1. 概述编辑
1.1 版本
| FineDataLink 版本 | 功能变动 |
|---|---|
| 4.1.11.4 | - |
1.2 应用场景
用户需要实时读取 kafka 中的数据,将数据解析后,写入指定数据库中,并使用数据进行报表和实时大屏制作和展示。
1.3 功能简介
FineDataLink 「实时任务」支持使用 Kafka 输入算子进行实时读取数据。
2. 功能说明编辑
| 配置项 | 说明 |
|---|---|
| 数据连接 | 配置Kafka数据源之后即可选择对应数据连接 |
| Topic | 选择读取 kafka 中的topic 支持手动填入topic |
| 同步类型 |
1)选择「指定时间」,通过日期时间控件选择时间点。 2)任务启动时间:初次启动任务时,同步启动时间开始的增量数据,再次启动任务时,从上次执行结束的断点继续同步。 3)自定义时间:初次启动任务时,从指定的时间戳开始同步数据,再次启动任务时,从上次执行结束的断点继续同步。 4)如果断点状态丢失,则按照初次启动逻辑同步数据。 |
| 输出字段 | 配置读取 kafka 消息中哪些信息传输给下游算子
根据选择的数据内容,生成二维表 |
3. 操作步骤编辑
例如用户实时读取 kafka 中的数据,解析后进行入库。
3.1 设置 kafka 输入
进入 FineDataLink 数据平台后,选择「数据开发>实时任务」,新建实时任务,如下图所示:
在任务管理界面选择「编辑」,如下图所示:
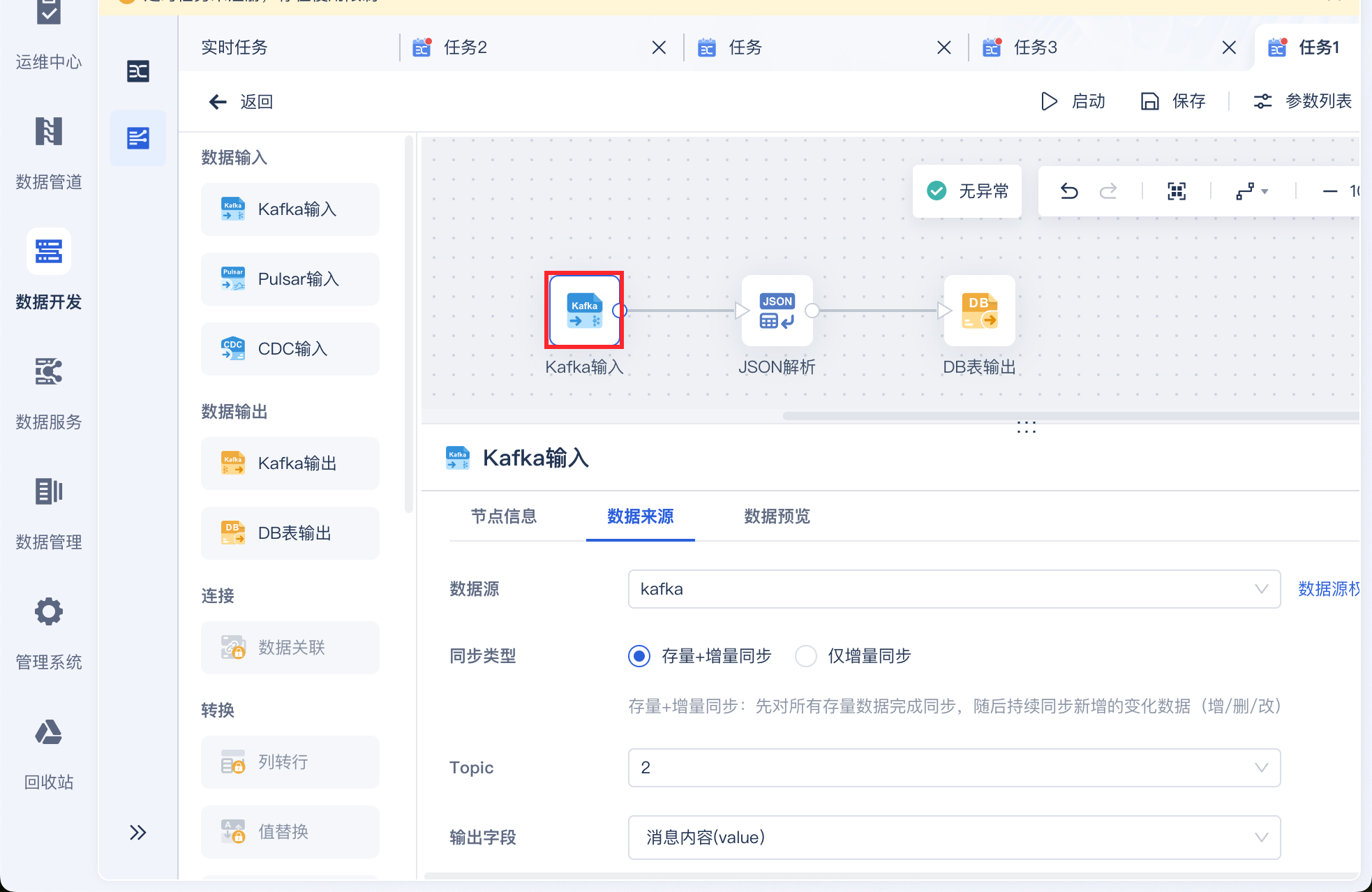
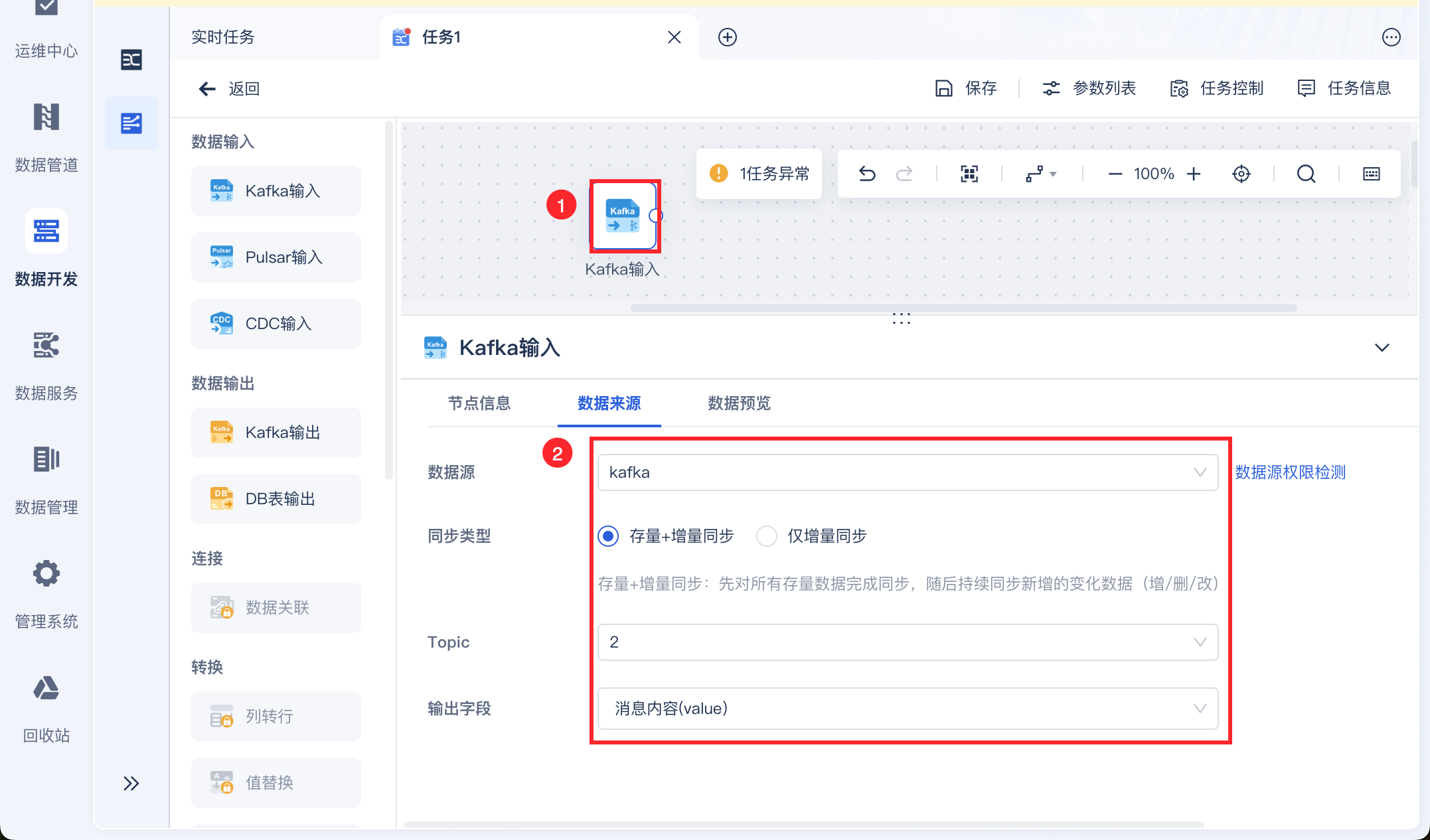
进入编辑界面后,拖入 Kafka 输入算子,选择数据源并设置同步类型,输入 Topic 并设置输出字段,如下图所示:
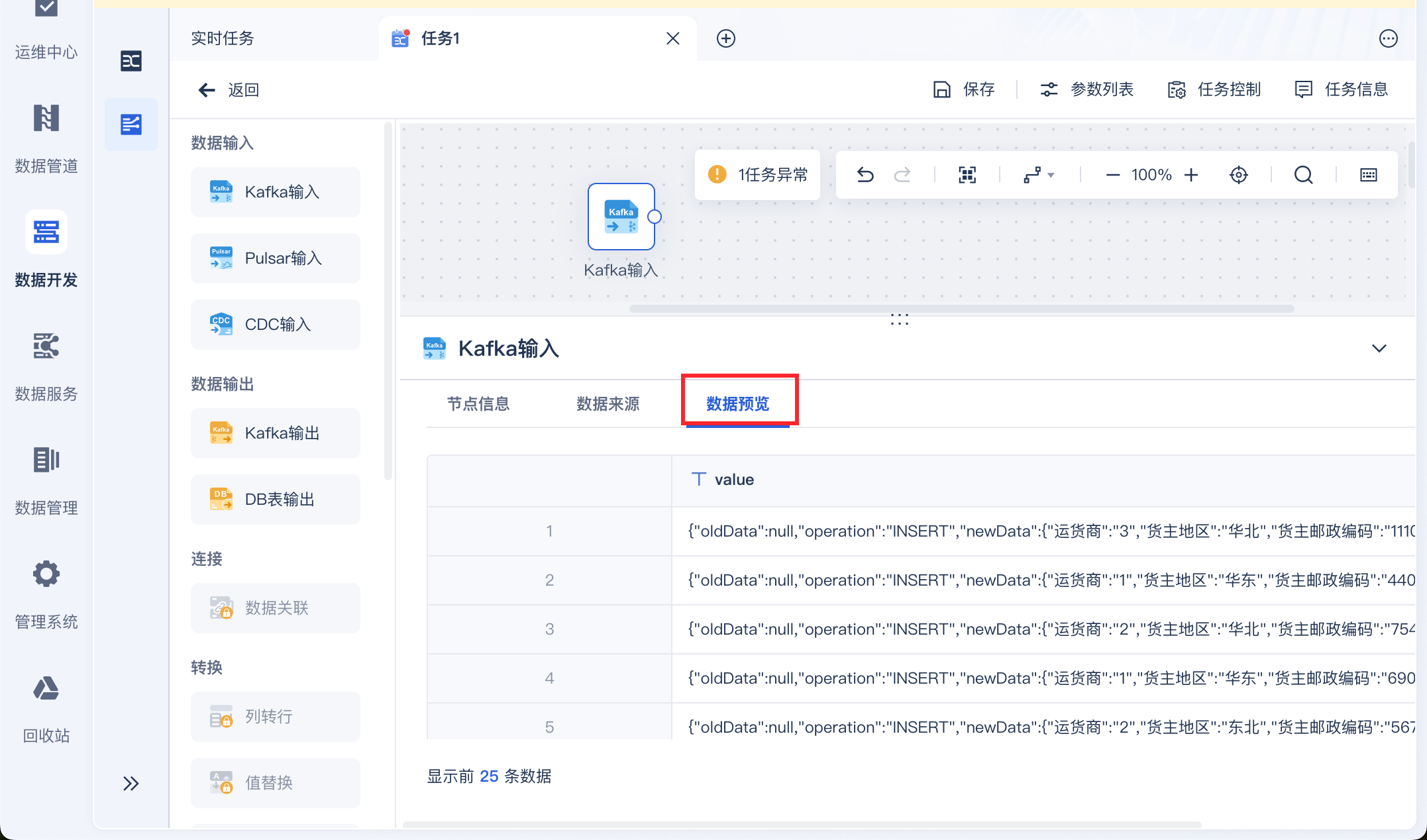
点击「数据预览」即可看到取出的 Kafka 数据,如下图所示:
3.2 解析数据
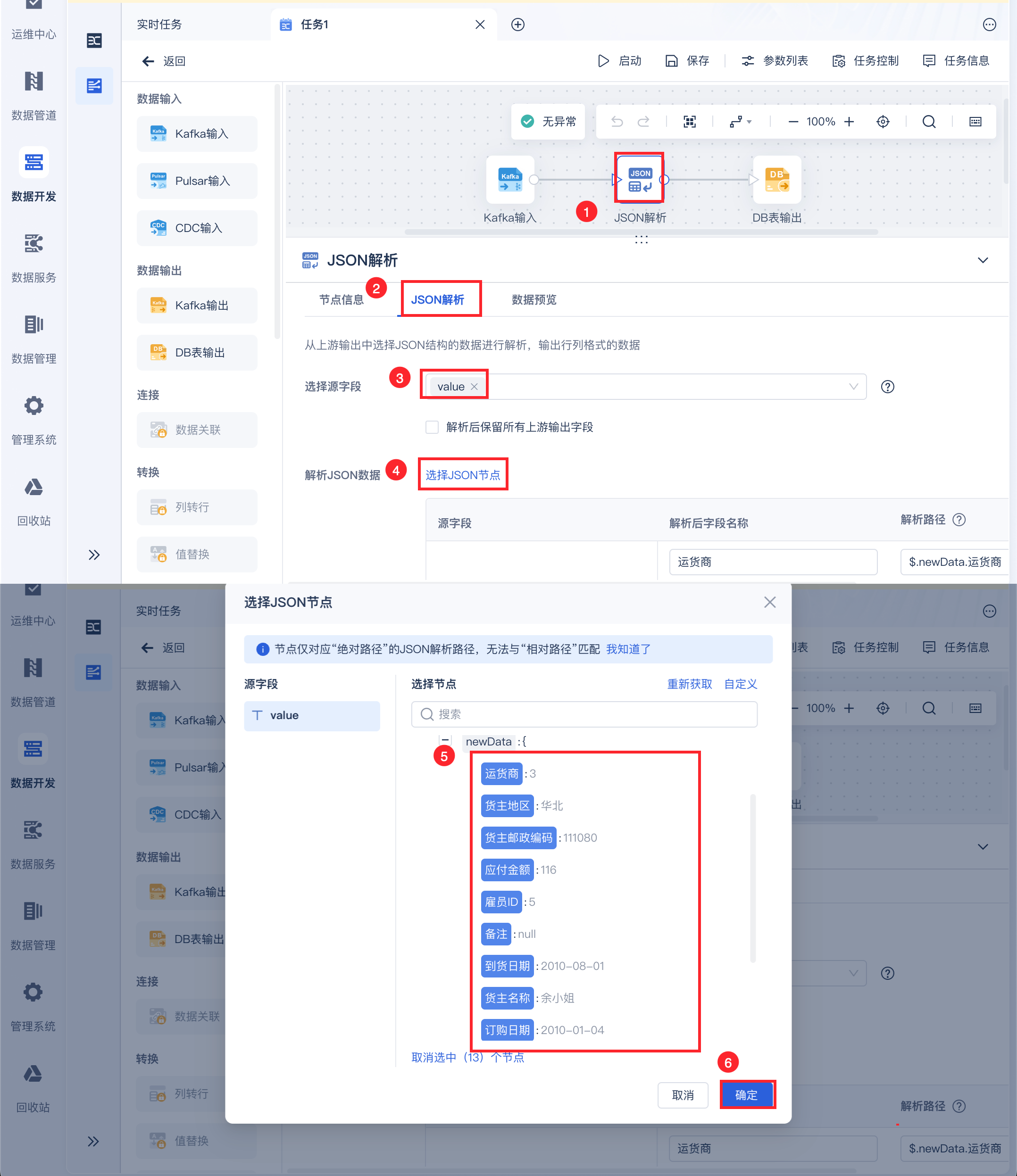
使用「JSON解析」将需要解析的 value 值解析成二维表字段,如下图所示:
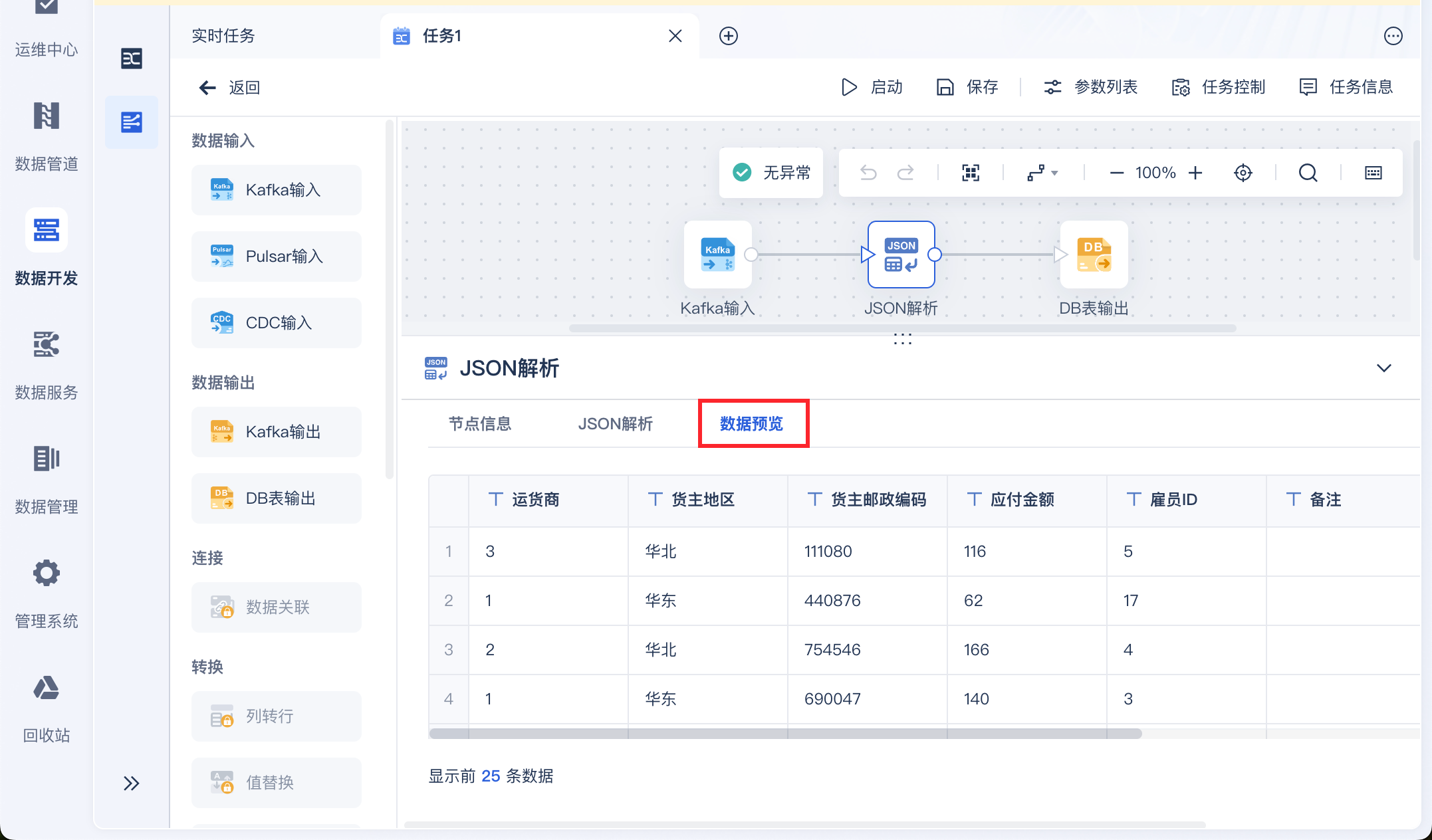
预览数据,即可看到被解析为二维表的数据,如下图所示:
3.3 数据输出
设置数据实时计算后输出至指定的数据库中,如下图所示:
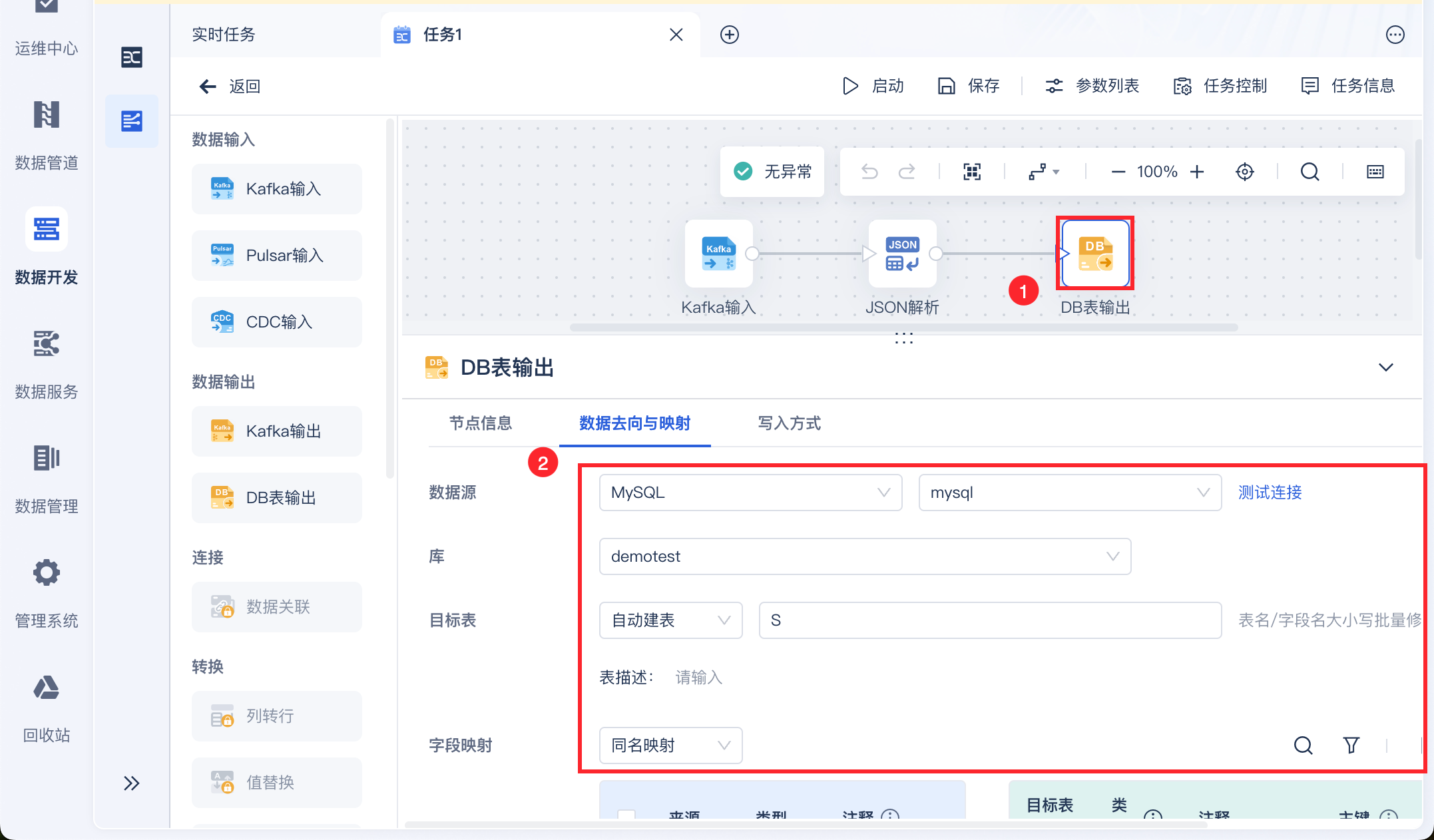
DB表输出设置详情参见:DB表输出(实时任务)
3.4 任务启动和管理
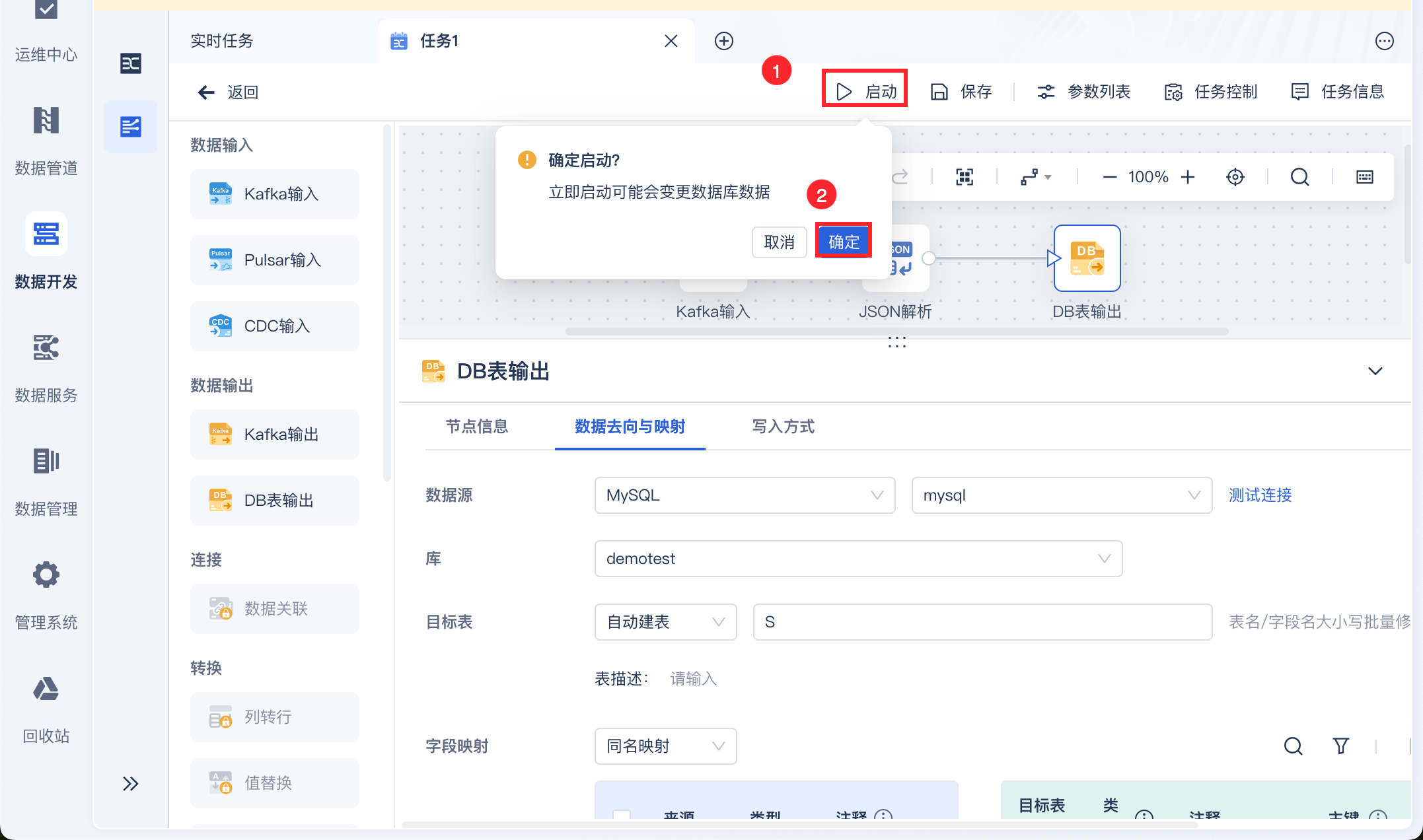
点击启动,即可启动实时任务,如下图所示:
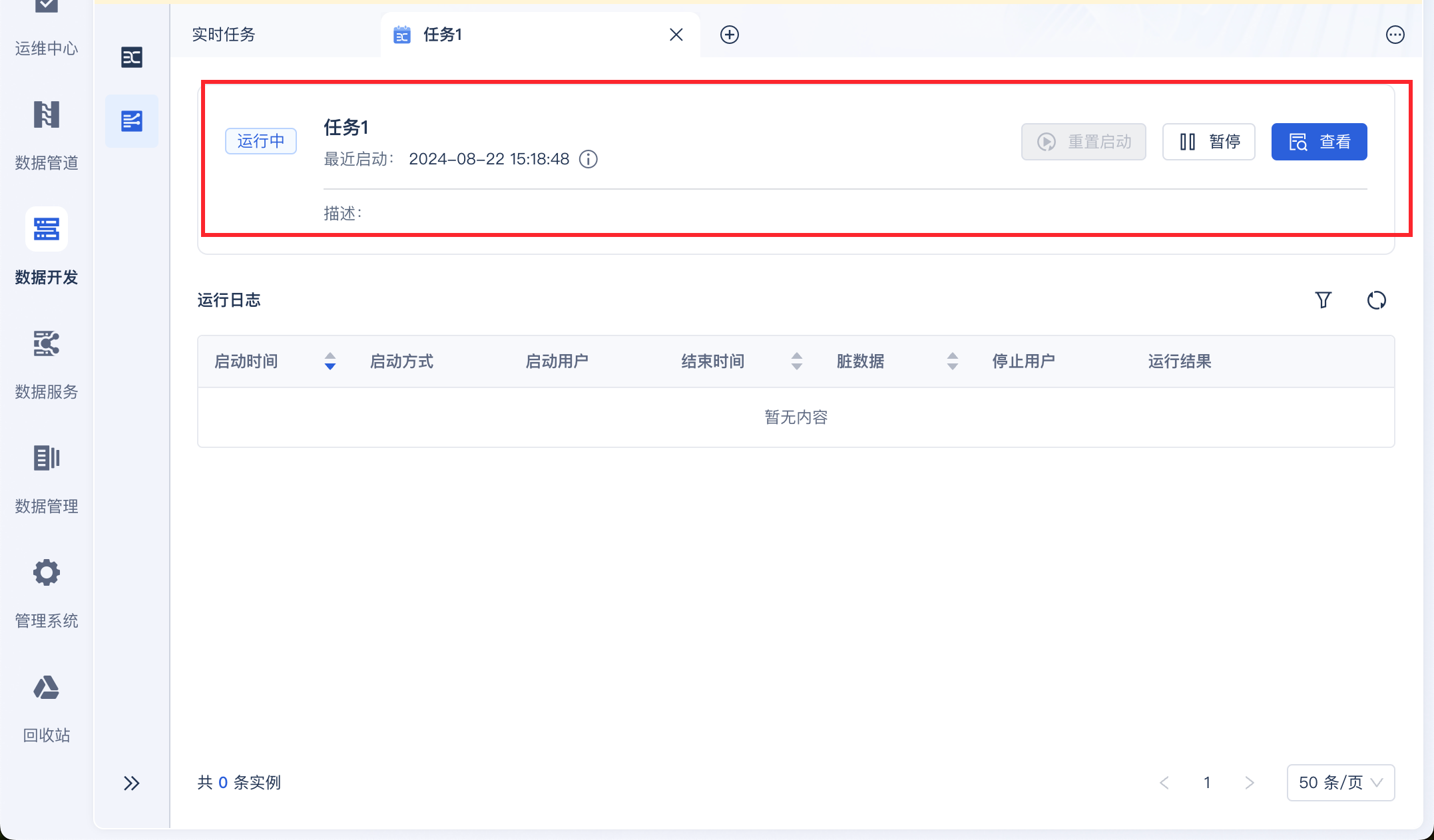
同时在任务管理界面看到任务运行状态,如下图所示:
3.5 效果查看
在日志中即可看到首次同步运行情况,如下图所示:
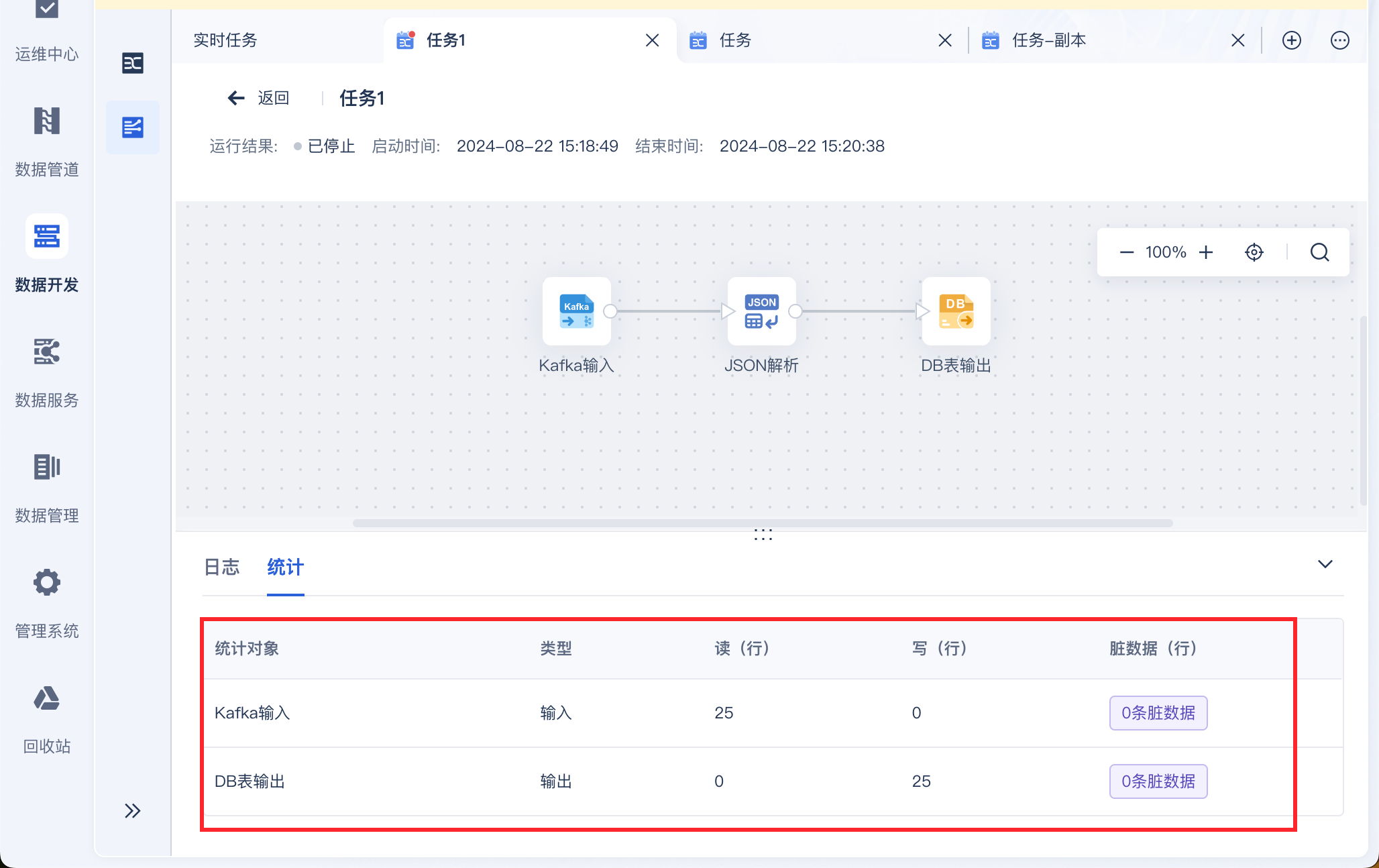
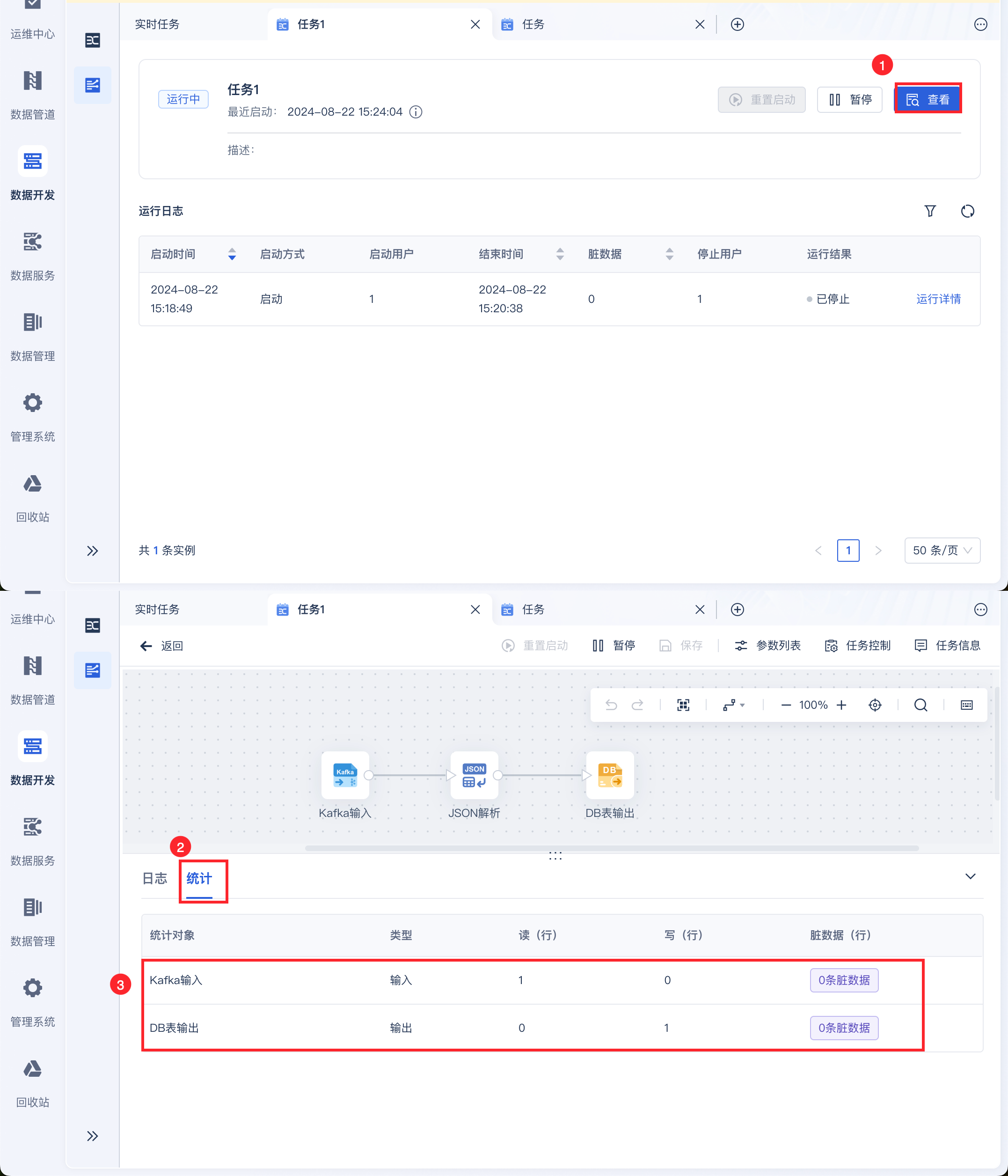
若此时 Kafka 中新增了一条数据,那么点击「查看」,即可看到实时任务的运行情况,同步了一条数据到指定的数据库中,如下图所示: