

1. 概述编辑
1.1 版本
| FineDataLink 版本 | 功能说明 |
|---|---|
| 4.0.11 | 支持使用Hadoop Hive (HDFS)写入数据 |
1.2 应用场景
FineDataLink 支持读取Hadoop Hive 中的数据进行数据处理,但是直接通过Hive、Impala的接口写入数据性能不佳,因此 FDL 提供了Hive(HDFS) 写入数据。
本文将介绍如何连接 Hadoop Hive (HDFS)数据源。
注:由于Hive底层存储(HDFS)的限制,数据同步中不支持选择比对字段;不支持比对删除。
2. 准备工作编辑
2.1 版本和驱动
下载驱动,并将其上传至 FineDataLink,如何上传可参见:驱动管理 2.1 节
注:在上传驱动包时,需要解压下面的「日志jar」文件,和驱动一起上传至 FineDataLink。
| 支持的数据库版本 | 驱动包下载 | 日志jar下载 |
|---|---|---|
| hive_1.1 | ||
| Hadoop_Hive_1.2;hive2.3; hive2.1.2;hive2.1.1 |
2.2 收集连接信息
在连接数据库之前,请收集以下信息:
数据库所在服务器的 IP 地址和端口号;
数据库的名称;
若是用户名密码认证,需要收集用户名和密码;若是 Kerberos 认证,需要收集客户端 principal 和 keytab 密钥路径;
3. 具体连接步骤编辑
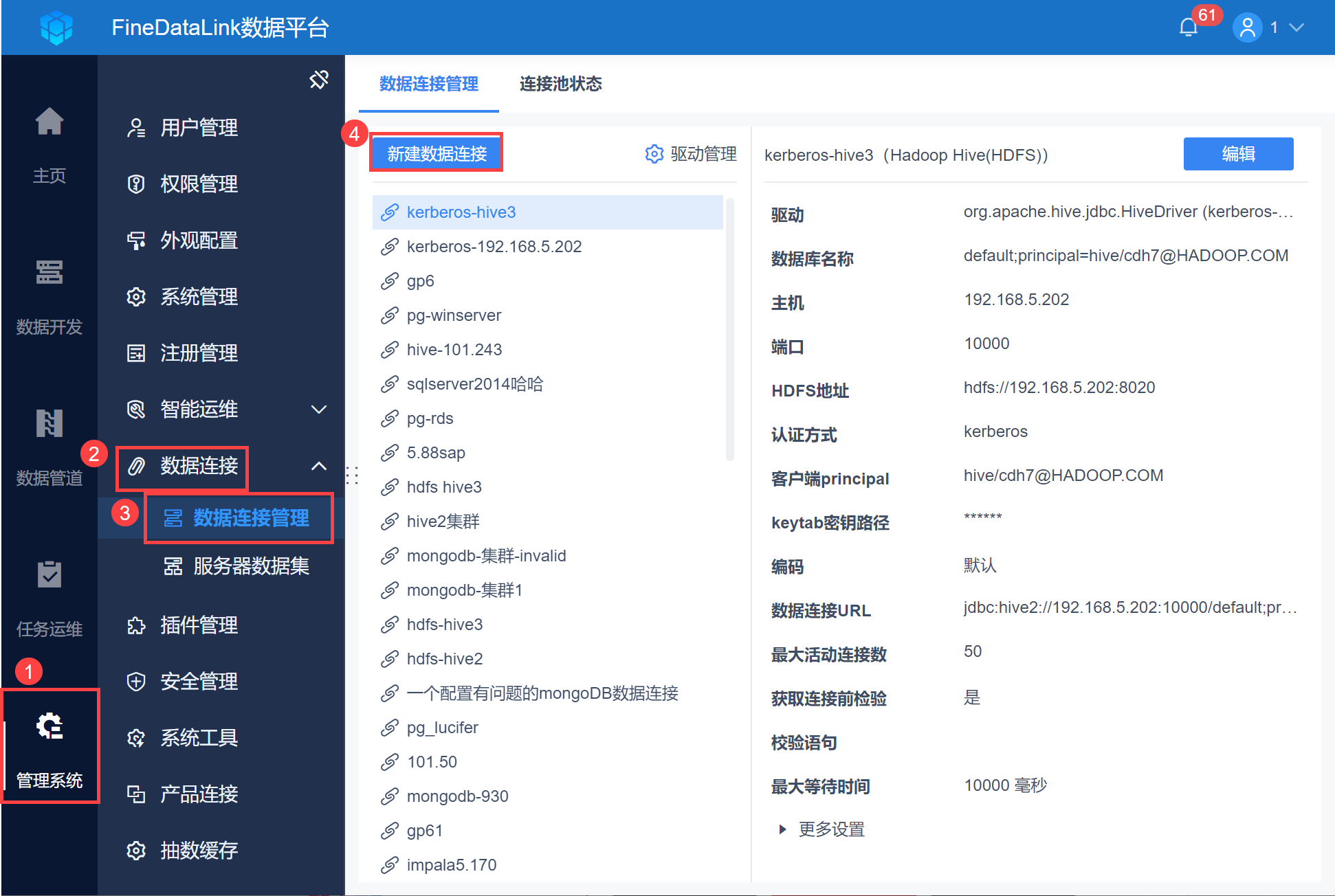
1)以管理员身份登录 FineDataLink ,点击「管理系统>数据连接>数据连接管理」,点击「新建数据连接」,如下图所示:
注:如果非管理员用户想要配置数据连接,需要管理员给其分配管理系统下数据连接节点的权限,具体操作请查看 数据连接管理权限
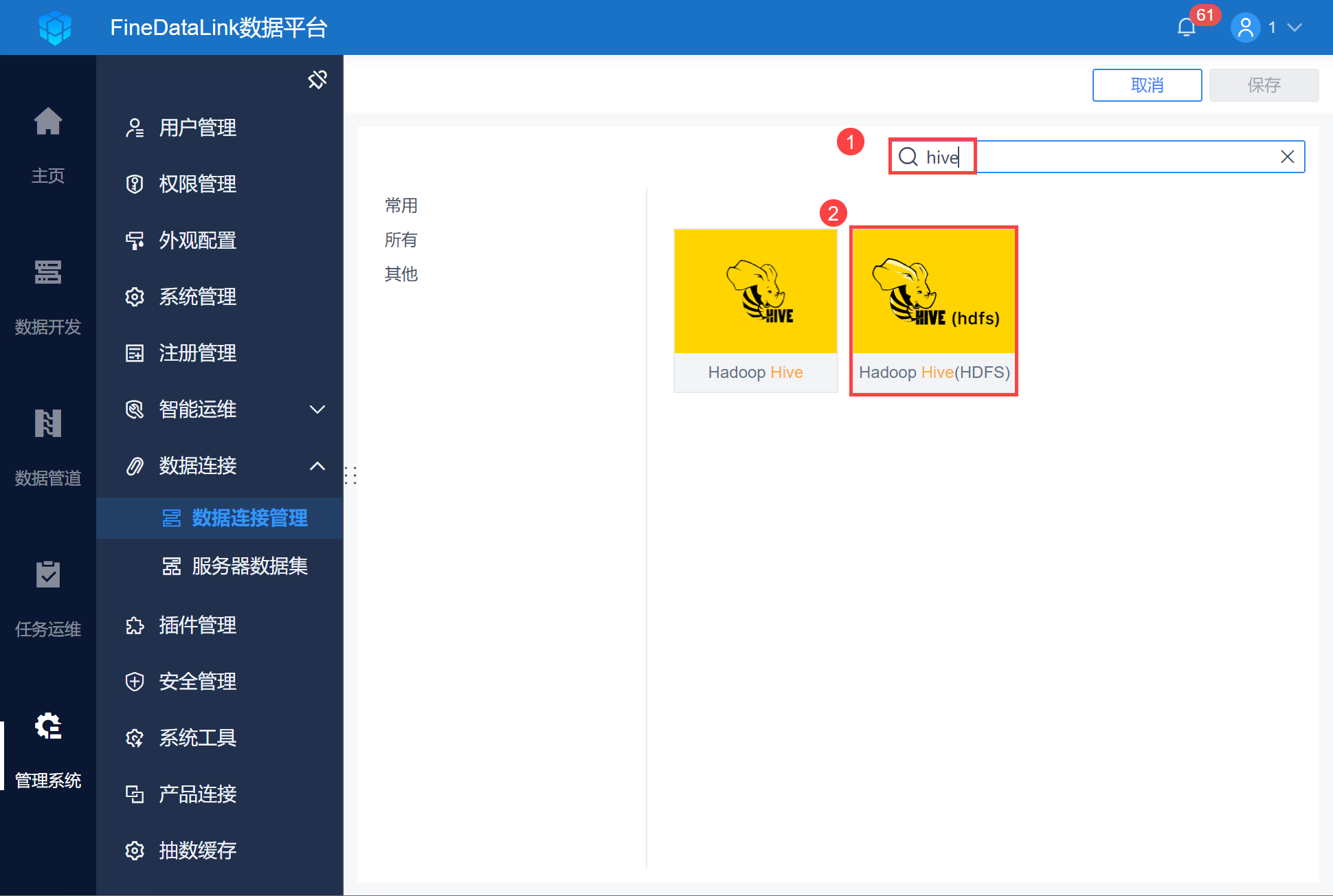
2)找到 Hadoop Hive 数据库,如下图所示:
3)切换驱动为「自定义」选择 2.1 节上传的驱动,并输入 2.2 节收集的连接信息,如下图所示:
Kerberos 认证方式详情可参见:数据连接 kerberos 认证
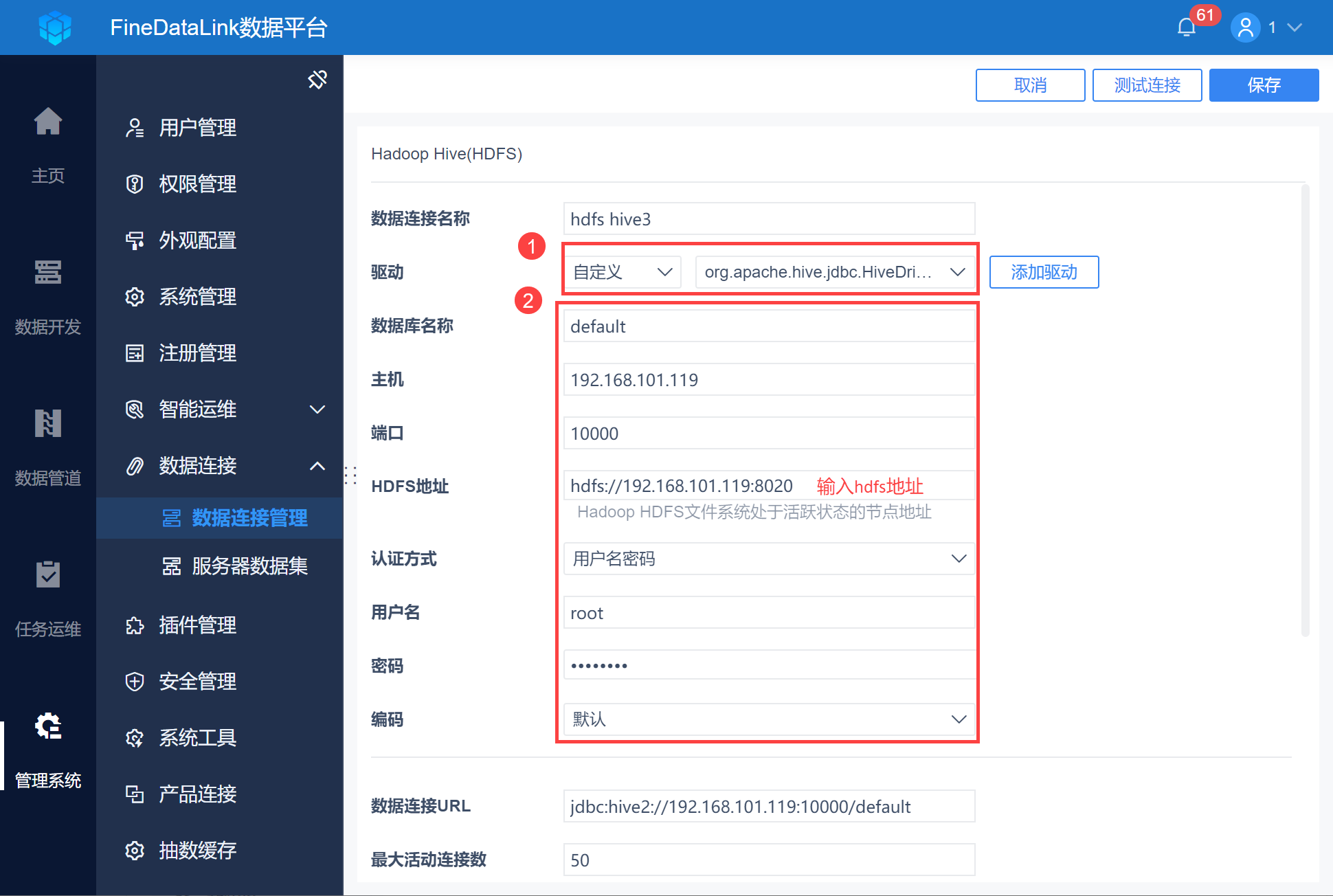
使用 Kerberos 认证需要注意以下事项:
连接前请检查 /etc/hosts 中的机器名对应 IP 是否为局域网 IP;
检查 /etc/hostname 中机器名设置和 /etc/hosts 中是否配置一致;
检查 FineDataLink 所在机器 hosts 配置的 IP+ 机器名是否正确;
本地连接时需要配置 /etc/hosts 文件,添加远端映射:IP+机器名,例如: 192.168.5.206 centos-phoenix 。
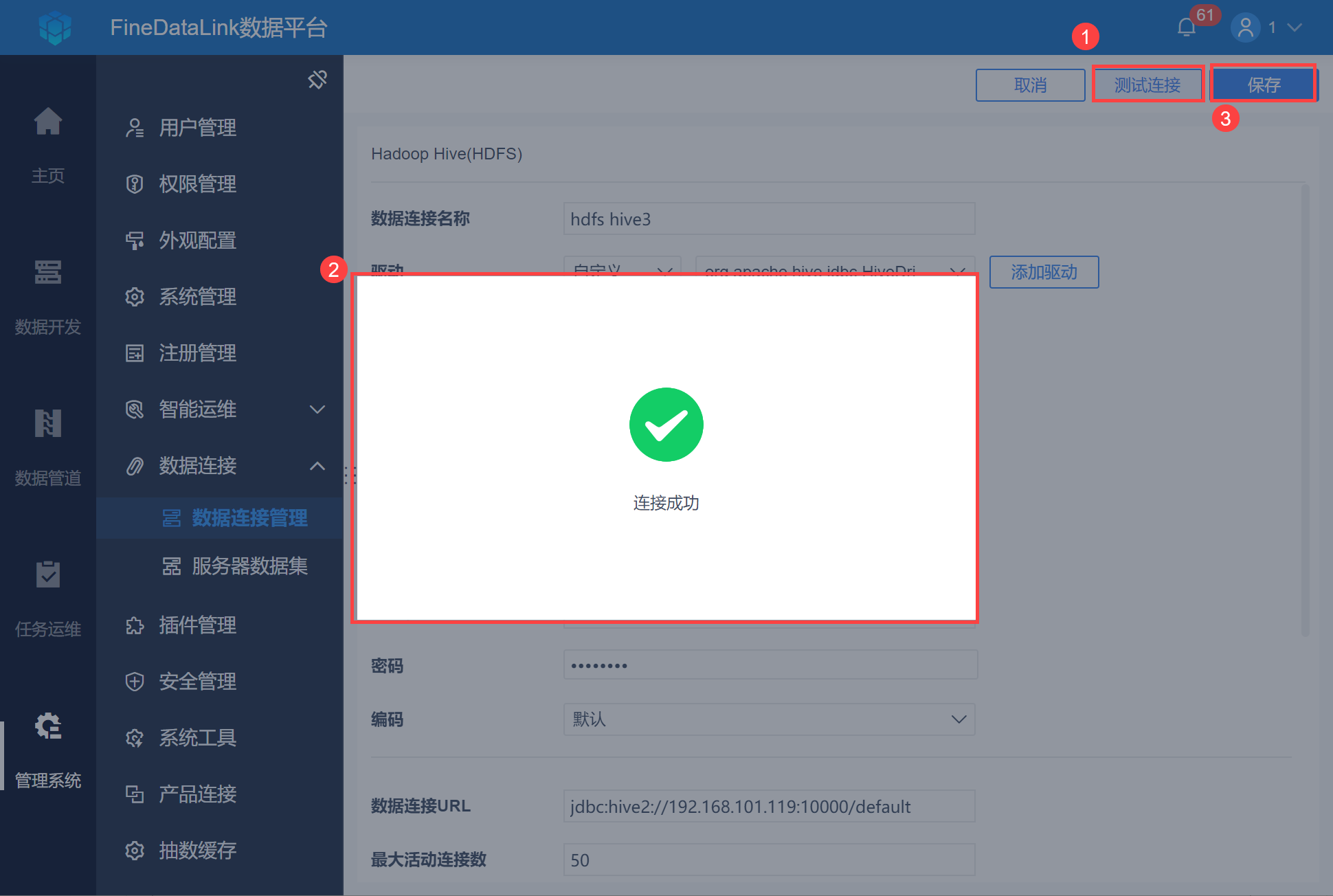
4)点击「测试连接」,若连接成功则点击「保存」,如下图所示:
4. 使用数据源编辑

5. 注意事项编辑
5.1 问题描述
数据连接报错 org.apache.hadoop.security.AccessControlException: Permission denied: user=root, access=WRITE, inode="/":hdfs:supergroup:drwxr-xr-x。
5.2 解决方案
5.2.1 解决方案1
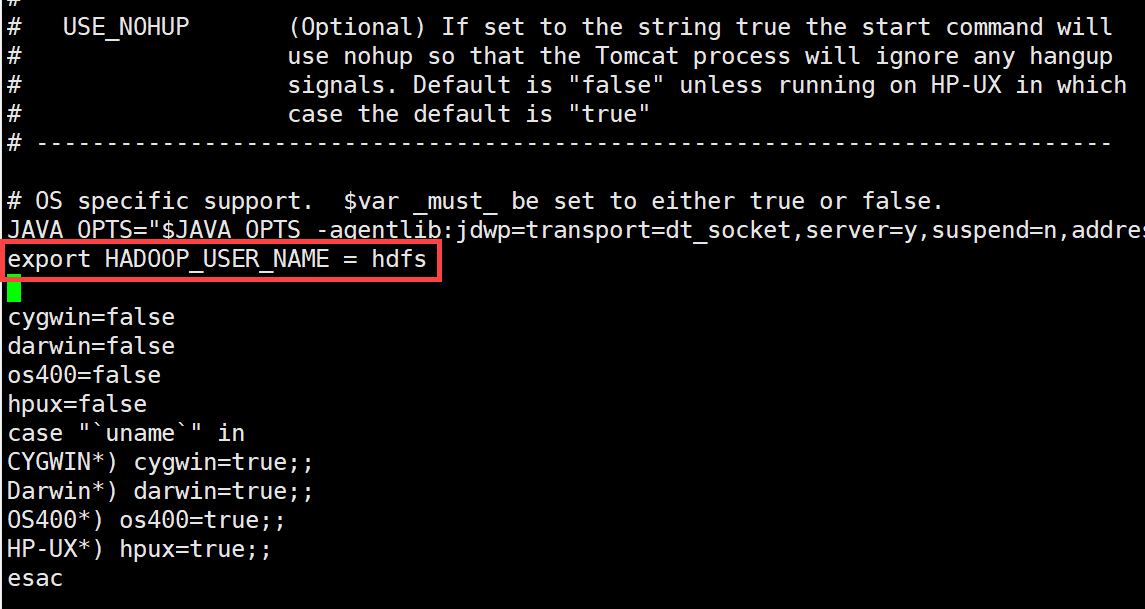
在FDL服务端的catalina.sh 里面指定新增变量声明:export HADOOP_USER_NAME = hdfs,指定连接 HDFS 的用户为 hdfs;
注:可根据实际用户名修改。
5.2.2 解决方案2(不推荐)
在不指定用户的情况下,连接HDFS时默认使用root账号,需要关闭HDFS用户验证,可能会带来安全隐患。因为该方案可让所有用户访问 hdfs,不用进入hdfs用户再执行命令。
注:CDH中没有这个配置需要自己加进去。
步骤如下:
1)找到 hdfs-site.xml 的 HDFS 服务高级配置代码段(安全阀)
2)dfs.permissions.enabled 的值设置为 false,保存更改,重启 hdfs 。
