1. 概述编辑
1.1 应用场景
用户想要同步钉钉通信录中的部门信息和用户信息。
1.2 接口说明
接口文档详情参见:获取部门列表、获取企业内部应用的access_token、获取部门用户详情
1.3 实现思路
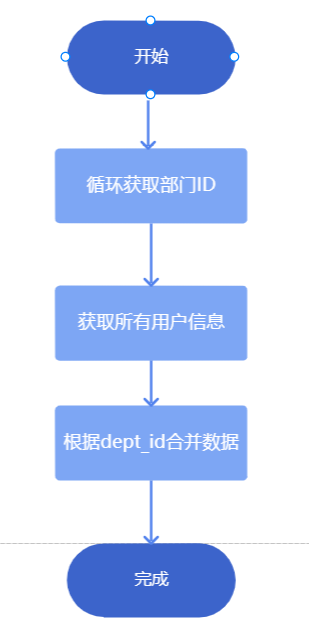
由于接口只能获取当前部门的下一级部门基础信息,不支持获取当前部门下所有层级子部门。因此需要依次根据父部门ID循环获取子部门ID,然后遍历循环部门ID,获取用户信息。
新建部门ID 数据表,赋值最上层部门ID为 1,开始循环
获取部门access_token
根据父部门 ID 循环取出所有部门ID
设置停止循环条件,得到部门ID信息表
通过接口和部门ID数据,获取部门用户详情
将部门ID信息表和部门用户详情数据表根据 dept_id 合并。
FineDataLink 中的数据处理过程,详情参见:https://demo.finedatalink.com/ 「API取数-钉钉接口-获取所有部门ID(循环替代递归)」、「API取数-钉钉接口获取所有用户信息」、「API取数-钉钉数据合并」。
2. 操作步骤编辑
2.1 循环获取所有部门ID
2.1.1 新建数据表
由于接口只能获取当前部门的下一级部门基础信息,不支持获取当前部门下所有层级子部门。因此需要依次根据父部门ID循环获取子部门ID。
使用 SQL 脚本,新建数据表 dd_dep 存放 获取部门列表 接口返回值,便于后续对父部门 ID 进行循环获取子部门 ID;
新建数据表 dd_depid 存放 depid 字段,便于后续作为参数写入接口,以及判断是否停止循环。
同时在dd_depid 表中插入一行 为1的数据,便于开始取数(钉钉接口 最上层部门ID默认为1)。
CREATE TABLE
IF NOT EXISTS `demotest`.`dd_dep` (
`auto_add_user` varchar(255) NULL DEFAULT NULL,
`create_dept_group` varchar(255) NULL DEFAULT NULL,
`dept_id` varchar(255) NOT NULL,
`name` varchar(255) NULL DEFAULT NULL,
`parent_id` varchar(255) NULL DEFAULT NULL,
`taskId` varchar(255) NULL DEFAULT NULL,
PRIMARY KEY (`dept_id`)
) ENGINE = InnoDB CHARACTER
SET
= utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
CREATE TABLE
IF NOT EXISTS `demotest`.`dd_depid` (`dept_id` varchar(255) NULL DEFAULT NULL) ENGINE = InnoDB CHARACTER
SET
= utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
DELETE FROM dd_dep;
DELETE FROM dd_depid;
INSERT INTO dd_depid (dept_id) VALUES ('1');

2.1.2 获取 accesstoken
使用 获取企业内部应用的access_token 接口获取 access_token。
使用参数赋值,输入 API 信息,获取token,如下图所示:

并将取出的数据设置为参数。如下图所示:

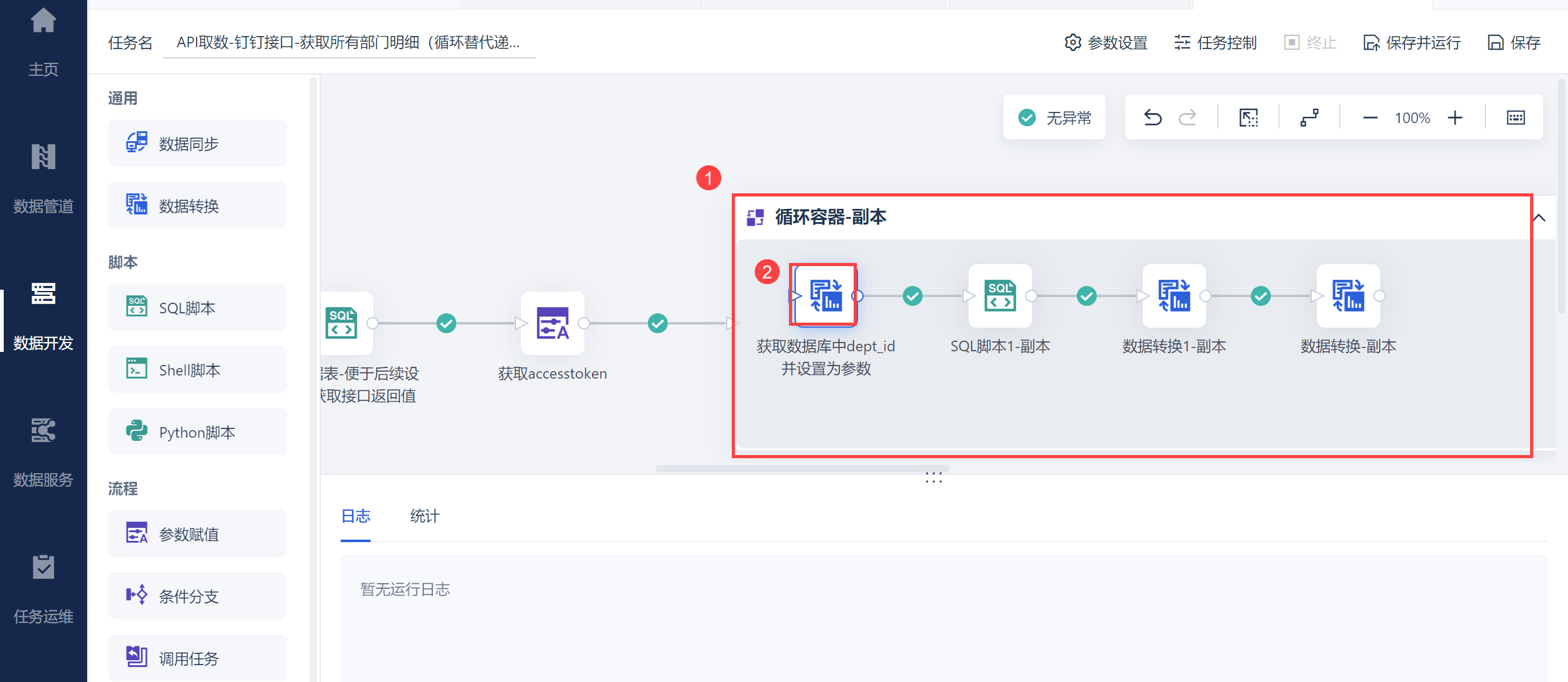
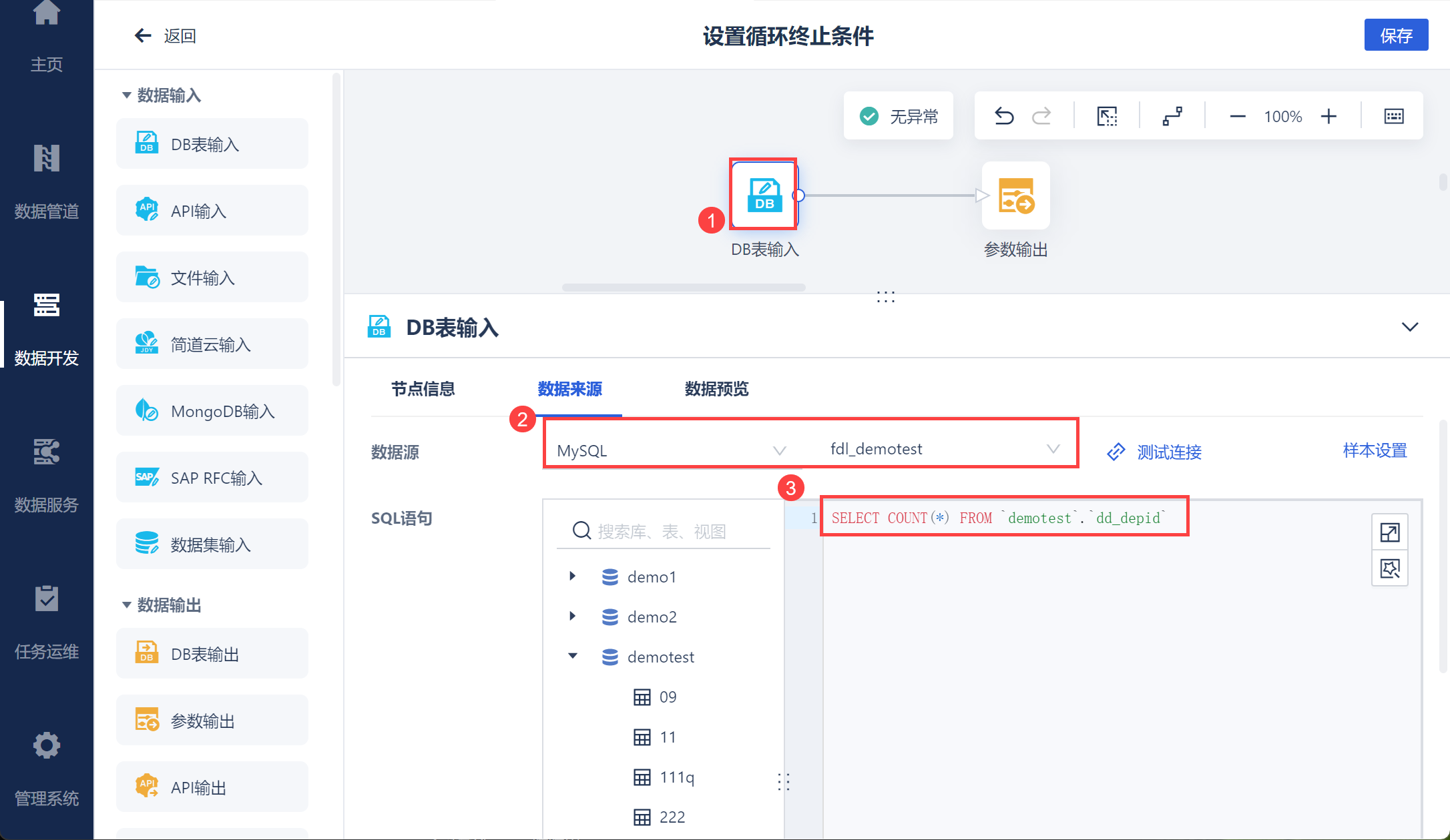
2.1.3 根据父ID循环取出所有部门ID
由于需要循环,因此使用循环容器,然后拖入数据转换,如下图所示:
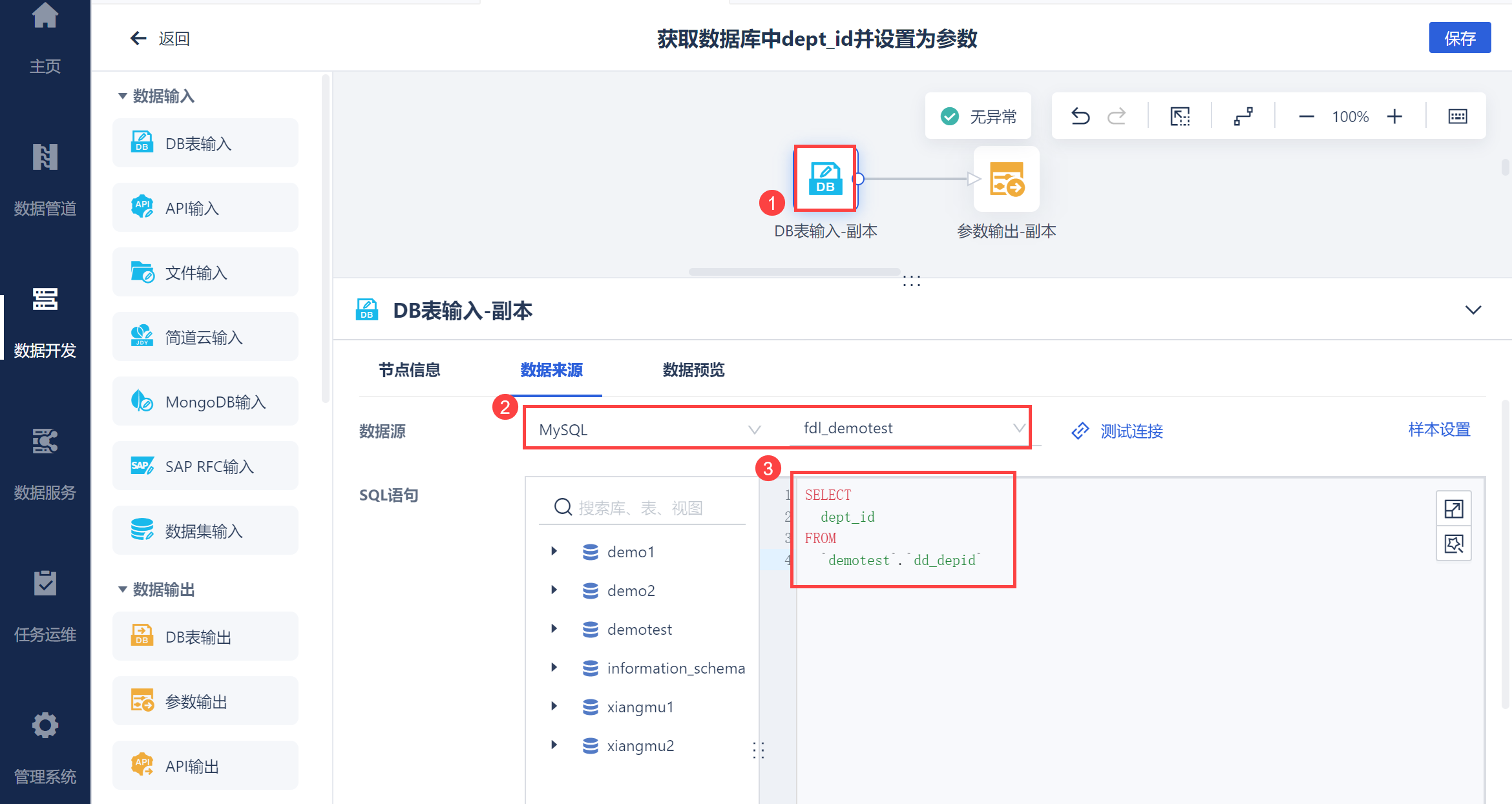
进入数据转换编辑界面,从 2.1.1 节落库的 dd_depid 数据表中读取部门ID,如下图所示:
使用参数输出将 dept_id 字段设置为参数 depIds,便于后续作为输入接口的参数,如下图所示:

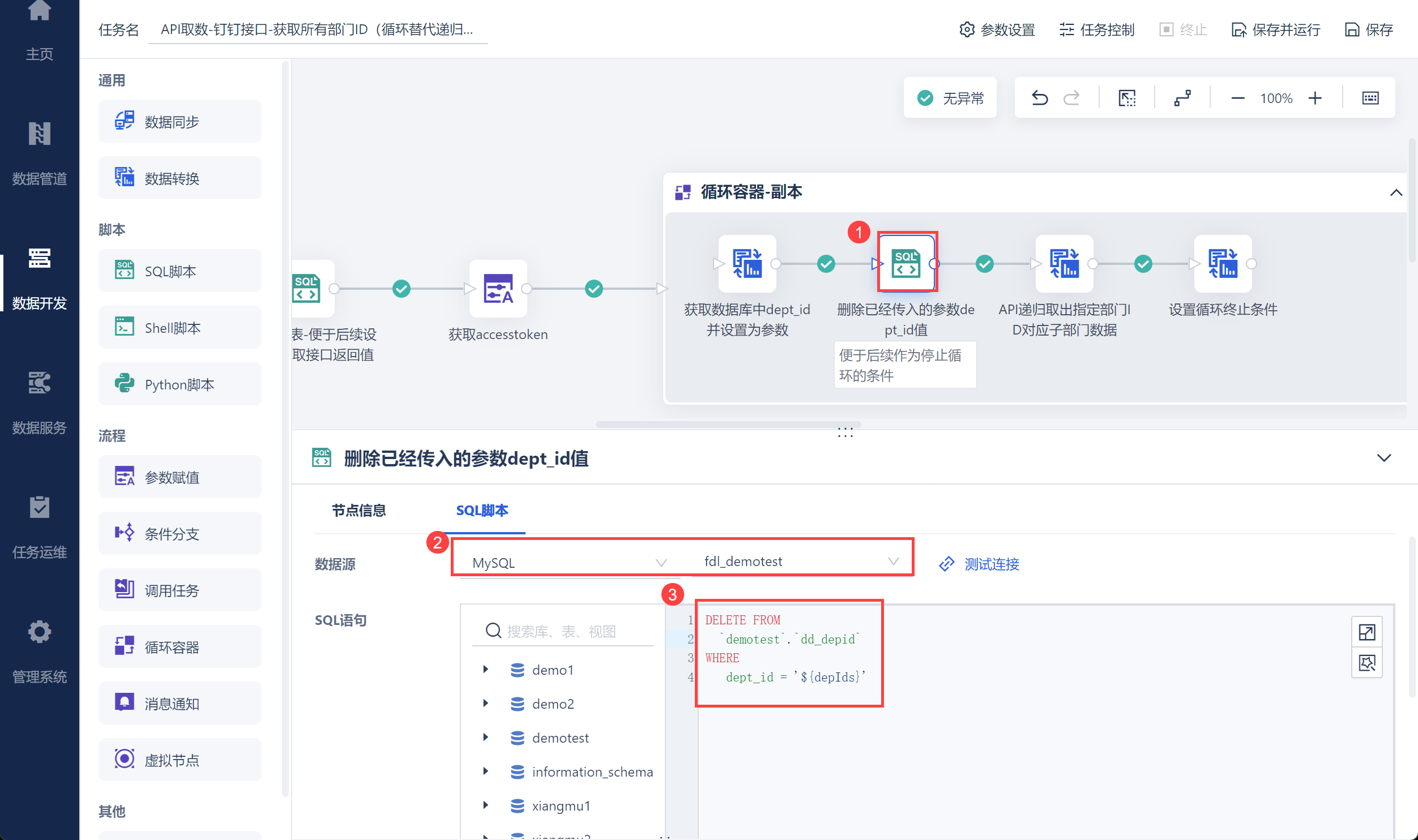
由于后续设置让循环停止的条件为 dd_depid 数据表中 dept_id 字段无数据,因此需要在传入dept_id 参数后,删除 dd_depid 数据表中当前循环传入的参数,所以需要使用 SQL 脚本,如下图所示:
注:此时参数 depIds 已经输出,删除该数据不影响参数后续的使用。
DELETE FROM
`demotest`.`dd_depid`
WHERE
dept_id = '${depIds}'
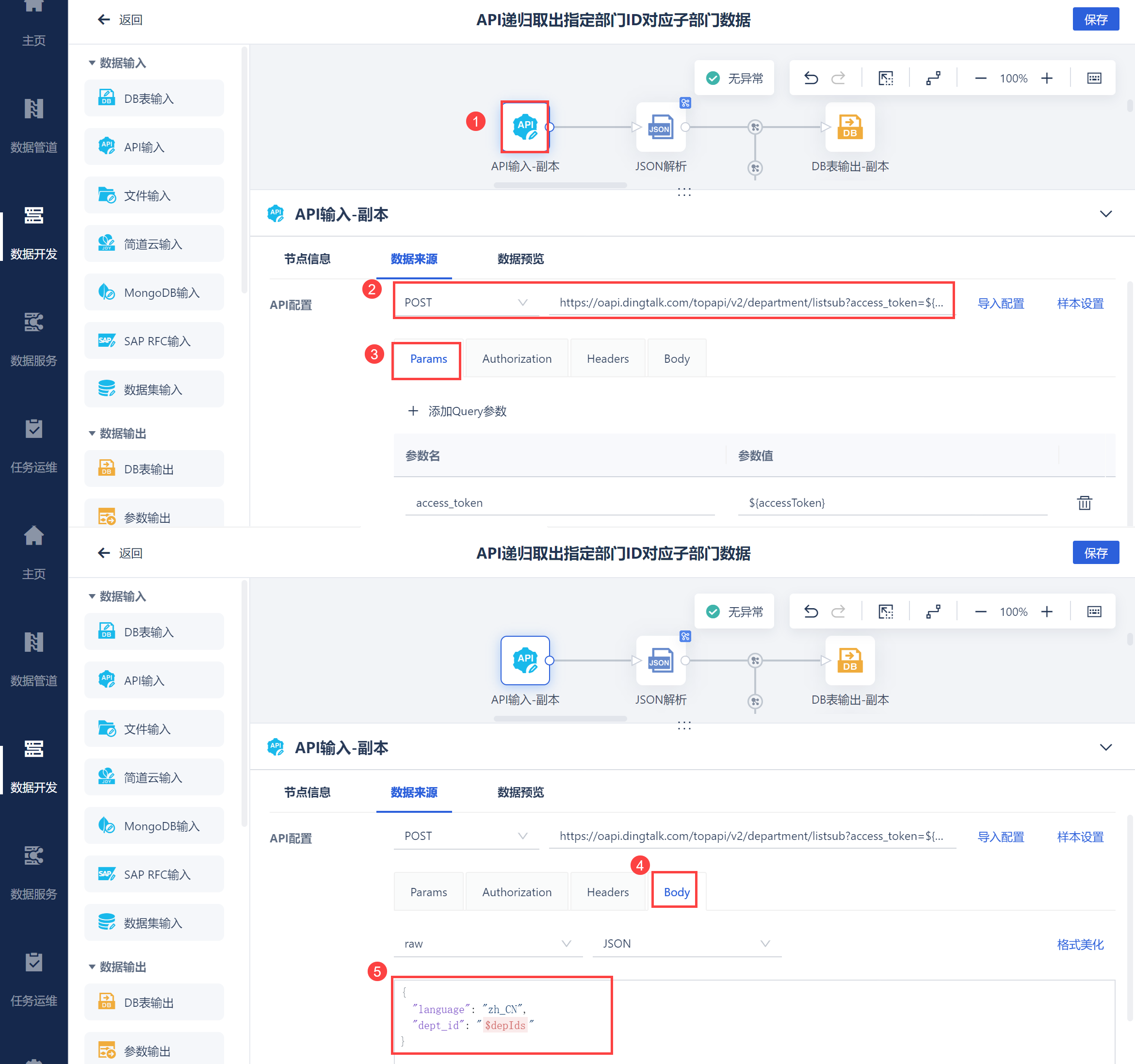
新建数据转换,进入编辑界面,使用 API 输入算子,使用 获取部门列表 接口将dd_depid 数据表中 depIds 参数传入,取出指定部门ID对应子部门ID等数据,如下图所示:
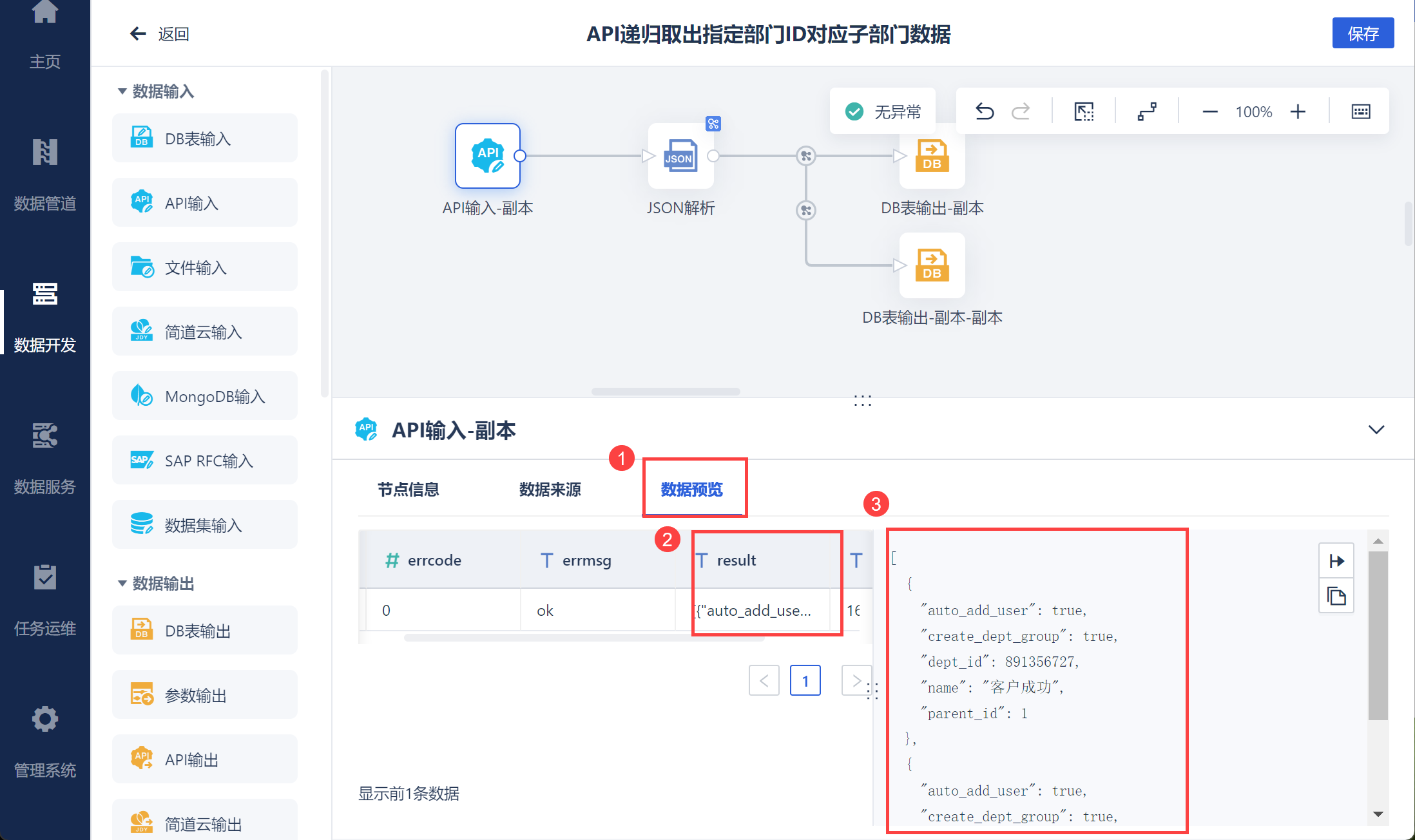
数据预览即可看到取出的数据,如下图所示:
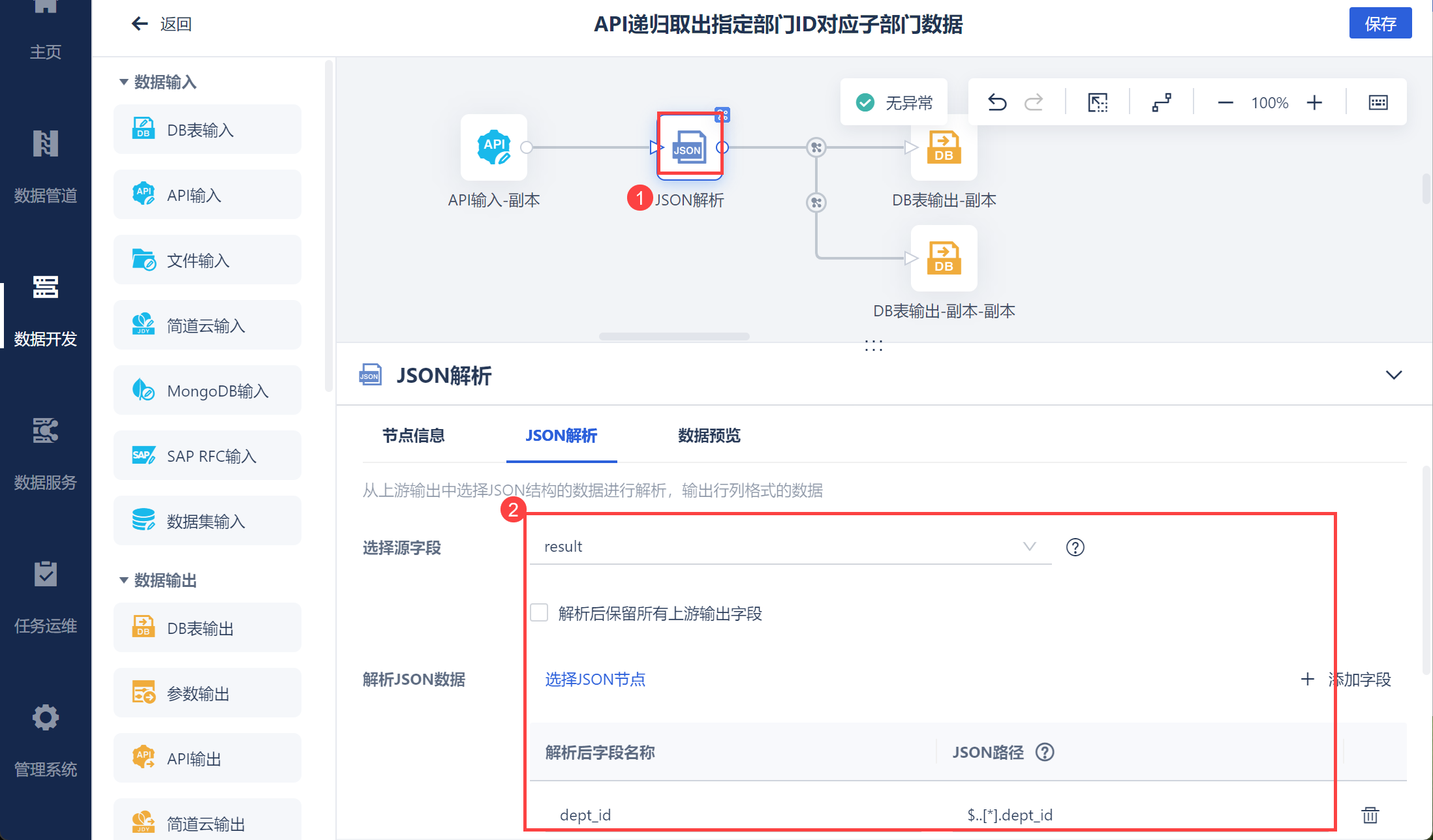
将取出的 JSON 数据解析,如下图所示:
将取出的父部门ID 对应的子部门ID 数据信息落库至 2.1.1 节创建的 dd_dep 数据表,也就是我们最终取出的全量部门ID 数据,如下图所示:

为了保证落库的最终数据表dept_id 字段数据唯一,因此设置为逻辑主键,并设置冲突策略,如下图所示:

由于循环容器中 SQL 脚本需要删除传入的dept_id 字段,以便后续进行循环终止判断,因此需要将dept_id 写入之前构造的 dd_depid数据表中,只保留 dept_id 字段,如下图所示:

2.1.4 设置停止循环条件
新增数据转换节点,对 dd_depid 字段进行计数,如下图所示:
并将计数结果作为参数输出,如下图所示:

设置循环容器的执行条件为当参数 count 值大于 0 ,即还有dd_depid 字段可循环,当 dd_depid 数据表无数据可循环,则停止循环取数,如下图所示:

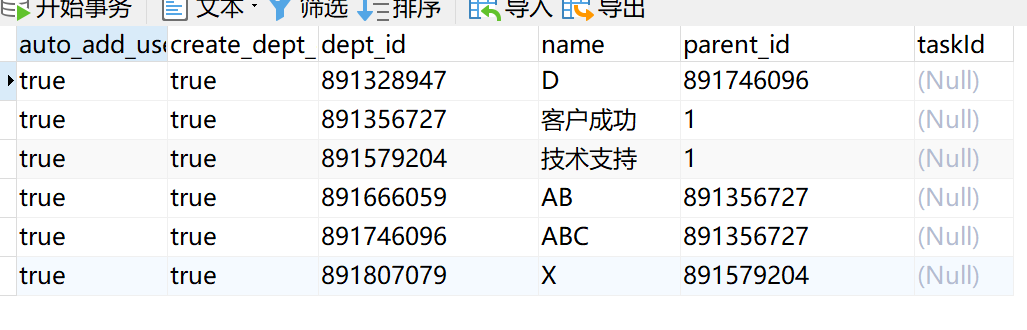
运行任务后,即可看到 dd_dep 数据表中取出所有的部门ID 信息,如下图所示:
2.2 获取所有用户信息详情
新建一个定时任务,使用参数赋值 获取企业内部应用的access_token,如下图所示:
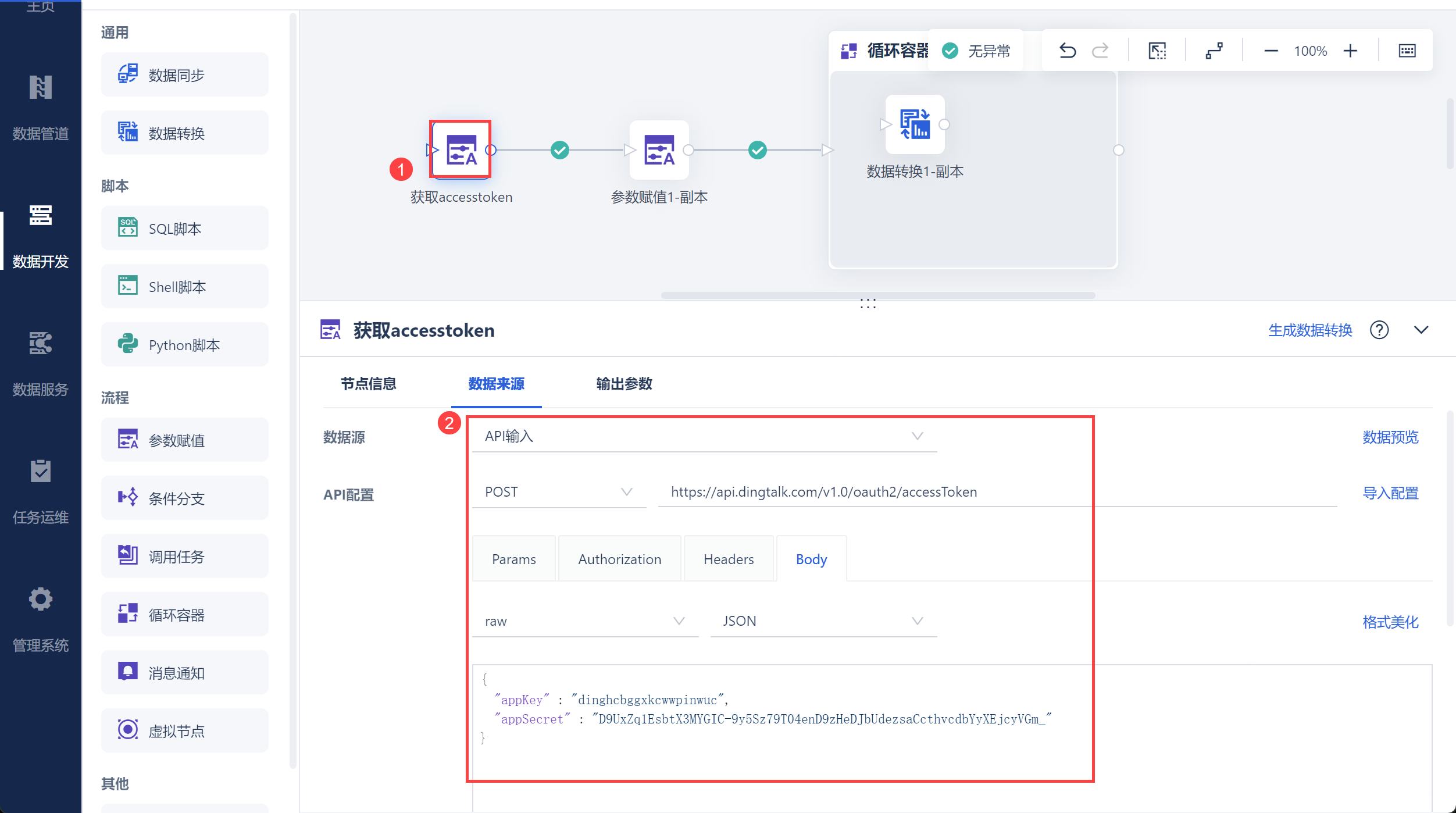
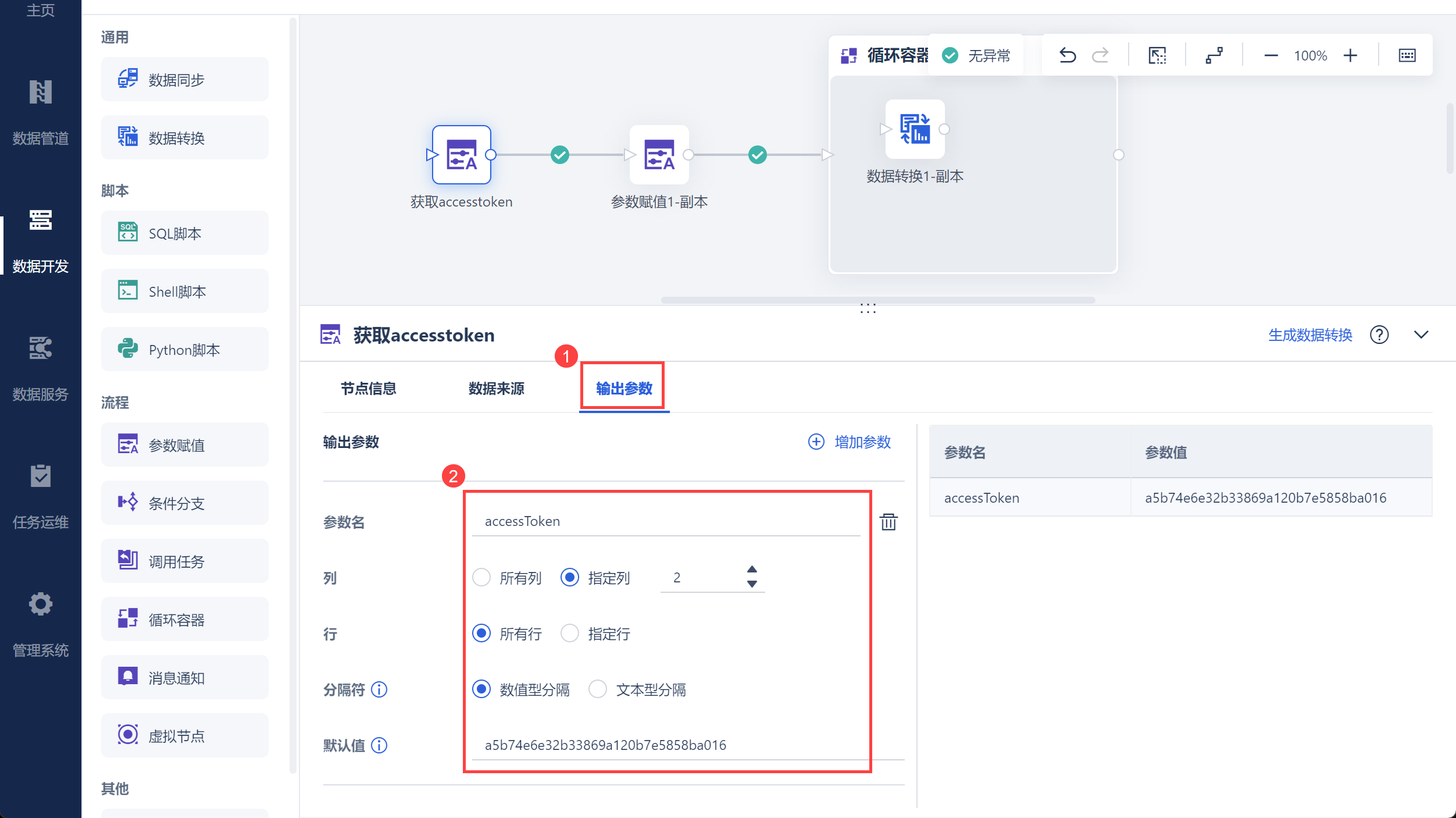
并将其设置为参数 accesstoken,如下图所示:
再次使用参数赋值,从 2.1节中的 dd_dep 数据表取出所有的 dept_id,如下图所示:
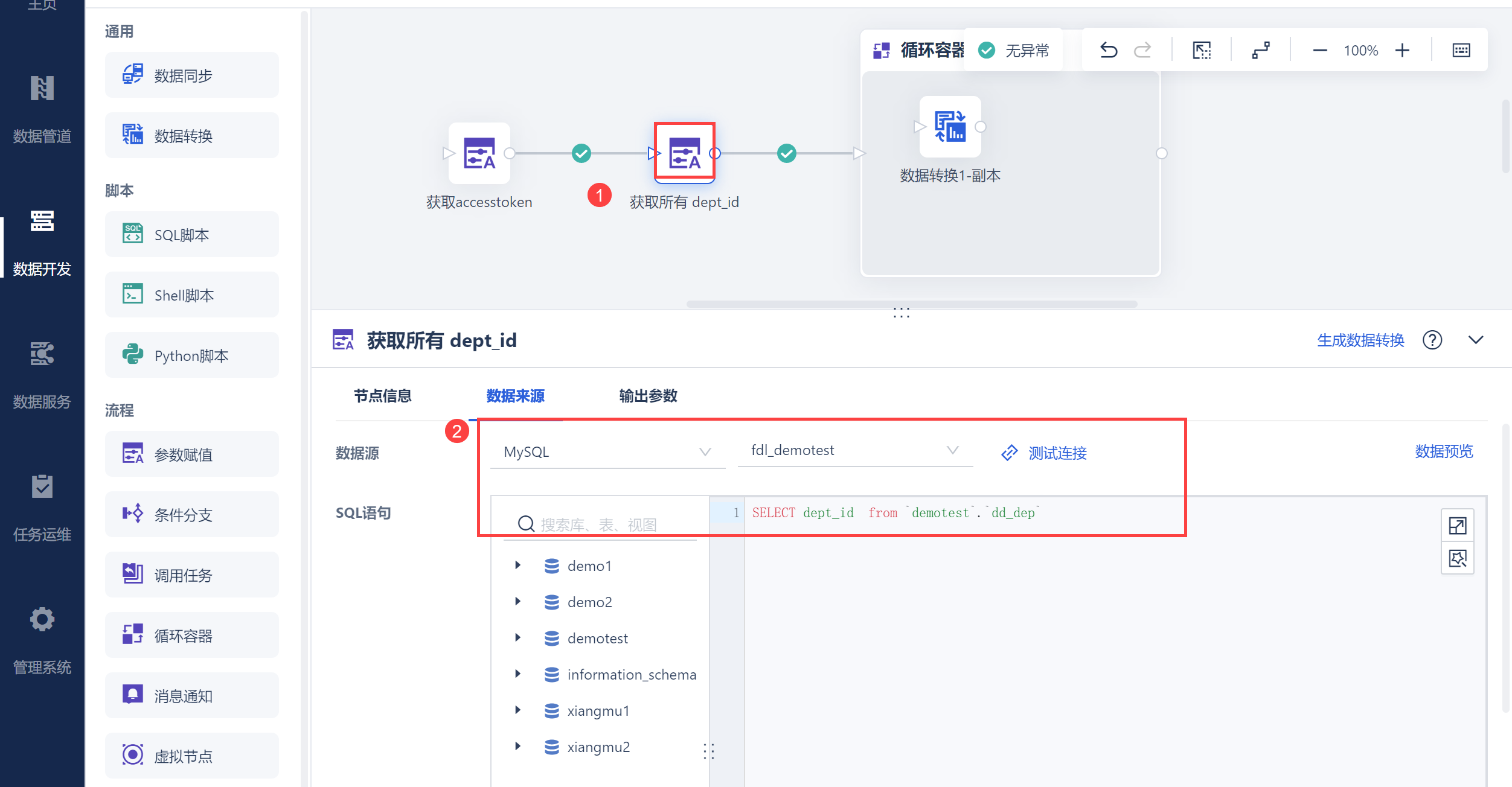
将其设置为参数,便于传入 API 接口中,如下图所示:

使用循环容器遍历dept_id,取出所有的用户信息。在循环容器中使用数据转换,如下图所示:
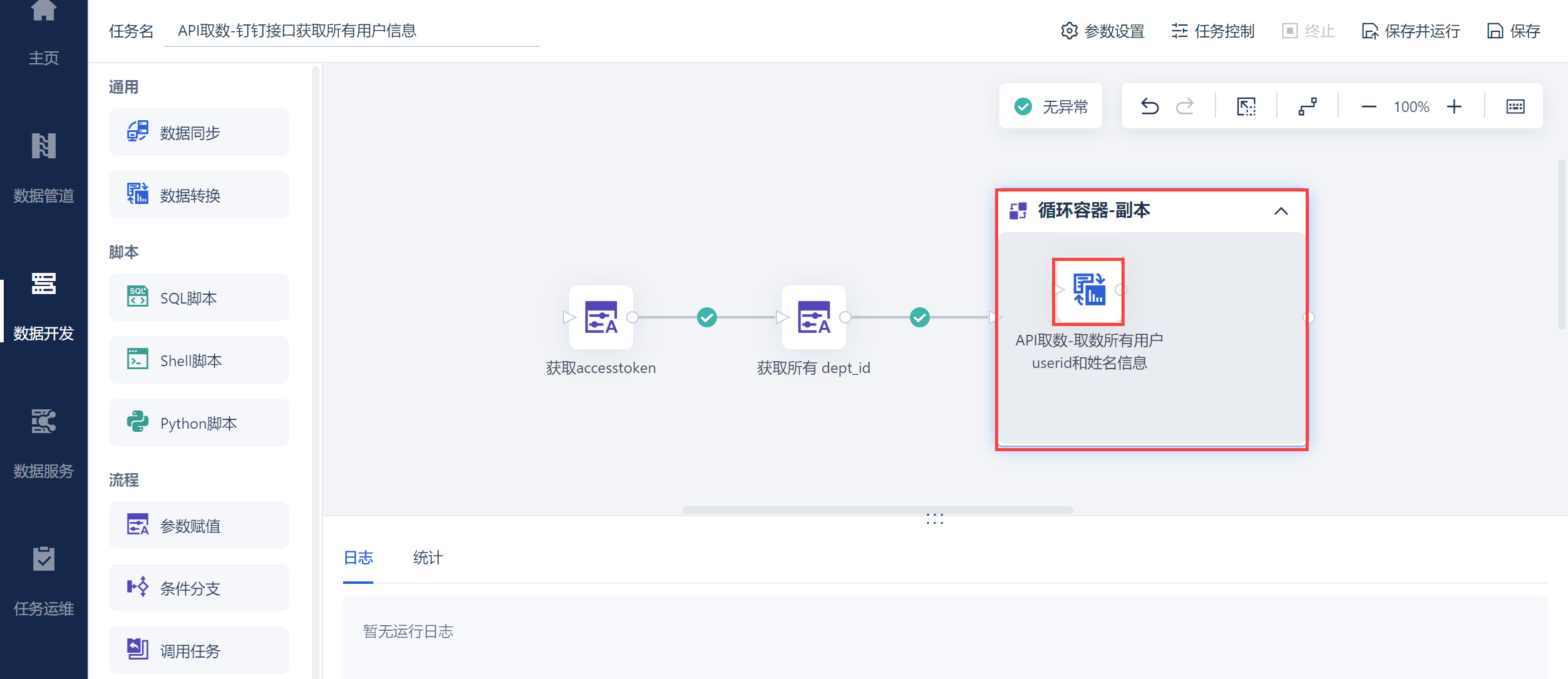
进入数据转换编辑界面,使用API 输入,使用 获取部门用户详情 接口将 dept_id 参数传入,获取每个 dept_id 对应的用户详情信息,如下图所示:

使用 JSON 解析将取出的数据解析为二维表,如下图所示:
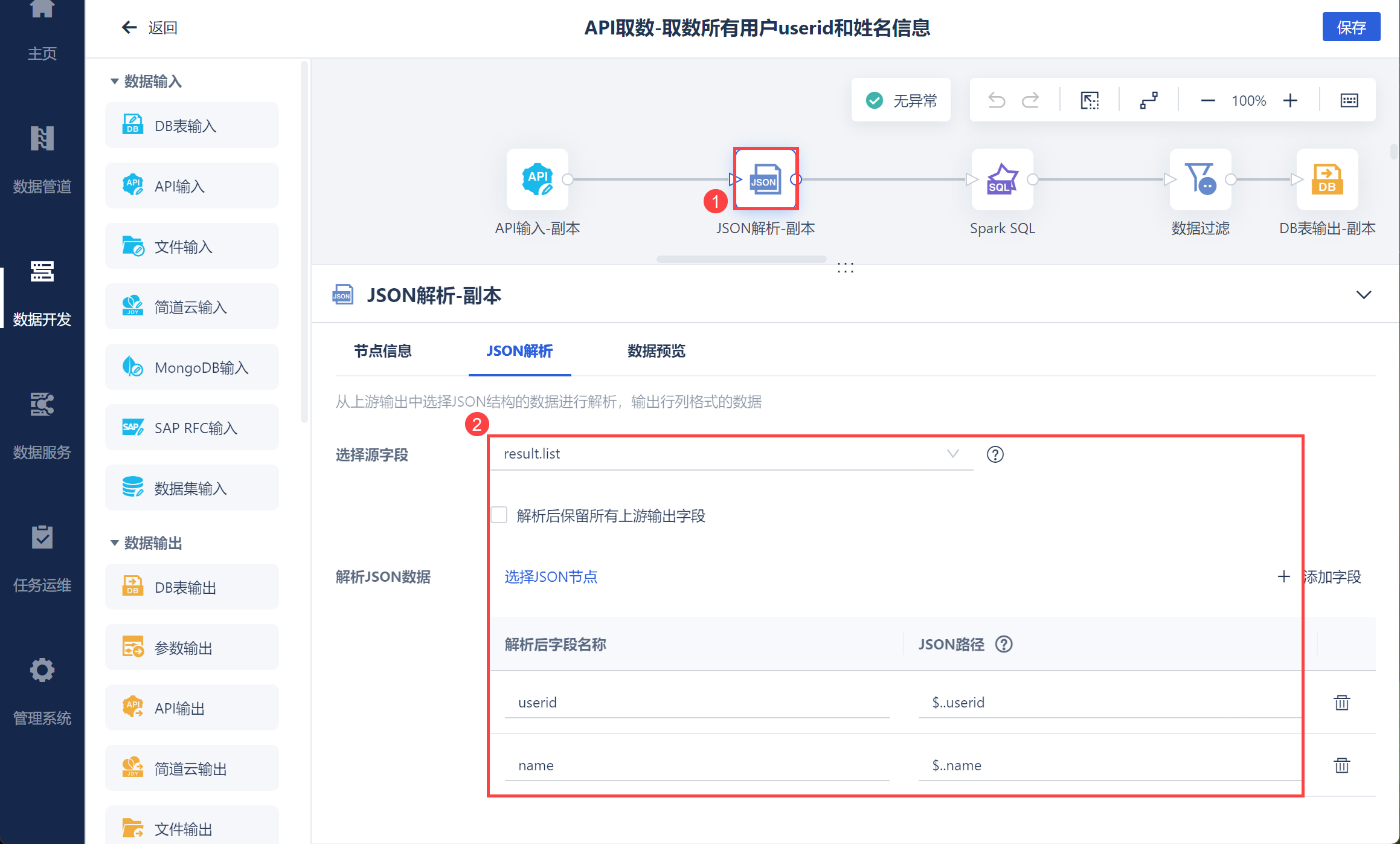
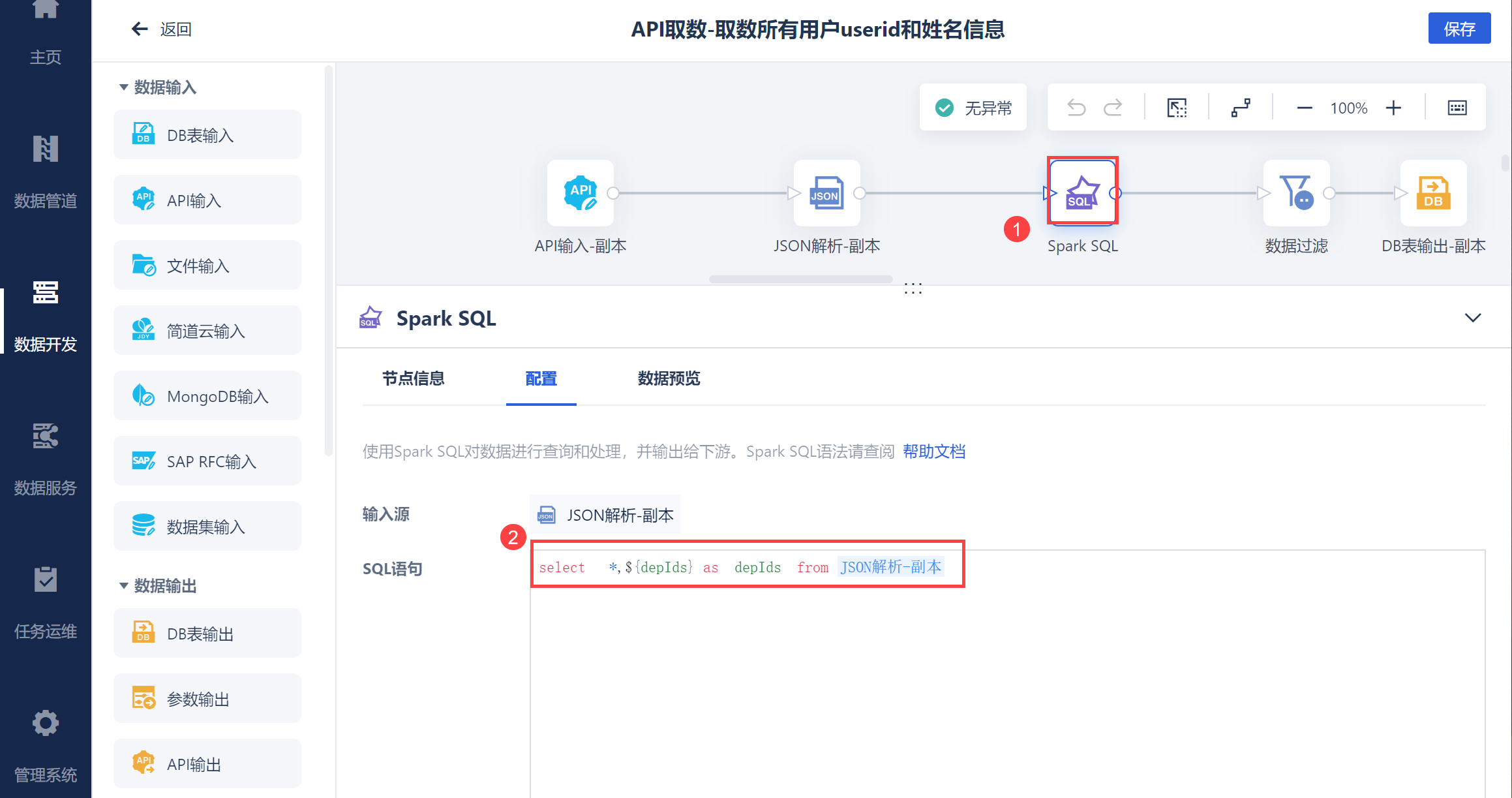
由于需要数据表同时包含用户信息和部门ID ,因此新增一列部门ID,用于后续作为左右合并的依据,如下图所示:
select *,${depIds} as depIds from $[JSON解析-副本]
预览即可看到数据戴上了dept_id数据,如下图所示:
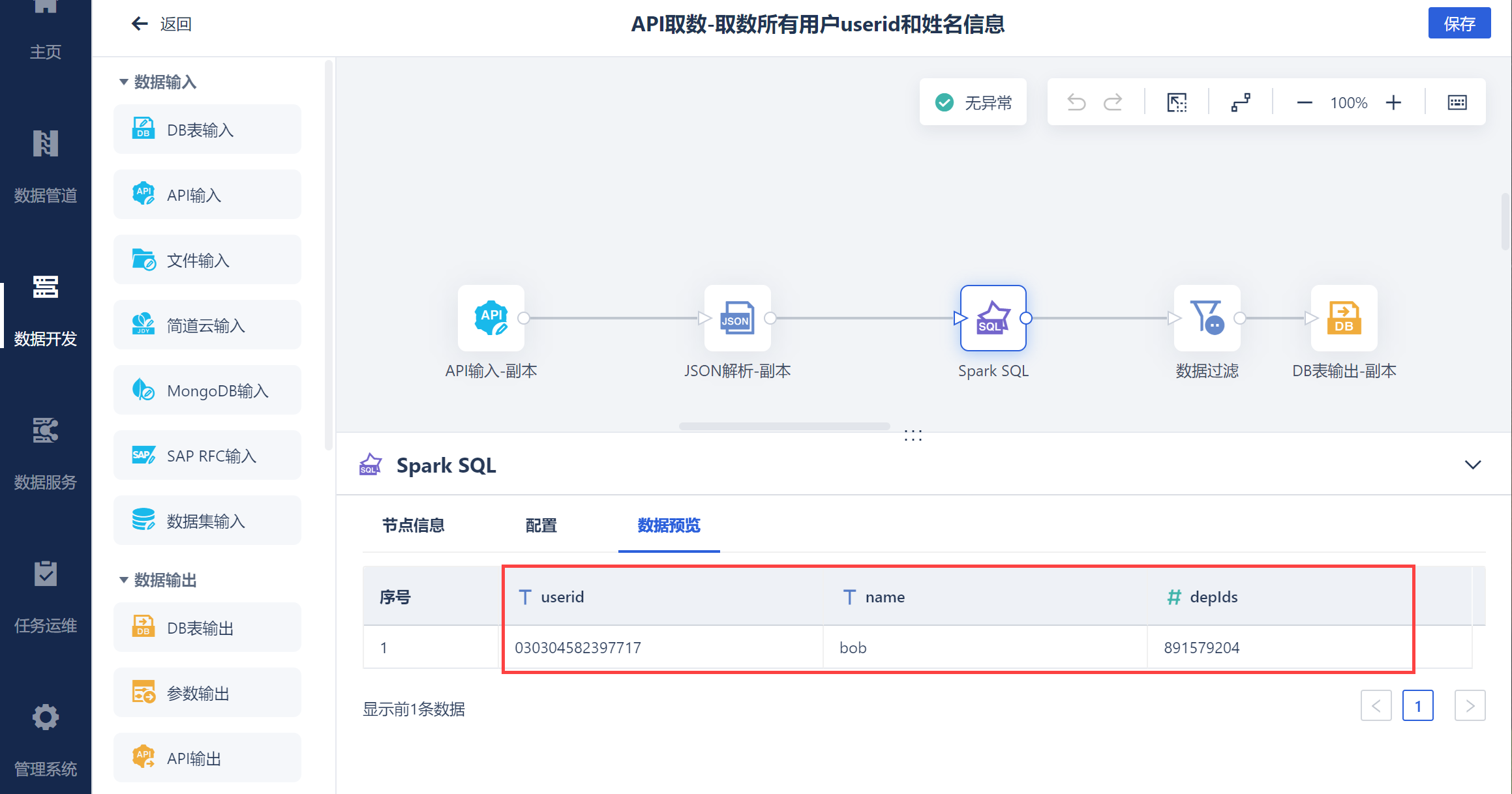
如果一些部门下没有用户,可以使用数据过滤,将userid为空的数据过滤掉,如下图所示:
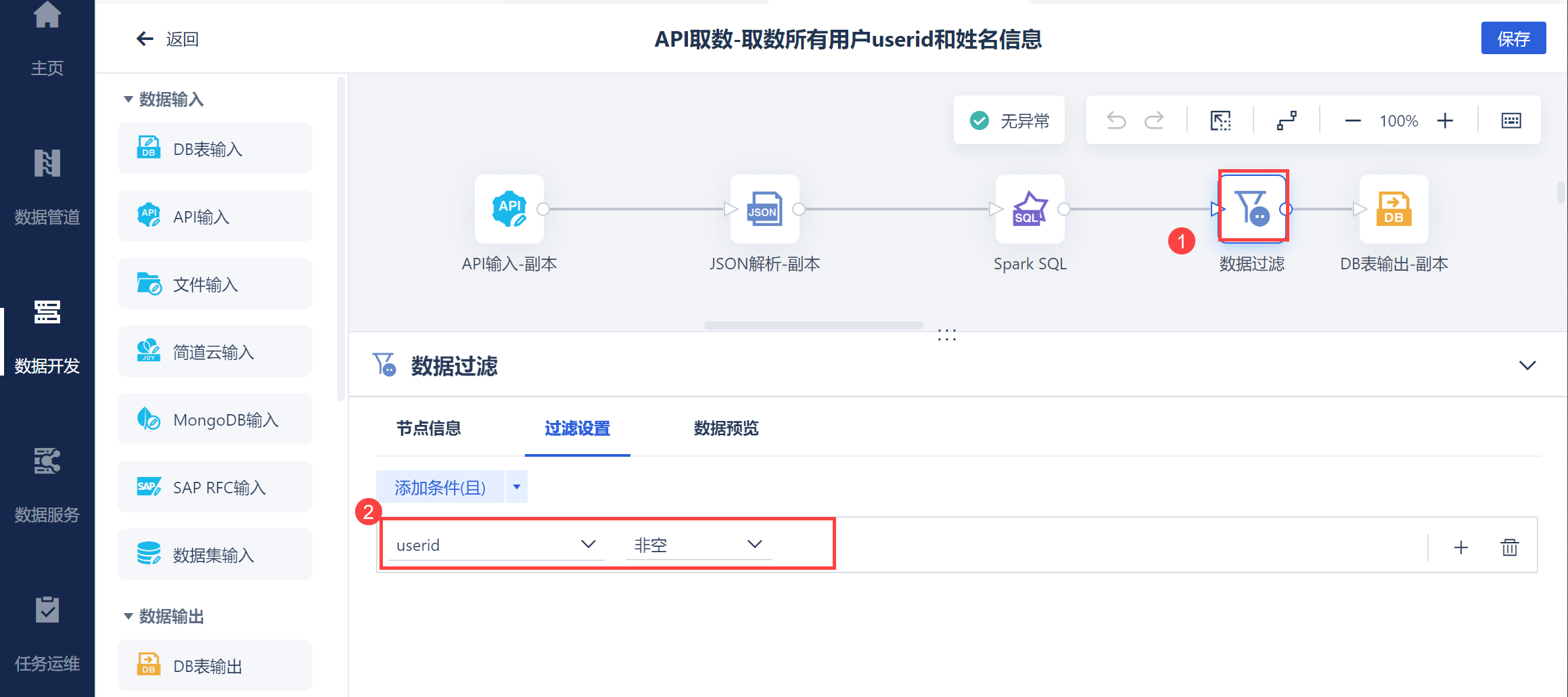
将获取的数据输出至指定数据库中,如下图所示:
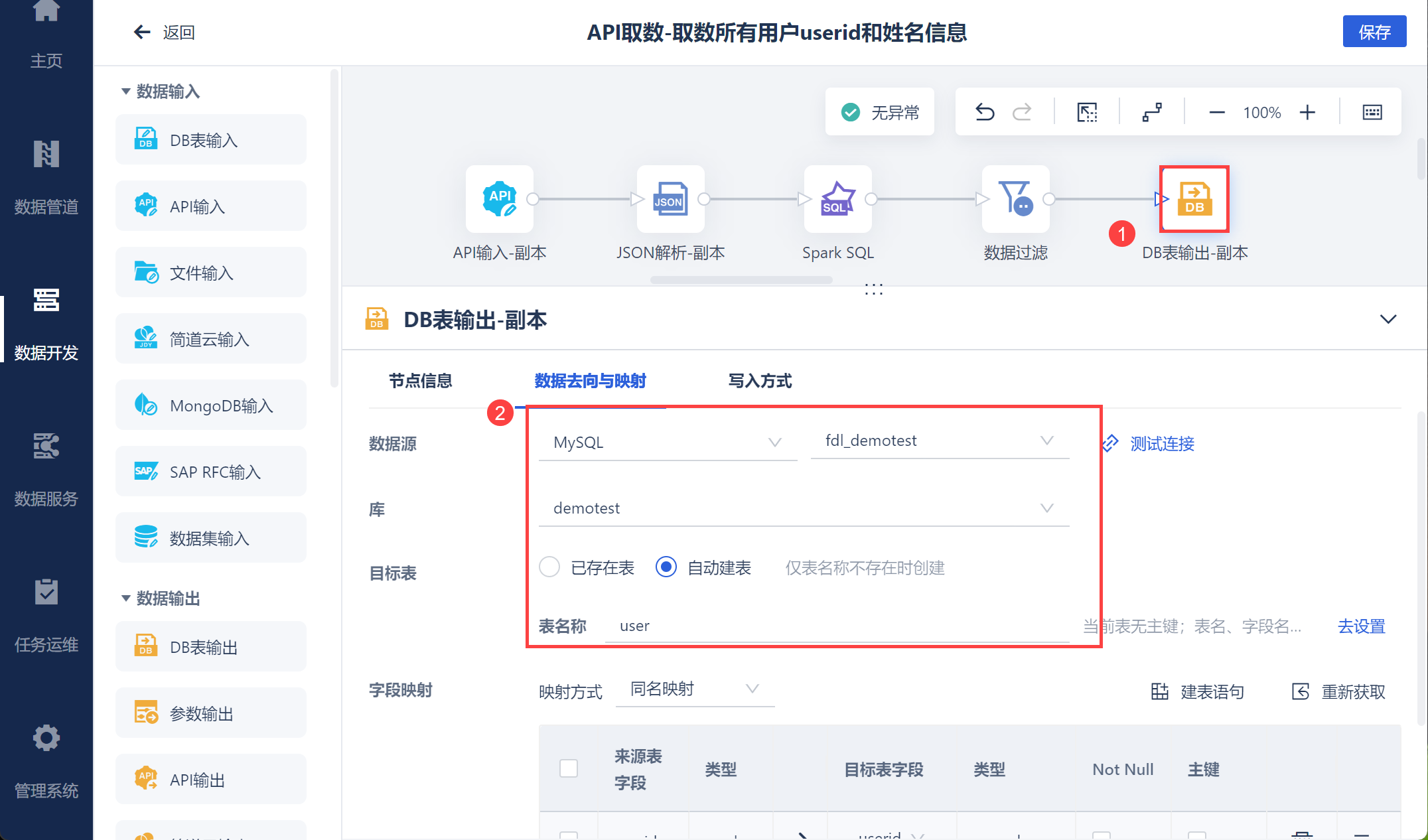
保存数据转换配置后,选择循环容器,设置遍历 deplds 参数,也就是遍历 dept_id,以此获取所有部门的用户信息,如下图所示:
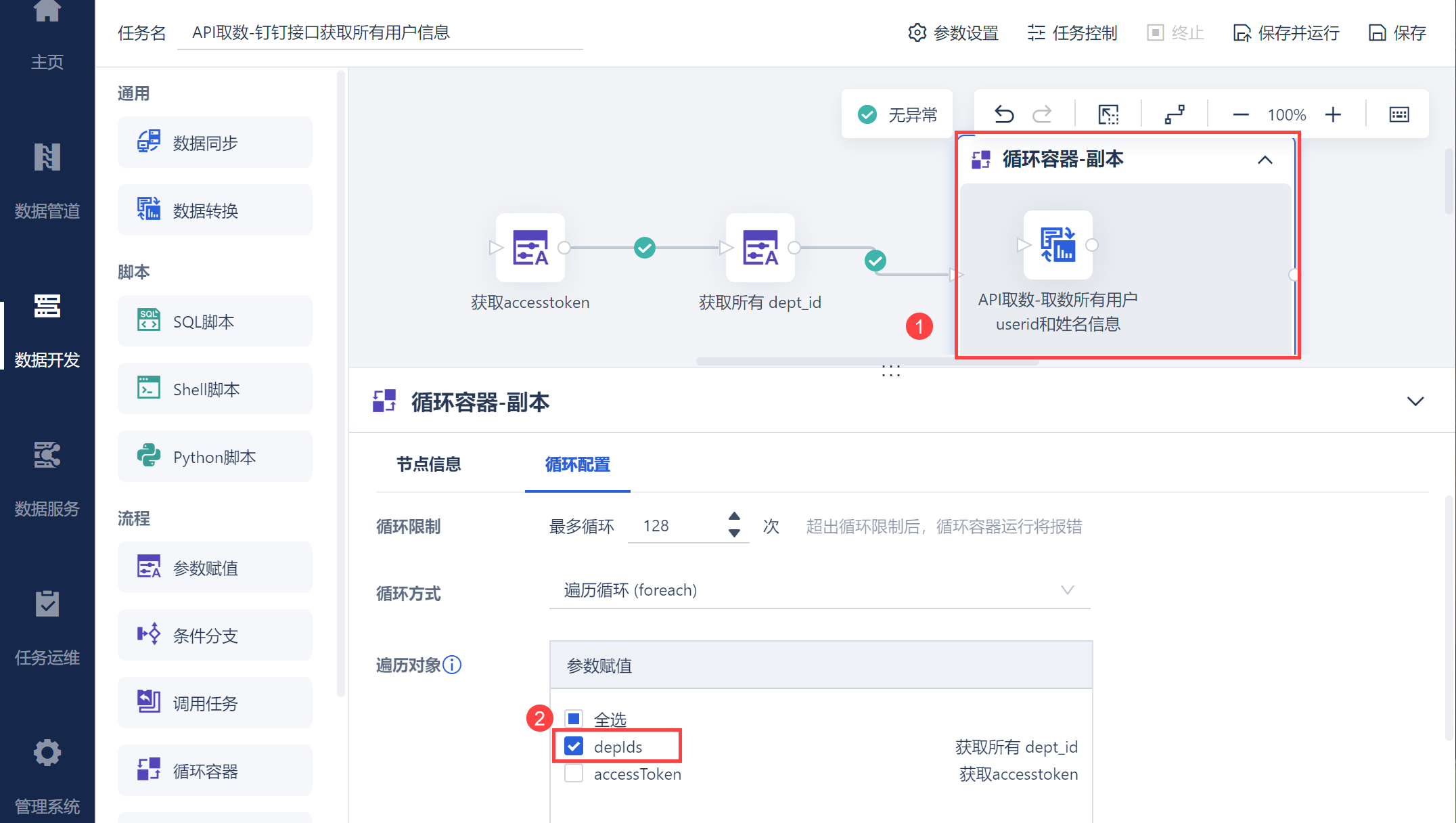
运行任务后,即可在数据库中看到取出的所有部门用户信息数据表user,如下图所示:
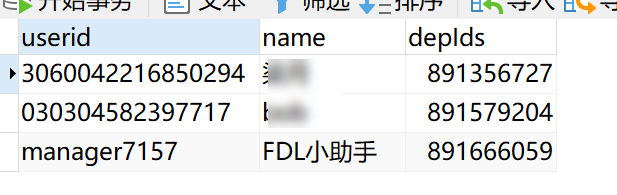
2.3 部门信息与用户信息关联
新增定时任务,进入数据转换编辑界面,使用DB表输入读取要合并的 2.1 节获取的部门列表数据 dd_dep 和2.2 节获取的用户列表数据 user,如下图所示:
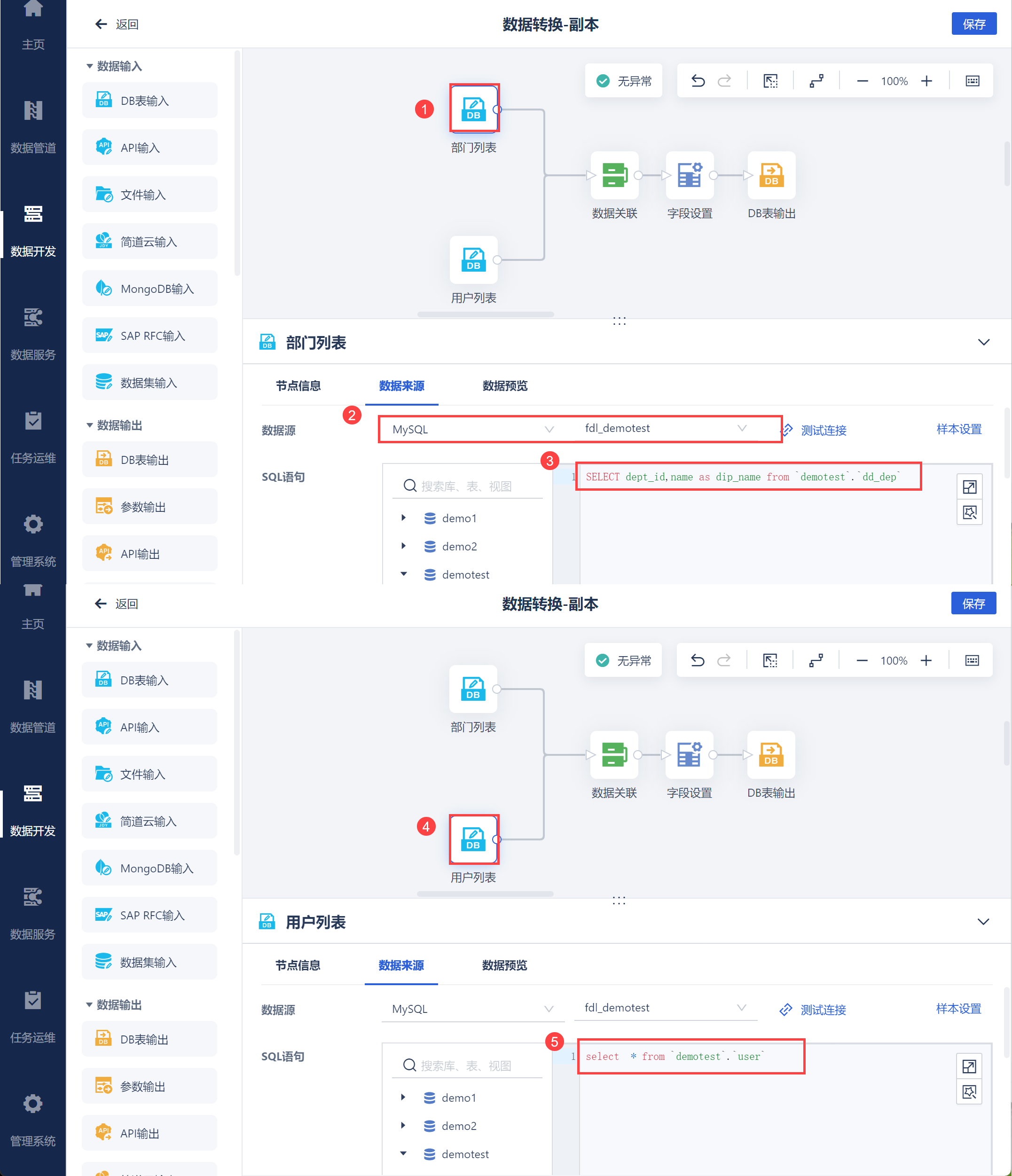
通过 dept_id 将两张数据表关联,合并成一张表,如下图所示:

然后调整字段,并将合并后的数据输出即可,如下图所示:

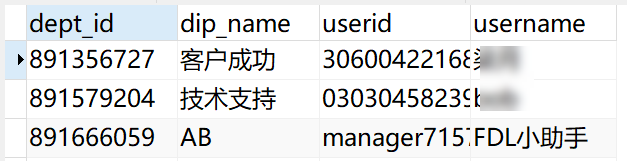
得到结果如下图所示: