

1. 什么是数据分析误区编辑
先看一下字典对误区的定义:由于某种原因而形成的不正确的认识或看法。
再结合我们对数据分析的理解:
把某事物分解成较简单的组成部分进行研究,找出这些部分的本质属性和彼此间的关系。通过认识事物或现象的区别与联系,细致地寻找能够解决问题的主线,并以此解决问题。
因此,所有阻碍了解决问题或是误导问题判断的情况,都是数据分析的误区。
本文将为你简单介绍几个在数据分析过程常见的误区,以便你能在做分析时更好的规避它们。
2. 意识误区编辑
正如我们刚才说的,阻碍解决问题的都是误区,因此并不止逻辑上的误区,许多意识层面的问题也会导致结论出错,甚至无法开展数据分析。
希望通过了解下面几个意识层面的误区,能够让大家拥有进行数据分析的想法,并保证分析思路能尽量切合实际。
2.1 数据分析很高大上
许多人在提到数据分析时,就会天然有种固执的感觉,那就是数据分析只针对少数掌握高级的分析方法或是分析技能的人。
其实不然,真理至简。
我们的分析是从业务中来到业务中去:
在分析方法上,我们常说的四象限分析、SPAN图、SWOT分析,就都是简明扼要且极富实际意义的分析模型,通过这些具有简单的美感的模型,就能很大程度上保证决策不「迷路」。
在分析工具上,做数据分析也并不要求大家掌握 Python、精通算法等,只要有合适的分析方法,找到关键性的指标,那处理流程自然水到渠成,只要你的分析能驱动与业务,用 Excel 也未尝不可。而且企业内部对于不同需求自然有分工处理,过于复杂的分析可以通过协调数据运营等资源进行开展。
就像对于元素规律的大胆分析,诞生了所有人必学的元素周期表。
通过田间地头杂交的豌豆,总结出了完整的遗传学规律。
因此要敢于分析,跨过这个最初也是最严重的误区。
2.2 需要大数据才能支撑分析
日常我们听到数据分析,往往都和大数据这个词挂钩,但实际上两者并无任何依赖关系,更多是在炒作大数据这个概念。
分析需要的是特定数据,而不是更多的数据。
大数据在很多情况下,其实是无法人力剔除脏数据的情况下的方案,通过放大数据量,减少这些内容的影响。
但是如果我们的样本,可以一定程度上反映全量数据,那就已经可以进行分析,并且得到的结论也具有足够的可信度。
2.3 与实际业务脱钩
分析是无止境的,因为有着无穷无尽的变量,但是我们做分析是带有明确目的性的,而且动作也是有明确限制的,因此一定要警惕为了分析而分析。
解决这个误区最管用的办法是找到最合适的指标(北极星指标),再就是认清现状,明确我们能做的事情。
比如分析发现给的红包力度越大,用户越频繁使用,留存率越好,但这明显不是可行方案。
我们最终的结论很可能是长期通过运营内容,周期性通过红包促活,这样才能保证合理的获客成本,实现良性的循环。
2.4 过分依赖数据
过分依赖数据:一方面,会让我们自己做很多没有价值的数据分析;另一方面,也会限制产品经理本身应有的灵感和创意。
数据分析是达到目标的一个科学手段,但不是唯一的手段,而且过分依赖数据也会变得不科学。
在比如数据缺失或是问题简单时,数据分析可能并不是必要的步骤。
假如你去造一个汽车,分析以往马车的情况并无意义,甚至限制了对汽车舒适度和速度的想象。
3. 逻辑误区编辑
3.1 辛普森悖论
先通过一个案例了解一下什么是辛普森悖论:
学院 | 女生申请 | 女生录取 | 女生录取率 | 男生申请 | 男生录取 | 男生录取率 | 合计申请 | 合计录取 | 合计录取率 |
|---|---|---|---|---|---|---|---|---|---|
商学院 | 100 | 49 | 49% | 20 | 15 | 75% | 120 | 64 | 53.3% |
法学院 | 20 | 1 | 5% | 100 | 10 | 10% | 120 | 11 | 9.2% |
总计 | 120 | 50 | 42% | 120 | 25 | 21% | 240 | 75 | 31.3% |
在这个表格中,不管是商学院,还是法学院,男生的录取比例都比女生高很多,但是总体来看,女生录取率却是男生的两倍。
这种在分组比较中都占优势的一方,在总评中有时反而是失势的一方的情况,就是辛普森悖论。
举一个例子,A 应用的用户每日平均访问时长提升了,因此我们得到了结论,用户的粘性提升了,大家做的真棒!
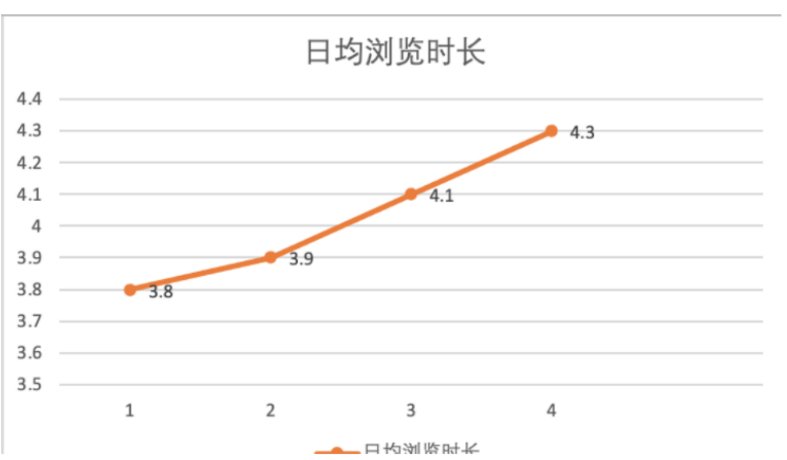
但这是真的吗,如果此时我们把用户根据类型拆分来看,可能会得到如下的结论。
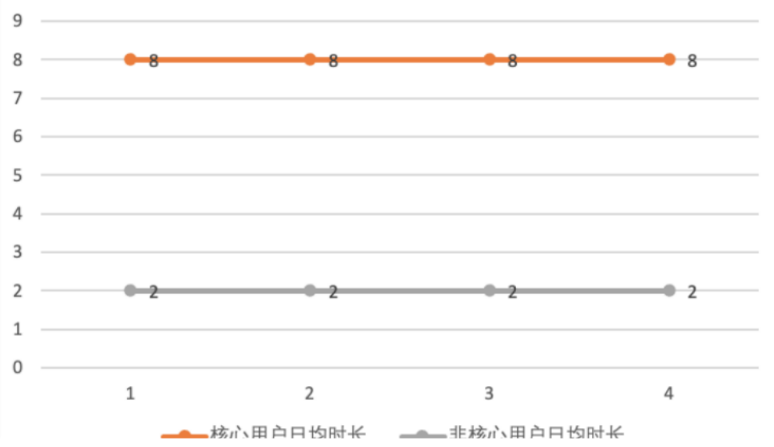
这能反映什么呢?核心用户和非核心用户的日均访问时长都没有变化,似乎与之前的结论相悖。
此时我们就可以进一步分析,去查看核心和非核心用户的占比情况。
我们可以看到核心用户占比提升了,哦,原来是核心用户占比高,所以整体来看,拉高了日均访问时长,此时又忍不住想夸一句大家做得真棒!
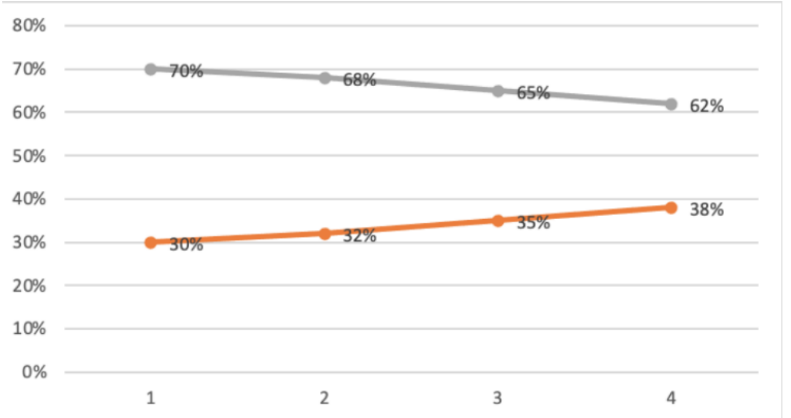
但这难道就是真的吗,我们需要再看一下各类用户的具体数量。
此时我们才得到了真正的结论,原来是非核心用户减少了,有大批用户的流失,才让我们的指标看上去显得变好了。
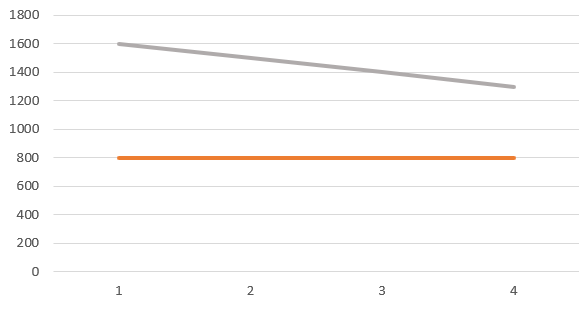
在这个问题中,我们就不只是看最终日均访问时长结果,更应该加上用户数这个观测指标,或是通过合理的规划,将用户数的作用体现在最终指标里。
回避辛普森悖论的方法是:
斟酌个别分组的权重,以一定的系数去消除以分组资料基数差异所造成的影响;
了解该情境是否存在其他潜在要因而综合考虑。
这里在平均值中有给大家介绍,详情参见:平均值
3.2 因果陷阱
在介绍因果陷阱之前,先给大家举日常生活中经常会看到的观点:
打篮球能让人长高
喝咖啡可以长寿
不吃早饭容易变胖
爱笑的女孩子通常运气都不会太差
会撒娇的女人更好命?
然而事实真的是这样嘛?下面我们来分别给出这几个常见观点隐藏的因果陷阱:
| 观点 | 说明 | 因果陷阱类型 |
|---|---|---|
| 打篮球能让人长高 | 这很有可能是因为长高的人都会去打篮球,而不是打篮球让人长高 | 因果倒置 |
| 喝咖啡可以长寿 | 常喝咖啡的人一般都是白领阶级,他们的营养供给更高,所以他们可以长寿,而不是因为咖啡让他们长寿 | 相关性而非因果关系 |
| 不吃早饭容易变胖 | 吃不吃早饭其实和你肥不肥胖没有什么关系,运动健康才和你的肥胖有关系 | 相关性而非因果关系 |
| 爱笑的女孩子通常运气都不会太差 | 爱笑的女孩其实运气也有差的,最后她就不笑了,事实是因为运气好的女孩她们才会爱笑 | 因果倒置 |
| 会撒娇的女人更好命 | 女人好不好命其实与另一半或者周围的人和环境更有关系,而不是和你会不会撒娇有关系 | 需要找到遗漏的 X 变量 |
3.3 幸存者偏差
在讲述幸存者偏差的之前,先给大家举几个例子:
淘宝上卖极限运动设备的商家,尤其卖降落伞、滑翔伞的卖家好评都是满的,从来没有差评。(出事故的人:“我倒是想有差评的机会”)
别人家的孩子都比你强。(日常接触会放大瑕疵,偶尔接触会放大优点)
读书无用论、极端女拳、成功学。(天时地利人和缺一不可,哪怕只从自己身上看,头脑远见几乎不能复制,态度勤奋可以争取,挫折都可以模仿。但是只会鼓吹最后两项)
幸存者偏差出现的原因是逻辑和统计上的错误,本质是统计时忽略了样本的随机性和全面性,用局部样本代替了总体随机样本,从而对总体的描述出现偏差。
当然幸存者偏差还很大程度上反映了人性的弱点,人性总是会让我们忽略或筛选信息,最终导致幸存者偏差。
要避免幸存者偏差有一下几个方法:
关注沉默的数据,当我们已经习惯了逼乎上刚下飞机,年入百万,朋友圈名牌豪车,拼多多的崛起让「沉默证据」发力:原来购买廉价产品,为了几毛钱动员砍价的人,才是中国人口最广的群体。
学习数学统计知识,就像讲述辛普森悖论里的案例,表面欣欣向荣,其实暗藏了用户流失的风险。
提升认知水平和逻辑思维能力,很大程度发生幸存者偏差上是因为自身认知水平确实有限,也就是自己只知道某些表面的信息,根本不知道那些关键信息的存在,最后导致判断失误。比如传销和成功学,就是未曾全局思考事物,没有想清楚利益背后的逻辑与风险