

1. 概述编辑
1.1 版本说明
| FineDataLink 版本 | 功能变动 |
|---|---|
| 4.0.6 | 支持Mysql 作为读取和写入数据源 |
| 4.0.28 | 管道任务支持写入至 TiDB 数据库 管道任务支持写入至 ClickHouse 管道任务支持写入至Amazon Redshift |
| 4.1.2 | GaussDB 数据库,支持「目标端执行逻辑删除」 |
| 查看历史版本更新 | ||||||||||||||||||
|
1.2 应用场景
企业在在构建数仓和中间库时,由于业务数据量级较大,如果使用数据同步批量定时同步数据很难做到高性能的增量同步,若使用清空目标表再写入数据的方式时,还会面临目标表一段时间不可用、抽取耗时长等问题。
因此希望能在数据库数据量大或表结构规范的情况下,实现高性能的「实时数据同步」。
1.3 功能说明
FineDataLink监听数据管道来源端的数据库日志变化,利用 Kafka 作为数据同步中间件,暂存来源数据库的增量部分,进而实现向目标端实时写入数据。
支持对数据源进行单表、多表、整库数据的实时全量和增量同步,可以根据数据源适配情况,配置实时同步任务。
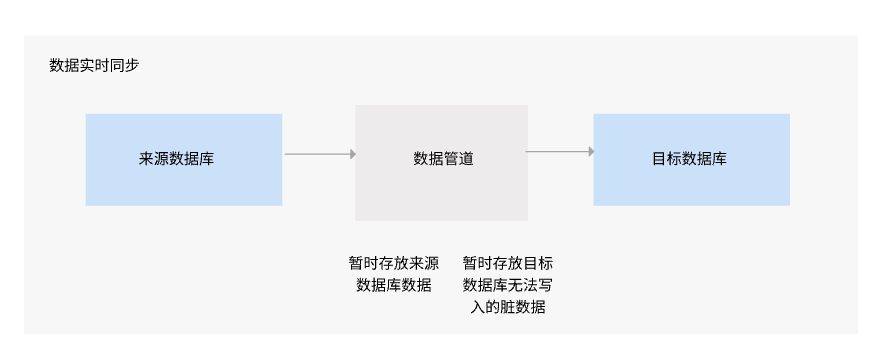
本文为你介绍数据管道数据同步支持的数据源情况。
2. 约束限制编辑
管道任务仅支持在「独立部署」环境下使用。
管道任务不支持同步视图和索引。
3. 功能概述编辑

| 功能 | 描述 |
|---|---|
| 多种数据源间的数据同步 | 实时同步支持多种数据源,可以将多种来源端及目标端数据源搭配组成同步链路进行数据实时同步。 详情请参见本文第五节。 |
| 数据同步场景 | 支持对数据源进行单表、多表、整库数据的实时全量和增量同步。
同步类型为存量+增量同步:先对所有存量数据完成同步,随后持续同步新增的变化数据(增/删/改) |
| 实时数据同步任务配置 | 实时同步任务配置无需编写代码,通过简单的任务配置即可实现单表、整库实时数据的同步。详情请参见:配置数据管道任务 1)设置目标端:
关于实时同步各目标端支持的DDL操作详情请参见:同步源表结构变化。
注1:4.1.2 之前版本,GaussDB 数据库不支持「目标端执行逻辑删除」;4.1.2 及之后版本,支持「目标端执行逻辑删除」 注2:PostgreSQL9.4以下(含9.4)版本数据库,不支持「目标端执行逻辑删除」
2)设置字段映射:
3)设置管道控制:
|
| 实时同步任务运维 | 支持对同步任务进行监控,详情请参见:管道任务运维。
|
4. 操作流程编辑
使用 FineDataLink 数据管道进行数据同步的操作流程如下:
1)数据源配置。在进行数据管道任务配置前,配置好需要同步的源端和目标端数据库,以便在同步任务配置过程中,可通过选择数据源名称来控制同步任务的读取和写入数据库,详情参见:配置数据连接
2)数据源环境已准备完成:基于需要设置数据管道任务的数据源,授予数据源配置的账号在数据库进行相应操作的权限。详情请参见数据库环境准备概述。
3)部署 Kafka 开源流处理平台作为中间件,详情参见:部署Kafka、配置传输队列
4)若需要使用数据管道的用户不是超级管理员,则需要为对应用户分配数据管道的使用权限,详情参见:管道任务管理权限
5)完成上述操作即可配置数据管道任务:配置数据管道任务。
5. 数据管道支持的数据源编辑
详情参见:数据管道支持的数据源
若需要使用对应数据源,则需要参考文档注册相关功能:注册简介