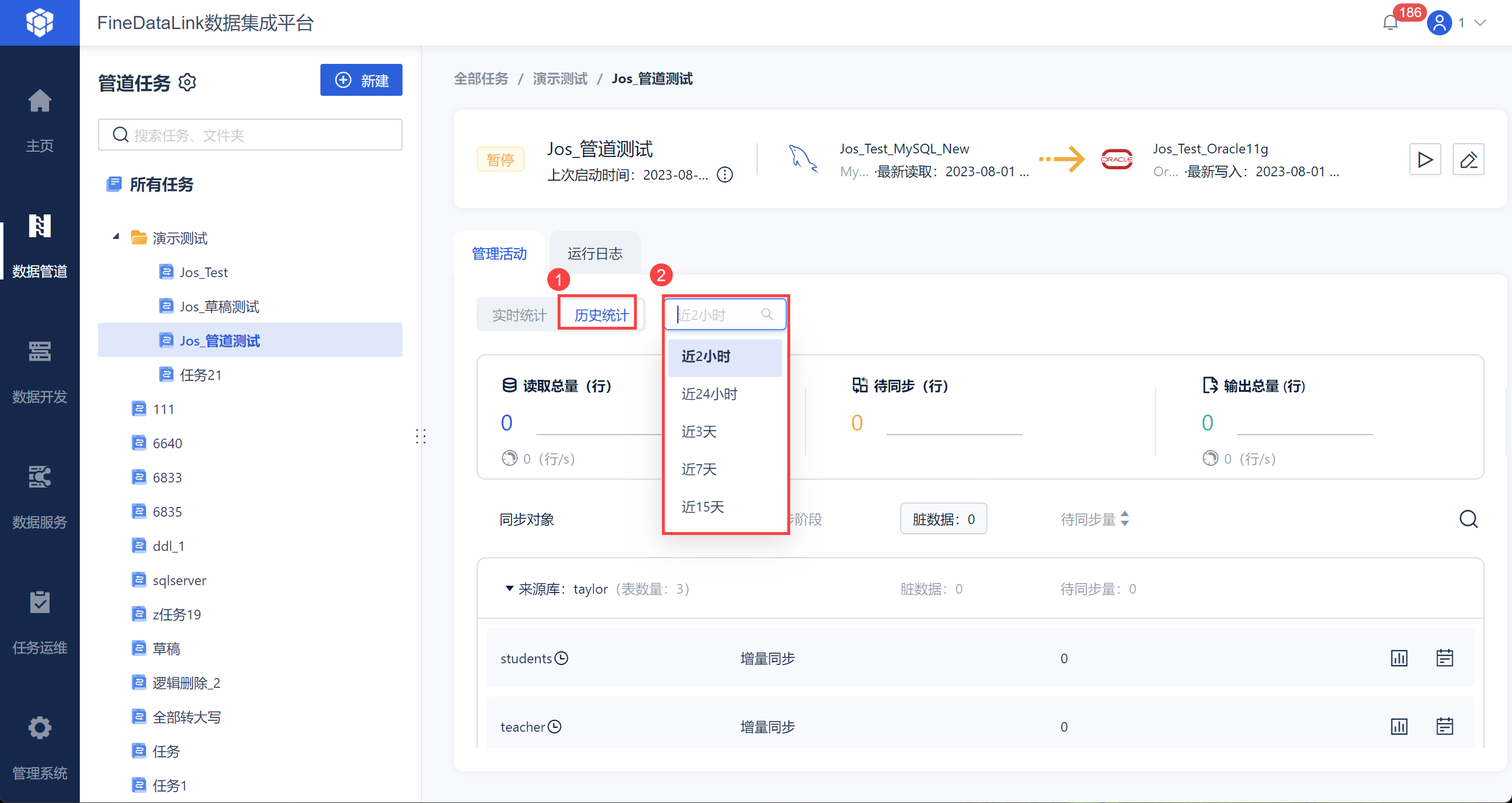
3.1.2 历史统计
点击「历史统计」,用户可以选择近2小时、近24小时、近3天、近7天、近15天等等各种时间段的实时同步详情。
展示同步读取数据总和、待同步行和输出总量、以及读取和输出数据的实时速率(行/s)),如下图所示:
3.2 数据表维度查看同步情况
同步对象模块下可查看到所有来源表的同步情况,如下图所示:
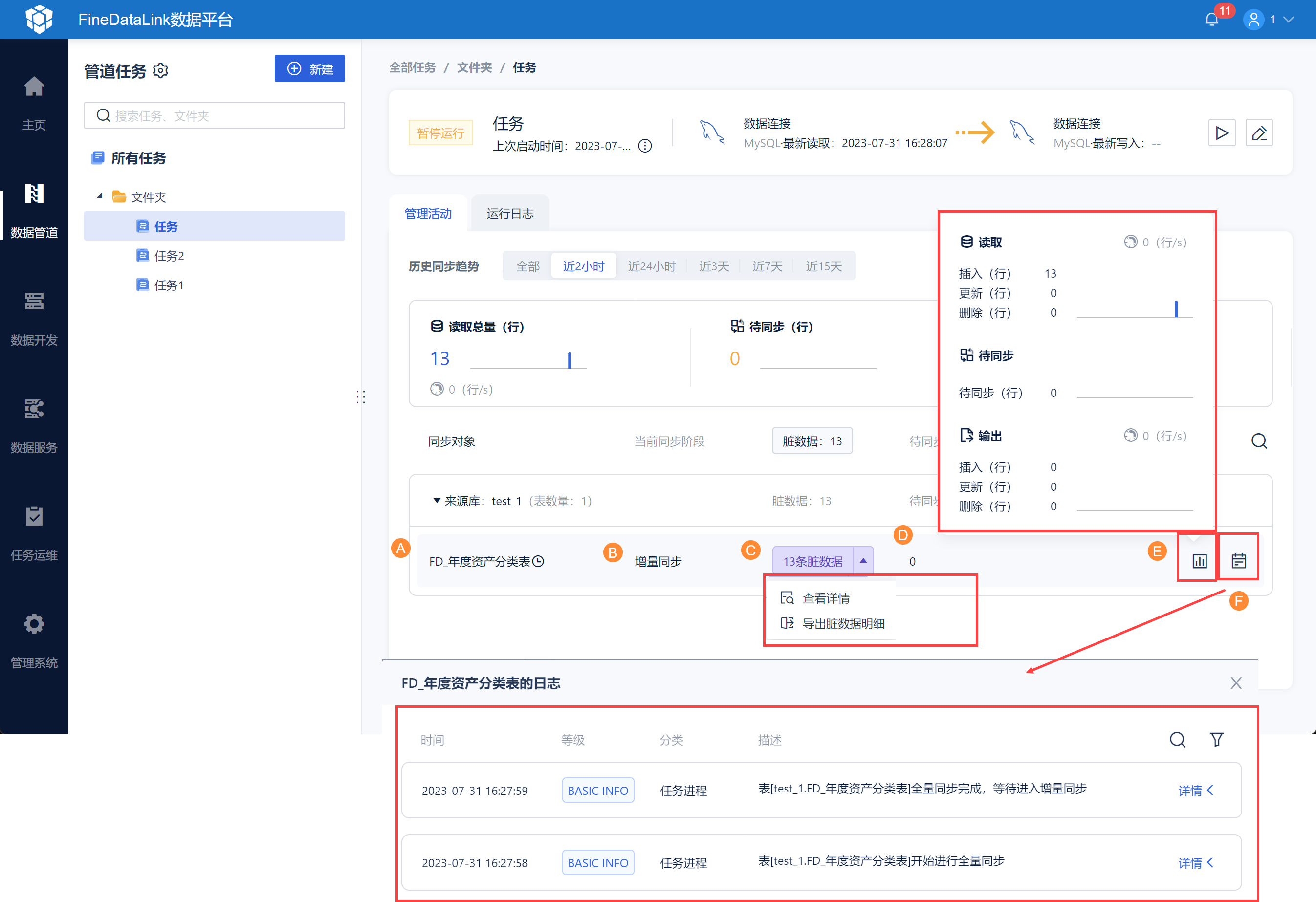
| 功能 | 说明 | |
|---|---|---|
| A | 来源数据表 | 数据表名 |
| B | 同步状态 | 表当前同步阶段:增量同步、存量同步 |
| C | 脏数据 |
注:对于主键字段值由A更新为B的数据,当主键更新事件失败时,拆解为两条脏数据记录:主键为A的数据删除、主键为B的数据upsert; 导出时,按照字段映射配置中的目标端表结构导出; |
| D | 待同步量 | 待同步数据量 |
| E | 读写统计 | 详细描述数据插入、更新、删除条数 显示读写速度 |
| F | 查看日志 | 查看单表任务运行日志 |
3.3 脏数据处理
支持快速查看脏数据、快速定位单条脏数据并对脏数据进行灵活处理。
选择对应的任务,点击全部,即可勾选任务中的单表或者多表,进行脏数据的忽略、重试或者重新同步,如下图所示:

| 处理方式 | 说明 |
|---|---|
| 忽略脏数据 | 对单表和指定多表,忽略功能会将缓存的脏数据进行删除,且删除后不可找回; 同时这部分数据的行数从日志统计的脏数据行数去掉; |
| 重试脏数据 | 对单表和指定多表,重试功能会将缓存的脏数据进行再次提交,并更新数据量统计; 对update事件进行重试可能会覆盖针对该数据后续的update事件; 注:存量同步阶段产生的脏数据不支持重试。 |
| 重新同步 | 支持对单表和整个管道任务进行重新全量同步,会将目标端表清空并重新执行全量同步、在全量同步结束后转入增量同步; 在任务被开启重新全量同步后,日志统计信息会重置(输入行、输出行); 注:若开启逻辑删除标识时,重新同步对目标表清表重写,重写采用insert逻辑,出现提示“任务运行期间产生的逻辑删除数据将会被清空,请确认”。 |
注:当数据源是kafka ,不支持重新同步。
脏数据事件记录逻辑:
若在t1时间点,主键为A的数据产生了脏数据,则在t1的脏数据未被处理前、t1以后的关于主键A的所有数据均计入脏数据队列,原因也记录为与t1的脏数据一致的原因;
若在t1时间点,主键为A的数据被更新为主键为B,则管道应拆解为两个事件进行顺序处理至目标端:Delete A,Insert B;
注意事项:
输出端为批量装载模式的制约
当输出端为批量装载模式时,此时一般会使用一个包括很多数据条数的大批次进行一次性提交数据到目标端,这类数据源可能无法识别到过程中哪些数据出现了脏数据,目前已有的支持批量装载的目标端具体分析如下:
1)GaussDB 200 支持两种写入模式,分别为copy和并行装载:
copy模式:
在全量阶段,当单批次提交失败后,会将这个批次的数据改为调用JDBC接口进行写入(目前单个批次1024条),JDBC写入时能获取到具体错误数据,进而实现脏数据明细展示,但是JDBC方式性能不佳;
在增量阶段,当单批次提交失败后,会将整个批次的数据记为脏数据(目前单个批次最大是5M,约合一般1万行内,具体行数与单条数据大小有关);
并行装载(load):
并行装载时,也是将单次任务内所有需要的数据进行一次性提交,但是并行装载提供接口可以查询具体错误数据,进而FineDataLink 也可以实现脏数据明细查询。
2)HIVE 的HDFS写入方式:
直接一次性写入到HDFS文件、完全无法获取明细错误数据,不支持脏数据管理;
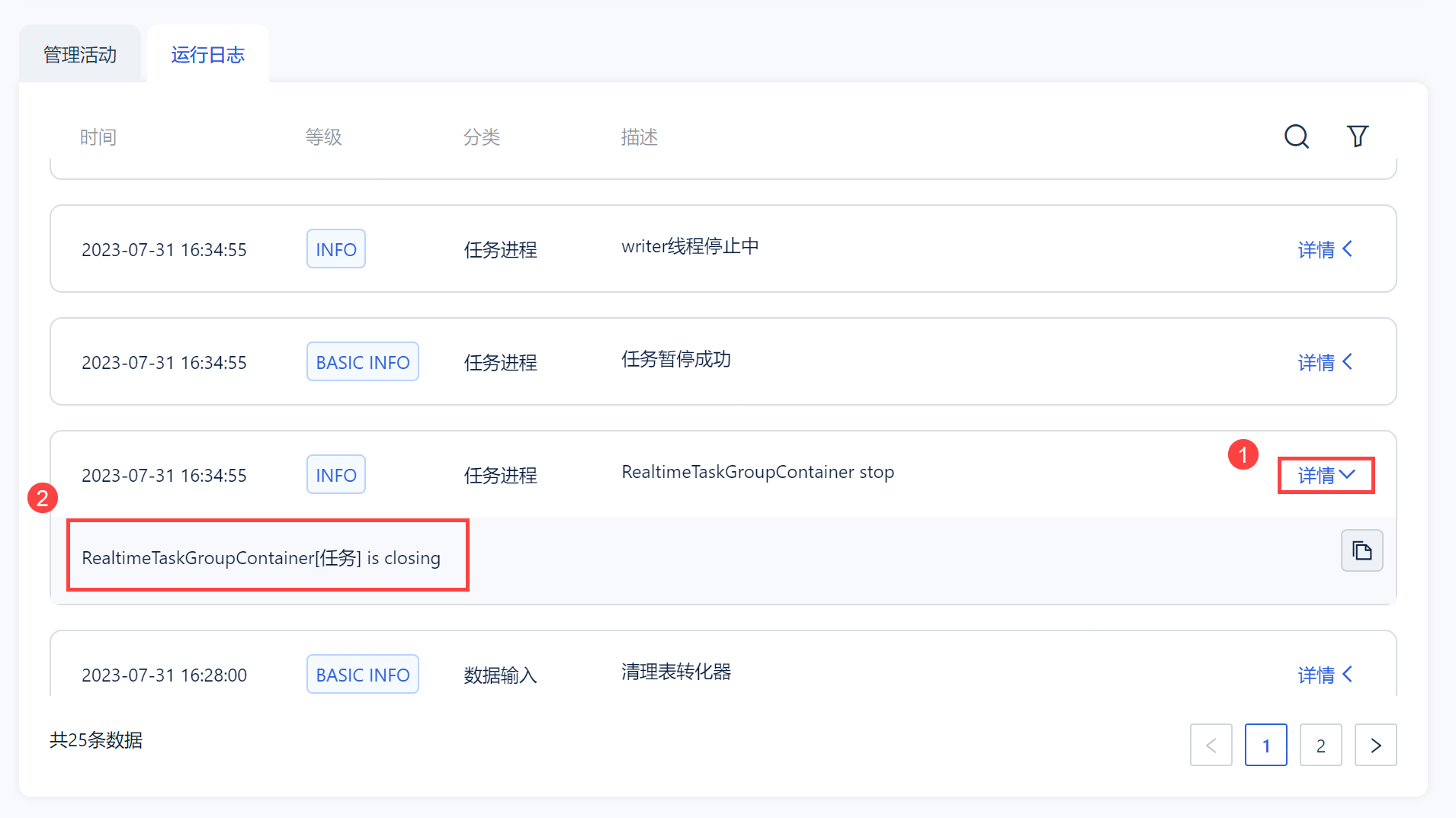
4. 运行日志编辑
4.1 可视化日志
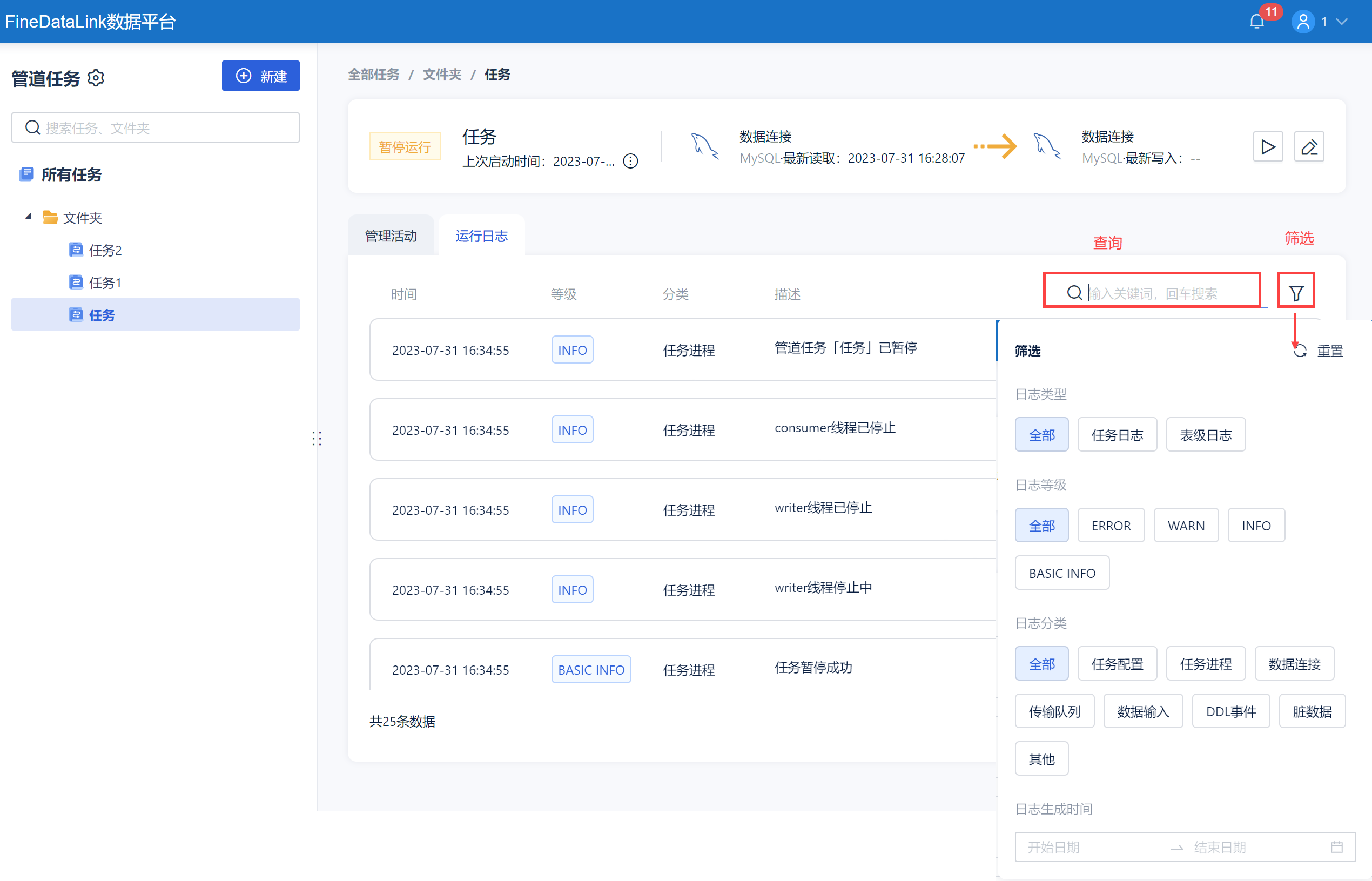
点击「运行日志」即可看到当前管道任务的历史运行日志记录,展示日志的时间、等级、分类、描述,如下图所示:

同时可进行日志查询和筛选,如下图所示:
注:支持根据任务筛选日志和根据表筛选日志,同时可以查看各种类型的日志;也可根据查看断点时间。
4.2 日志等级
日志分为四级:BASIC INFO、INFO、WARN、ERROR 四级。
其中BASIC INFO 作为基础等级的日志。

也可以点击每一条日志对应的详情查看具体的说明,如下图所示: