

1. 概述编辑
1.1 版本
| FineDataLink 版本 | 功能变动 |
|---|---|
| 4.0.17 | 支持Mysql 设置同步源表结构变化 |
| 4.0.20.1 | 支持SQL Server、Oracle 、GaussDB 200、PostgreSQL、Greenplum、Greenplum(并行装载)作为目标端设置同步源表结构变化 |
| 4.0.21 | Oracle数据源作为来源端,适配同步源表结构变化 |
| 4.0.27 | 交互体验优化 |
| 4.0.28 | 支持TiDB、Amazon Redshift、SeaboxMPP 作为目标端的DDL |
| 4.0.29 | 支持 PostgreSQL 作为来源端的 DDL |
| 4.1.1 | 支持 SQL Server 作为来源端的 DDL,DDL 逻辑详情参见本文3.3 节表格,且目前 DDL 同步不支持自动同步源端新增字段,若需要使用 DDL 进行新增字段的处理,请参见本文第四章。 |
1.2 应用场景
在使用管道任务进行数据实时同步过程中,来源端结构可能因业务调整等原因发生变动,如增删表、增删字段、修改字段名称、修改字段类型等,此时,用户希望目标端可以自动同步这些来源端的调整,不需要人为的进行数据表的调整。
1.3 功能说明
数据管道任务支持同步源库DDL功能,开启相关选项后,在源库发生DDL(删除表、新增字段、删除字段、修改字段名称、修改字段类型(长度修改 & 兼容类型修改))时,管道任务可以自动同步这些来源端变化至目标端,不需人为介入修改目标表结构。
2. 支持范围编辑
| 数据源 | 来源端 | 目标端 |
|---|---|---|
| MySQL | 支持 | 支持 |
| Oracle | 支持 | 支持 |
| SQL Server | 支持 | 支持 |
| GaussDB 200 | 不支持 | 支持 |
| PostgreSQL | 支持 | 支持 |
| Greenplum 包括并行装载 | 不支持 | 支持 |
| kafka | 不支持 | 不支持(目标端暂不支持kafka) |
| Doris、StarRocks | 不支持 | 不支持 |
| TiDB | 不支持(来源端暂不支持TiDB) | 支持 |
| Amazon Redshift | 不支持(来源端暂不支持Amazon Redshift) | 支持 |
| DB2 | 支持 | 不支持 |
| SeaboxMPP | 不支持(来源端暂不支持SeaboxMPP) | 支持 |
| SAP HANA | 不支持 | 不支持 |
3. 操作步骤编辑
注:此步骤为非 SQL Server 数据库的 DDL 操作,若需要使用 SQL Server 进行 DDL 则需要对数据库进行操作,详情参见本文第四章。
示例以 MySQL 数据同步至 MySQL 数据库为例。
将 test_1 数据库中的「出入库信息」、「DEMO_PRODUCT」、「CUSTOMER」数据表实时同步至 demotest 数据库中。
DEMO_PRODUCT.xls、出入库信息.xls、CUSTOMER.xls
3.1 配置数据管道任务
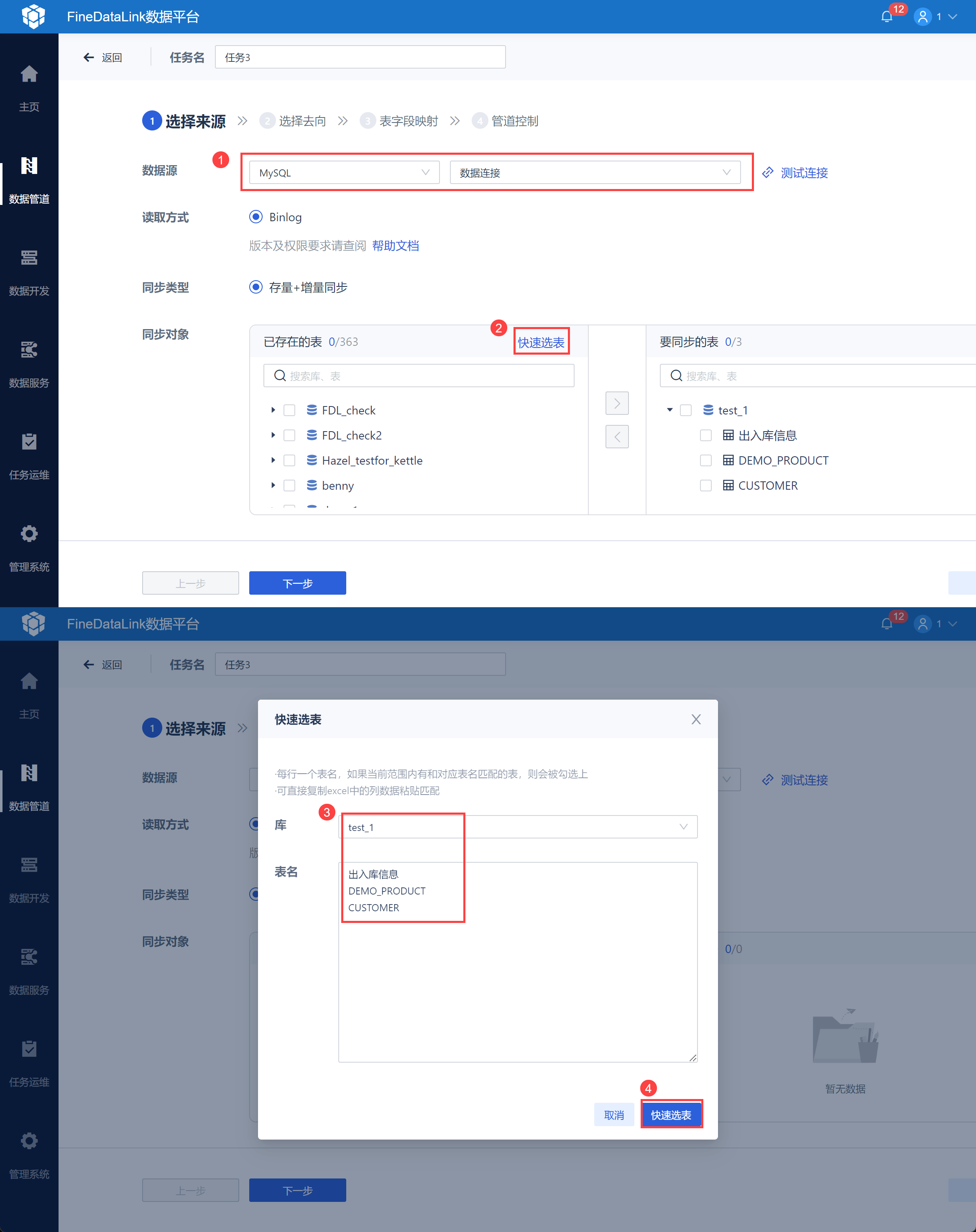
1)参考:配置数据管道任务 设置数据来源,选择需要同步的数据表,如下图所示:
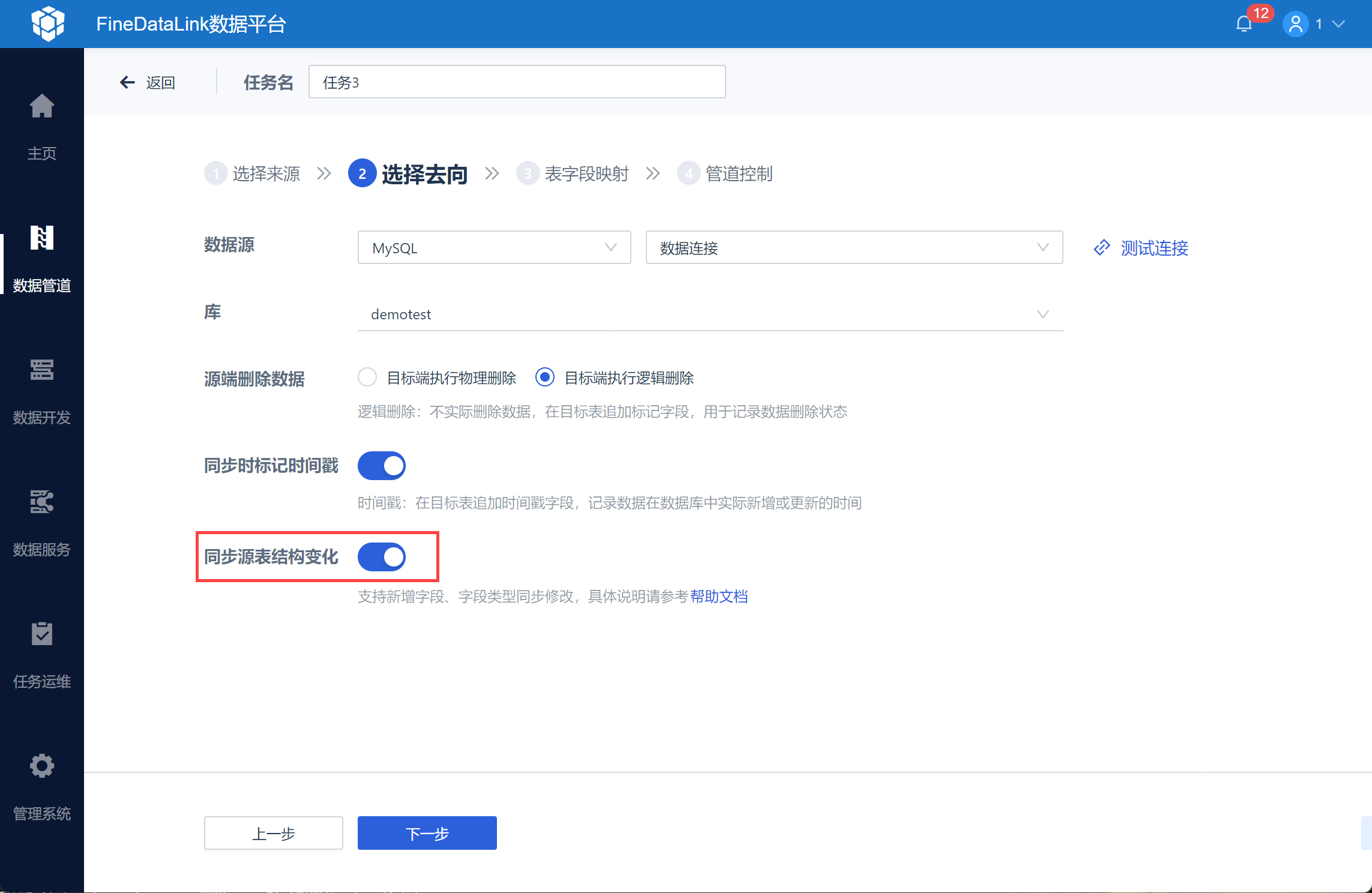
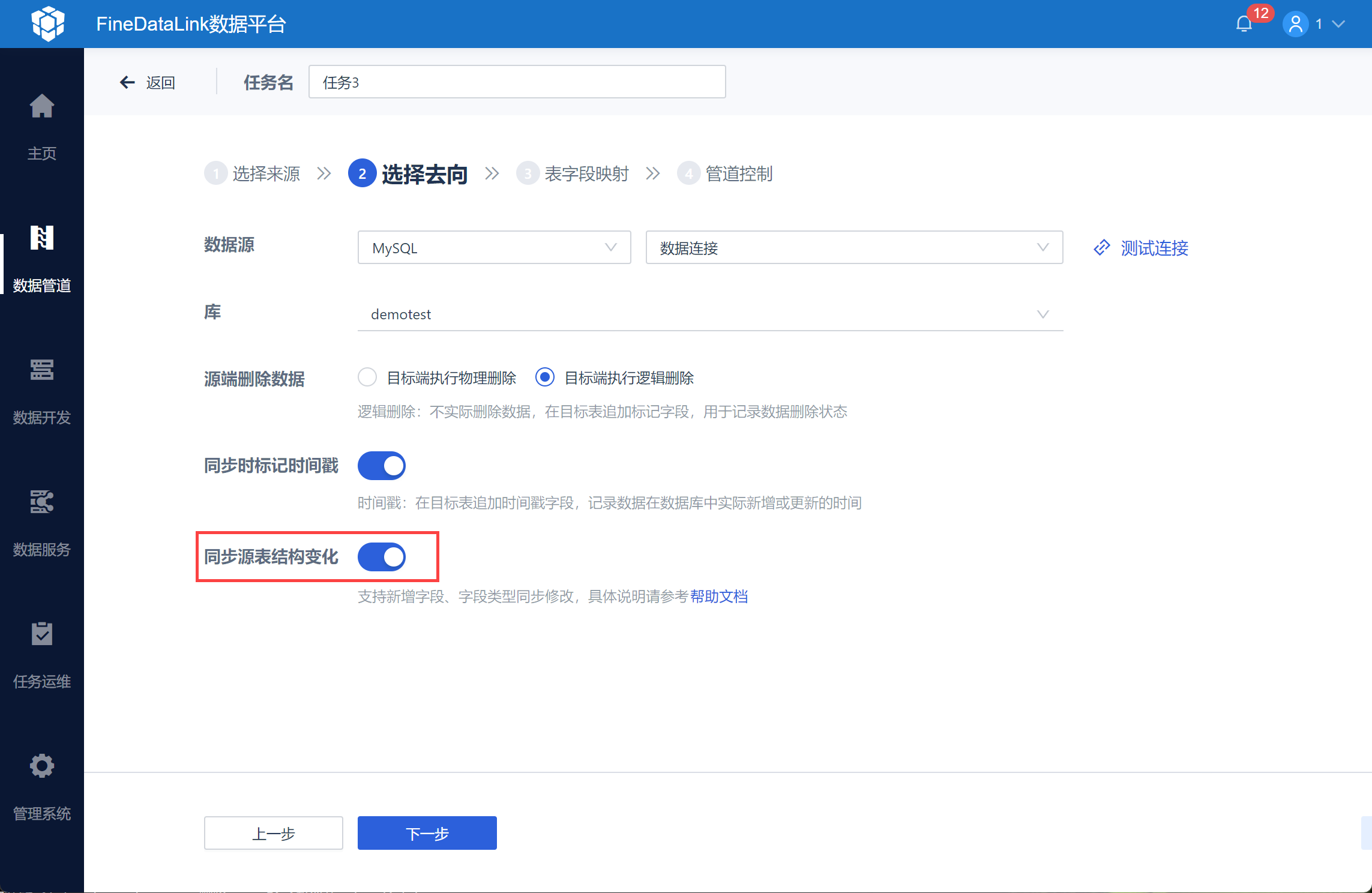
2)同时在「选择数据去向」时,勾选「同步源表结构变化」按钮,如下图所示:
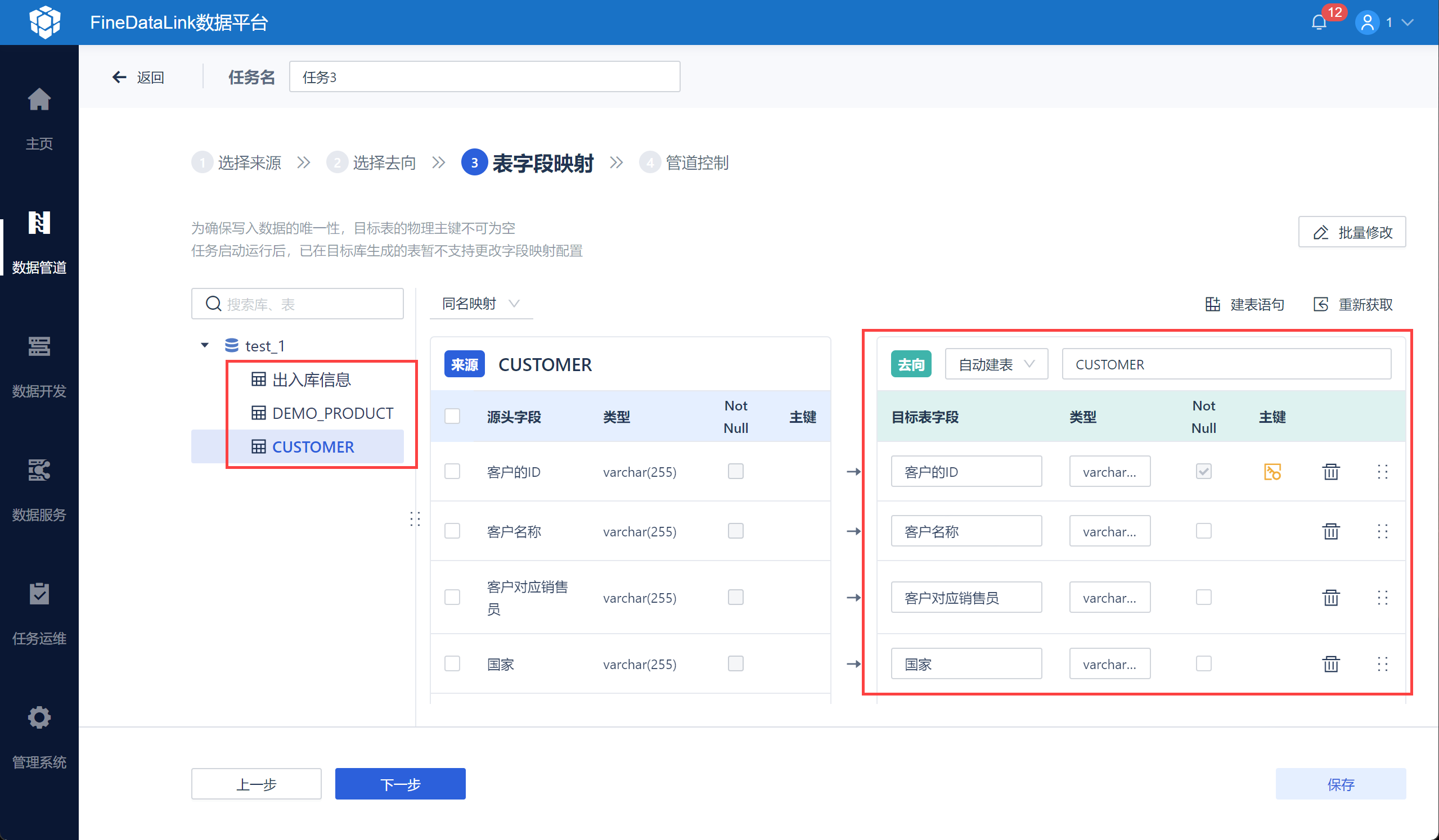
3)设置表字段的映射关系,修改目标表名并设置主键,如下图所示:
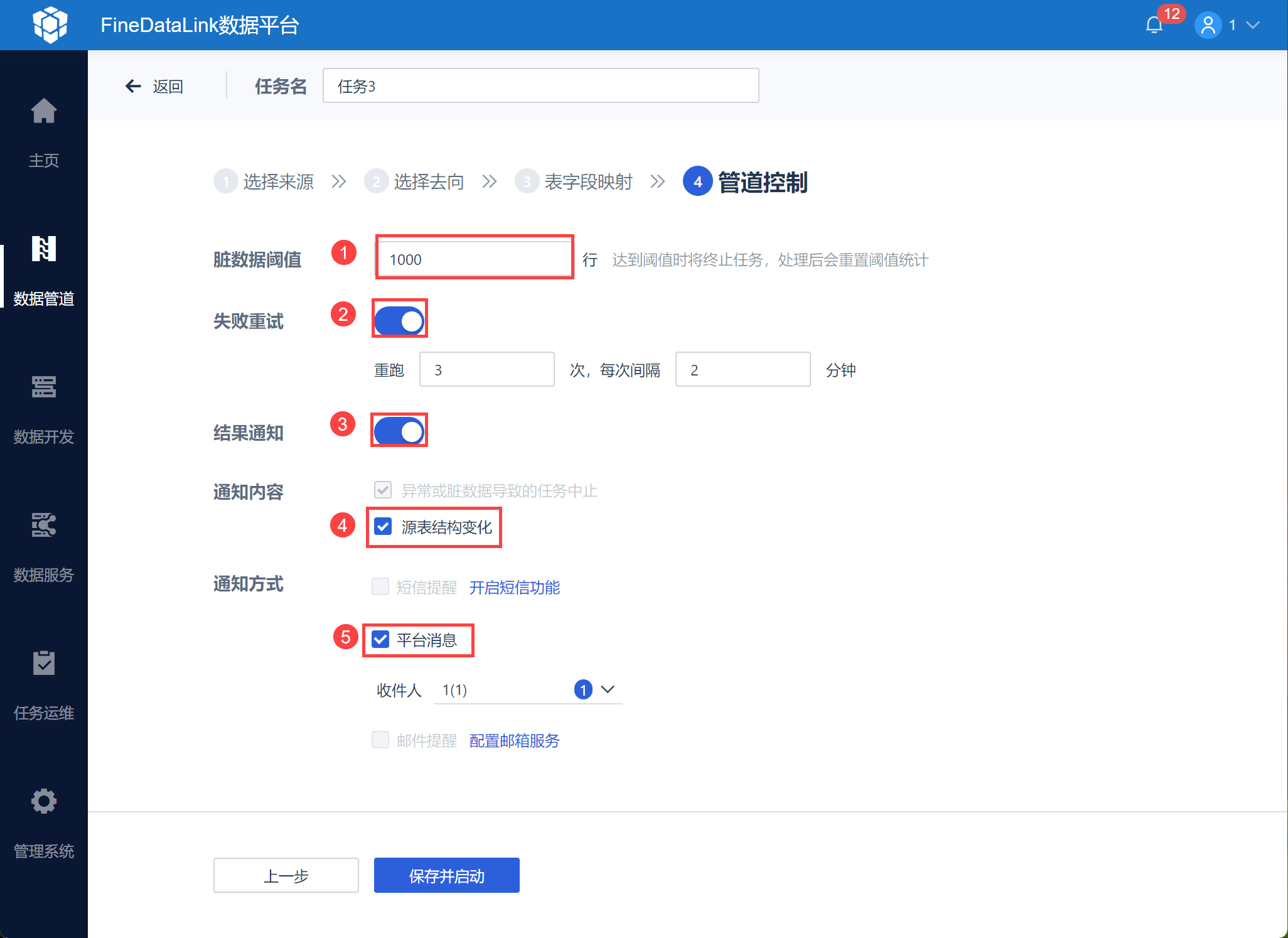
4)设置任务的脏数据阈值、勾选「失败重试」,并选择「消息通知」,勾选「源表结构变化」,并选择通知方式,如下图所示:
此步骤可保证来源端结构因业务调整等原因发生变动,如增删表、增删字段、修改字段名称、修改字段类型后用户可即时被提醒。
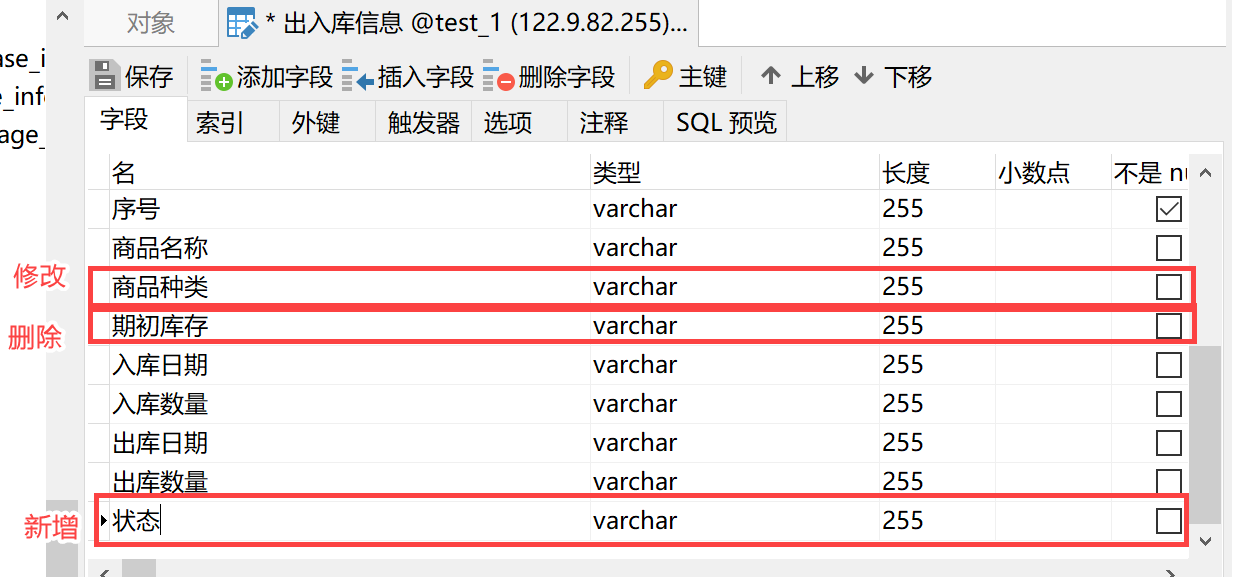
3.2 来源端数据变化
在设置管道任务后「出入库信息」表中新增了「状态」字段、修改「种类」字段为「商品种类」、删除了「期初库存」字段,如下图所示:
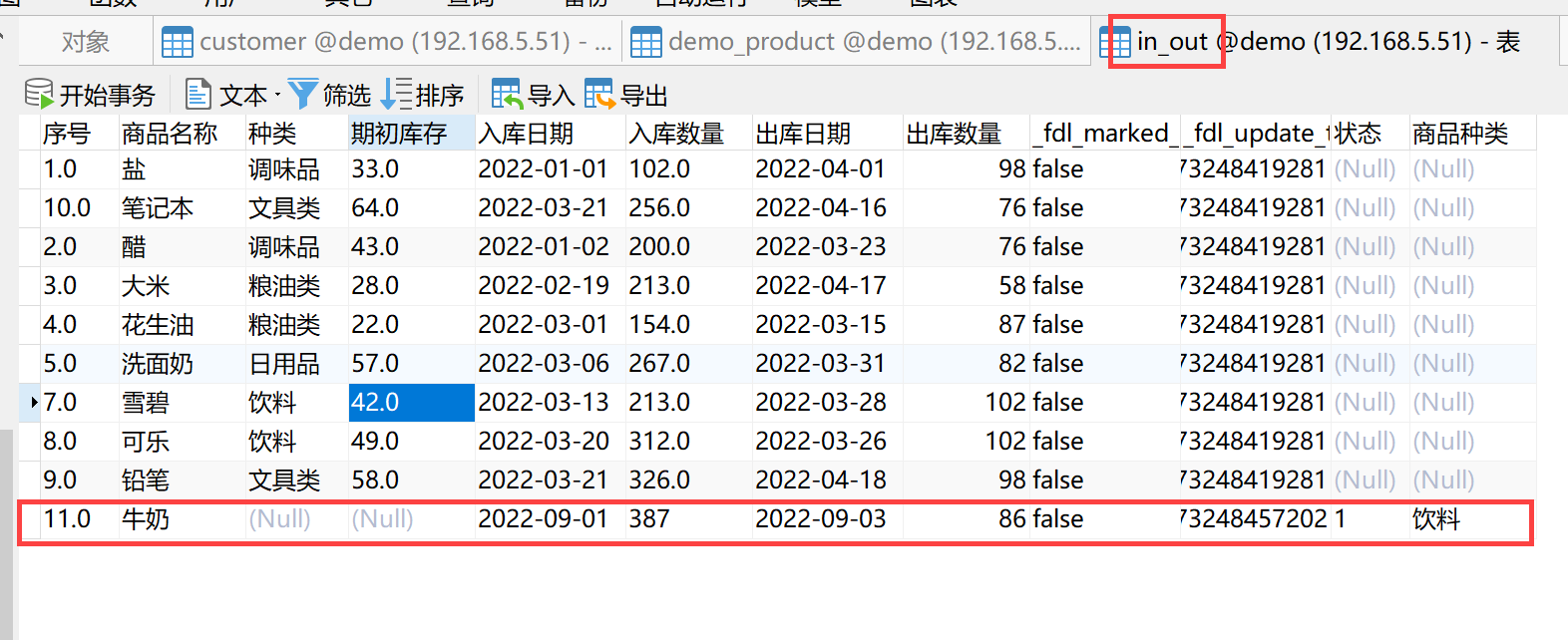
3.3 目标端同步结果
查看「出入库信息」目标端数据「in_out」,例如「序号」为11的这条数据为数据结构变化后同步的数据,在修改字段后同步的数据中:
新增字段:同步新增字段后续新增的数据(状态字段同步新增数据);
删除字段:被删除字段在后续同步中传NULL值(期初库存字段同步NULL 值);
修改字段名称:原名称字段在后续同步中传NULL值,同步新名称字段的后续新增数据(种类字段修改为商品种类后,种类字段停止同步,商品种类字段继续同步新增数据)。
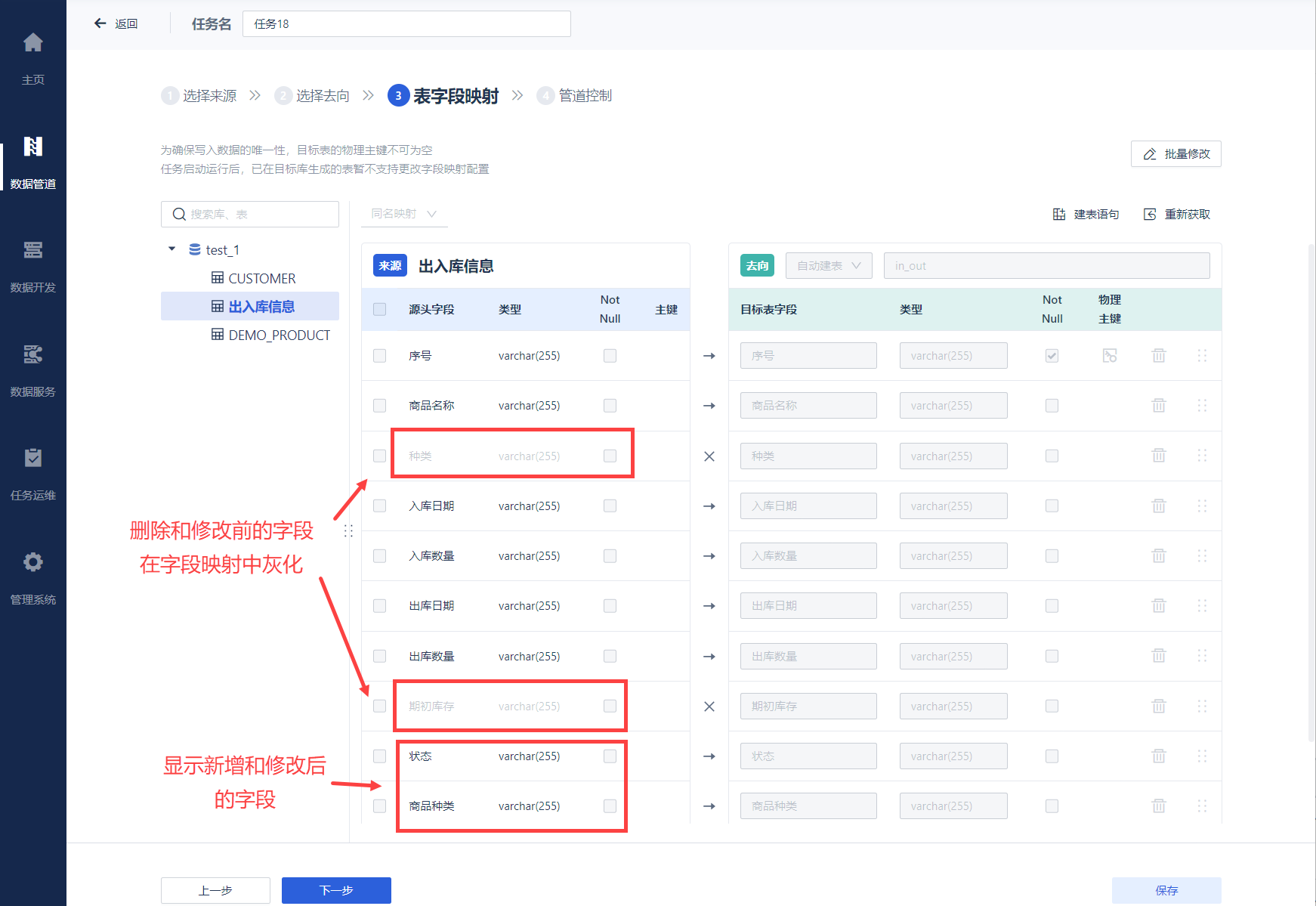
同时在「表字段映射」中会对修改进行标记,如下图所示:
开启「同步源表结构变化」后,数据结构变化实时同步说明:
操作 | 「开启」同步源表结构变化 | 字段映射配置变化 | 目标表结构变化 | 目标表数据变化 |
|---|---|---|---|---|
| 删除表 | 继续同步其他表。 | 标记被删除的同步表。 该表对应源表已被删除,该表将不会继续同步。 | 无变化。 | 被删除表在后续同步中将没有新数据写入。 |
重命名表 | 继续同步其他表。 注:PostgreSQL 作为来源端,不支持重命名表。 | 标记原名称表为删除。 该表对应源表已被删除,该表将不会继续同步。 | 无变化。 | 原名称表在后续同步中将没有新数据写入。 |
| 删除字段 | 继续同步其他字段。 | 标记被删除的字段。 对应源字段已被删除,该字段在后续同步中将传NULL值。 | 无变化。 | 被删除字段在后续同步中传NULL值。 对于 SQLServer 数据源作为来源端,在检测到字段删除的时刻(每次查询都会比对表结构检测),FDL 就会当做字段已经删除。 此时 CDC 表中可能还存在一部分数据带有这个字段,此时该字段的值将不会同步到目标表中。 |
| 新增字段 | 自动同步新增字段。 同步失败时,记录日志且发送通知,任务正常运行。 对于 SQLServer 数据源作为来源端,目前DDL同步不支持自动同步源端新增字段,若需要进行新增字段 DDL ,需要对数据库进行操作,详情参见本文第四章。 | 自动在来源端和目标端添加新的映射关系。 | 同步新增字段。 新增的这个字段不标记物理主键或逻辑主键 | 同步新增字段的后续新增数据。 |
| 修改字段名称 | 原名称字段删除,新名称字段新增。 对于 SQLServer 、DB2数据源作为来源端,不支持修改字段名称。 | 标记原名称字段删除。 自动在来源端和目标端添加新名称字段的映射关系。 | 同步新增新名称字段。 | 原名称字段在后续同步中传NULL值。 同步新名称字段的后续新增数据。 |
| 修改字段类型或者长度 | 自动同步修改字段类型,修改不成功时,记录日志,任务继续运行。修改时的字段映射逻辑和自动建表时一致。 | 来源表与目标表字段配置自动修改字段类型。 | 同步修改字段类型。 | 历史数据与后续新增数据变化为对应类型数据。 |
3.4 任务管理
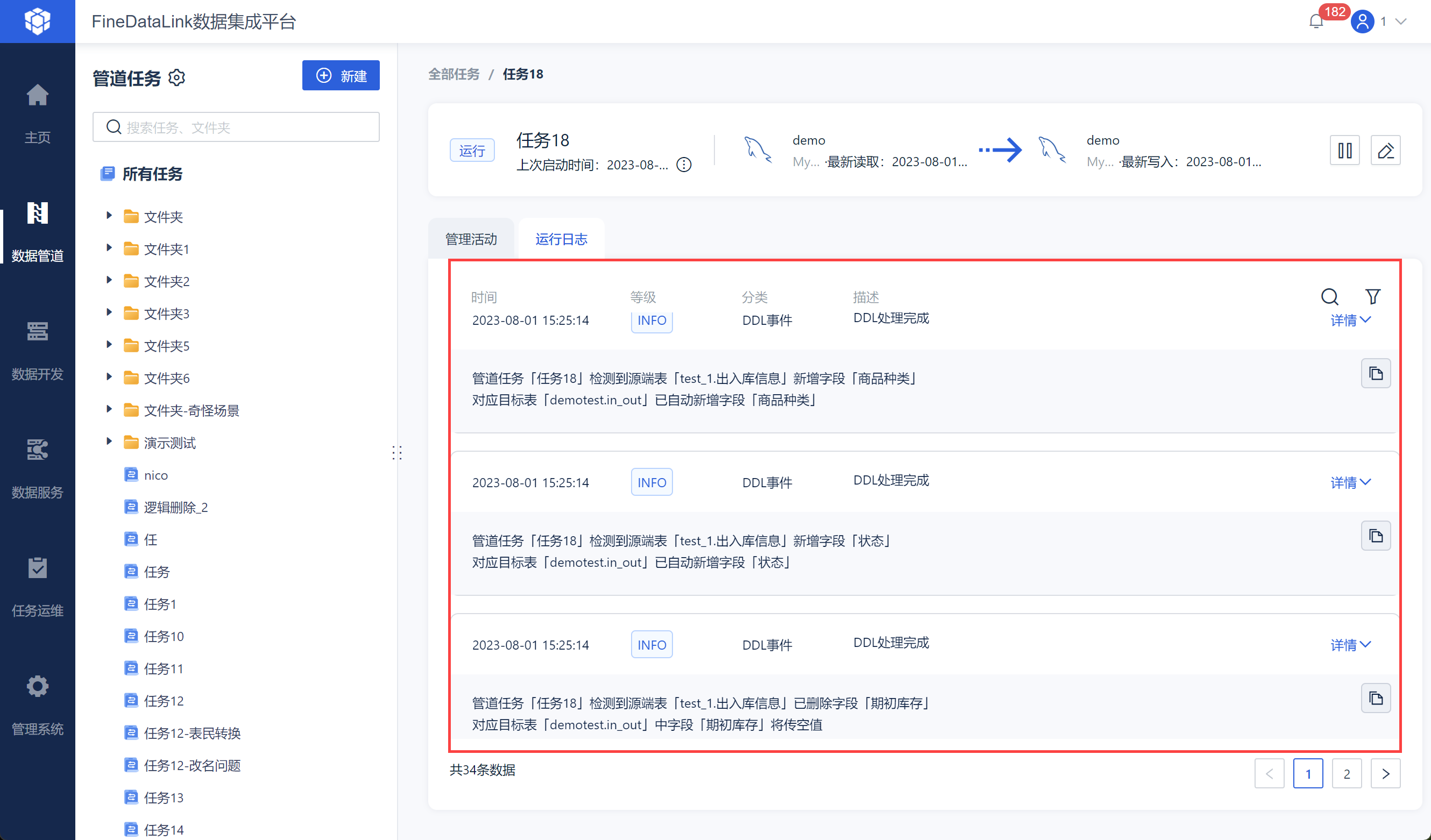
「运行日志」界面会出现 DDL 的更改日志,如下图所示:
4. SQL Server DDL 操作说明编辑
4.1 新增字段
对于SQLServer数据源,目前 DDL 同步不支持自动同步源端新增字段,若需要使用 DDL 进行新增字段的处理,请参见下文提供的方案。
4.1.1 在线方案
注:此方案如果源表在不停写入数据,源表新增字段之后,没有立刻创建新的 CDC 实例,那么在源表新增字段之后到新的 CDC 实例创建前的这段时间中,源表发生的数据修改是不会写入到新的 CDC 实例中的。这可能会导致部分数据丢失新增字段的数据,如果要完全避免这种情况,请采用离线处理方案。
1)源表执行 DDL,新增一个字段。
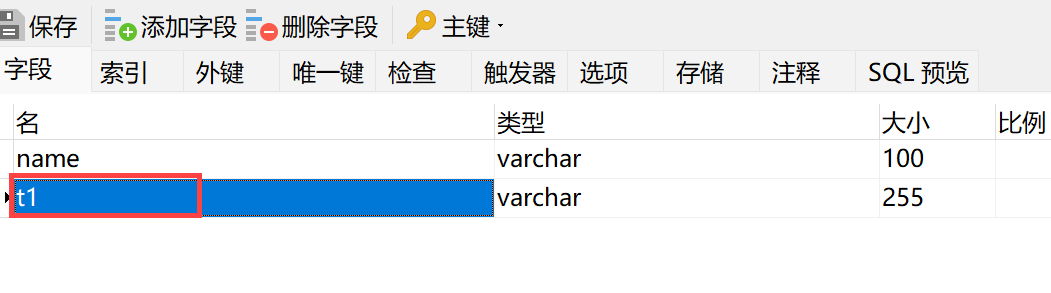
2)给源表新建一个 Capture Instance
使用命令:
EXEC sys.sp_cdc_enable_table
@source_schema = N'Schema',
@source_name = N'Table',
@role_name = NULL, -- 如果要限制读取角色,可能需要设置
@capture_instance = N'Schema_Table_newname'; -- 给一个新的名字
注:Table 是数据表的名称(没有 schema )。
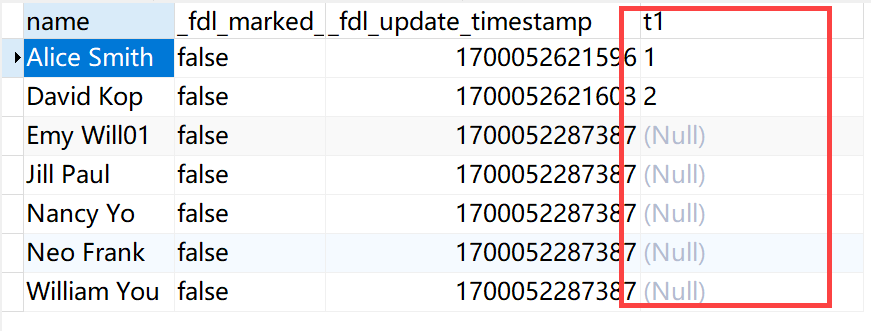
3)等待 FineDataLink 检测到新的 Capture Instance 创建后,自动切换到新的 Capture Instance
即可看到目标表中已经同步新增的字段,如下图所示:
4)可以手动把旧的 Capture Instance 删除。
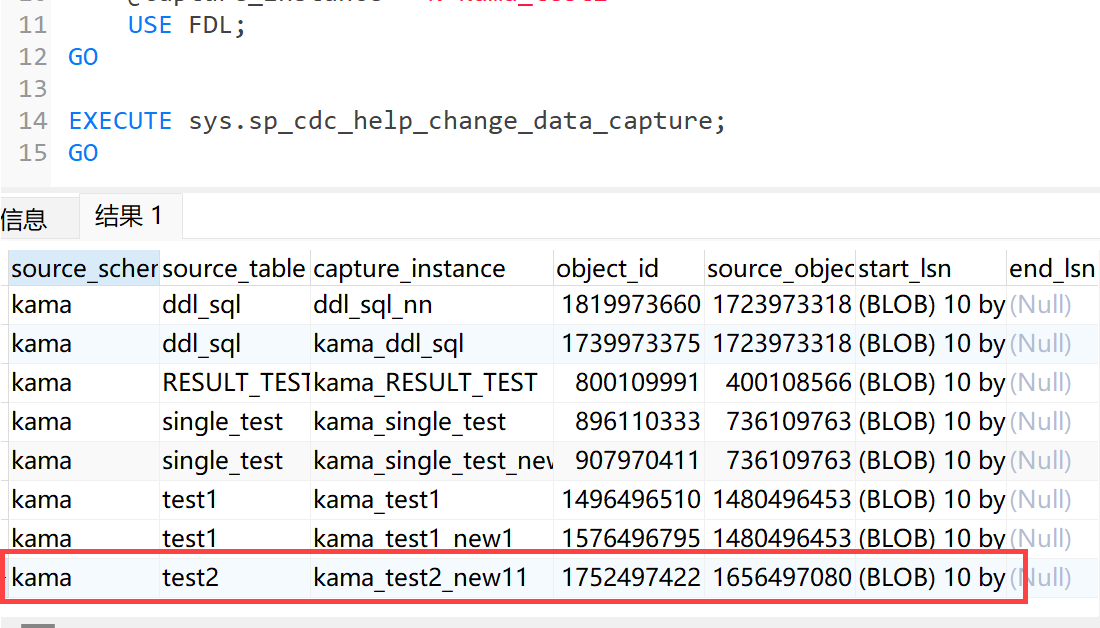
检查 change_tables 中旧的 Capture Instance 名称:
USE database;
GO
EXECUTE sys.sp_cdc_help_change_data_capture;
GO
然后禁用该 Capture Instance ,示例命令:
-- Disable a Capture Instance for a table
EXEC sys.sp_cdc_disable_table
@source_schema = N'Schema',
@source_name = N'Table',
@capture_instance = N'Schema_Table'
注:Table 是数据表的名称(没有 schema );Schema_Table 为需要删除的旧 Capture Instance 。
然后使用如下命令检查 change_tables 里是否有这条记录,若没有则表示已经被删除,若有的话需要手动使用 SQL 命令删除。
USE database;
GO
EXECUTE sys.sp_cdc_help_change_data_capture;
GO
4.1.2 离线处理方案
1)源表停止写入,等待 FineDataLink 同步完源表所有的数据。
2)停止管道任务。
3)源表执行 DDL,新增一个字段:
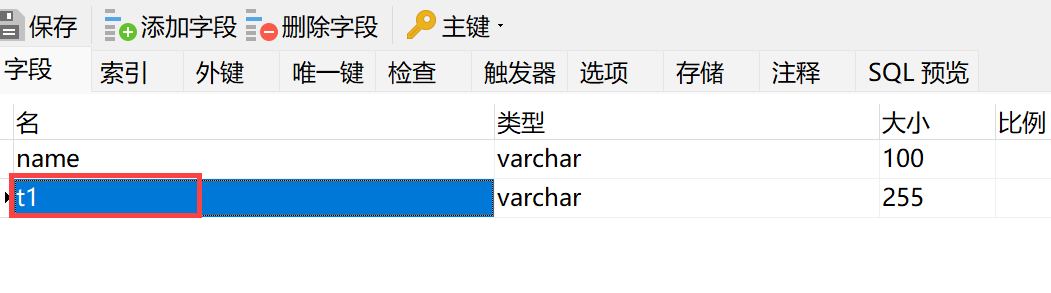
4)给源表新建一个 Capture Instance
使用命令:
EXEC sys.sp_cdc_enable_table
@source_schema = N'Schema',
@source_name = N'Table',
@role_name = NULL, -- 如果要限制读取角色,可能需要设置
@capture_instance = N'Schema_Table_newname'; -- 给一个新的名字5)恢复源表写入。
6)启动管道任务。
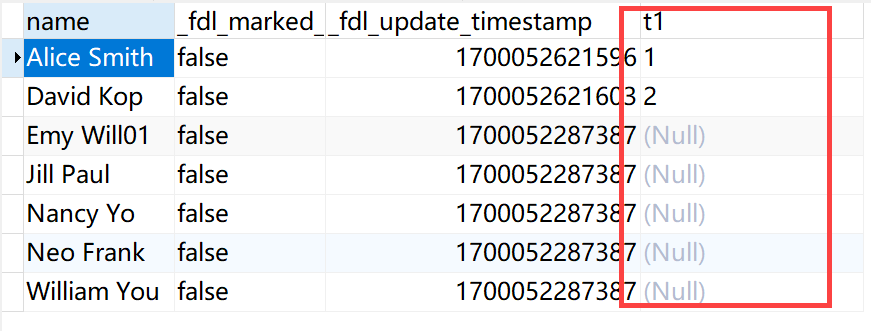
7)等待 FineDataLink 检测到新的 Capture Instance 创建后,自动切换到新的 Capture Instance
即可看到目标表中已经同步新增的字段,如下图所示:
8)可以手动删除旧的 Capture Instance。
注:如果没有按照正确顺序操作,可能造成部分有新字段的数据流入了旧的 CDC 实例,那么这部分新字段的数据就丢失了。