1. 概述编辑
1.1 版本
| FineDataLink 版本 |
|---|
| 4.0.4.2 |
1.2 应用场景
Hadoop 是个很流行的分布式计算解决方案,Hive是建立在 Hadoop 上的数据仓库基础构架。
本文将介绍如何连接 Hadoop Hive 数据源。
注:建议使用该数据连接进行数据读取源,由于直接写入Hive性能不佳,4.0.11 以及以上版本可以使用Hive(HDFS)作为数据去向,详情参见配置Hadoop Hive(HDFS)数据源
2. 准备工作编辑
2.1 版本和驱动
下载驱动,并将其上传至 FineDataLink,如何上传可参见:驱动管理 2.1 节
注:在上传驱动包时,需要解压下面的「日志jar」文件和驱动一起上传至 FineDataLink。
| 支持的数据库版本 | 驱动包下载 | 日志jar下载 |
|---|---|---|
| hive_1.1 | ||
| Hadoop_Hive_1.2;hive2.3; hive2.1.2;hive2.1.1 |
2.2 收集连接信息
在连接数据库之前,请收集以下信息:
数据库所在服务器的 IP 地址和端口号;
数据库的名称;
若是用户名密码认证,需要收集用户名和密码;若是 Kerberos 认证,需要收集客户端 principal 和 keytab 密钥路径;
3. 具体连接步骤编辑
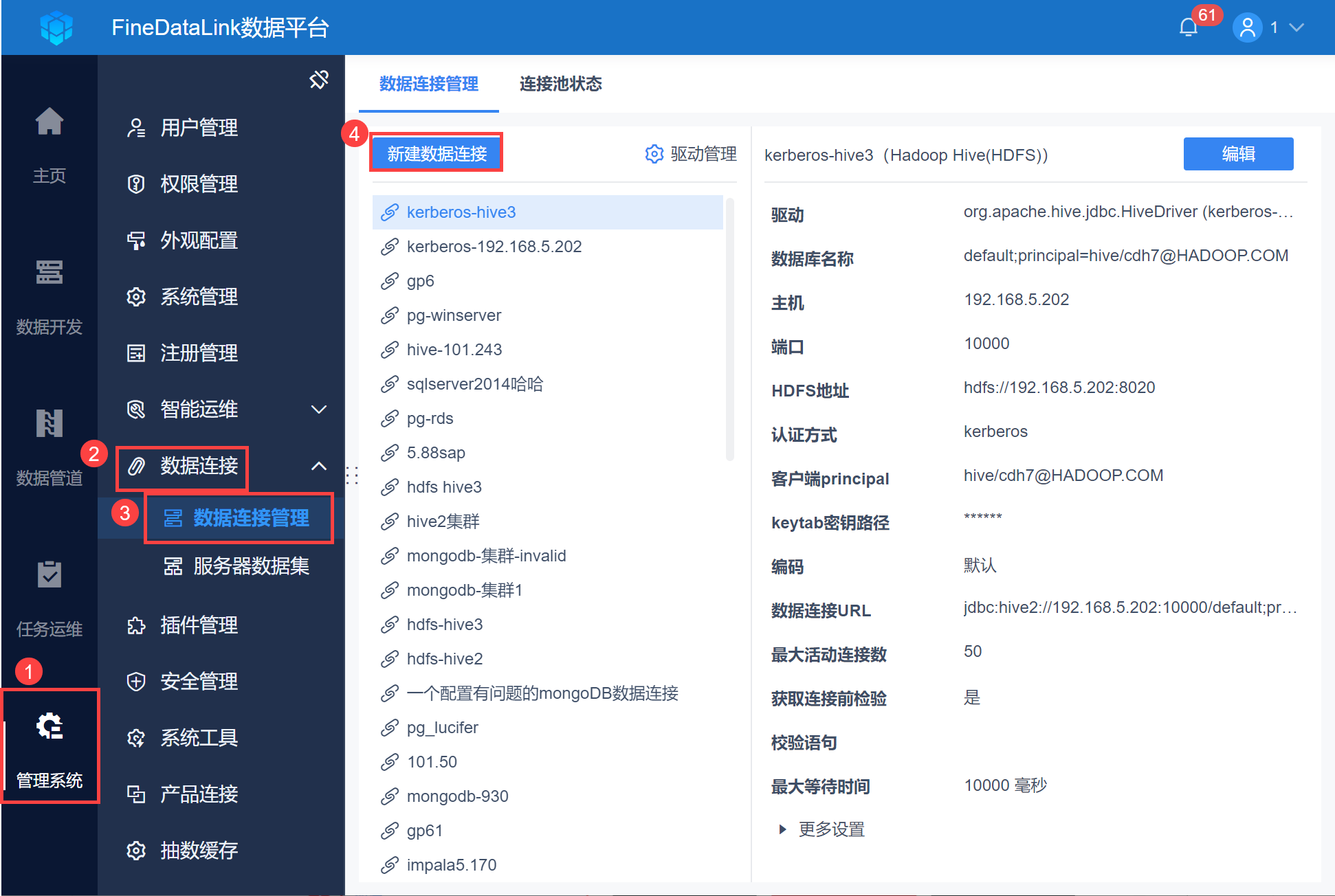
1)以管理员身份登录 FineDataLink ,点击「管理系统>数据连接>数据连接管理」,点击「新建数据连接」,如下图所示:
注:如果非管理员用户想要配置数据连接,需要管理员给其分配管理系统下数据连接节点的权限,具体操作请查看 数据连接管理权限
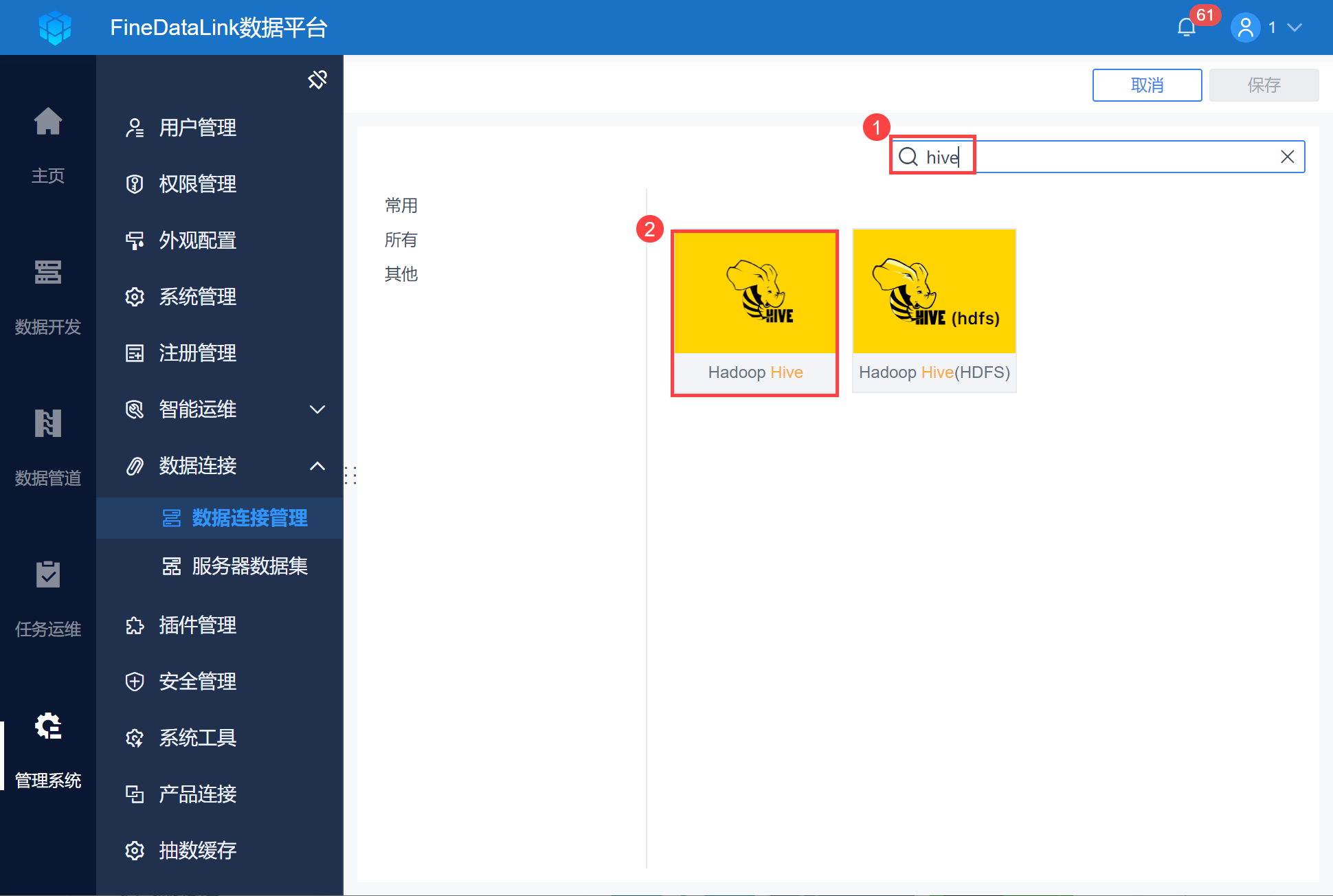
2)找到 Hadoop Hive 数据库,如下图所示:
3)切换驱动为「自定义」选择 2.1 节上传的驱动,并输入 2.2 节收集的连接信息,如下图所示:
Kerberos 认证方式详情可参见:数据连接 kerberos 认证
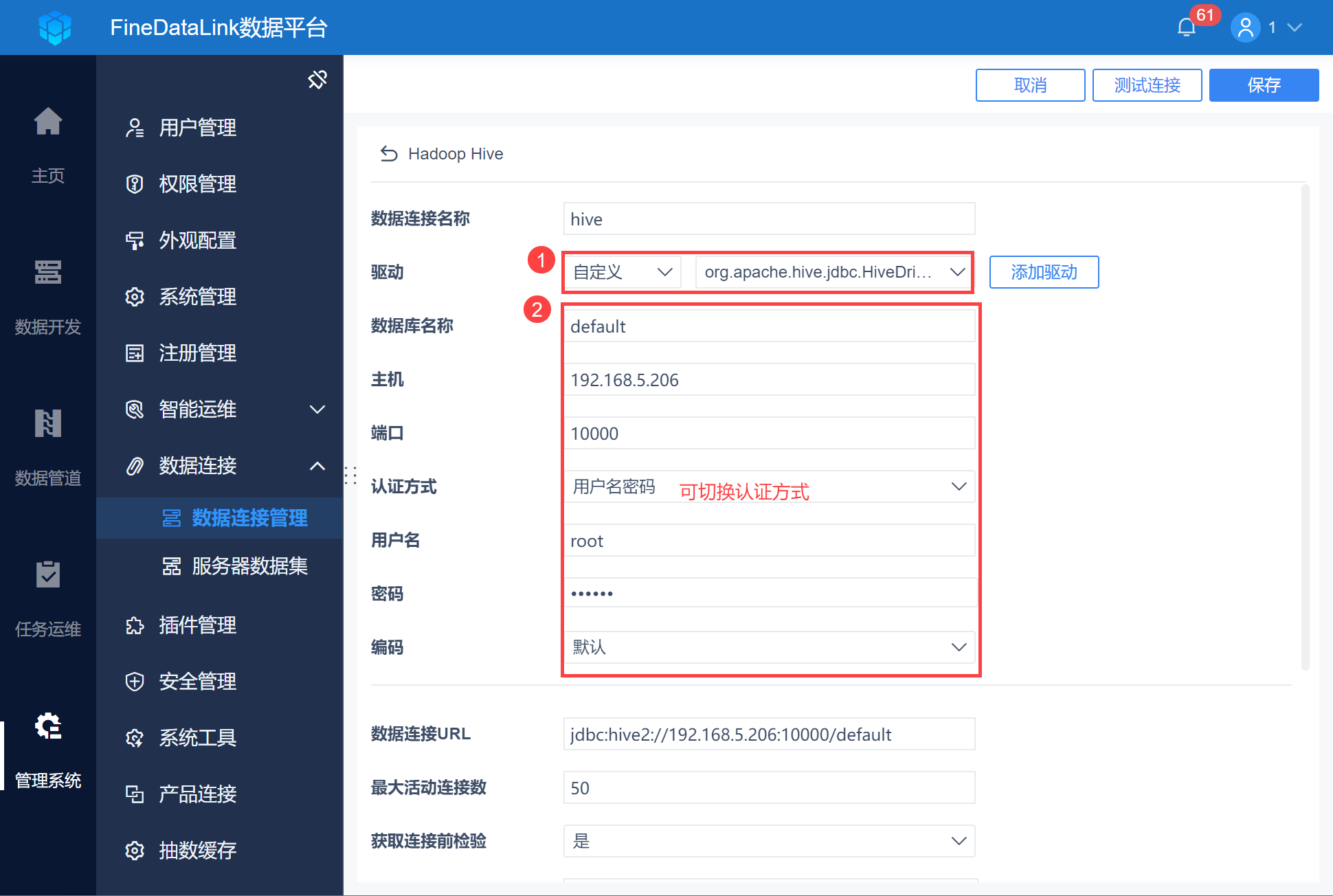
使用 Kerberos 认证需要注意以下事项:
连接前请检查 /etc/hosts 中的机器名对应 IP 是否为局域网 IP;
检查 /etc/hostname 中机器名设置和 /etc/hosts 中是否配置一致;
检查 FineDataLink 所在机器 hosts 配置的 IP+ 机器名是否正确;
本地连接时需要配置 /etc/hosts 文件,添加远端映射:IP+机器名,例如: 192.168.5.206 centos-phoenix 。
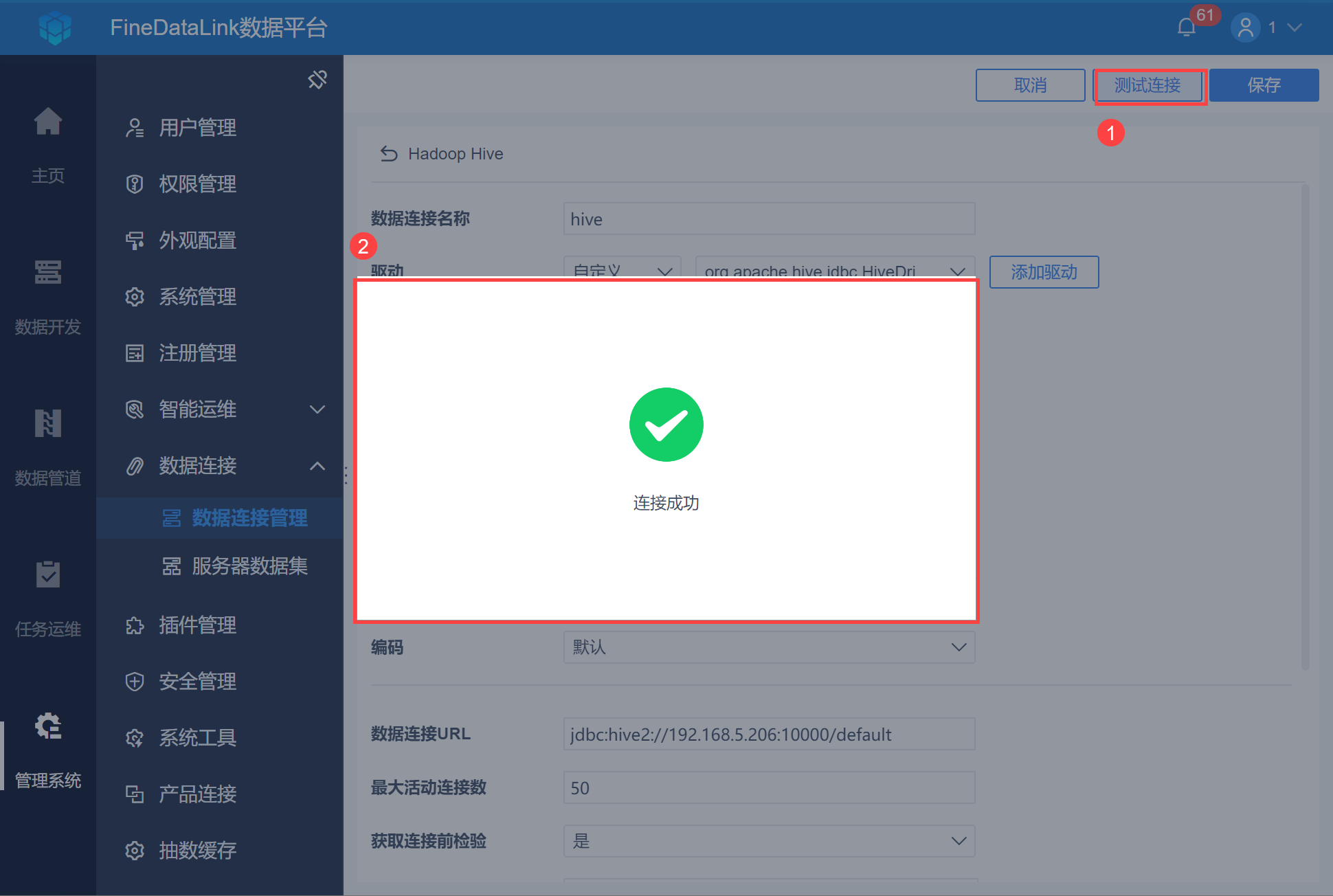
4)点击「测试连接」,若连接成功则点击「保存」,如下图所示: