目录:
1. 概述编辑
1.1 应用场景
本文介绍如何将通过 FineDataLink 数据服务 发布的API 接口数据取出。
注:若用户需要使用自己系统中的 API 进行取数,可参见:API取数概述
1.2 接口说明
已经发布的 API 接口说明如下:
请求说明:
| 请求域名 | 发布API中使用的 FineDataLink 服务器地址 例如:http://192.168.5.175:8089/webroot |
|---|---|
| 请求地址 | 发布API中设置的API路径 例如:http://192.168.5.175:8089/webroot/service/publish/demo 注:可直接在发布界面复制完整的API请求地址。
|
| 请求方式 | POST 注:当前版本仅支持 POST 请求方式。 |
| ContentType | application/json |
请求body参数:
| 名称 | 类型 | 是否必填 | 描述 | |
|---|---|---|---|---|
| paging | pageNum | int | 是 | 分页参数 pageNum 为页数,数值可自定义。 |
| pageSize | int | 是 | pageSize 为每页数据条数,数值可自定义 | |
| params | object | 否 | 自定义参数 如果在发布API时设置了自定义参数,但是请求中未传此参数,则返回报错。 | |
请求示例:
{ "paging": { "pageNum": 1, "pageSize": 10 }, "params": [{ "name": "dtime", "value": "2010-07-13 00:00:00" }]}注:此处的 name 为 发布的API 中设置的自定义 dtime 参数。
返回值参数:
| 名称 | 类型 | 描述 |
|---|---|---|
| data | object | 返回用户使用接口取出的数据 |
| totalNum | int | 返回取出数据的总数据条数 |
| pageSize | int | 返回取出数据的每页数据条数 |
| pageNum | int | 数据页数,即从第几页开始取 |
| message | string | success,则返回成功 失败时具体原因会在Messege中体现 |
响应值示例:
{ "data": [ { "运货商": null, "货主地区": "华中", "货主邮政编码": "214000", "应付金额": null, "雇员ID": "214001", "备注": null, "到货日期": "2023-02-22", "货主名称": "林小姐", "订购日期": "2023-02-27", "货主城市": null, "货主国家": "中国", "订单ID": "214001", "货主地址": null } ], "totalNum": 1, "pageSize": 10, "message": "success", "pageNum": 1}错误返回码:
详情参见本文第三节。
1.3 实现思路
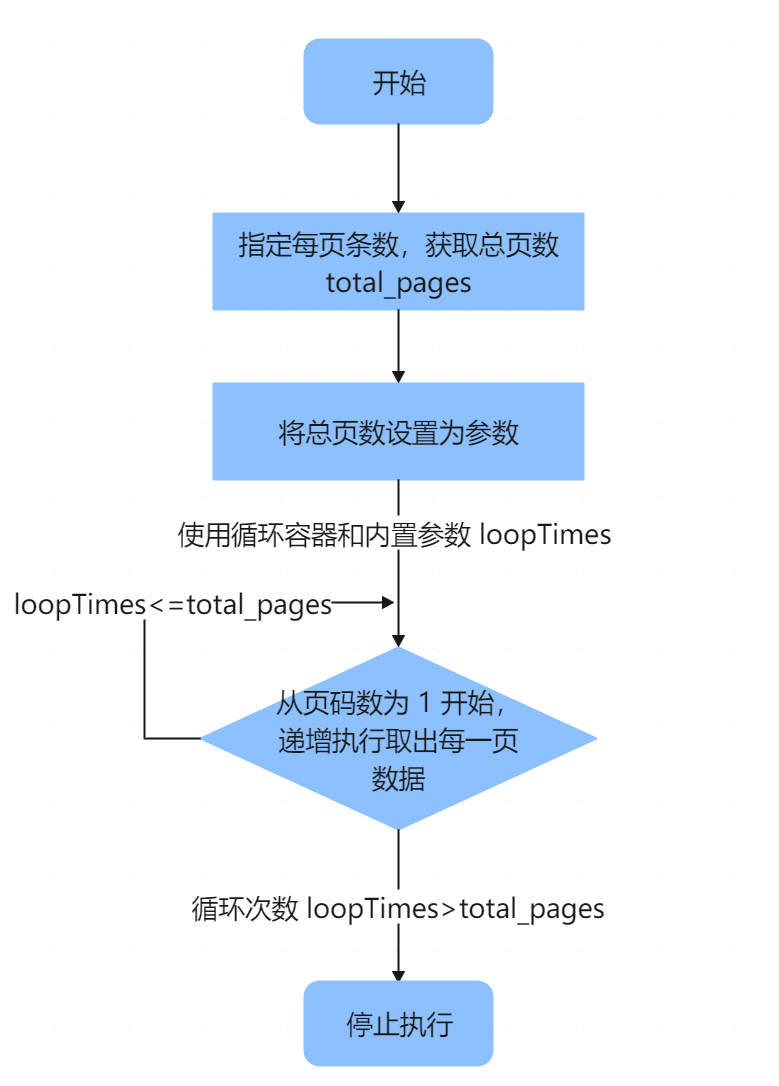
接口取数时,通常不会一次性取出全量数据,因此使用参数,分批从接口中取出全量数据。
从接口中获取 pageNum 和 pageSize 返回值,并使用 SparkSQL 计算出数据总页数 total_pages,将其作为参数,也就是需要执行的次数;
使用循环容器和内置参数 loopTimes,首次执行 pageNum 页码数为 1 ,然后递增执行取出每一页的数据,当循环次数 loopTimes<=total_pages 继续执行,当循环次数 loopTimes>total_pages 时,停止执行。
2. 操作步骤编辑
2.1 获取API信息
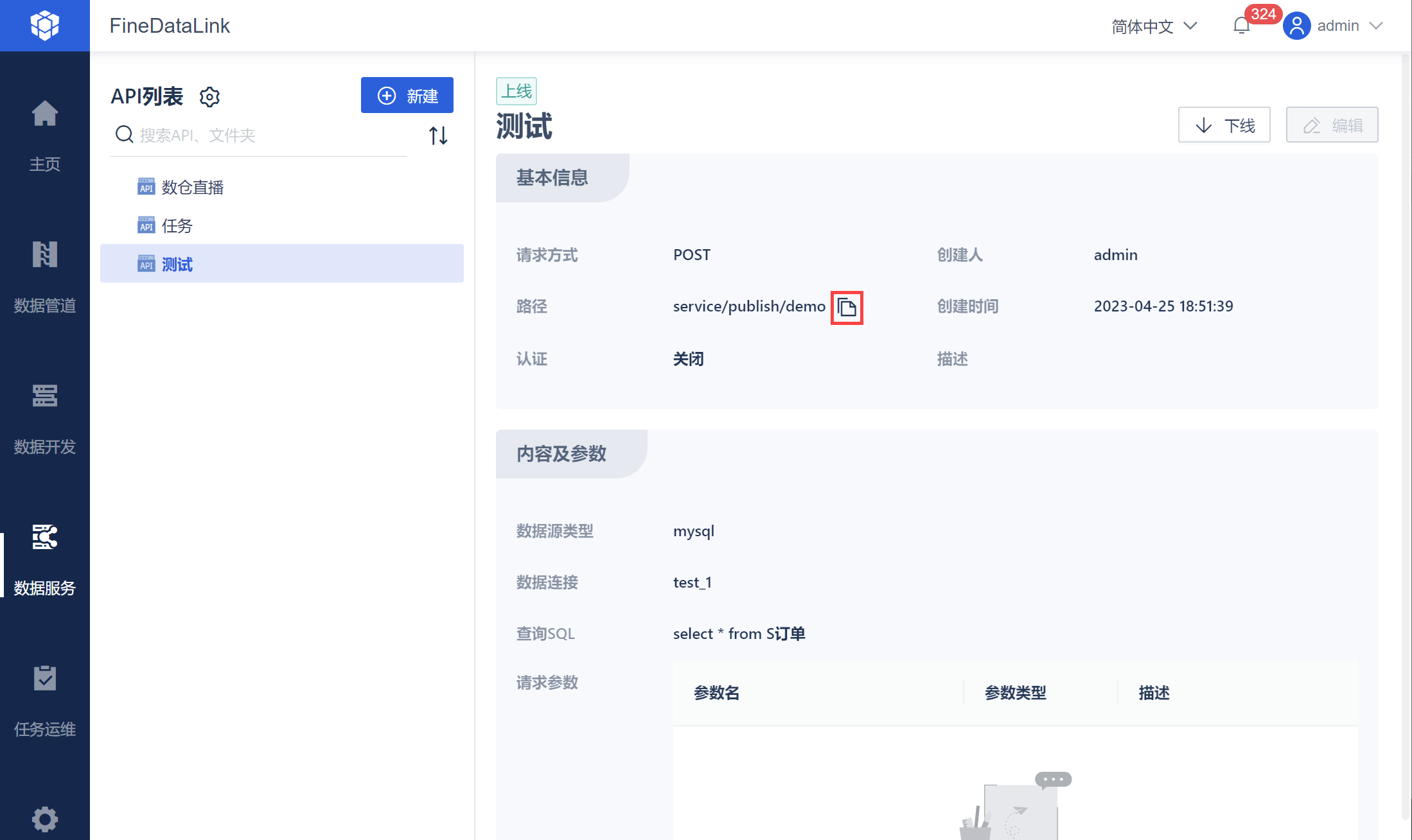
首先在 API 列表界面选择需要使用的API,然后再基本信息处复制路径。
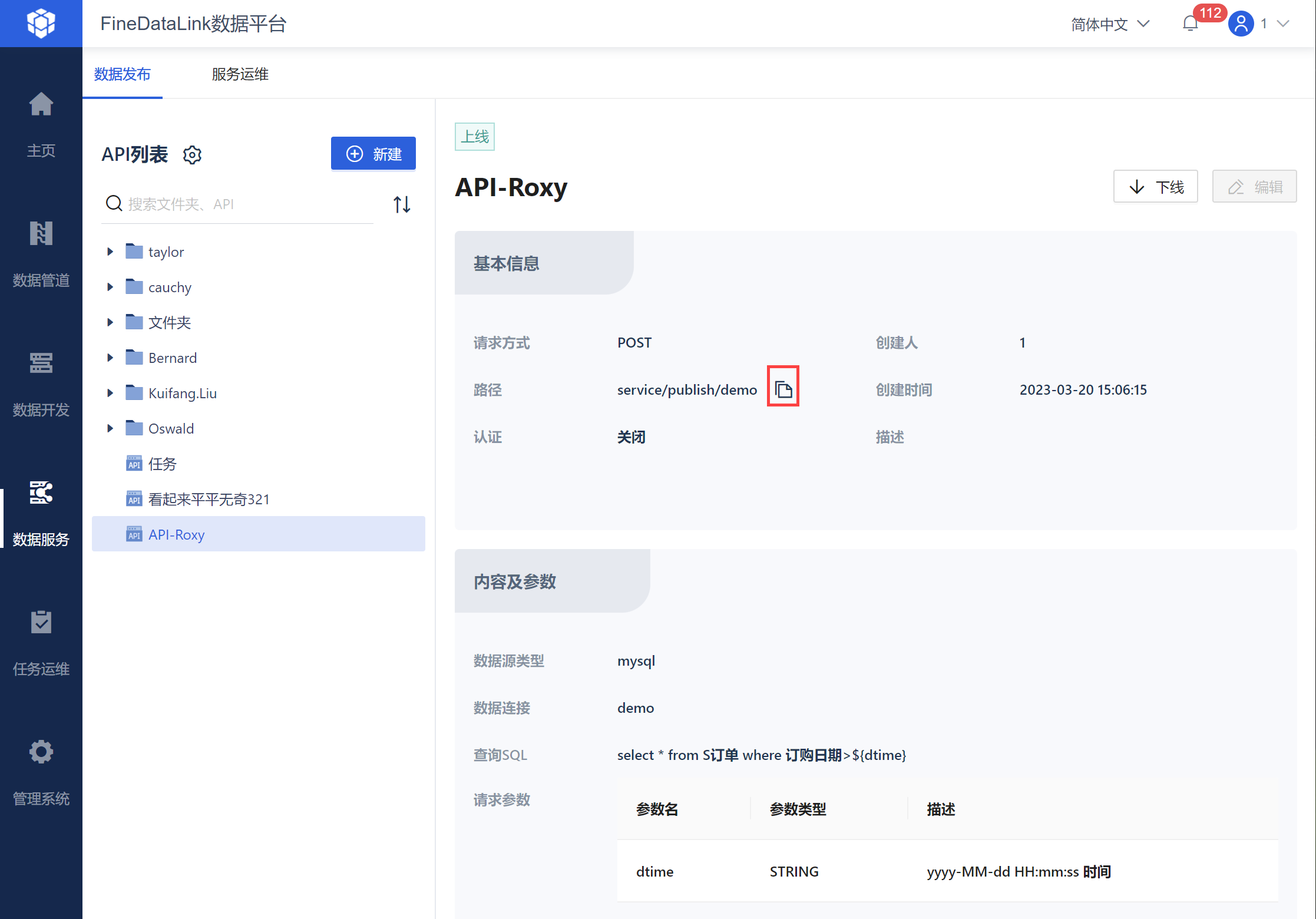
然后在「数据服务>认证配置」中复制 APPCode,如下图所示:
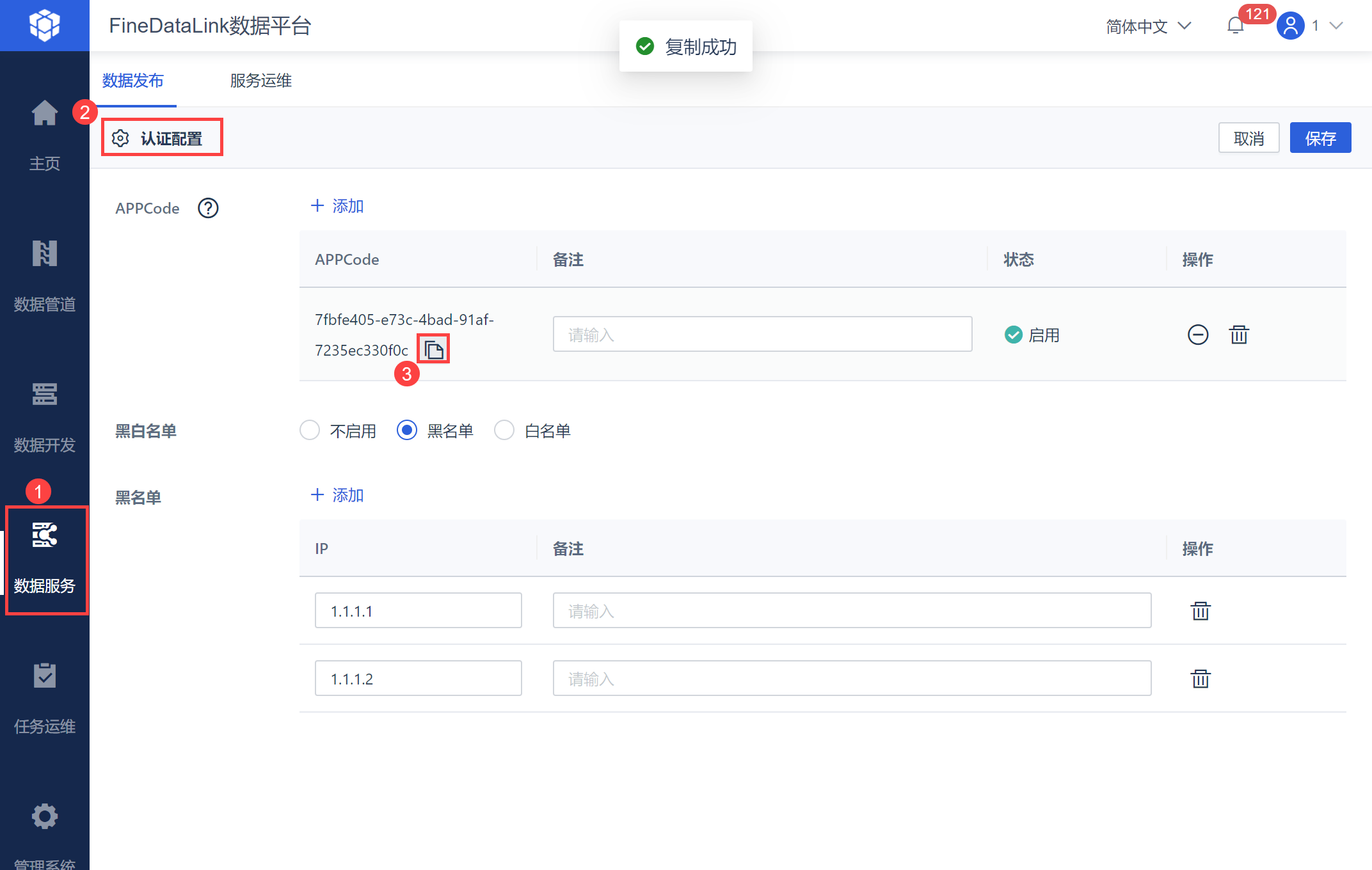
注:如果开启了黑白名单,需要保证使用 API 的环境与发布 API 环境之间信息能互通。
2.2 设置 API 基本信息
新建一个定时任务,由于需要将 API 数据解析计算后获取总页数值作为参数,因此需要使用「数据转换」节点。
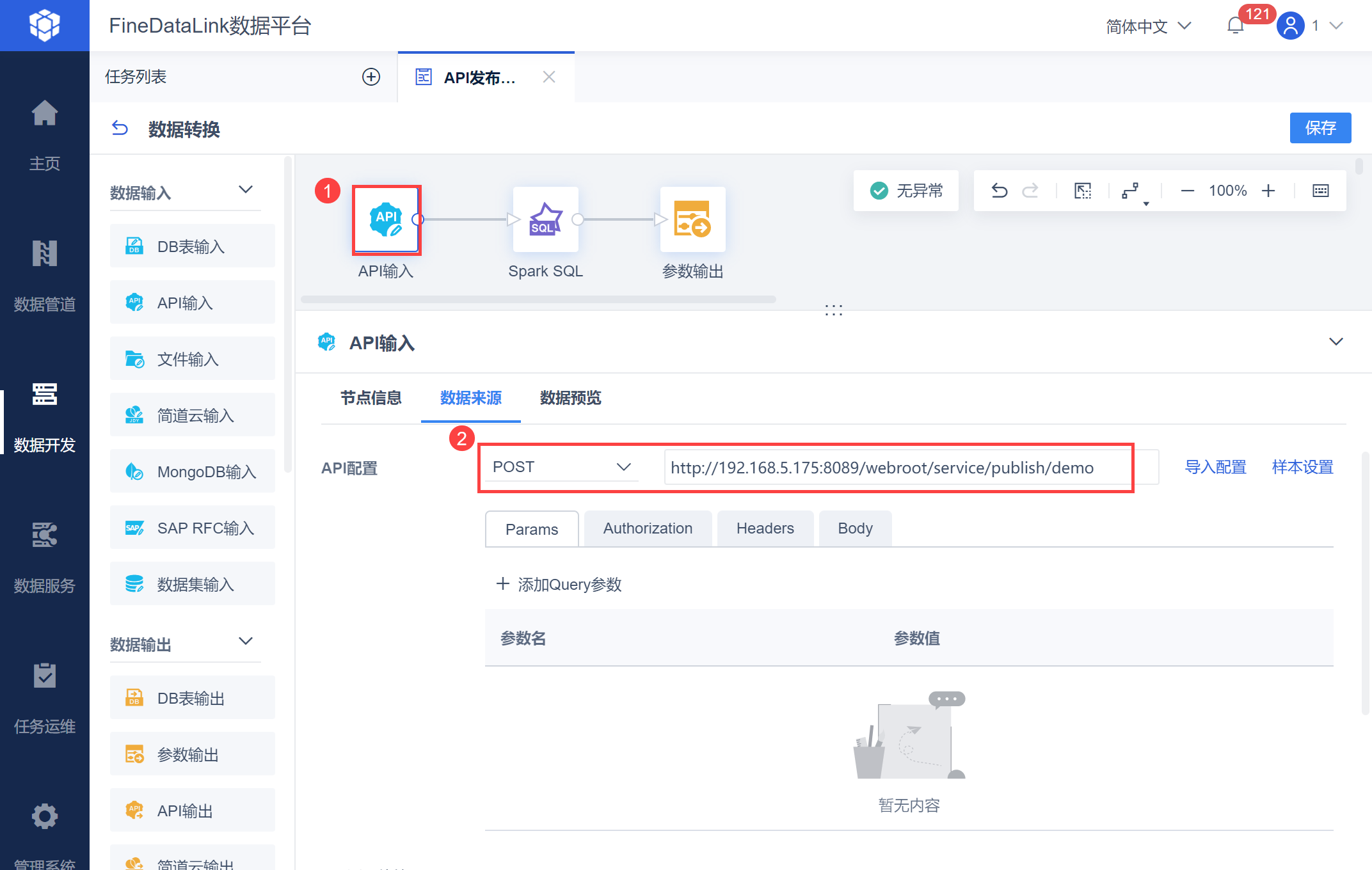
在数据转换中,选择「API输入」并选择POST请求方式,输入复制的API链接,如下图所示:
注:复制的链接默认为IP:端口/webroot 路径,如果用户的FineDataLink做过Tomcat下通过IP直接访问系统,则需要给复制的url去掉webroot。
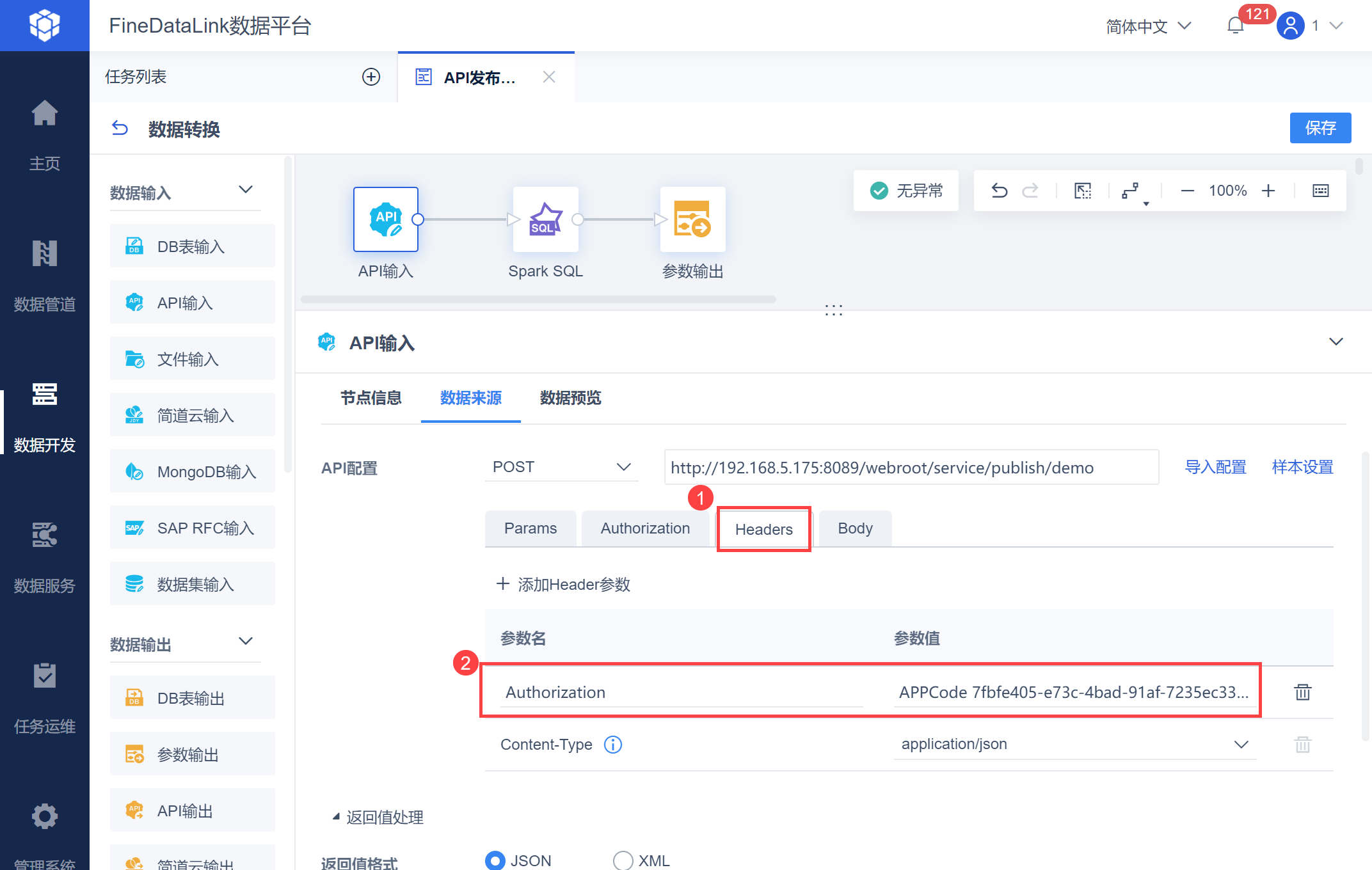
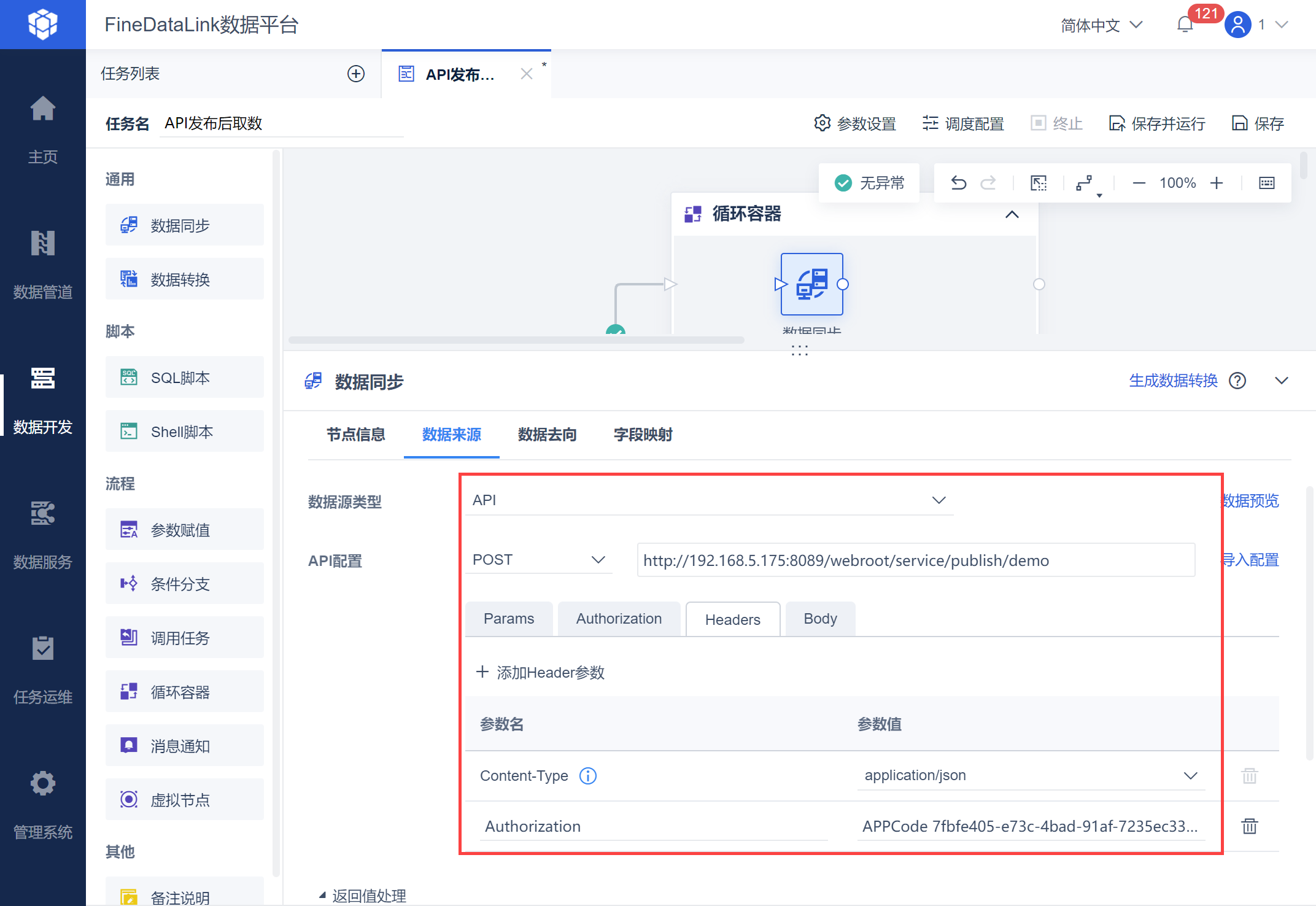
选择 Headers,输入参数名:Authorization,参数值:APPCode 0b1c2234-a439-4098-9e3a-0f41bae1123b,如下图所示:
注:参数值格式为:APPCode+空格+APPCode值,此处的 APPCode 为示例。
然后在Body 中输入 json 数据,如下图所示:
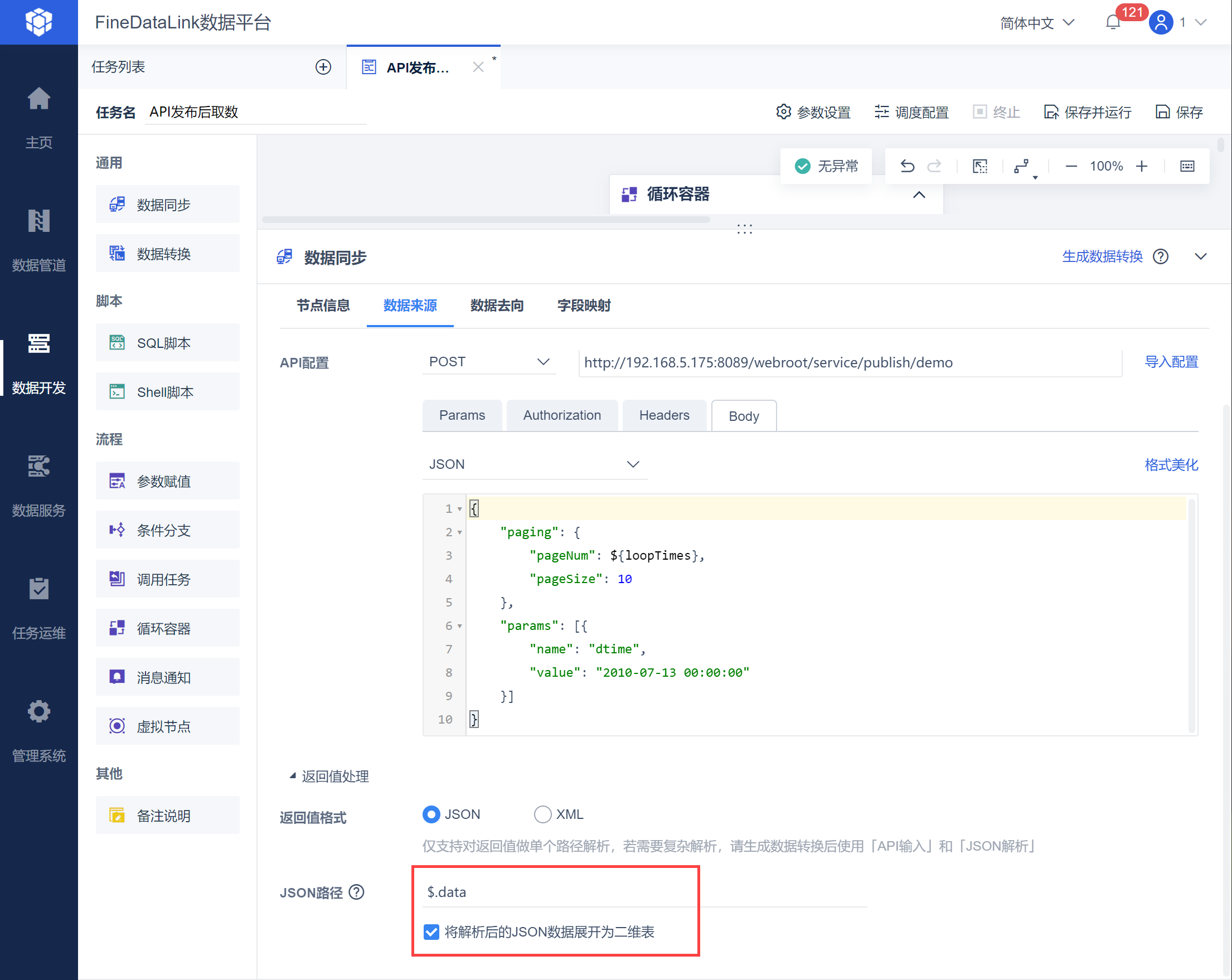
示例取出 2010-07-13 00:00:00 之后的数据,因此自定义参数 dtime 的 value 直接写成 2010-07-13 00:00:00,将 pageSize 设置为 10,也就是每页数据限制为 10 条,从第一个开始取数,查看返回值中,每页 10 条数据计算总页数为多少。
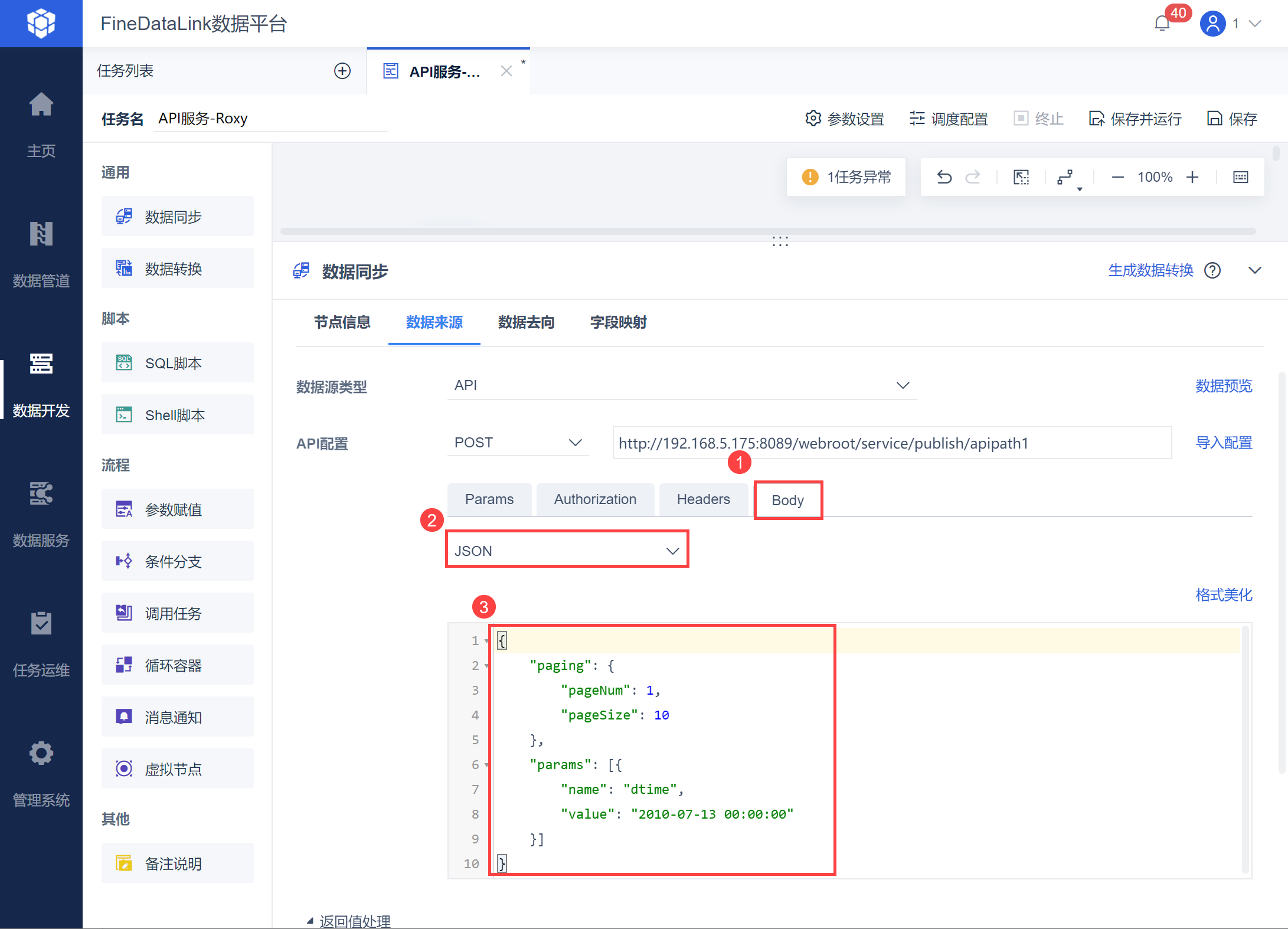
{ "paging": { "pageNum": 1, "pageSize": 10 }, "params": [{ "name": "dtime", "value": "2010-07-13 00:00:00" }]}解析后的返回值如下图所示:
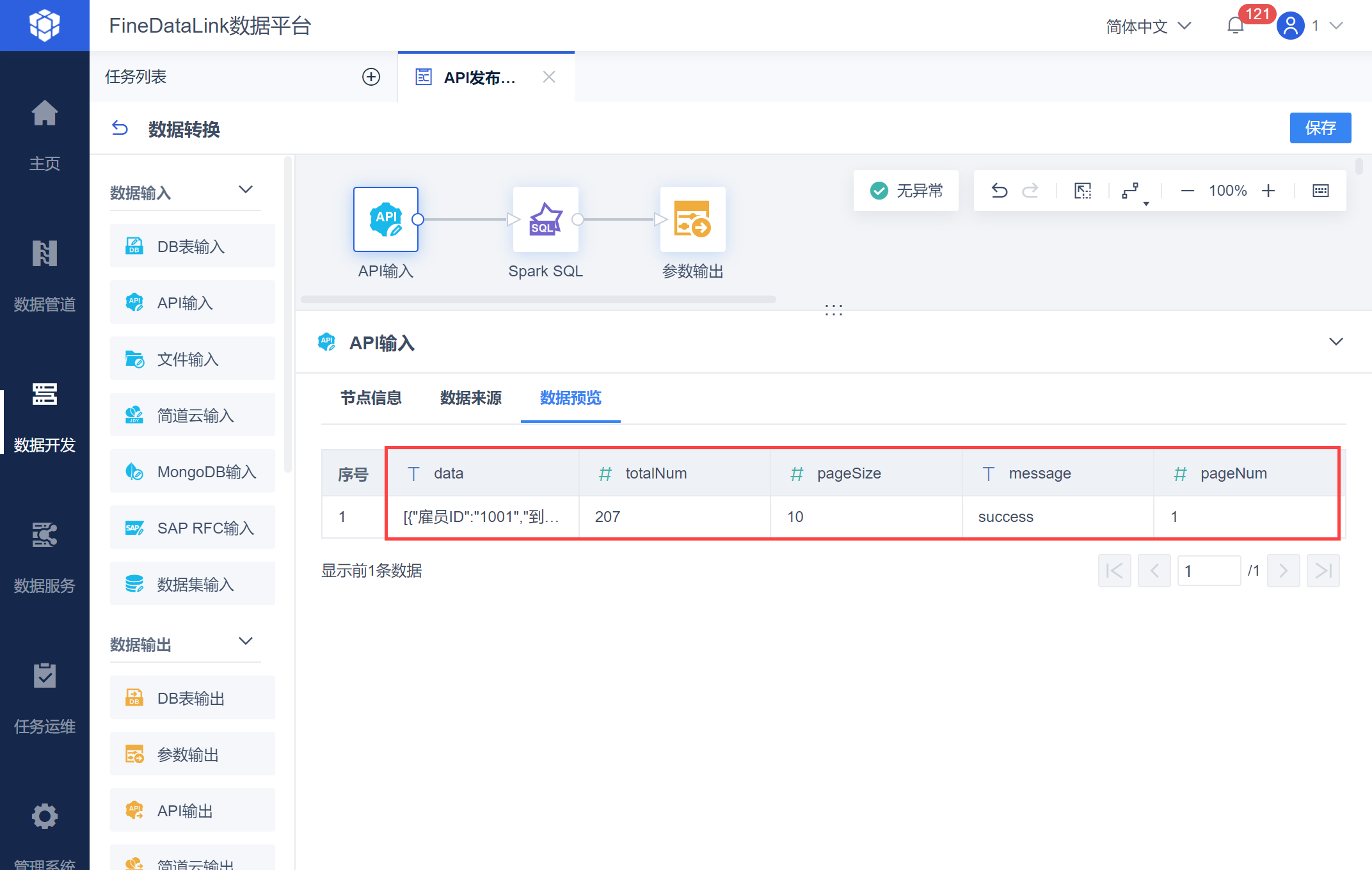
2.3 获取数据总页数
使用获取到的 totalNum:返回总数据条数和 pageSize:每页数据条数进行计算,获取总页数。
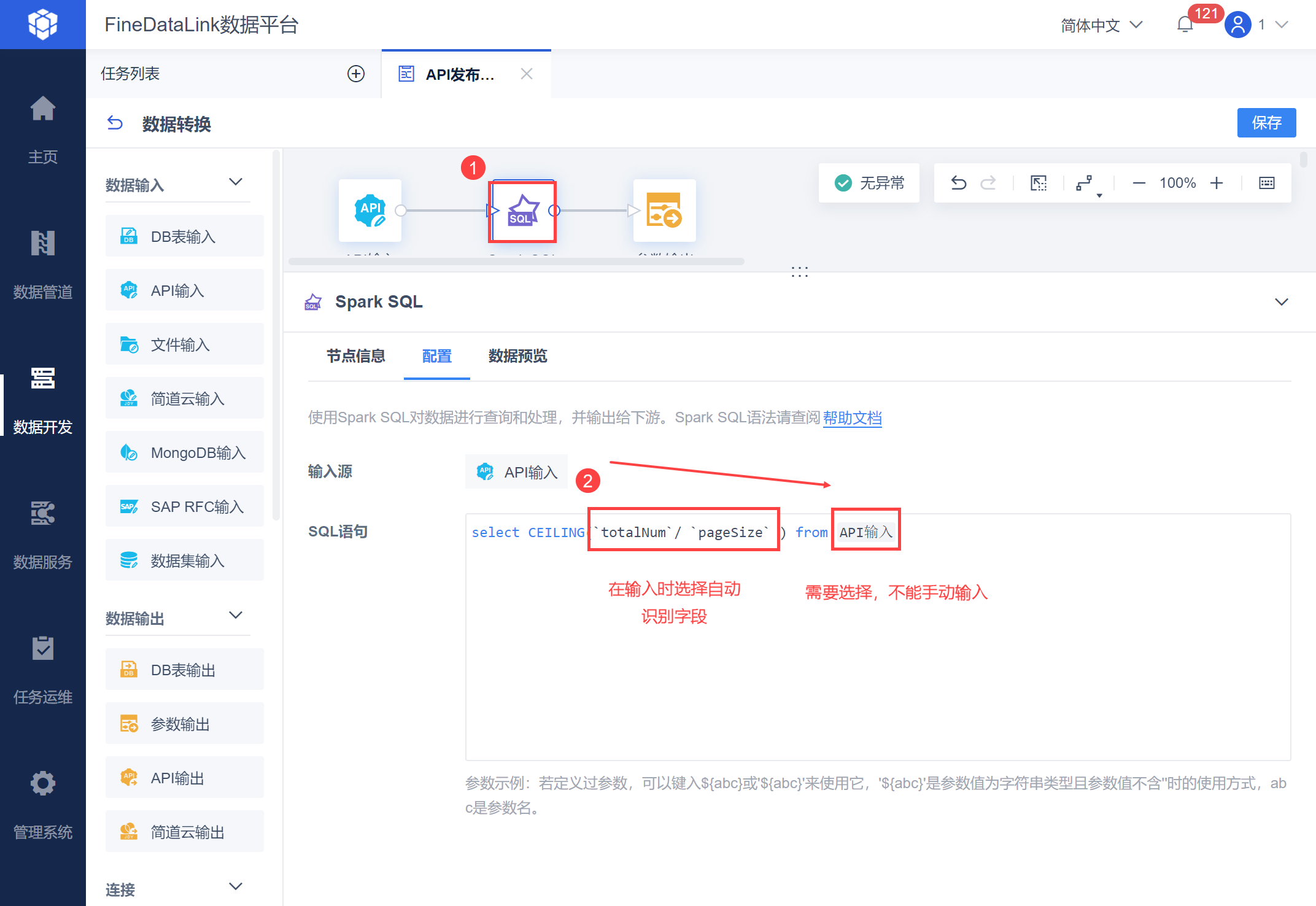
使用 SparkSQL 输入如下公式:
select CEILING(`totalNum`/ `pageSize` ) from API输入
注:totalNum、pageSize 都需要在输入时选择自动识别出的字段,不能手动输入。
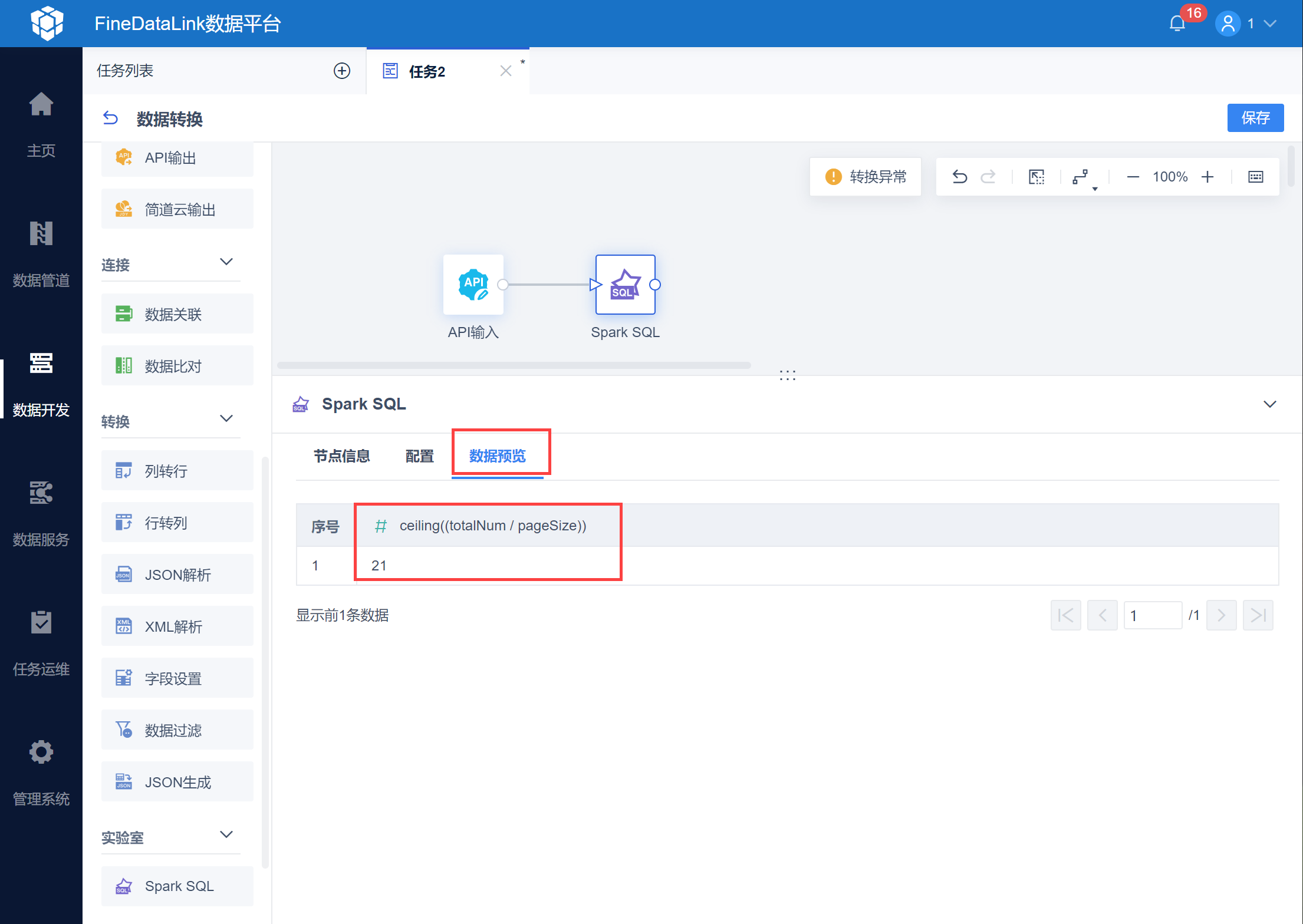
在数据预览界面就可以看到计算出的总页数,如下图所示:
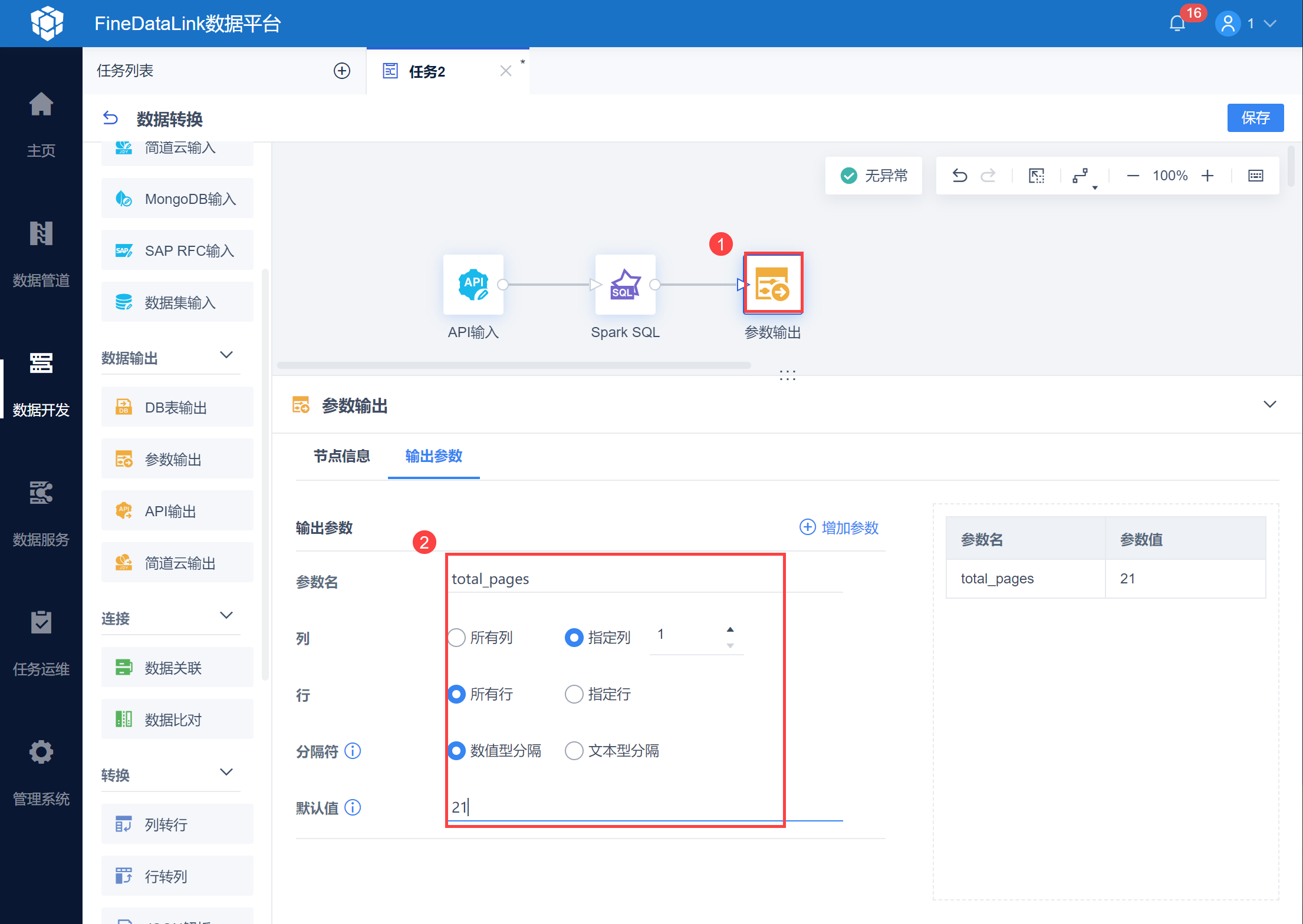
使用参数输出,将总页数设置为参数 total_pages ,如下图所示:
2.4 分批取数
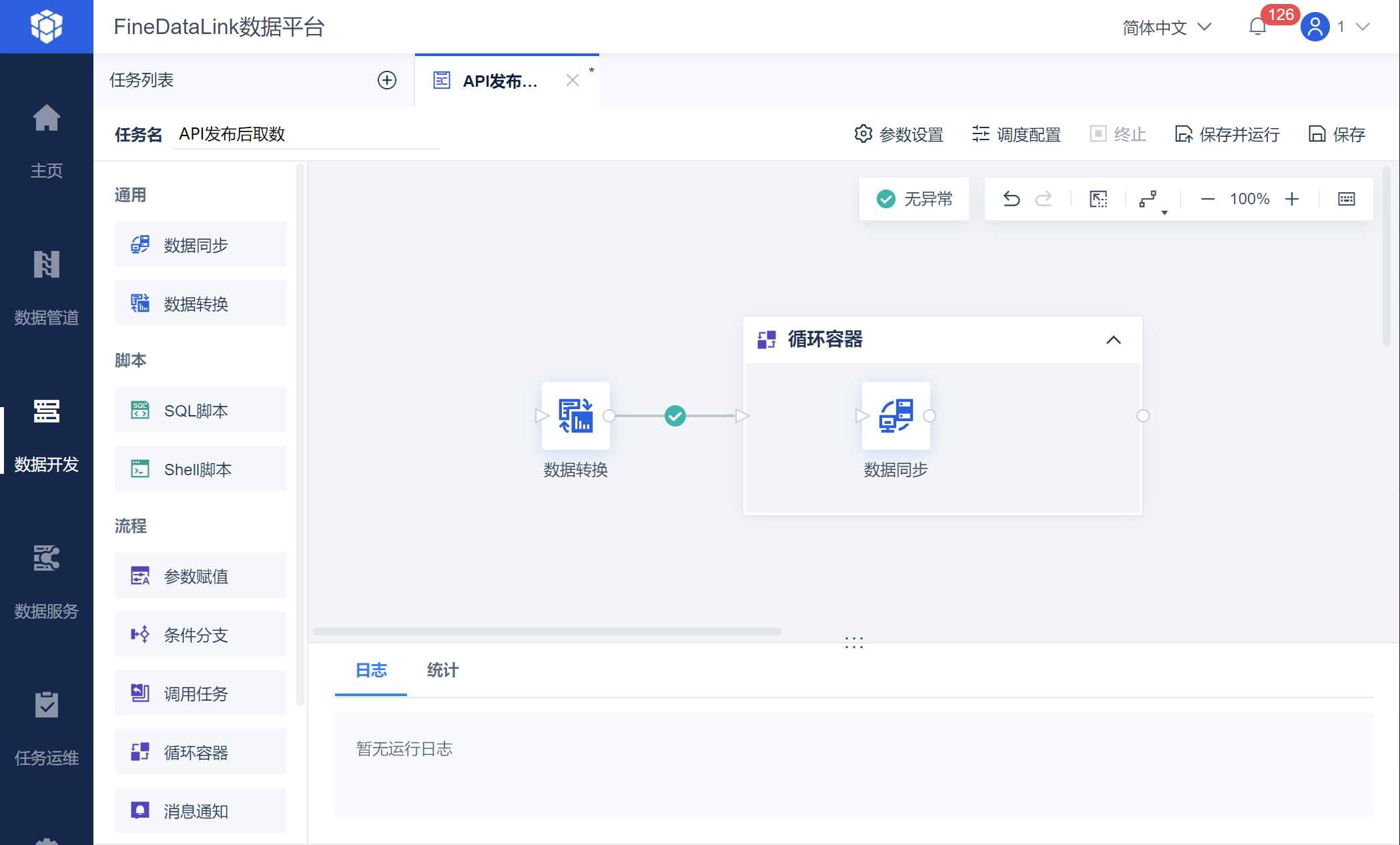
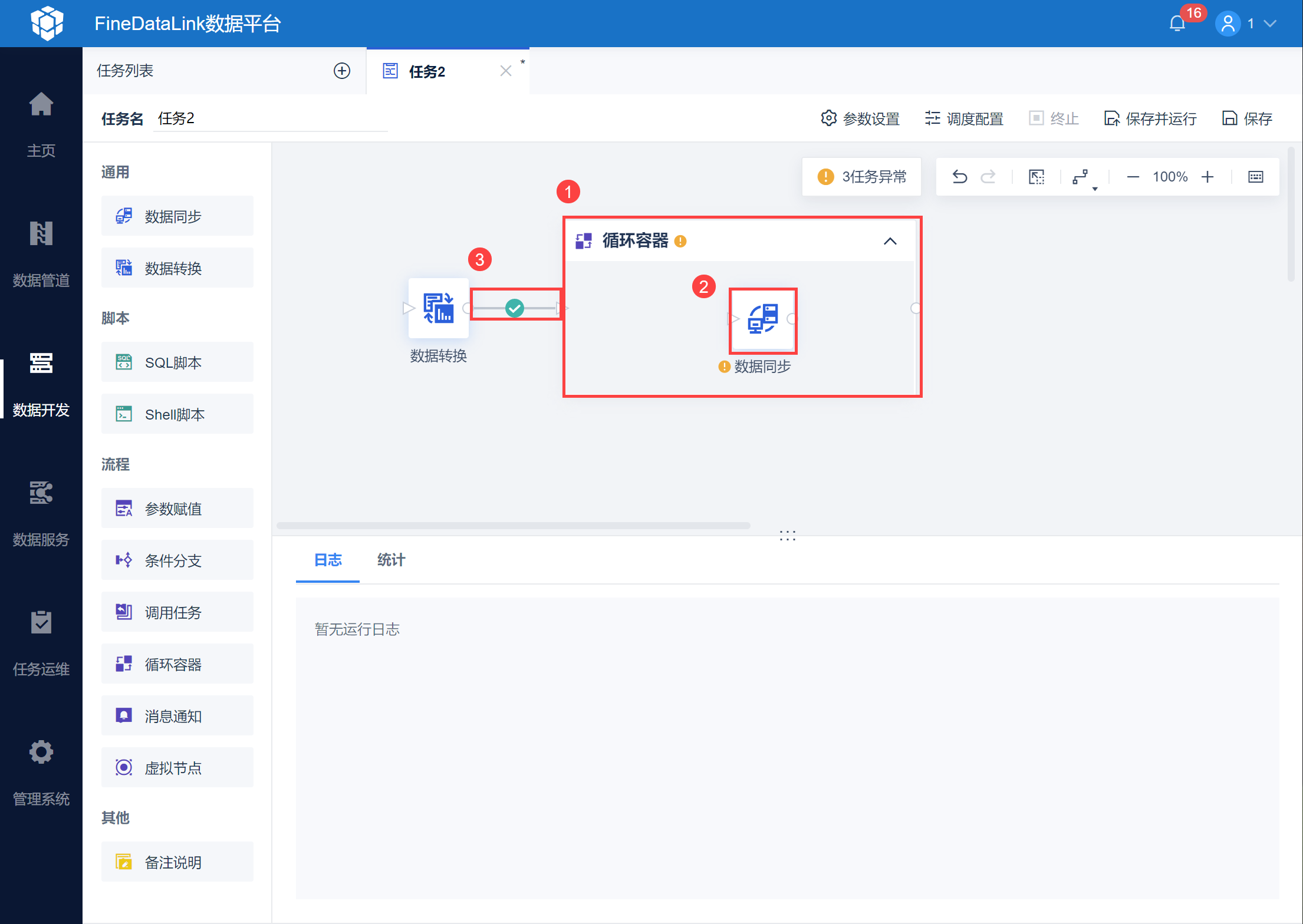
由于需要进行页数分批取出所有数据,因此使用循环容器功能。
保存数据转换节点设置后,进入任务开发界面,拖入循环容器节点,然后再拖入数据同步节点至循环容器中,与上游的数据转换相连,如下图所示:
在数据同步中仍然进行 API 取数的设置,如下图所示:
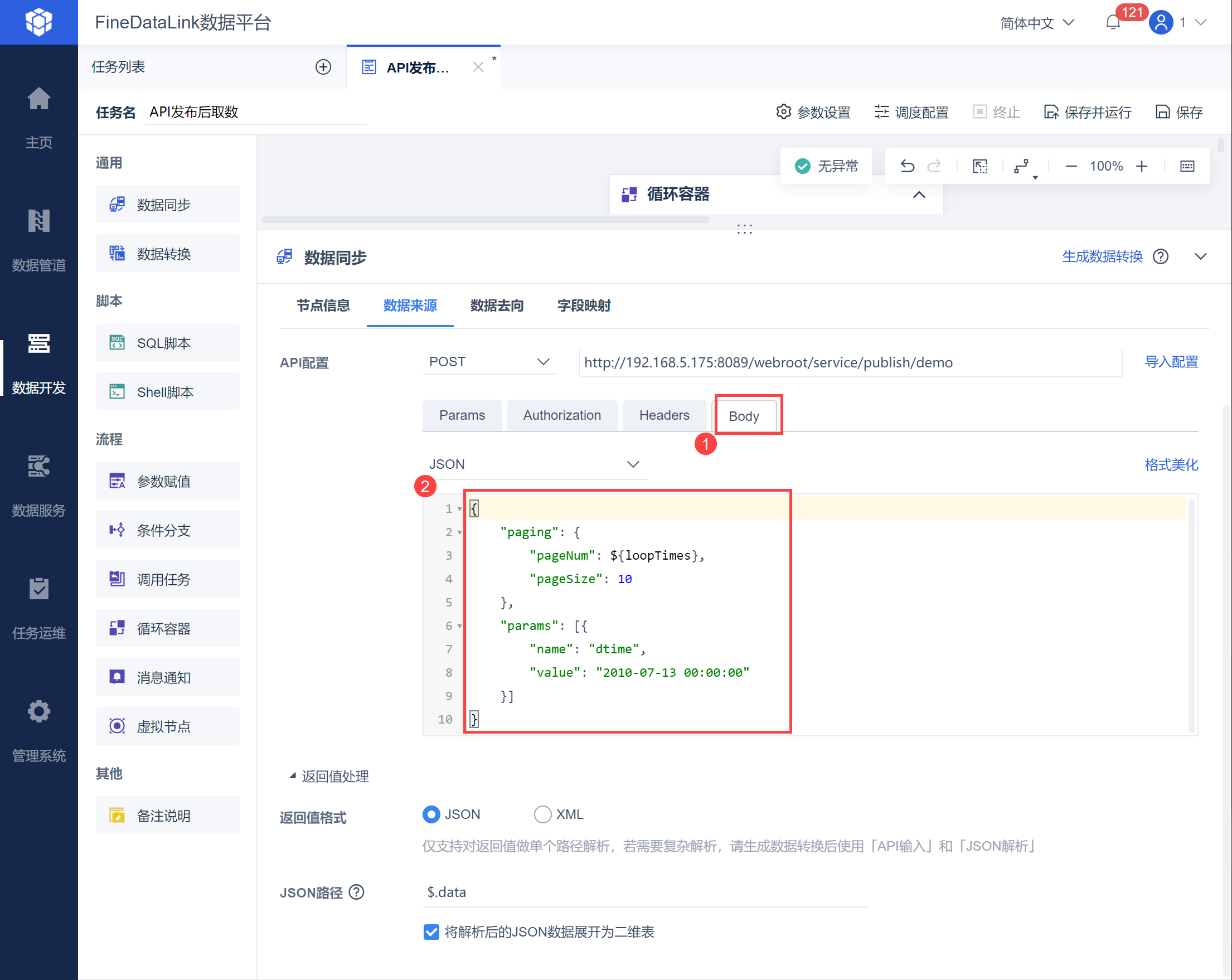
loopTimes 为循环容器内置参数,容器内当前循环次数,初次为 1 ,后续每次循环递增加。该参数即可实现按照页数递增取出所有的数据。
在 Body 中设置 pageSize:10,pageNum 使用内置参数${loopTimes},也就是按照每页 10 条数据,从第一页开始递增从接口取数,如下图所示:
由于返回值为 JSON 格式,可以使用 JSON 格式取出指定的数据,如下图所示:
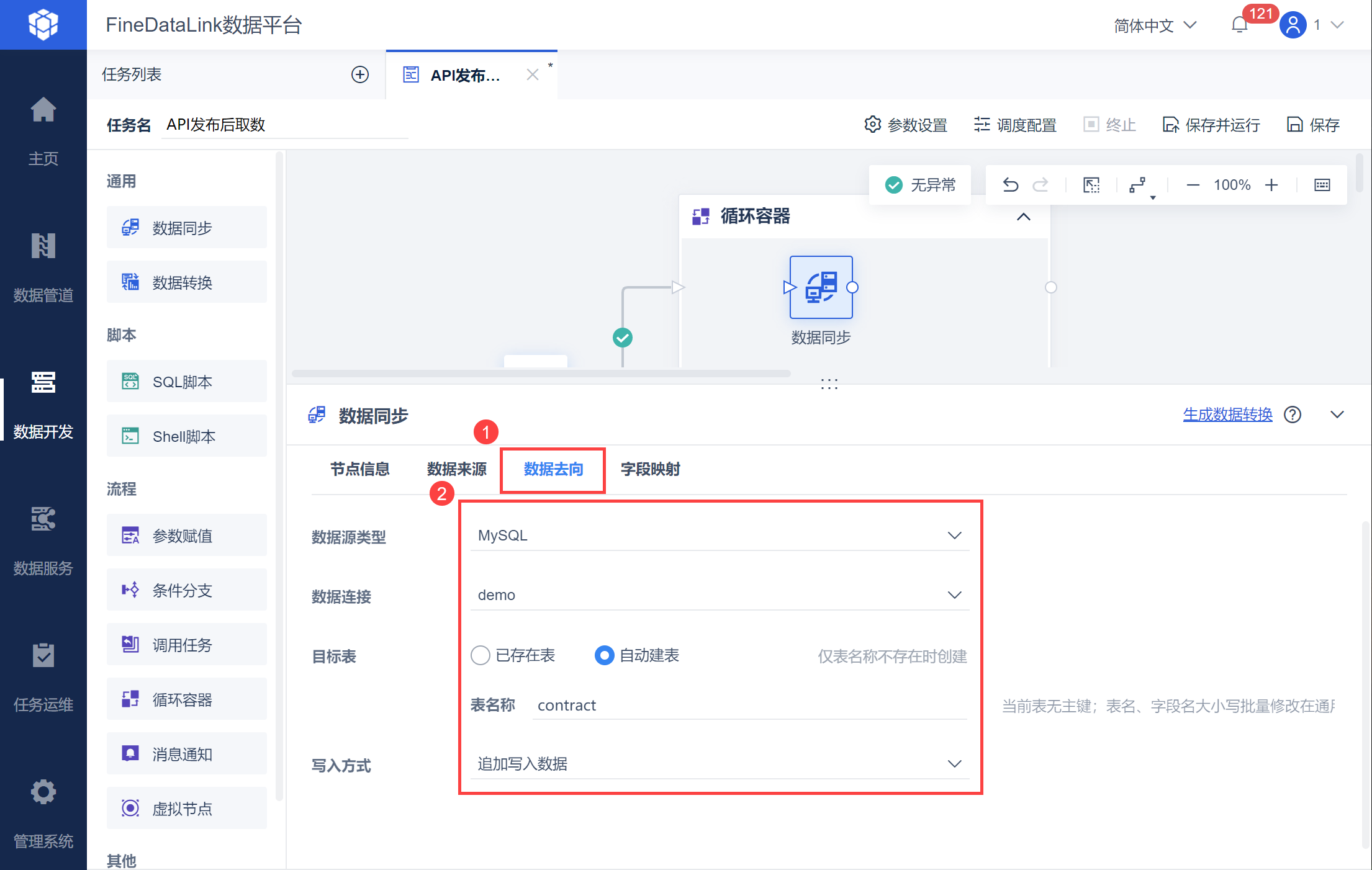
在数据去向中设置指定的输出数据库以及数据表,如下图所示:
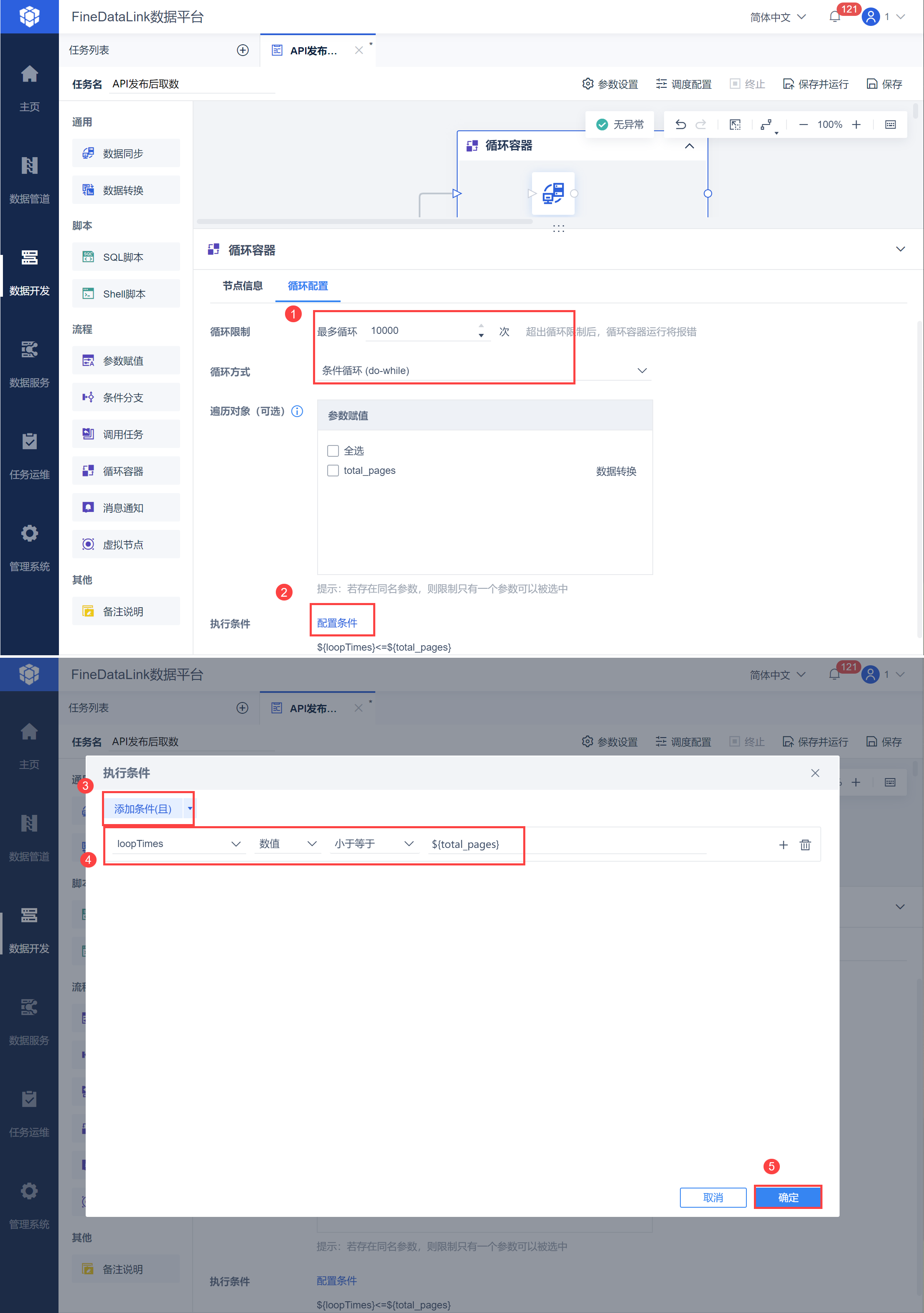
点击循环容器节点,设置循环次数,并设置循环方式为「条件循环」,点击配置条件为 loopTimes<=${total_pages},如下图所示:
此时即可实现当递增的页数大于总页数时,跳出循环停止执行,从而取出所有的数据。
2.5 效果查看
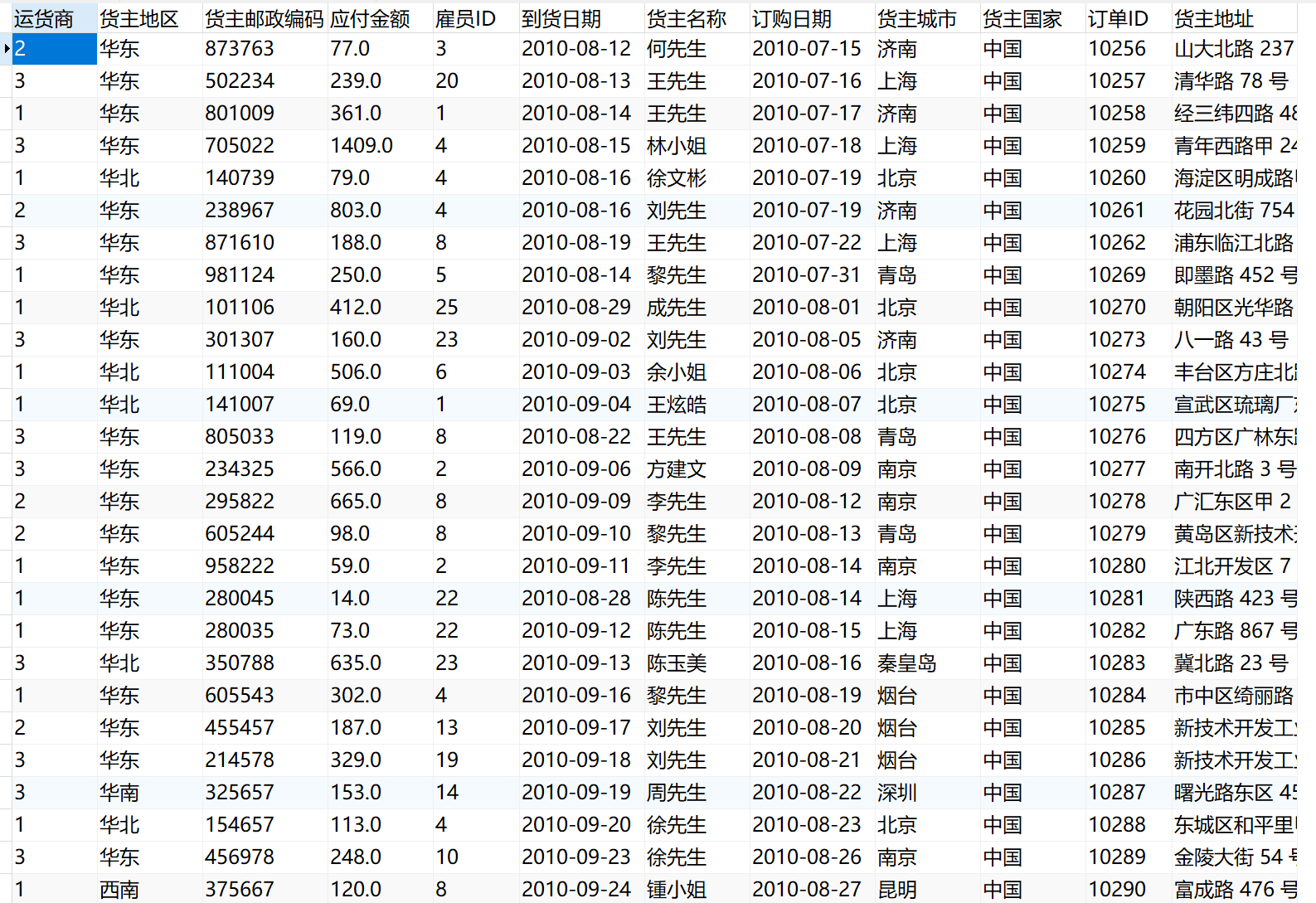
执行任务后,即可在数据库中查看到取出的数据,如下图所示:
3. 接口响应码说明编辑
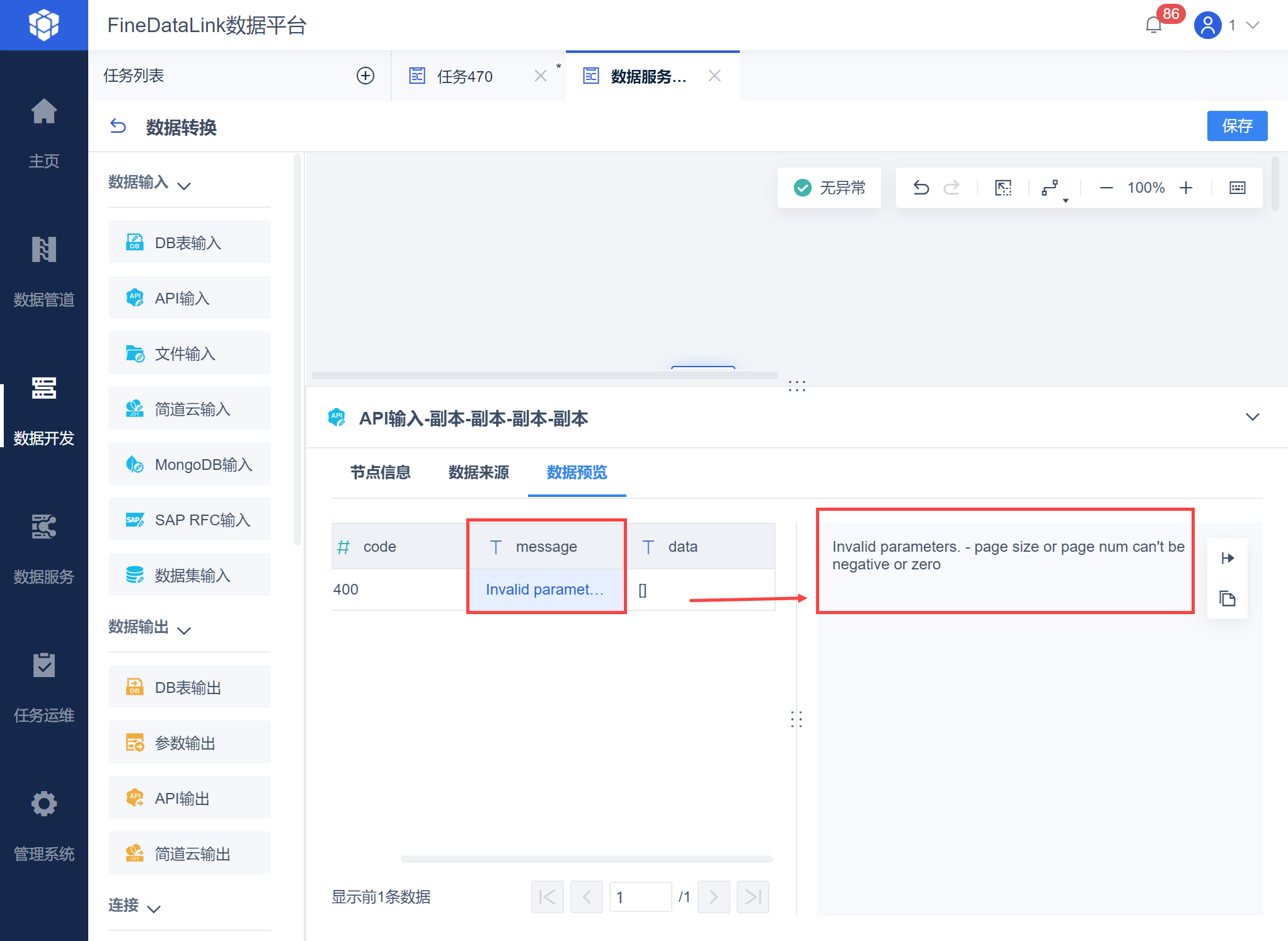
用户在使用API发布的数据时,可以根据 Messege 字段判断 API 响应成功与否。
Messege 为 success,则返回成功,如下图所示:
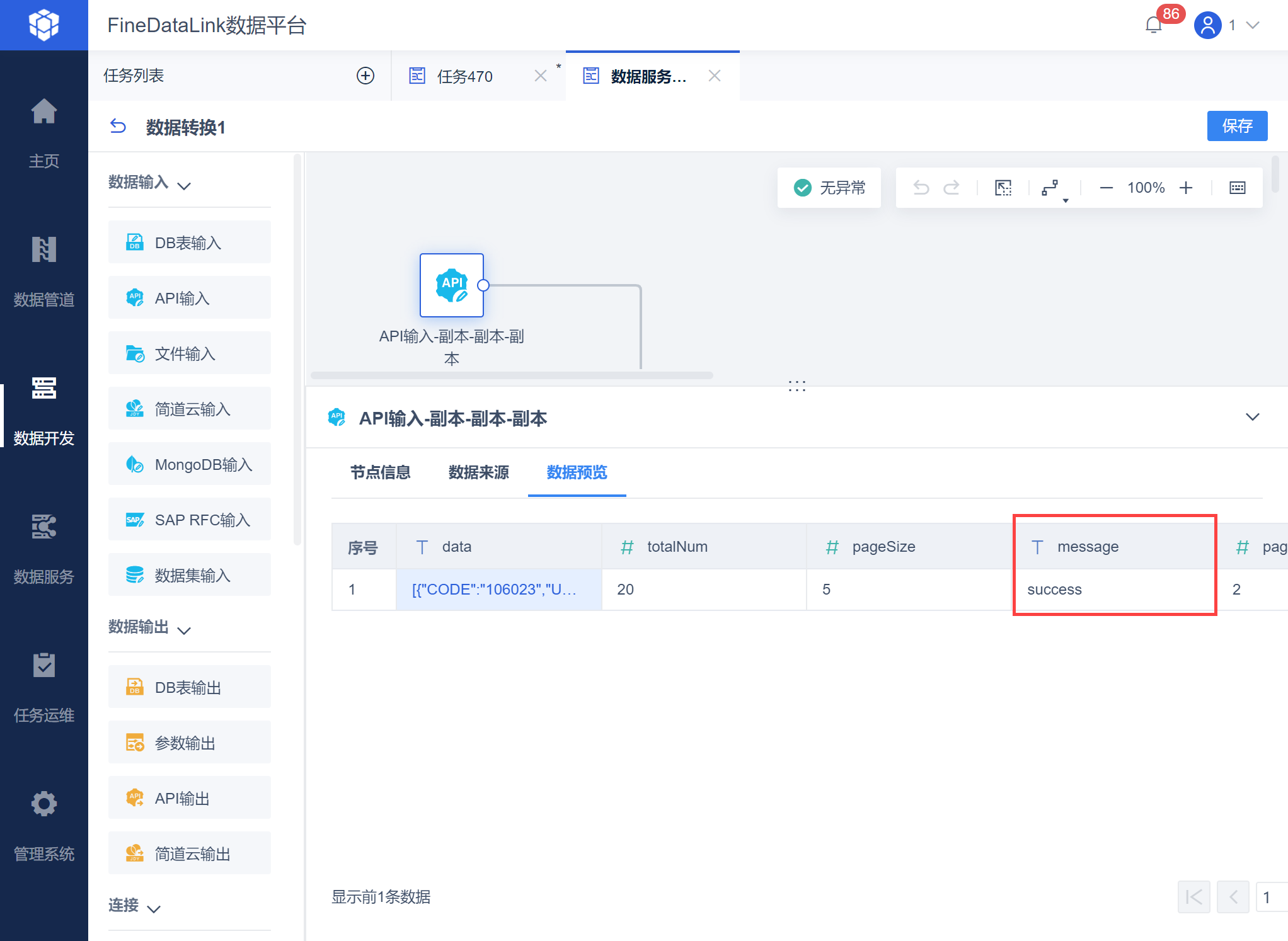
否则当返回失败时,会返回失败状态码:
HTTP状态码400:客户端请求异常,可能是URL错误、认证异常、参数错误等。
HTTP状态码500:服务端处理异常,需要结合后台监控报错信息排查具体出错原因。
失败时具体原因会在Messege中体现,如下图所示: