最新历史版本
:2、任务设置——数据源 返回文档
编辑时间:
内容长度:图片数:目录数:
修改原因:
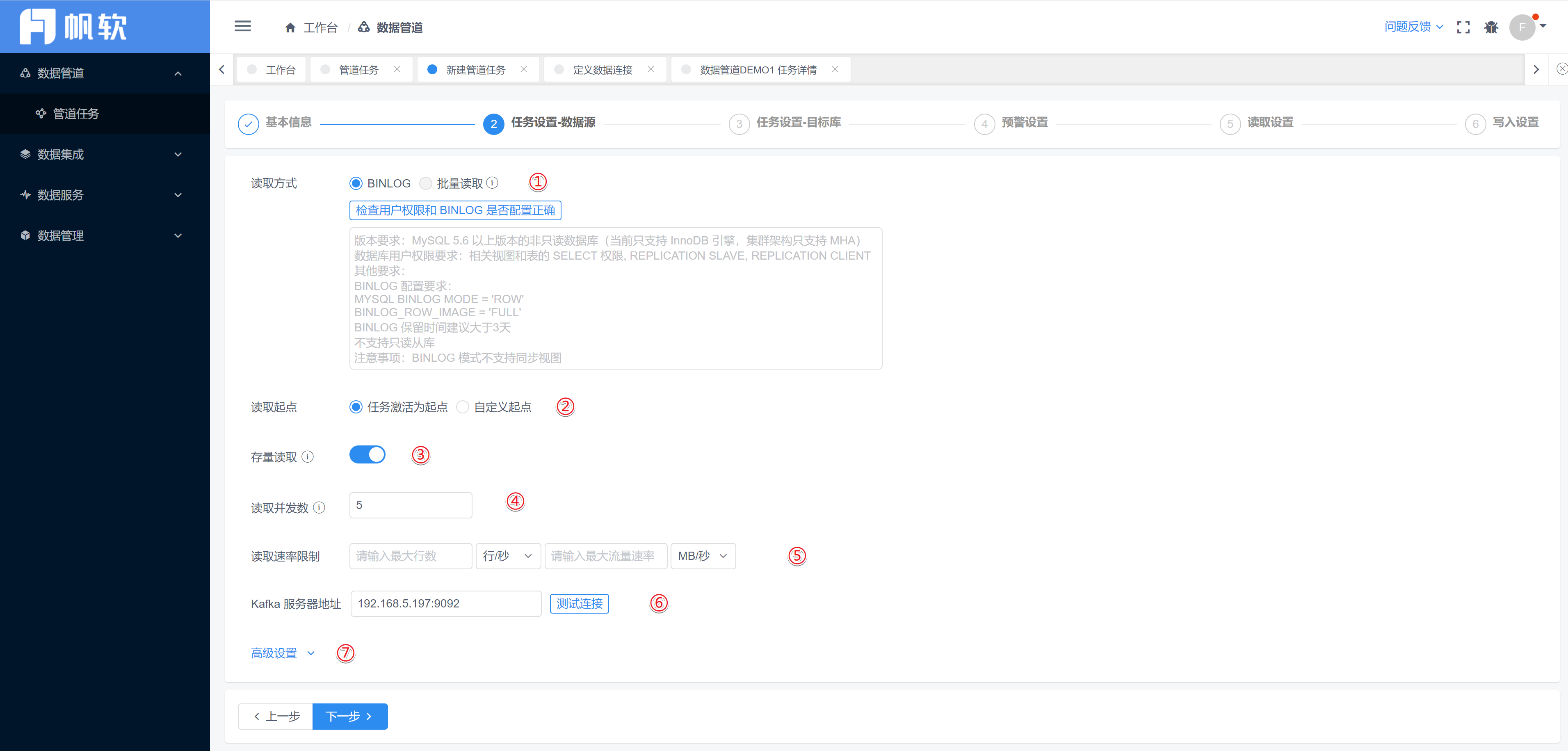
①读取方式:数据管道任务目前仅支持基于日志的读取方式
MySQL: BINLOG 模式
Oracle: LogMiner模式
SQL Server: CDC 模式
② 读取起点(增量数据读取部分):
任务激活为起点:完成任务配置后开始进行同步。
自定义起点:点击后,可自由选择日期以及具体时分秒。
提示:读取起点为日志的读取起点,注意如果指定的解析时间在任务激活时间之前, 且在任务激活时间之前发生过对于所选择的数据源表的 DDL 操作,那么任务会报错并停止。
③ 存量读取:
开启:任务启动时,记录当前时间节点,将会先同步所有存量数据后,再通过日志模式从开始增量数据同步。
关闭:存量数据则从读取起点开始读取。
④ 读取并发数:在日志读取模式 (非批量读取模式)下,为存量同步时的并发线程数;批量读取模式下是每次读取数据时的并发线程数。
一般为默认为 5,最大建议不超过 FT 服务器最大 CPU 数量。
⑤ 读取速率:若为空,则不进行限制。
⑥ Kafka服务器地址:信息消息列队处理系统,点击测试连接,可确认是否连接成功。
⑦ Kafka高级设置:可默认,目前支持自由配置。