

通过Sql实现的组内排序(排名)
1. 环境
注意事项:由于9.0设计器内置的是sqlite数据库,在使用上很多语法都不支持,请将sqlite数据库文件迁移到主流数据库(MySql、MSSQL、Oracle…)后运行。
迁移方法:使用第三方软件迁移内置FRDemo数据库到指定数据库
本文运行环境:Microsoft SQL Server 2012 - 11.0.2100.60 (X64)
Copyright (c) Microsoft Corporation
Enterprise Edition (64-bit) on Windows NT 6.1 <X64> (Build 7601: Service Pack 1)
2. 描述
对于一些特殊的数据表(年报,月报),可能只需要对它某一个时间点(某一年或某一个月)的数据进行分析,此时在你的脑海里肯定会闪现一个词--【组内排序】。设置单元格父格,进行分组扩展就能实现。但我们知道,这种方法是浏览器(客户端)获取到数据,通过决策报表处理再展示的,当我们面对的是大数据时,考虑到效率问题,上面的方法是否是最佳选择?有没有更好的选择方案呢?答案是肯定的!
3. 思路
我们可以直接在新建数据集时将其处理成带组内排序字段的结果集,然后将数据交付给浏览器直接展示。大家都知道,数据在服务器端处理肯定比在客户端处理快的多。
4. 示例
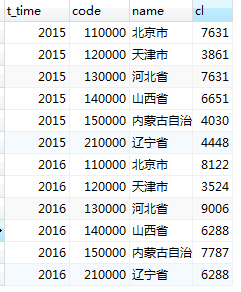 4.2 执行(组内)排名sql
4.2 执行(组内)排名sql
关键点分析:
解释:按t_time分组(示例将t_time分为2005,2006二个组), cl排序(默认:升序)。降序可设置ORDER BY cl desc
函数ROW_NUMBER() OVER () ,RANK() OVER ()RANK(),DENSE_RANK() OVER ()的区别在这就不详细介绍了,可参考:开窗函数-排名

条件的分析函数有:
row_number() over(partition by … order by …)
rank() over(partition by … order by …)
dense_rank() over(partition by … order by …)
count() over(partition by … order by …)
max() over(partition by … order by …)
min() over(partition by … order by …)
sum() over(partition by … order by …)
avg() over(partition by … order by …)
first_value() over(partition by … order by …)
last_value() over(partition by … order by …)
lag() over(partition by … order by …)
lead() over(partition by … order by …)
等等…有兴趣的朋友可以试试,这里就不详解了!
附件列表
文档内容仅供参考,如果你需要获取更多帮助,付费/准付费客户请咨询帆软技术支持
关于技术问题,您还可以前往帆软社区,点击顶部搜索框旁边的提问按钮
若您还有其他非技术类问题,可以联系帆软传说哥(qq:1745114201)