一、数据同步编辑
(1)报错:“Long类型不能转为Bytes”
原因:tinyint(1)类型字段被代码读取为bit类型字段
解决方案:数据连接中增加参数?tinyInt1isBit=false
(2)报错:account_id有不可为空

原因:来源表中account_id字段有空值,但是目标表中该字段设置了不可为空
解决方案:过滤掉来源表中account_id字段为空的数据,或者设置目标表字段可为空
(3)报错:您填写的参数值不合法
报错:com.fr.dp.exception.FineDPException: Code:[DBUtilErrorCode-02], Description:[您填写的参数值不合法.]. - 您的配置文件中的列配置信息有误. 因为您未配置写入数据库表的列名称,fdi获取不到列信息. 请检查您的配置并作出修改.
原因:来源表字段获取失败
解决方案:检查来源表数据预览是否成功,若是数据库数据源,可能是sql语法错误,若是API数据源,可能token失效
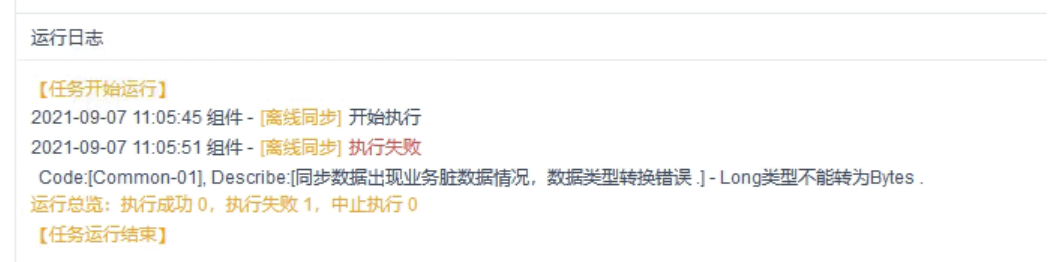
(4)报错:FineDI传输脏数据超过用户预期
报错:com.fr.dp.exception.FineDPException: Code:[Framework-14], Description:[FineDI传输脏数据超过用户预期,该错误通常是由于源端数据存在较多业务脏数据导致,请仔细检查FineDI汇报的脏数据日志信息, 或者您可以适当调大脏数据阈值 .]. - 脏数据条数检查不通过,限制是[0]条,但实际上捕获了[7]条.
原因:来源数据与目标数据的字段类型或字段长度对不上
解决方案:修改目标表字段类型、字段长度,与来源表相符
(5)报错:脏数据条数检查不通过
报错:"脏数据条数检查不通过,限制是0条,实际上捕获了11条",查看fanruan.log看到“当 IDENTITY_INSERT 设置为 OFF 时,不能为表 'CB' 中的标识列插入显式值。”的报错

原因:当 IDENTITY_INSERT 设置为 OFF 时,不能为表 'CB' 中的标识列插入显式值。
解决方案:数据库配置问题set IDENTITY_INSERT Student ON。
(6)报错:无法获取已存在的目标表
日志报错:不支持的字符集(在类路径中添加orai18n.jar)

原因:lib中缺少orai18n.jar包
解决方案:FDL的lib中增加orai18n.jar包即可
(7)报错:对于字符类型来说这个值太长了
原因:源端的字段和目标端的字段长度不匹配,或者原端字段的数据类型和目标端不匹配
解决方案:修改问题字段的字段长度或者更改数据类型
(8)API取数执行失败
报错:com.fr.dp.exception.FineDPException: API_DATA_INVALID_ERROR - ApiReader can't get data of column [data], please check api response.
原因:API数据源token失效,读不到data字段
解决方案:重新获取API数据源的token
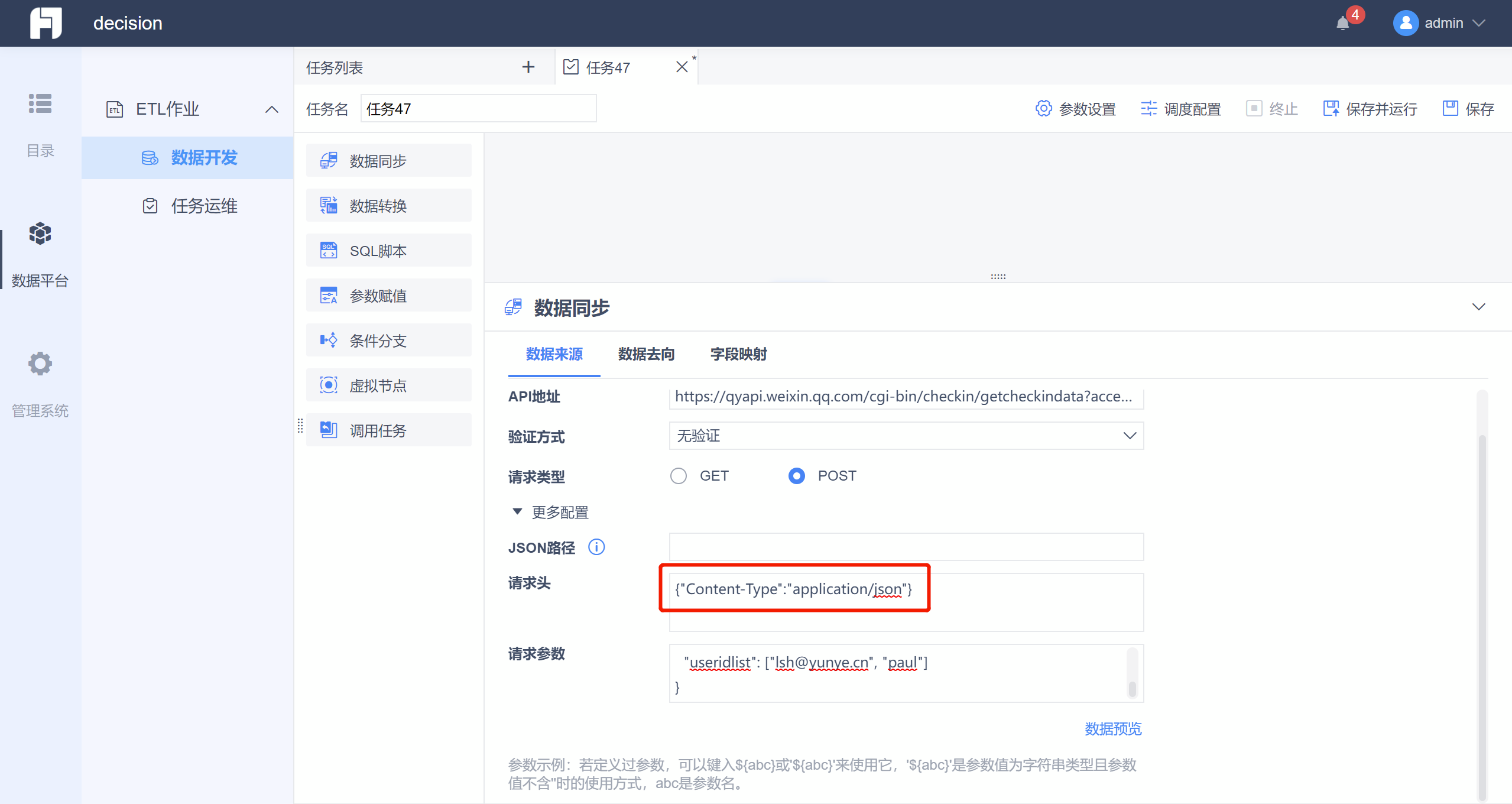
(9)API取数预览显示所需要的数据为空值
原因:请求头中可能未指定通过json的格式进行取数
解决方案:请求头中添加: {"Content-Type":"application/json"}
(10)API报错Warning: wrong json format
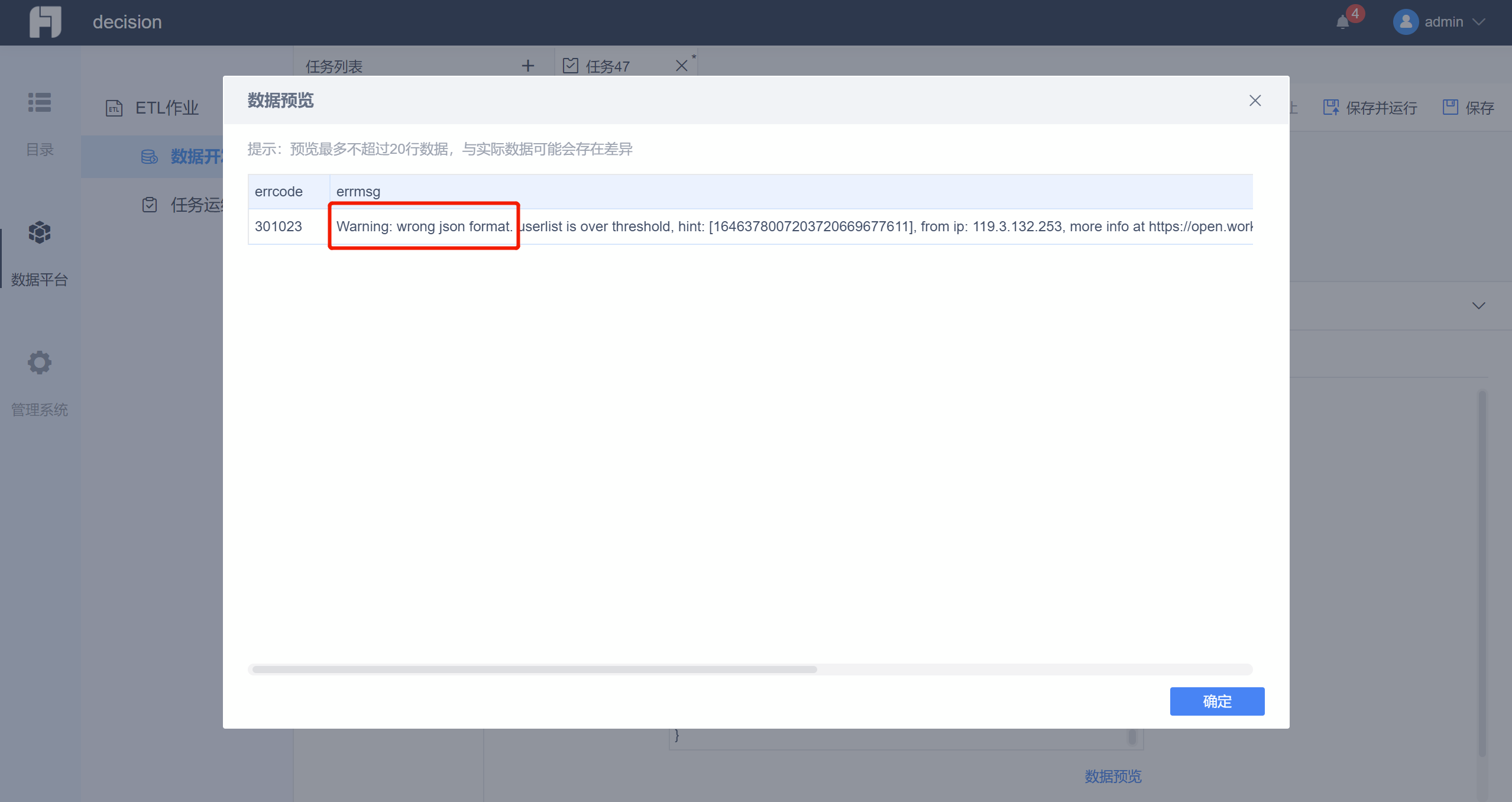
原因:导入的是表格形式,如果不写,就是识别表格,会报错
解决方案:请求头加上:{"Content-Type":"application/json"}
二、数据转换编辑
(1)脏数据报错
报错代码:Code:[DICommon-40], Describe:[Too many dirty data error.] -Too many dirty records,limit [0]records,but catch [13] records actually.
[DB表输入]: Code:[Executor-04],Description:[Job is Terminated].-Job is Terminated
原因:

解决方案:https://blog.csdn.net/weixin_44943631/article/details/99933835
报脏数据目前发现的原因:
1.字段类型不匹配
2.字段长度不够
3.inentity insert设置为off
4.复制节点没有点击字段映射
(2)报错【数据关联】Spark执行错误
关联结果膨胀超过5倍 + 关联数据量大于 1kw
执行报错:[数据关联]: Spark执行错误- org apache spark sql. execution joins .exception.N2NInterruptException - null

原因:spark自己的保护机制,数据量过大避免宕机时触发
三、SQL脚本编辑
(1)call 存储过程不生效
原因:存储过程没有指定数据库模式,jdbc方式没有识别
解决方案:除Mysql数据库外,其他数据库的存储过程、数据表调用时,建议均增加模式名:call 模式名.存储过程名
(2)sql脚本节点运行报错:数据库字段编码格式问题
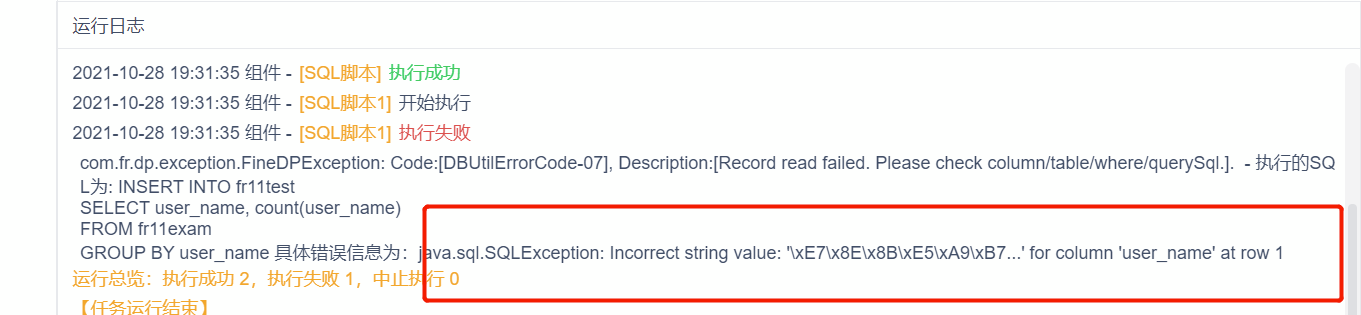
原因:一节点使用自动建表创建目标表A,二节点使用手动建表语法创建目标表B,三节点将目标表A的数据进行汇总插入到目标表B,报错的原因是自动创建的目标表编码格式和手动创建表的编码格式不同。
解决方案:手动创建表时,指定目标表编码格式和自动创建表格式相同
CREATE TABLE IF NOT EXISTS `test1234` (
`user_name` varchar(255) DEFAULT NULL,
`numbers` varchar(255) DEFAULT NULL
)charset=utf8mb4
(3)sql脚本执行报错
执行报错:[数据来源]: Code:[DatasourceError. 008], Description:[Cached table data has been removed].
[数据去向]: Code:[DICommon-20], Describe:[Shutdown command received.]
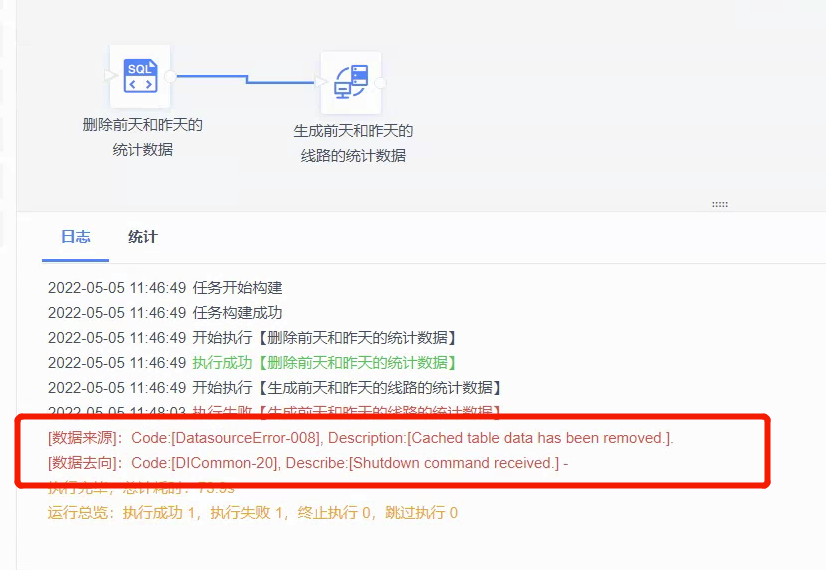
原因:sql脚本先删除数据库前两天的数据,数据同步把excel的数据同步到数据库,预览什么的都正常,excel数据是finereport导出的数据,数据量不大,但数据计算有点大,预览时间超过六十秒
解决方案:如果超过60s,会自动清除服务器数据集对象
四、条件分支编辑
(1)参数赋值-条件分支,显示服务器内部错误
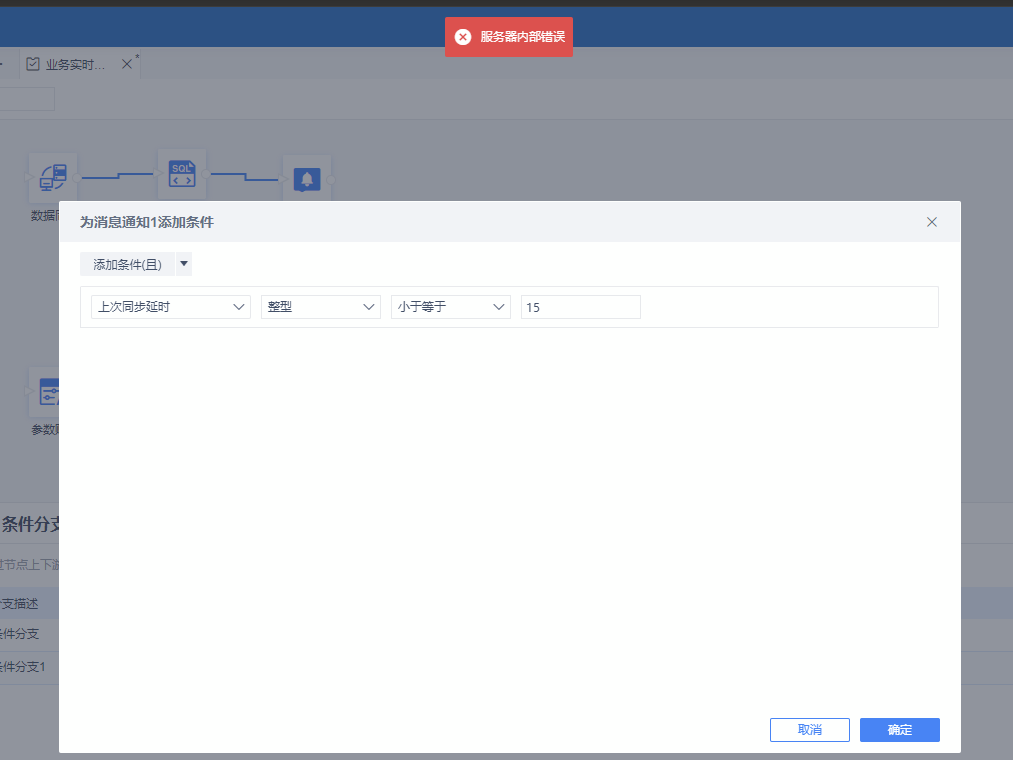
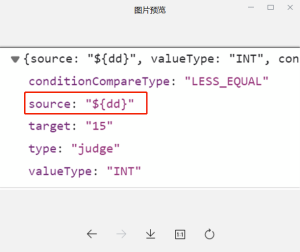
原因:核实触发了20009规则,该规则主要拦截POST数据请求体解码后包含”%“、”$“等特殊字符的攻击特征,这些字符通常是代码执行攻击利用到字符,所以被识别为攻击拦截了。
解决方案:条件分支用到了$,特殊字符需要加密传输,可以先给$ 这个字符开通道,或对这个ip加白名单
五、任务运行编辑
(1)页面报错,F12报错:nested exception is java.lang NoSuchMethodError:
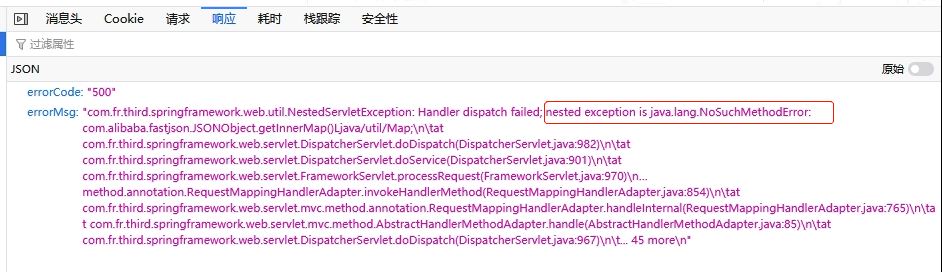
原因:FDL中内置了fastjson.jar,服务器工程内其他地方也存在fastjson.jar,两侧冲突,导致报错
解决方案:找到工程内其他fastjson.jar,若版本低,可用数据准备的fastjson.jar替换掉对应jar,若版本高,则删除数据准备内fastjson.jar
(2)所有任务均无法执行,报错无法执行cloudpayorder
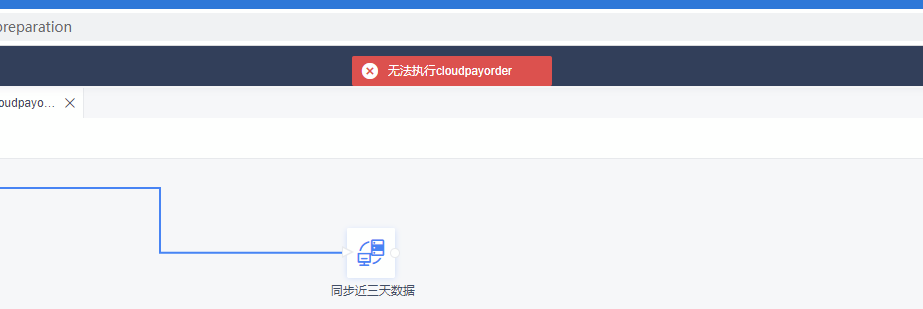
原因:Finedb中存在两条一样的数据
解决方案:SELECT * FROM "fine_dp_conf_entity_x"
where value_class = 'WorkAttributeEntity' and entity_value like '%%'
先看fanruan.log里面的报错信息,定位到错误信息
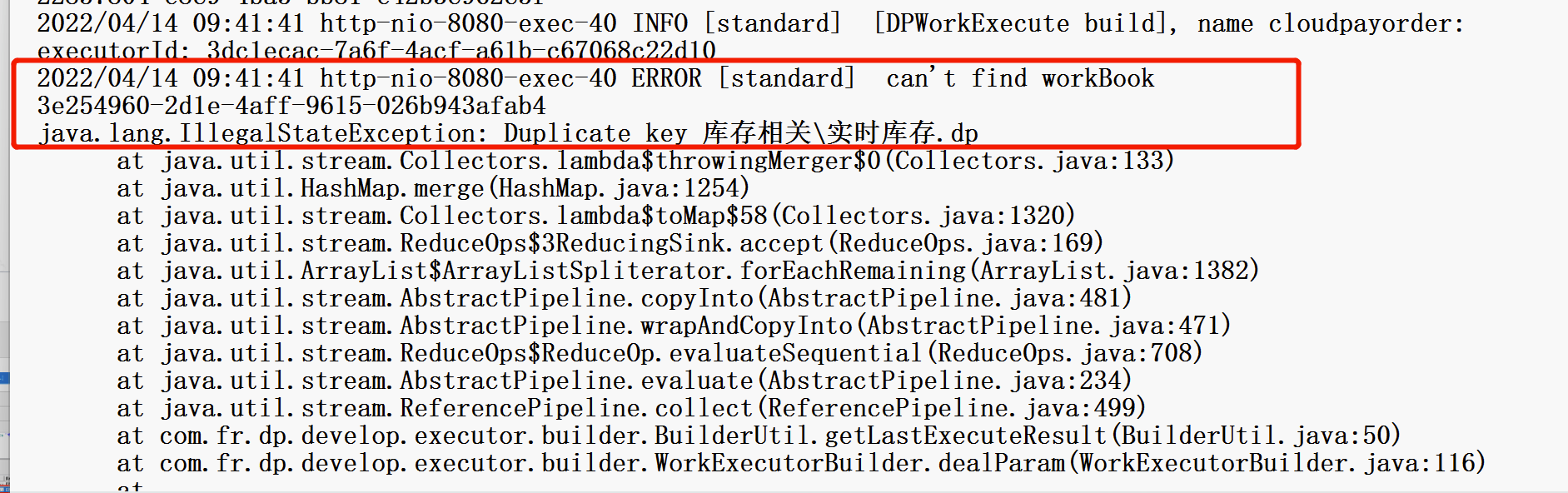
打开finedb,找到fine_dp_conf_entity_x
执行上述sql语句,找到日志里的圈起来的dp文件。
删除其中一个文件即可