

数据转换编辑
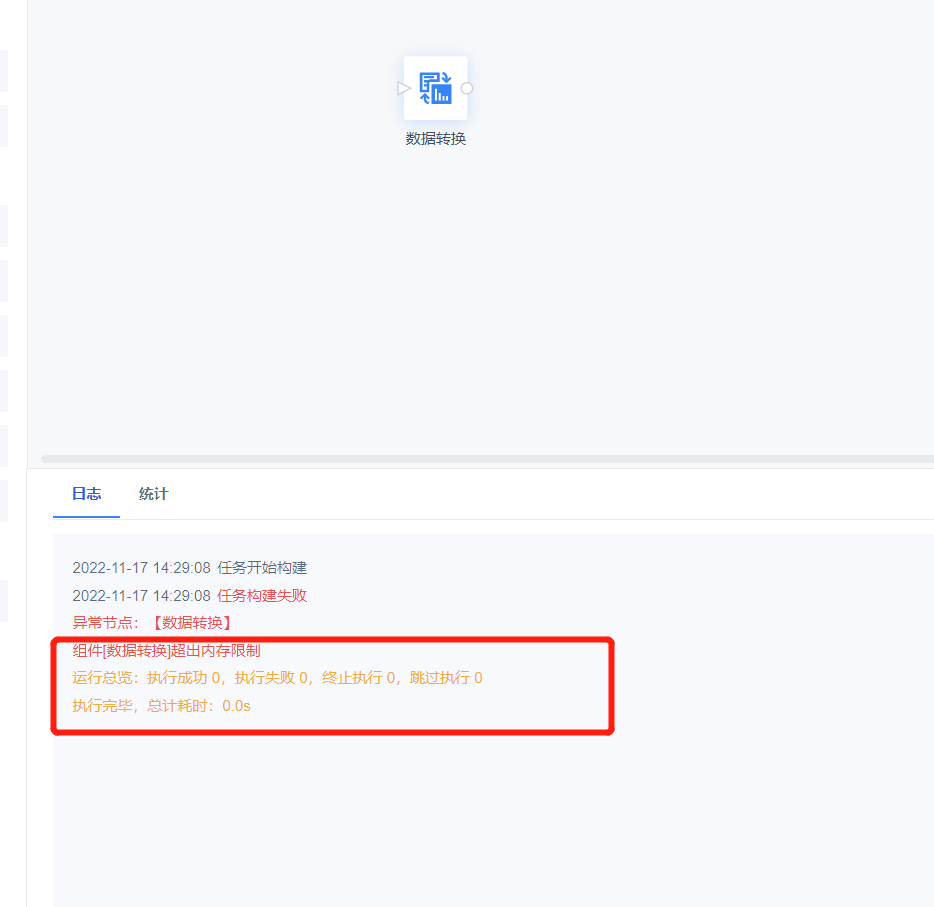
运行日志报错:超出内存限制
| 点击展开更多 |
问题描述: 任务运行失败,报错超出内存限制。
原因分析: 数据开发所占用的内存资源超过工程设置的上限。 解决方案: 可以根据实际运行任务情况,参考 机器要求 适当调整 Tomcat的JVM内存和负载分配 |
API 输入编辑
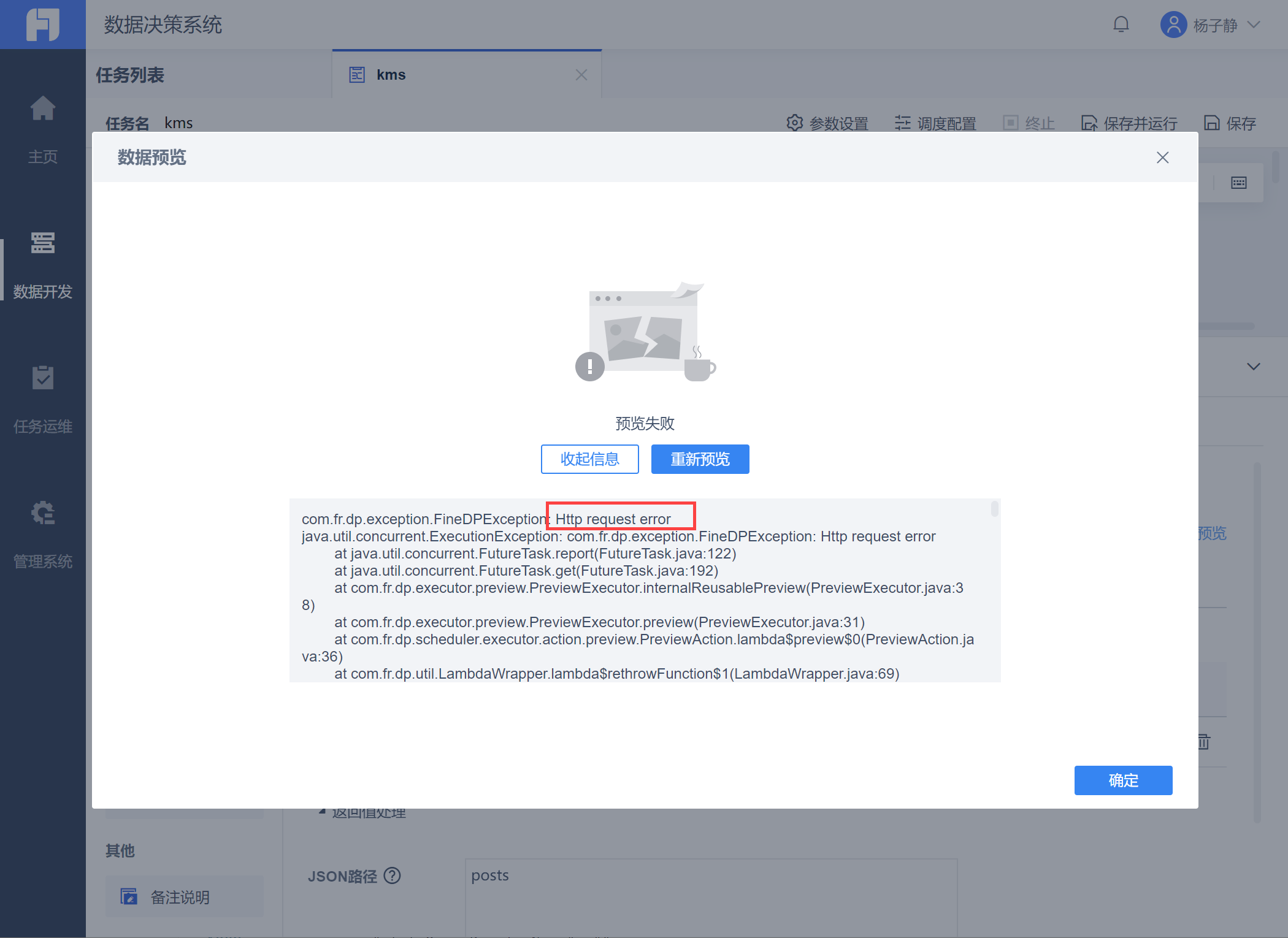
API取数数据预览报错:Http request error- Read timed out
| 点击展开更多 |
问题描述: 使用API取数,点击「数据预览」报错 Http request error,如下图所示:
原因分析: FineDataLink 默认超时是10s,耗时长的api会提示超时。 解决方案: 参考 FDLTimeout 在API Header 内使用 FDLTimeout 字段设置超时时间。 |
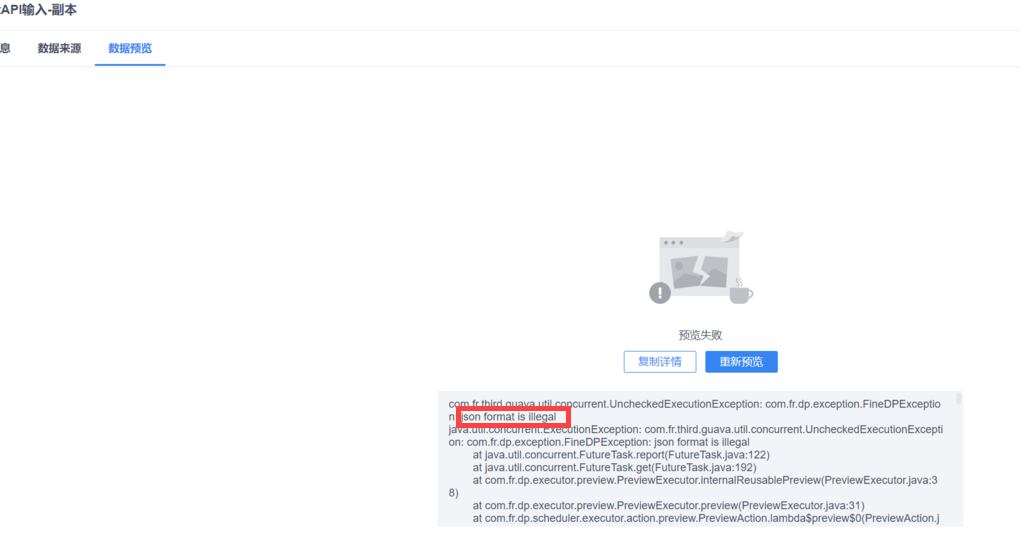
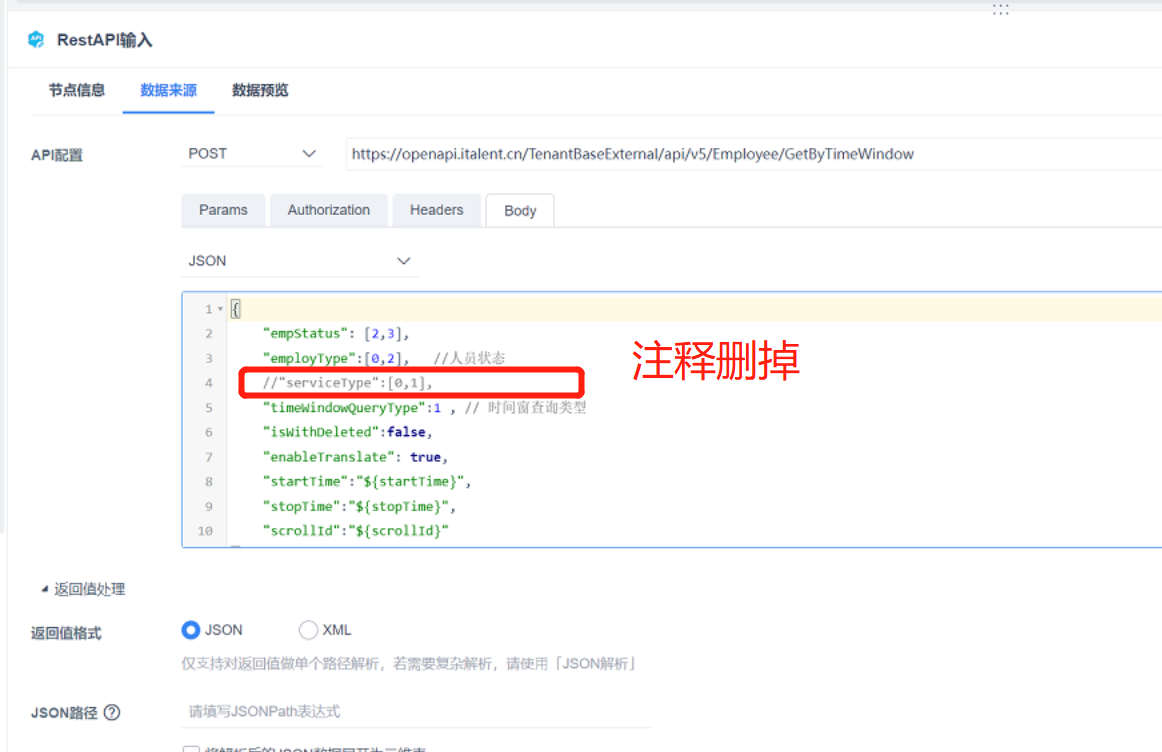
API 输入运行报错 json format is illegal
| 点击展开更多 |
问题描述: 使用API取数,点击「数据预览」报错 json format is illegal,如下图所示:
原因分析: 4.0.20 版本中加了json格式校验,API 的 body 请求中不再支持写入注释。 解决方案: 清除 body 中的注释即可。 4.0.21 已经支持使用使用注释,可升级工程解决。
|
数据关联编辑
运行日志报错:Spark执行错误
| 点击展开更多 |
问题描述: 任务运行失败,报错提示[数据关联]: Spark执行错误- org apache spark sql. execution joins .exception.N2NInterruptException - null
原因分析: spark 保护机制,避免数据量极速膨胀触发服务器宕机,通常在关联结果膨胀超过5倍 + 关联数据量大于 1kw出现,属于正常现象。 满足下面所有条件,判定为不合理场景: 1)存在N:N的情况 2)N:N步骤的结果数据量超过1kw 3)N:N膨胀系数>=5 例如,100w 数据和 500w 数据N:N结果为2000w数据,那么N:N膨胀系数为: 2000w/500w =4,或者2000w/100w =20 |

DB表输出编辑
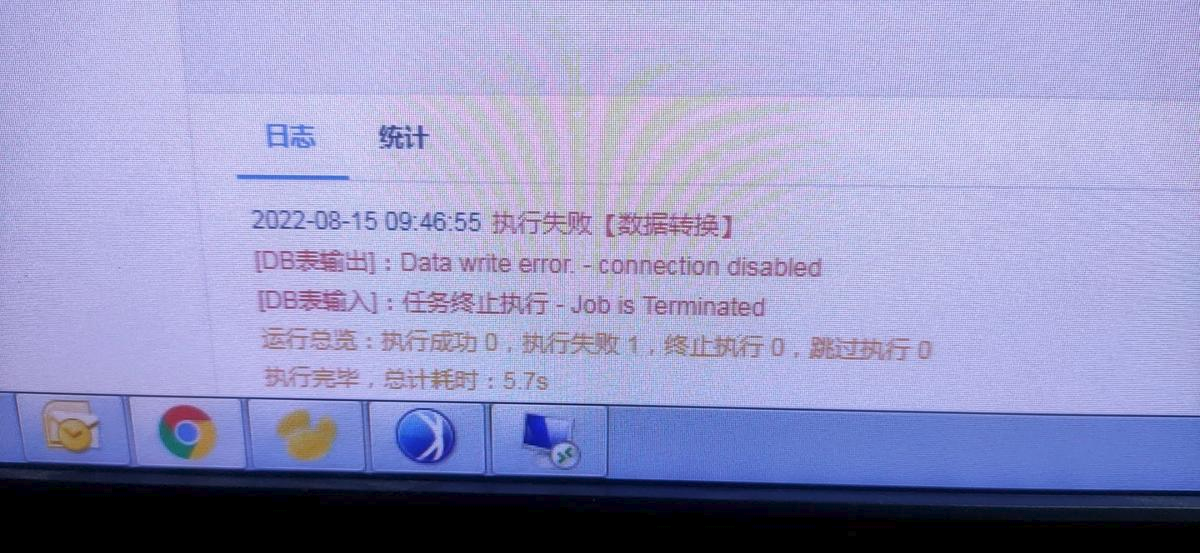
运行日志报错:Data write error - connection disables
| 点击展开更多 |
问题描述: 输出数据库为GreenPlum(并行装载)时,运行报错Data write error - connection disables
原因分析: gpdfist 文件不支持放置路径有空格 解决方案: 放置文件的路径下有空格,换个文件夹放置,并重启gpfdist进程,配置并行装载方案详情参见:配置Greenplum(并行装载)数据源 |
任务执行成功但写入数据不全
| 点击展开更多 |
问题描述: 用户将两个来源的数据通过「Spark SQL」算子 union 后写入到目标表,写入方式为「清空数据再写入」,发现写入的数据不全,只写入了一张表的数据。
原因分析: 数据写不全原因:目标表存在唯一索引(自增 ID 主键),写数时索引冲突。 任务执行成功原因:FineDataLink 写入方式选择「清空数据再写入」时,遇到冲突会默认跳过。 |

简道云输入编辑
运行日志报错:try request out of limit. DB表输出:Runtime internal error. -null
| 点击展开更多 |
问题描述:
解决方案: 在 配置简道云数据源 中将简道云数据连接请求失败重试次数调整的略大一些,默认值为5.
|

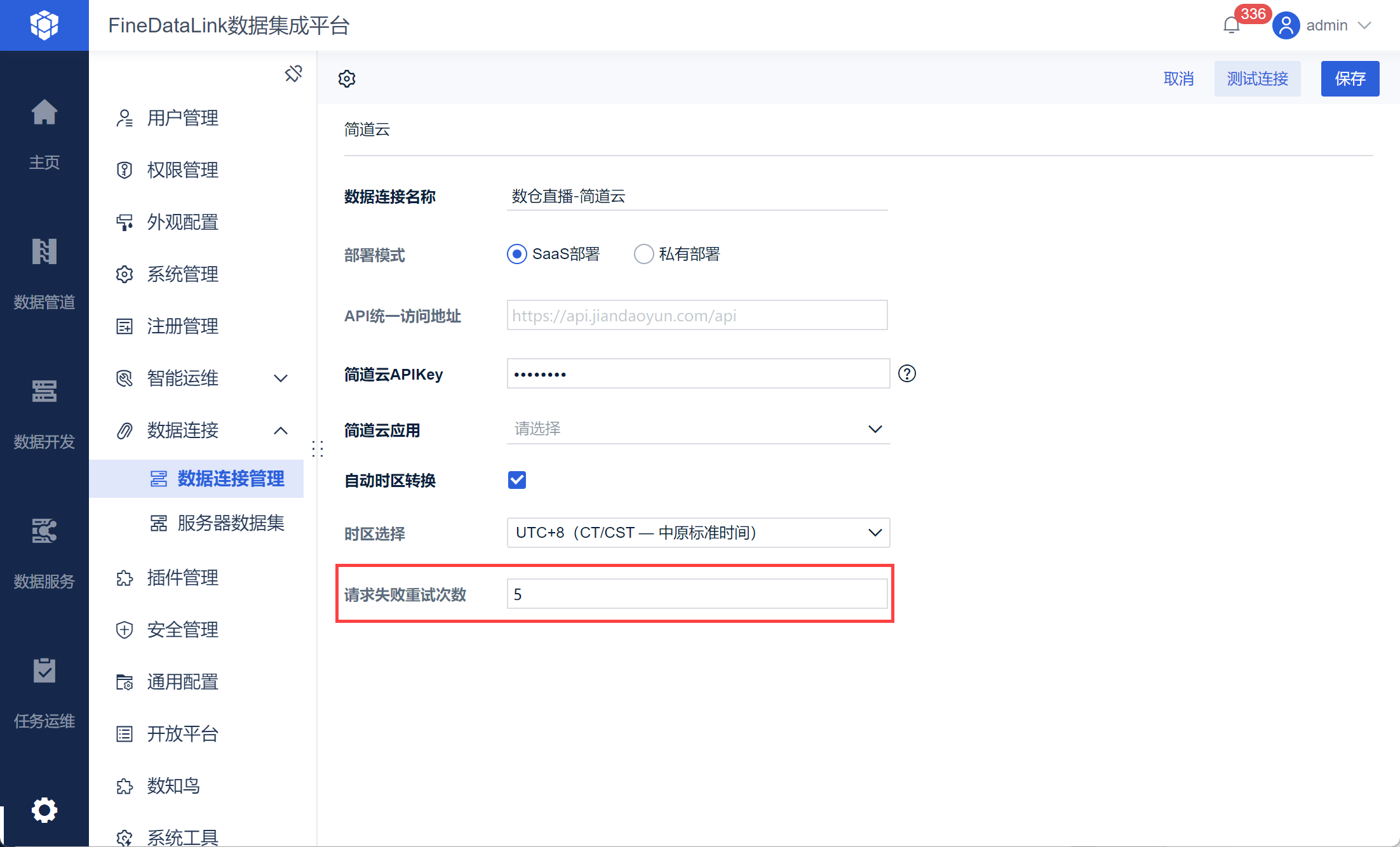
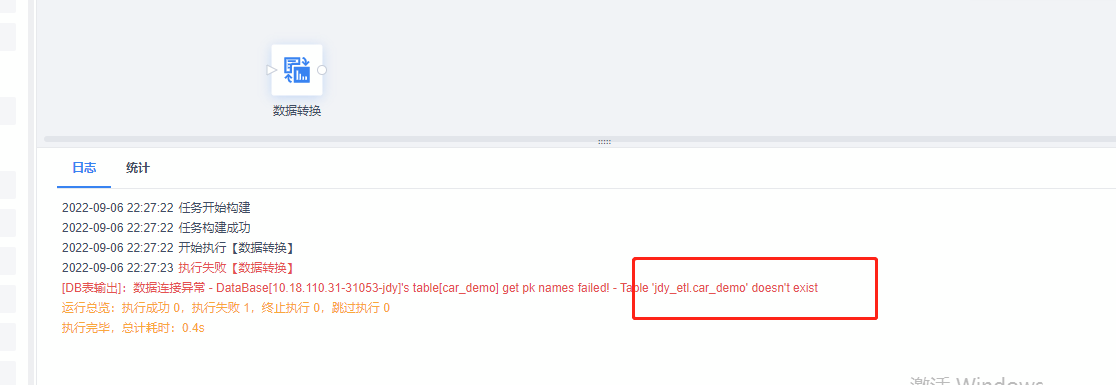
运行日志报错Table doesn't exist
| 点击展开更多 |
问题描述:
原因分析: 简道云字段过长,字段类型不匹配 解决方案: 通过字段设置修改对应字段的长度 |
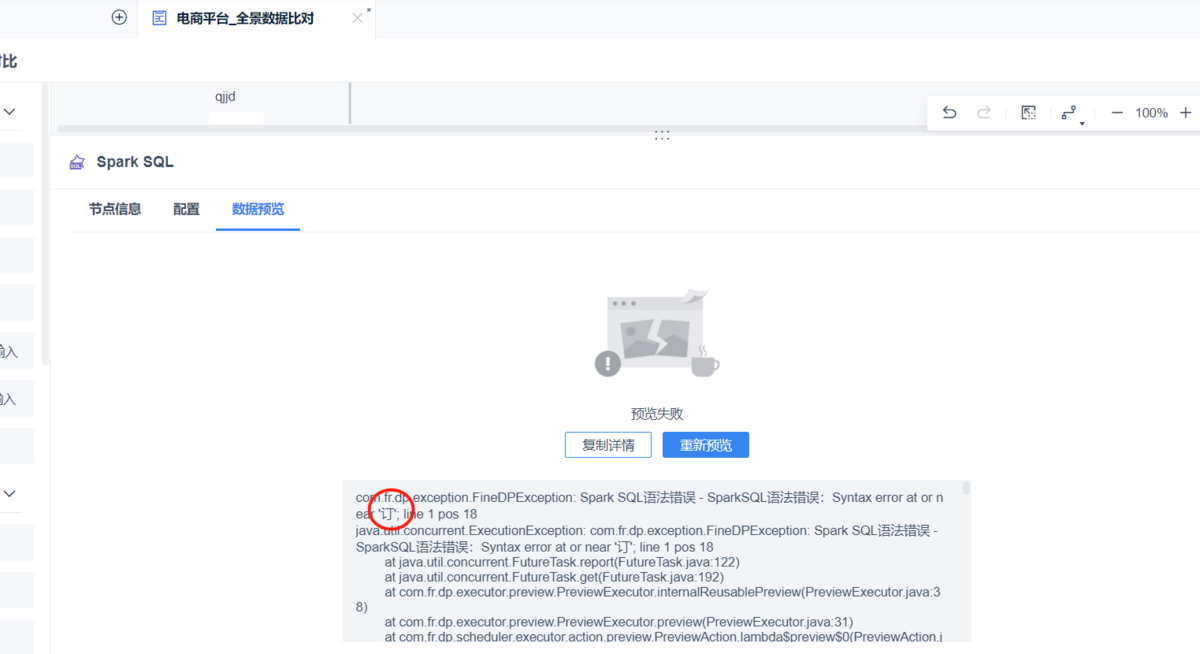
SparkSQL 编辑
数据预览报错:SparkSQL语法错误: Syntax error at or near 订; line 1 pos 18
| 点击展开更多 |
问题描述: 数据预览界面报错SparkSQL语法错误: Syntax error at or near 订; line 1 pos 18
原因分析: SparkSQL 不支持中文字段 解决方案: 在语法中去掉中文。 |
sparksql 使用count 计数只显示5000条
| 点击展开更多 |
问题描述: sparksql 算子中,使用 count 计数后预览只显示 5000 条。 原因分析: sparksql 算子中,预览采样 5000 条进行计算,避免数据量过大导致服务器压力大,实际运行会根据实际条数来 |
SAP RFC 输入编辑
运行日志报错:The current pool size limit is 10 connections.
| 点击展开更多 |
问题描述: 使用FineDataLink从SAP抽取数据,超过10个任务后面的任务报错:The current pool size limit is 10 connections. 原因分析: 这是SAP服务器配置了最大连接限制 解决方案: 请参考SAP相关配置说明,修改最大连接限制:配置 SAP 服务器的最大连接限制 |
执行速度过慢,且超时报错
| 点击展开更多 |
问题描述: SAP RFC 取数很慢,当取数超过 1 小时,定时任务会直接中断。 原因分析: SAP RFC 函数数据量大,执行逻辑比较复杂,导致执行时间久,超时报错 解决方案: 优先通过优化 RFC 本身的性能,或者通过直连底层库解决:
|
MongoDB 输入编辑
节点运行报错null
| 点击展开更多 |
问题描述: FDL4.1.0及之前的版本,如果mongdb输入选择条件过滤查询方式,配置之后,再选择其他查询方式保存,升级到4.1.1-4.1.6.4任意版本,会出现节点运行报错null 解决方案: 手动修改dp文件,将mongodb输入节点的filter值置为null 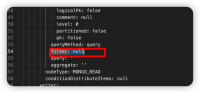 |
新增计算列编辑
报错:该操作符两端必须为数值类型
问题描述:
「新增计算列」算子中,公式中包含内置参数 loopTimes,预览正常。

执行时报错:Spark算子计算错误 - formula check error - 字段[b]的公式校验失败:[:该操作符两端必须为数值类型
原因分析:
目前所有的内置参数都当作文本格式处理。
解决方案:
使用 TOINTEGER 公式转换字段类型。
文件输入编辑
通过文件修改时间筛选文件,筛选结果不对
问题描述:
「文件输入」算子中,通过文件修改时间筛选文件,筛选 2023-05-22 11:48:30 之前的文件,最终 2023-05-22 11:48:59 的文件被筛选出来。
原因分析:
「文件修改时间」的精确度仅到分钟,暂时无法精确到秒级别。