

1. 概述编辑
1.1 版本说明
| FineDataLink 版本 | 功能变动 |
|---|---|
| 4.0.3.1 | 新增「循环容器」节点,满足多个节点循环执行的场景 |
| 4.0.30 | 「循环容器」外的节点允许拖到容器内;其中有连线连接的节点不能单独拖入容器内,需要整组选中,一起拖入容器内 |
| 4.1.0 | 调整参数在循环容器中的使用逻辑,详见 4.2.2 节 |
| 4.1.1 | 循环容器支持设置容错机制 当循环容器中有节点报错时(例如API循环取数时取出数据为空),支持继续执行循环,详情参见第三章 |
1.2 应用场景
用户需要从 API 接口取数, API 接口的参数来自数据库内的一列字段。由于 API 接口中,参数每次只能读取一个参数值,所以需要将数据库的某列字段值逐个输出为参数,遍历所有参数从 API 接口取数。
数据量非常大时,用户希望分段执行,每次只取出一段时间内的数据,直至取出所有时间段内的数据。
1.3 功能简介
「循环容器」节点+参数 联合使用,可满足分批抽取数据的场景。如下图所示:

| 循环方式 | 示例说明 | 示例文档 |
|---|---|---|
| 遍历循环 | API 接口中包含参数 dataid,可取出特定 dataid 的接口数据 现在 dataid 保存在数据库中,希望取出这些 dataid 对应的接口数据,其中 API 接口每次只能取出一个 dataid 对应的数据 | 循环容器典型示例-API取数 |
| 每次只取出一段时间内的数据,直至取出所有时间段内的数据 | 使用SparkSQL构建日期列并循环取数 | |
| 条件循环 | 从第一页开始取数,当页数>总页数时,停止循环 | 分页取数-按页数取数 中方案二 |
| 目标表数据行数<总行数时,才执行循环 | API取数-以起始行数作为参数 |
2. 使用限制编辑
若想使用「循环容器」功能,需注册「循环容器」功能点。详情请参见:FineDataLink注册授权
循环容器中的节点必须在创建节点,即在拖入节点至画布界面的时候直接拖入循环容器中,不能直接把循环外的节点拖进去,否则该节点在循环容器中不生效。
参数赋值的参数只能给其下游节点使用,循环容器内也是一样的。
「循环容器」节点内不能拖入的节点类型:「调用任务」节点和「循环容器」节点。
3. 功能说明编辑
3.1 遍历循环
3.1.1 使用说明
「循环容器」节点前,需要使用「参数赋值」节点或者「数据转换-参数输出」算子输出参数,然后在「循环容器」中遍历所有参数从数据库/API接口中取数。
注:每次循环使用的参数,来自容器外&循环容器上游。
为便于理解,下面以一个示例说明遍历循环。循环容器典型示例-API取数 示例说明:
场景:
API 接口中包含参数 data_id,可取出特定 data_id 的接口数据。
现在 data_id 保存在数据库中,希望取出这些 data_id 对应的接口数据,其中 API 接口每次只能取出一个 data_id 对应的数据。
方案:
使用「参数赋值」节点将保存在数据库中的 data_id 取出并输出为参数,将这些参数传递给「循环容器」。
「循环容器」中拖入「数据同步」节点从 API 接口取数,每次取数时只使用一个 data_id ,直到所有 data_id 都被使用停止循环。

3.1.2 循环限制
循环次数上限。默认128次,用户可手动调整,上限为10000次,不可为空。
3.1.3 循环方式
可选择遍历循环、条件循环。
1)遍历循环参数(数组)中的元素,遍历结束则循环结束,循环次数与遍历对象的元素个数一致。循环次数由字段值的个数决定。
当遍历值不为空时,返回布尔值:true,继续下一次循环。
当遍历值为空时,返回布尔值:false,结束容器内的循环。
2)条件循环说明请参见本文 3.2 节内容。
3.1.4 遍历对象
选择上游设置的参数,选择的参数逐行获取值,未选择的参数直接获取值。
当选择遍历循环(for-each)时,必须选择遍历对象。
当选择条件循环(do-while)时,遍历对象可选。
「遍历对象」设置为循环容器上游的参数赋值,可以选择单个和多个,但限制只能选择循环容器上游的参数。
3.1.5 执行条件
当选择遍历循环(for-each)时,无需选择执行条件。
3.1.6 容错机制
若用户希望循环容器内能忽略节点的报错继续执行循环,而不是停止下一次循环。例如:API循环取数时取出数据为空中出现的循环取数时,一次获取的批量数据可能为空,则希望此时还能继续执行循环取数,则可使用该功能。
默认不勾选:当一次循环中有节点执行抛错,不再进行下一次循环。
当勾选时:循环容器中有一个节点报错时,继续执行循环(在日志中需要输出单次循环中的错误信息),此循环容器的执行结果还是执行失败。

3.2 条件循环
3.2.1 使用说明
条件循环需要同时满足以下两个条件:
具备每次循环取数的参数:使用参数赋值、参数输出、内置参数等,设置每次循环取数需要用到的参数。参数可以来自容器外,也可以来自容器内。
具备循环结束条件:根据实际场景设置循环结束条件,当不符合循环条件时,结束循环。参数可以来自容器外,也可以来自容器内。
为便于理解,下面以一个示例说明遍历循环。分页取数-按页数取数 方案二示例说明:
场景:
接口文档中包含的参数如下图所示,其中 pageIndex 表示数据页数;pageSize 表示在每一页的数据条数:

某企业现在需要将某业务工单数据全部取出以供业务分析使用。
方案说明:


3.2.2 循环方式
循环限制、遍历对象、容错机制详细说明请参见本文 3.1 节内容。
条件循环:
先执行一次循环体,再判断条件。设定循环执行和结束的条件,循环次数由条件决定。
当条件判断返回布尔值:true,继续下一次循环;
当条件判断返回布尔值:false,结束容器内的循环。
注:4.1.1 及之后版本,产品内条件判断逻辑进行了统一,每个运算符的说明可参见:条件判断逻辑说明
3.2.3 执行条件
当选择条件循环(do-while)时,执行条件必选
需要设定结束条件,条件中的参数可以是循环容器外的参数,也可以是循环容器内的参数,也可以是自定义参数。

4. 容器内参数编辑
4.1 内置参数
内置参数 | 生效范围 | 定义 |
|---|---|---|
| ${loopTimes} | 循环容器内部 | 容器内当前循环次数,初次为1,后续每次循环递增加1。 |
详情参见:${loopTimes}
4.2 容器内参数规则
4.2.1 规则说明
容器内可以使用「参数赋值」,「参数赋值」输出的值形成容器内的参数:
容器内参数仅可在容器内使用,不可向容器外传递;
容器内参数优先级最高,优先级大于其他所有容器外参数和内置的参数。
对「参数赋值」中单个参数输出的字段值个数进行限制,限制最多不能超过 10000 个
4.1.0 之前版本,容器内使用文本型参数时,需要手动添加单引号。
4.2.2 升级兼容说明
4.1.0 之前版本中,「循环容器」节点中引用参数时,会自动去掉参数的单引号,所以「循环容器」节点在使用文本型(分隔符选择文本型分隔)参数需要手动加上单引号。
4.1.0 及之后版本,「循环容器」节点中引用参数时,不再自动去掉参数的单引号,所以「循环容器」节点在使用文本型(开启闭包符)参数时无需手动加上单引号。
「参数赋值节点+循环容器」场景中,若「参数赋值」节点输出参数的分隔符选择「文本型分隔」,在循环容器内使用参数时加了单引号,升级到 4.1.0 及之后版本时,需要手动去掉单引号。
5. 节点组成编辑
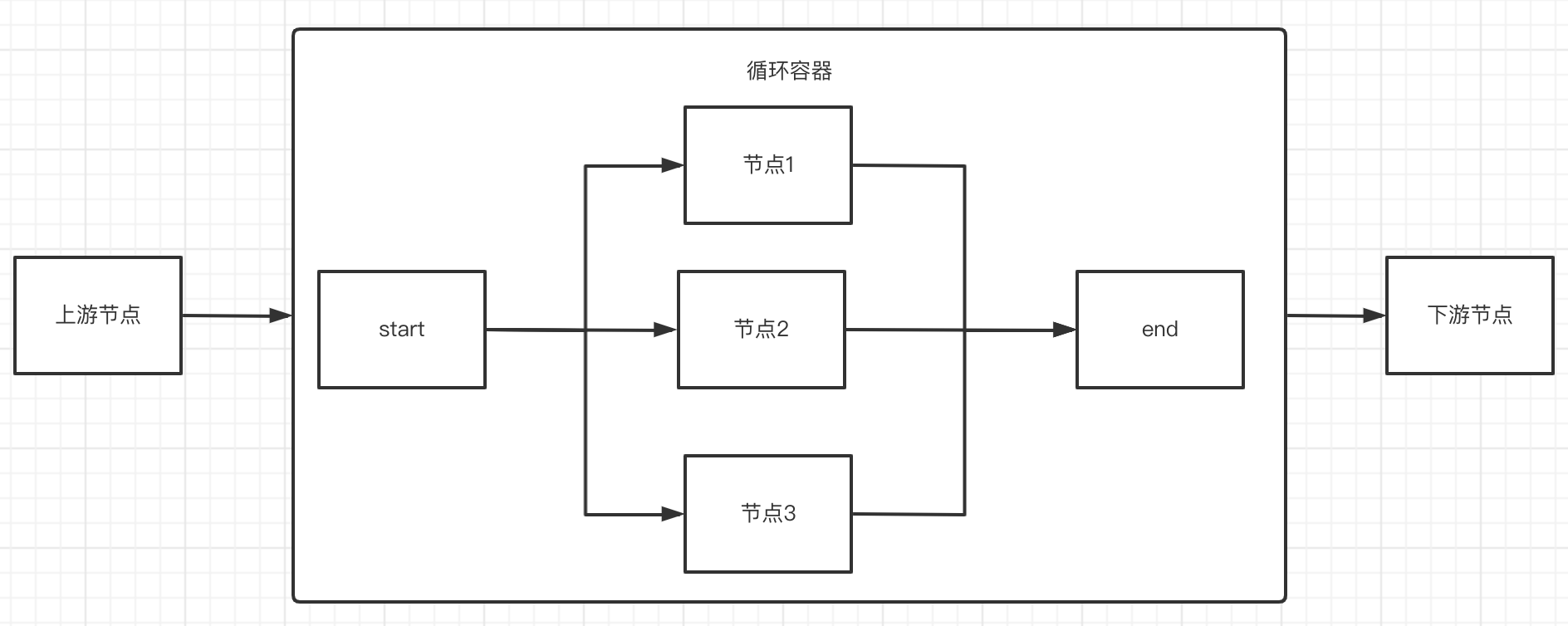
允许循环容器内的节点不必须通过连线建立联系,原因是循环容器内隐藏的有一个start和end节点。
在创建完成循环容器节点时,同时也自动创建完成了三个内部节点:start节点(循环开始节点)、循环任务节点、end节点(循环结束判断节点),通过内部节点组织成内部节点流程,实现任务的循环运行。
6. 应用示例编辑
| 循环方式 | 示例说明 | 示例文档 |
|---|---|---|
| 遍历循环 | API 接口中包含参数 dataid,可取出特定 dataid 的接口数据 现在 dataid 保存在数据库中,希望取出这些 dataid 对应的接口数据,其中 API 接口每次只能取出一个 dataid 对应的数据 | 循环容器典型示例-API取数 |
| 每次只取出一段时间内的数据,直至取出所有时间段内的数据 | 使用SparkSQL构建日期列并循环取数 | |
| 遍历新增、修改数据的主键,调用 新增或更新表单实例 接口,来更新、新增宜搭表单的数据 | 新增/修改宜搭表单数据 | |
| 嵌套循环 | 嵌套循环取数 | |
| 条件循环 | 从第一页开始取数,当页数>总页数时,停止循环 | 分页取数-按页数取数 中方案二 |
| 目标表数据行数<总行数时,才执行循环 | API取数-以起始行数作为参数 | |