

数据管道是FineTube中的重要模块,旨在提供稳定、高效的数据同步功能。
1、背景编辑
面对各行各业对数据的应用,数据处理会有很多的需求,其中包括能够快速配置大量数据表的原样同步任务,能够满足数据实时同步的时效性要求高的场景。
一句话概括:
用户需要把某一个或多个 [数据源] 的数据迁移到一个或多个 [目标库],此时用户可通过创建 [数据管道] 在系统实现数据迁移的工作。
2、架构概述编辑
将数据源的大量的数据传递给Kafka进行收集,减少源数据库的压力,再将Kafka收集到的数据,发送给目标数据库。
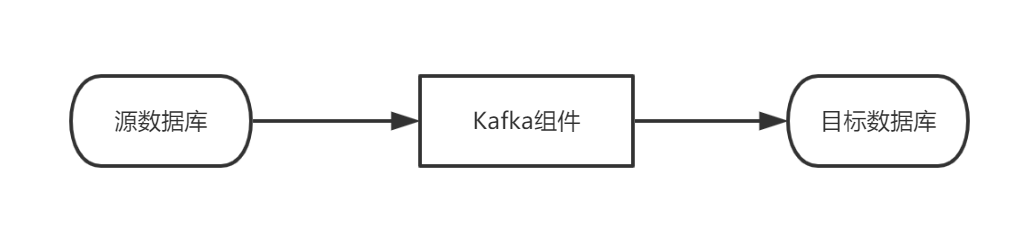
关于Kafka:
在FineTube中,kafka作为专业消息列队处理系统,主要应用于收集数据。
相当于一个临时容器的作用。将传送过来的数据转换为二进制文件保存在服务器硬盘上,这样可以防止程序运行不当造成数据丢失的问题;此外,kafaka作为专业的消息列队处理系统,数据输入输出性能强大,更适合处理大数据量的流数据场景。
3、典型场景编辑
全库数据增量/全量实时同步:需要实时全库同步mysql和oracle数据至FD数据仓库,三个数据源共一千多张表;
4、使用限制编辑
由于数据管道是基于数据库日志进行的数据同步任务,所以数据库类型、版本的日志会有部分差别,目前所支持的版本如下所示:
关于源数据库:
数据库类型 | 备注 |
MySQL |
|
| Oracle |
|
| SQL Server |
|
具体配置等详情参考: 数据源支持范围
关于目标数据库:
| 数据库类型 | 备注 |
| FineData |
|
| GreenPlum |
|
| SQL Server |
|