

1. 概述编辑
1.1 版本说明
| FineDataLink 版本 |
|---|
| 4.0.4 |
1.2 应用场景
企业在在构建数仓和中间库时,由于业务数据量级较大,如果使用数据同步批量定时同步数据很难做到高性能的增量同步,若使用清空目标表再写入数据的方式时,还会面临目标表一段时间不可用、耗时长等问题。希望能在数据库数据量大或表结构规范的情况下,实现高性能地数据增量同步。
1.3 功能说明
FineDataLink 支持对数据源组成同步链路进行单表、多表或整库数据的实时增量同步,可以根据数据源适配情况,配置实时同步任务。
本文介绍如何实现单表、多表、整库实时同步
1.4 使用限制
当前仅支持 MYSQL 5.6及以上的非只读数据库。
全量+增量同步:先对所有存量数据完成同步,随后持续同步新增的变化数据(增/删/改)。
提供数据实时同步的基础功能,支持MySQL Binlog,使有MySQL实时同步需求的客户可以完成功能的基础使用闭环(依赖数据管道任务管理功能);
2)支持变化数据同步(DML);
3)允许存在脏数据,并提供阈值提醒功能(在任务运行监控里提供导出),使实时数据同步具有容错性;
4)结构清晰,操作和配置简单易用,所有用户均能快速上手。
2. 前提条件编辑
由实时同步对 MySQL 数据库的读取方式为 Binlog ,因此需要提前对数据库开启 Binlog,示例如下图:

已完成数据源配置。需要在使用数据管道进行实时同步任务配置前,配置好需要同步的源端和目标端数据库,以便在同步任务配置过程中,通过选择数据源名称来控制同步任务,详情参见:配置数据连接
3. 操作步骤
示例将 test_1 数据库中的 S订单数据表实时同步至 test_2 数据库中。
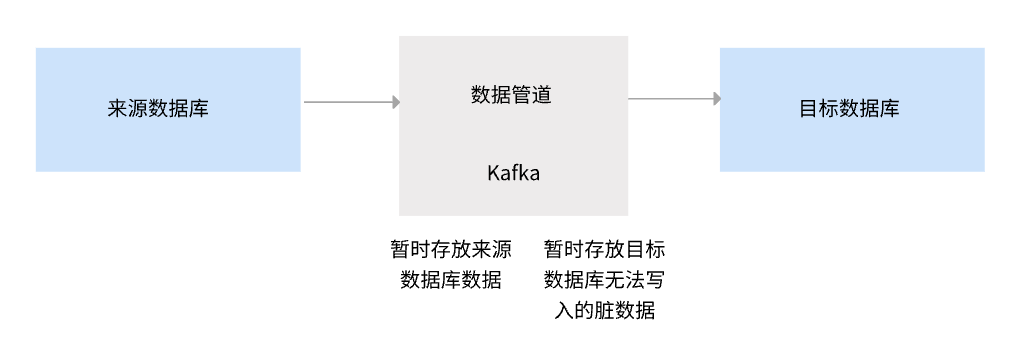
3.1 配置传输队列
配置传输队列,其实就是配置暂存来源库数据,方便目标库写入数据的「数据管道」,目前是通过 Kafka 实现的。
详情参见:配置传输队列
3.2 选择数据来源
首先选择需要数据同步的来源数据。
点击「数据管道>新建任务」,进入任务设置界面,选择来源数据库以及需要进行数据同步的数据表,当然也可以选择多个数据库下的数据表,默认读取方式为 Binlog,默认先对所有存量数据同步,然后持续同步新增变化,如下图所示:
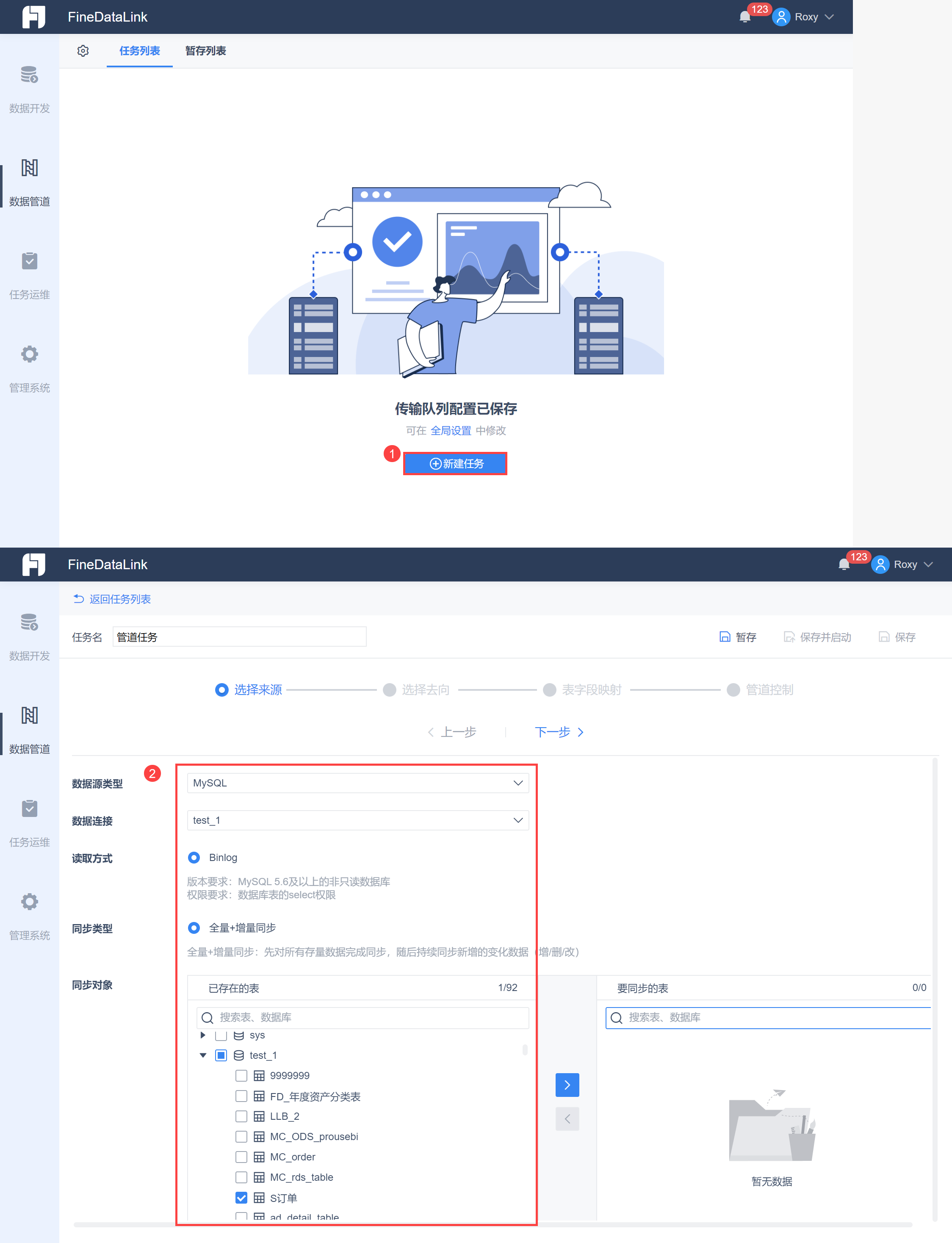
注1:单个任务限制最多选取 5000 张表,达到限制时不允许新增选择。
注2:读取对象只支持选择数据库表,不支持选择视图。
注3:当前只支持数据变化(DML)同步,不考虑支持结构变化(DDL)同步。
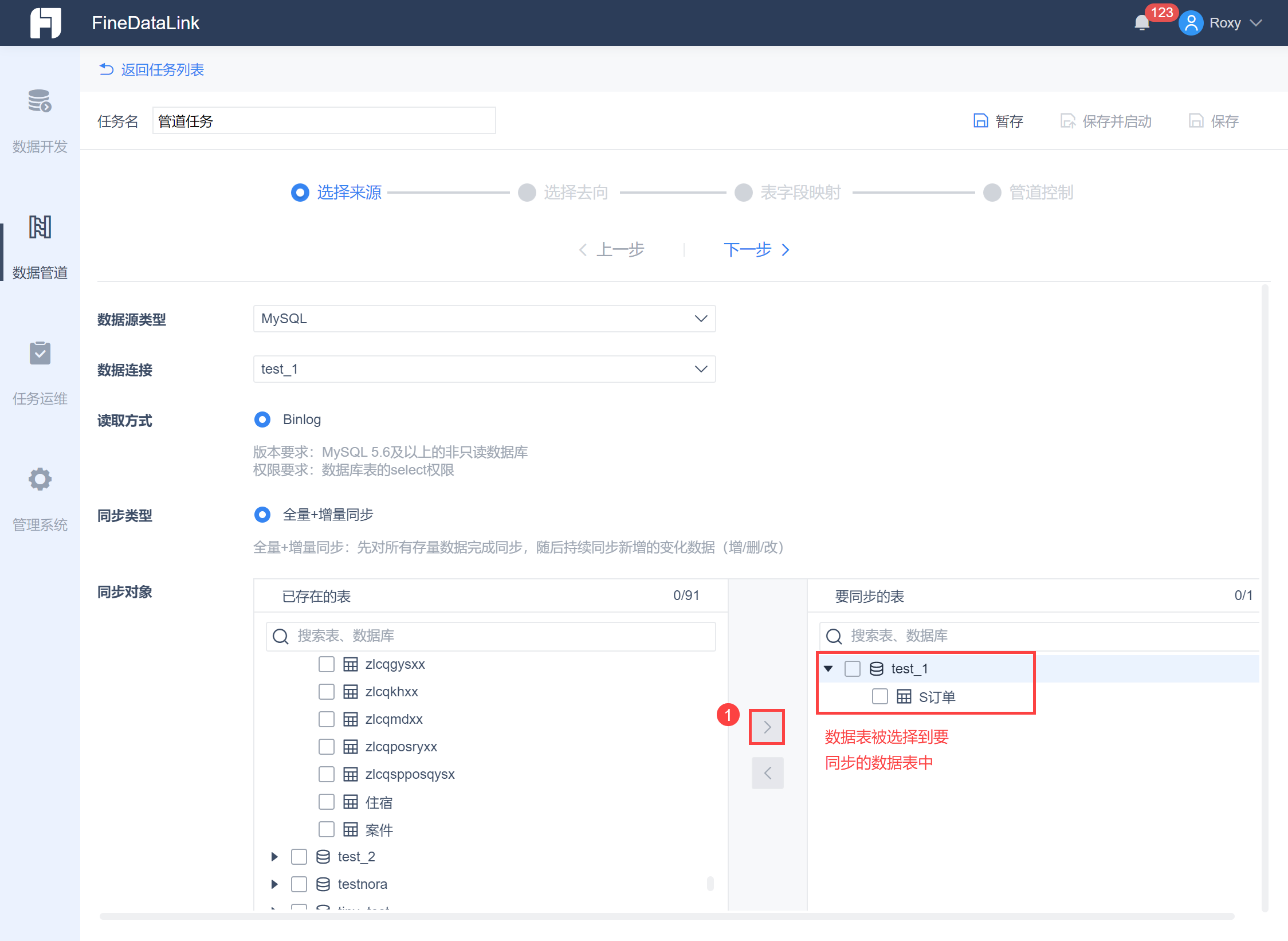
将已经存在的「S订单」数据表选到「要同步的表」中,如下图所示:
3.3 选择数据去向
然后选定需要同步至的目标数据库位置。
点击下一步进入「选择去向」界面,选定目标数据库,如下图所示:
若目标数据表数据结构和来源表一致:首次数据同步会清空目标数据表数据,然后全量同步数据,此后增量同步。
若目标数据库没有和来源表一样的数据标,则直接在目标数据库新建数据表。

注:当前版本不支持DDL同步,若目标数据表数据结构和来源表不一致,写入目标数据库中的策略如下所示:
来源端发生的表结构变化 | 目标数据库同步数据策略 |
|---|---|
| 表字段删除 | 删除字段的动作不会同步,目的地该字段传空值 |
| 表新增字段 | 新增字段的动作不会同步 |
| 删除正在同步的表 | 记录一条错误,继续同步其他表 |
| 表字段改名 | 识别为表字段删除,同表字段删除的逻辑 |
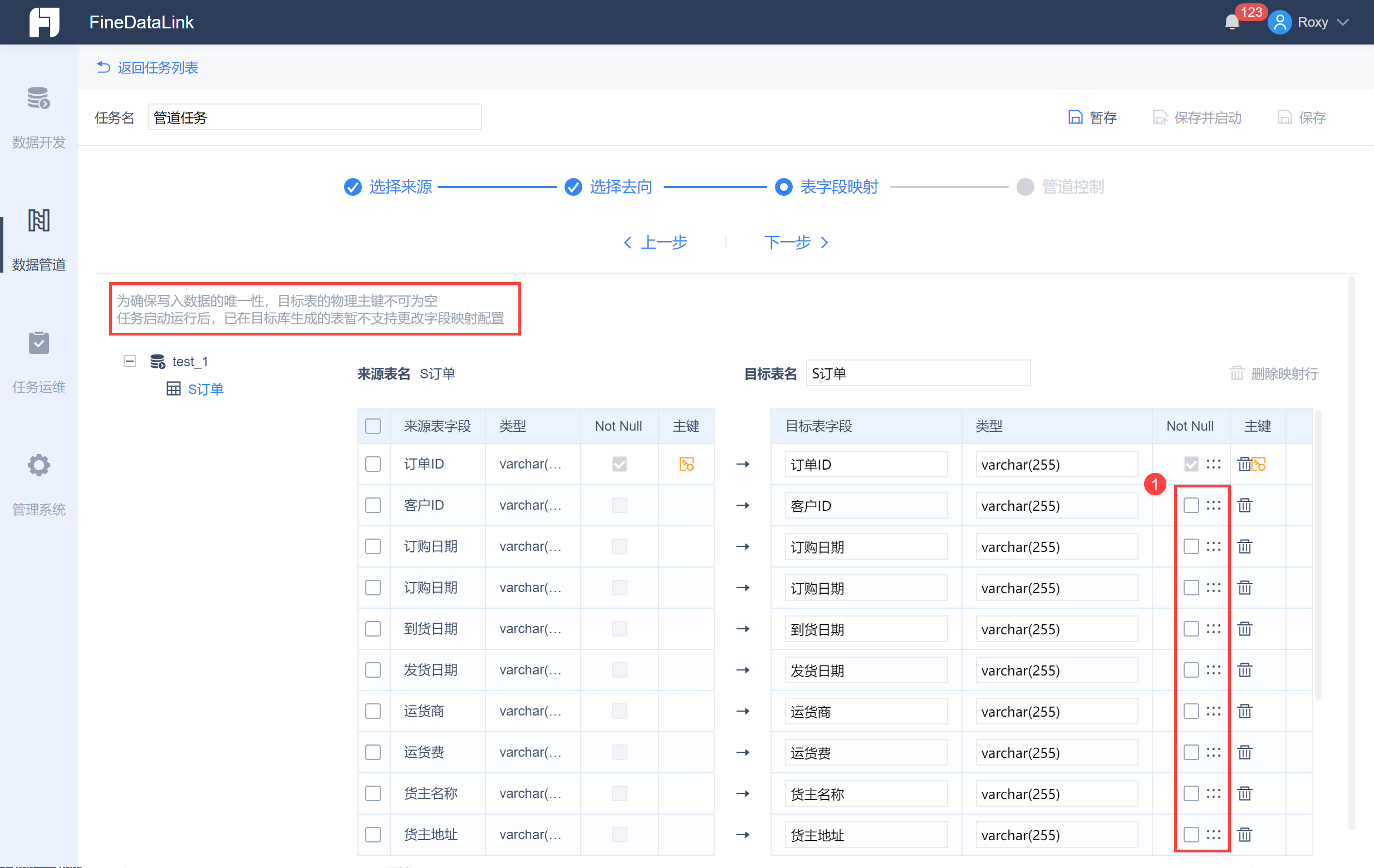
3.4 设置表字段映射
点击下一步进入字段映射设置界面。
同时可以调整目标数据库数据表的字段类型和字段顺序,并选择数据是否可以为空,如下图所示:
3.5 设置管道控制
点击下一步进行数据管道的任务设置。
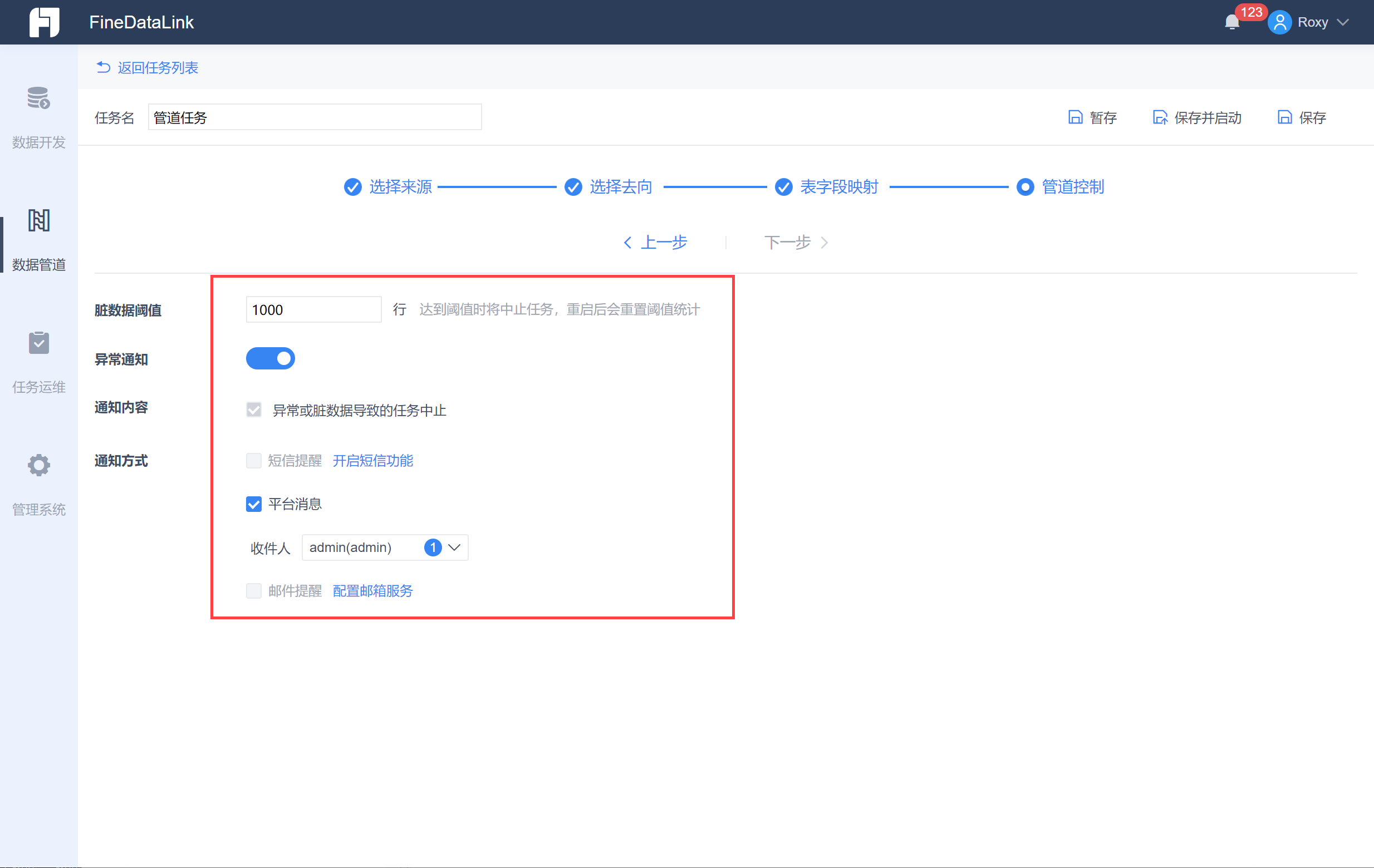
数据同步允许一定的容错,比如字段类型、长度不匹配、主键冲突等等问题,可以设置产生的脏数据上限,达到上限则自动终止管道任务。
注:限制最多10w行,且重启任务后,会重置阈值统计。
同时设置当任务异常时的通知,如下图所示:
3.6 保存任务
点击「保存」,即可保存任务,如下图所示:

暂存:每一步都可「暂存」,「暂存」的配置只有正式「保存」后方可生效,所有状态的任务都可编辑并「暂存」。
保存:只有在任务编辑的最后一步才可「保存」,「保存」即将修改写入正式的配置,要求仅未运行的任务可「保存」,「运行中」的任务需要暂停方可保存,保存不改变任务的状态。
此时在「任务列表」中即可看到设置完成的管道任务,如下图所示:
3.7 执行任务
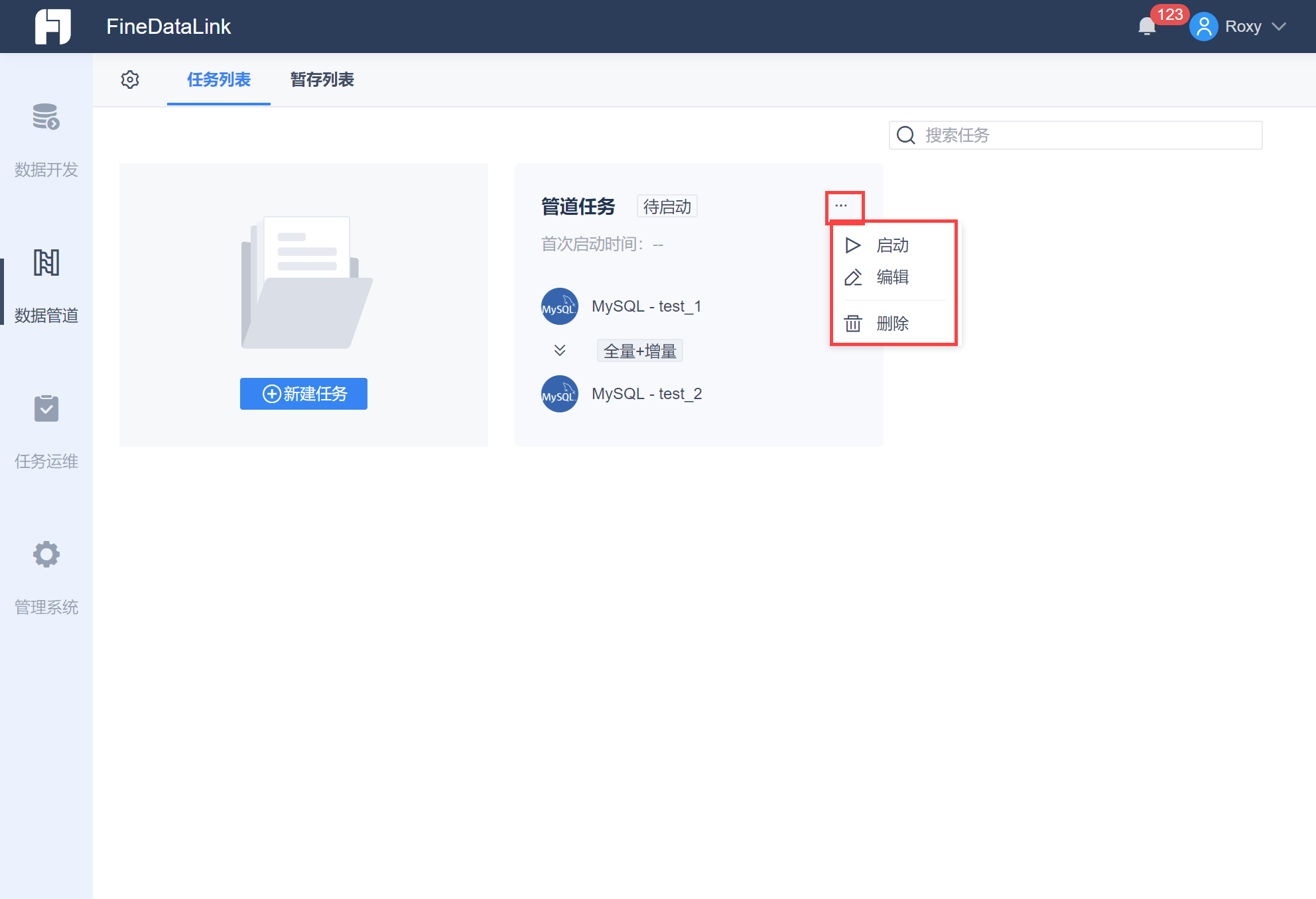
在任务列表界面,可以启动管道任务或者进入编辑界面进行任务修改设置,如下图所示:
此时启动任务,进入管道任务中,即可看到任务执行情况,如下图所示:
