历史版本2 :数据去重 返回文档
编辑时间:
内容长度:图片数:目录数:
修改原因:
1. 概述编辑
1.1 预期效果
在搭建数据仓库时,可能需要对重复的脏数据进行去重,此时可以使用 SparkSQL 算子中的 GROUP BY 进行处理。
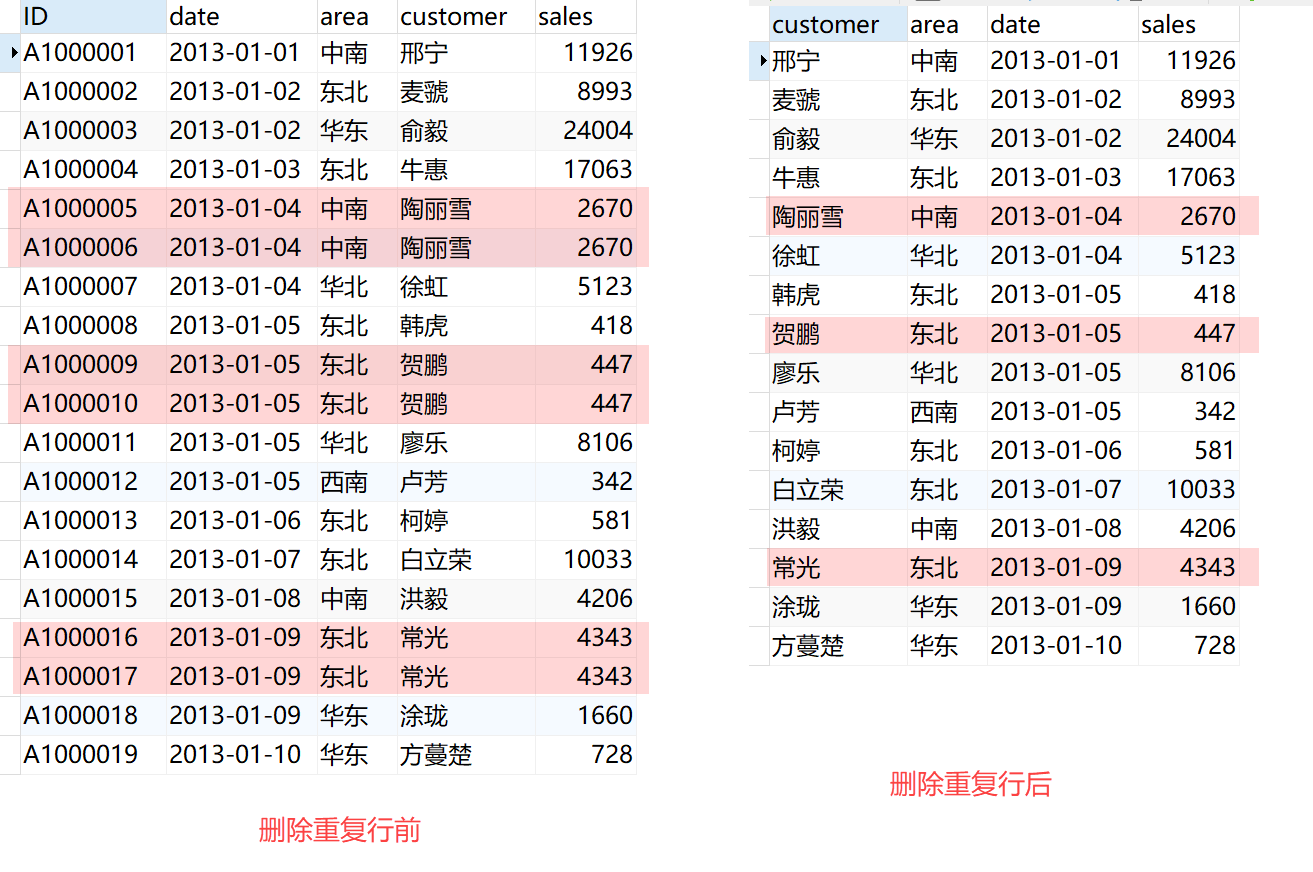
例如:有的订单数据不小心触发了两次,一个订单有两个订单数据,这就形成脏数据,我们可以通过删除重复行功能只保留一行。如下图所示:
1.2 实现思路
使用「Spark SQL」中的 GROUP BY 语法进行去重处理。
2. 操作步骤编辑
示例数据:orderlists.xlsx
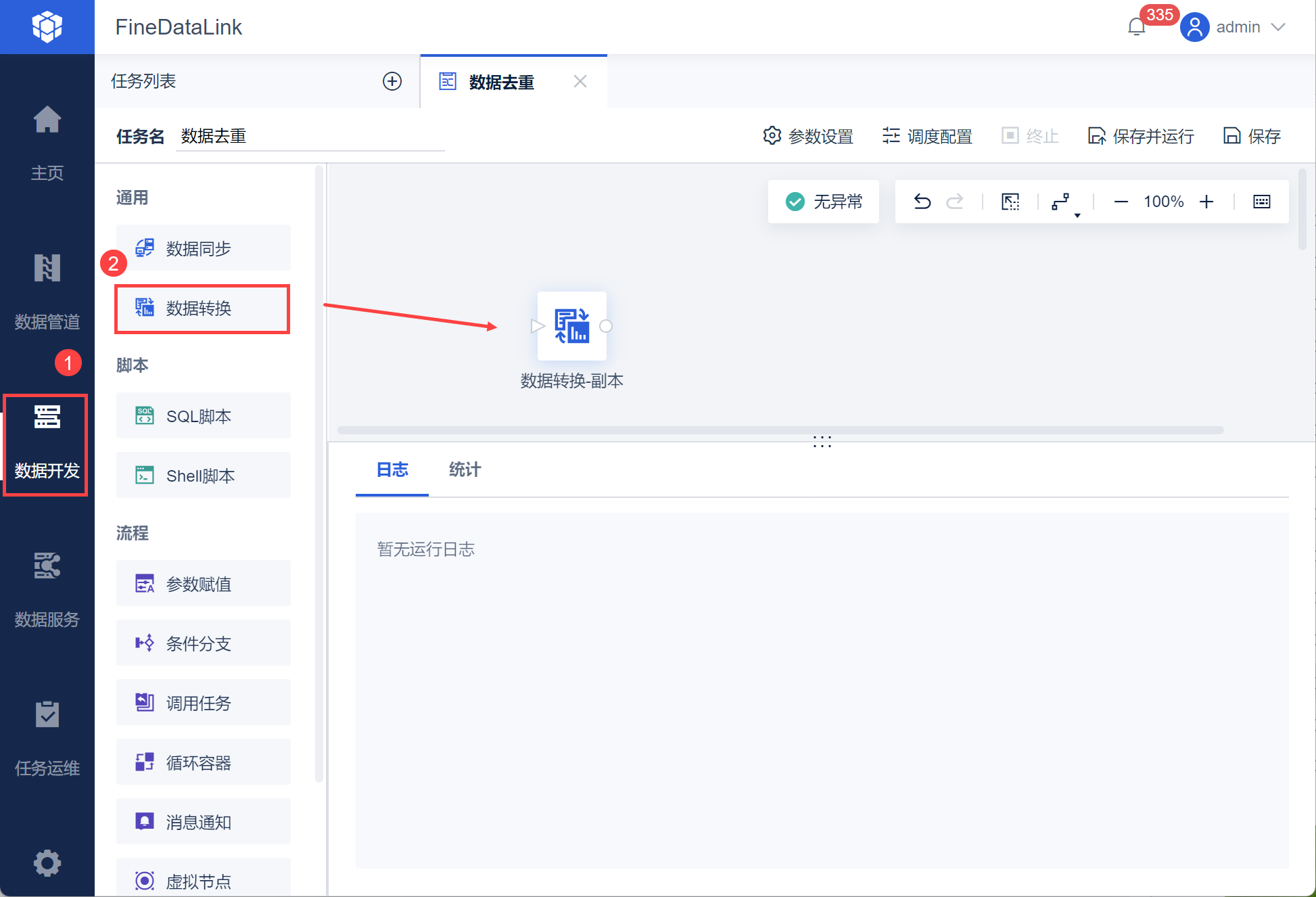
进入数据开发,新建一个定时任务。
在定时任务编辑界面新增一个数据转换节点,如下图所示:
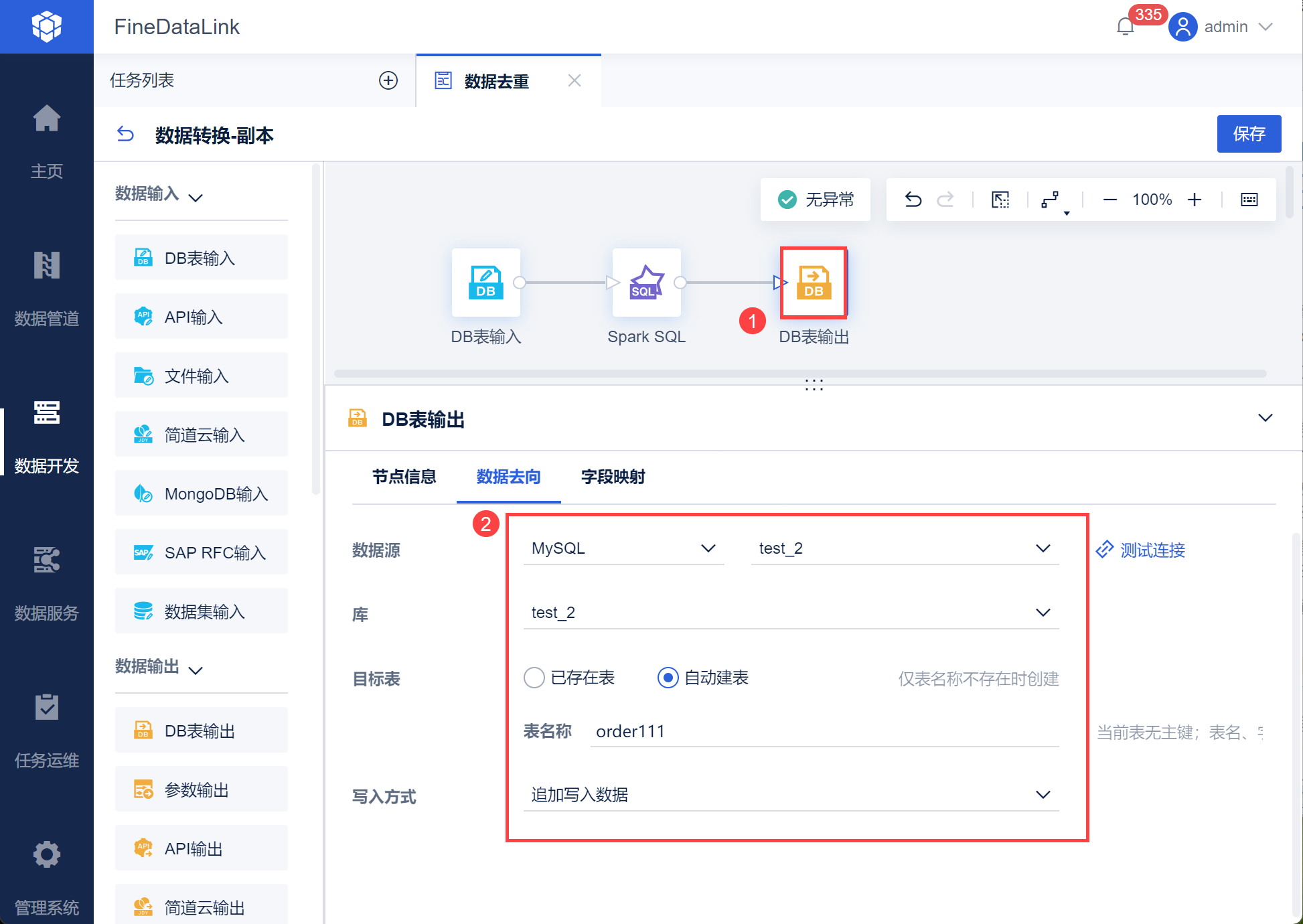
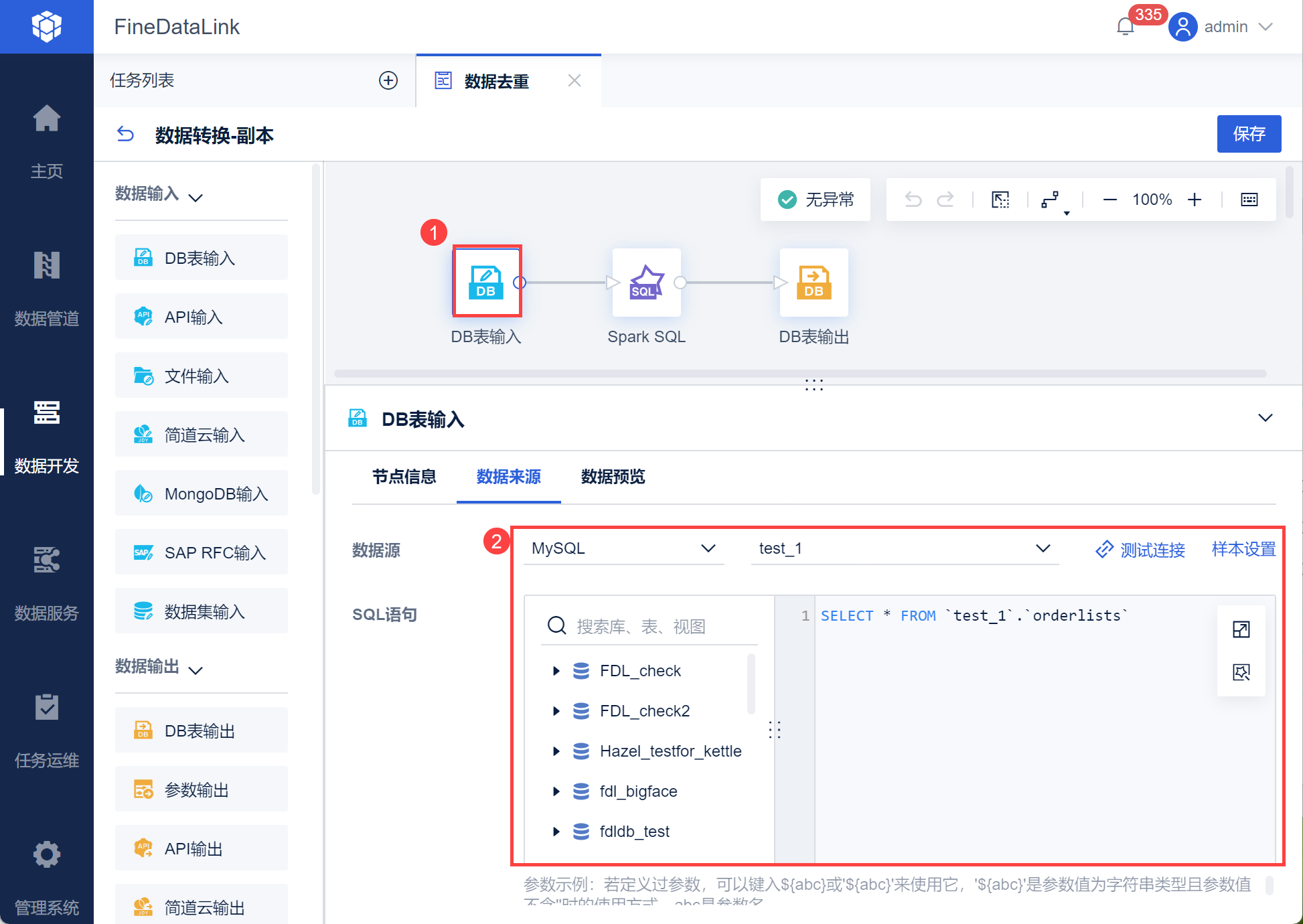
进入数据转换节点,新增DB表输入,取出需要去重的数据表,如下图所示:
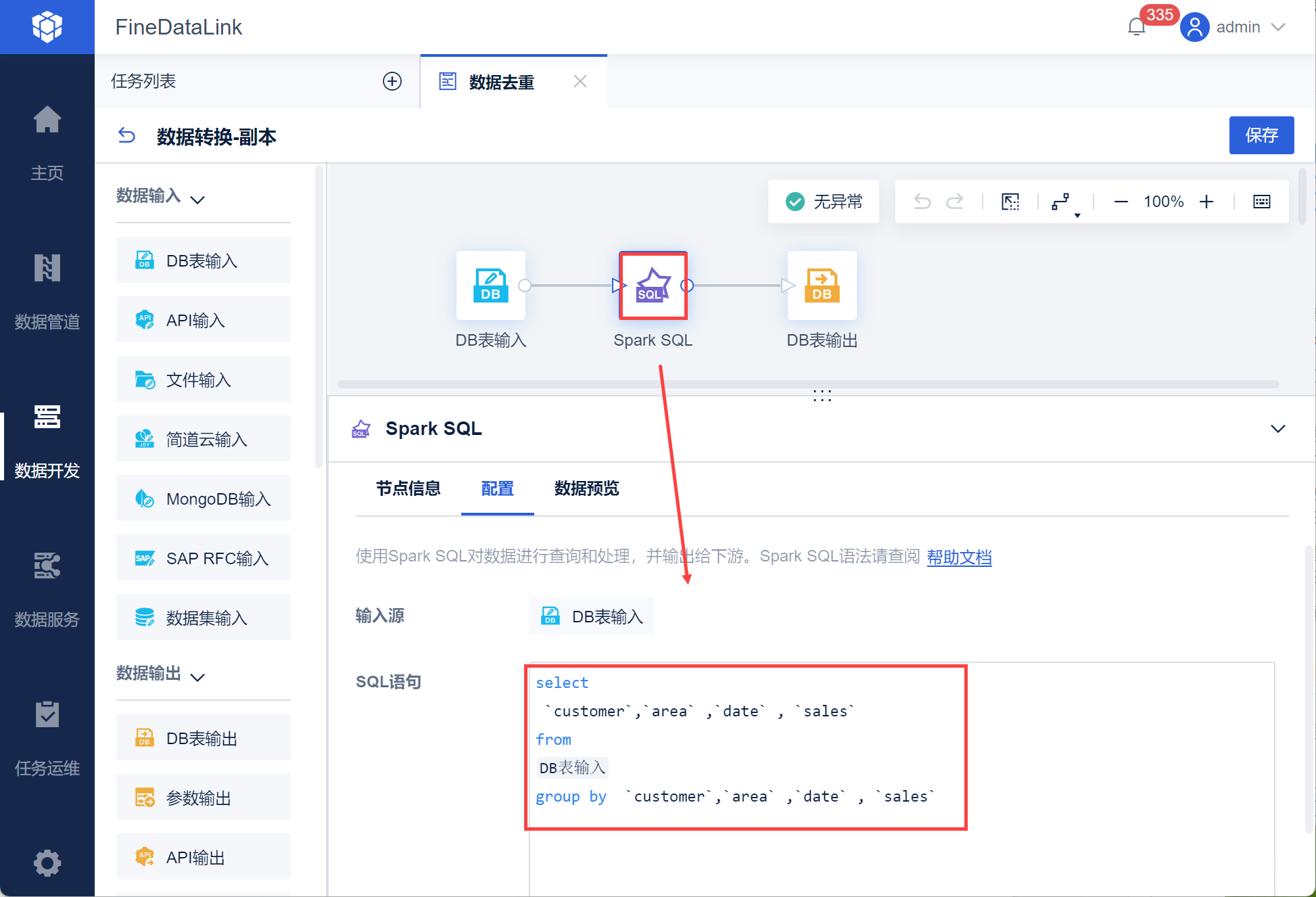
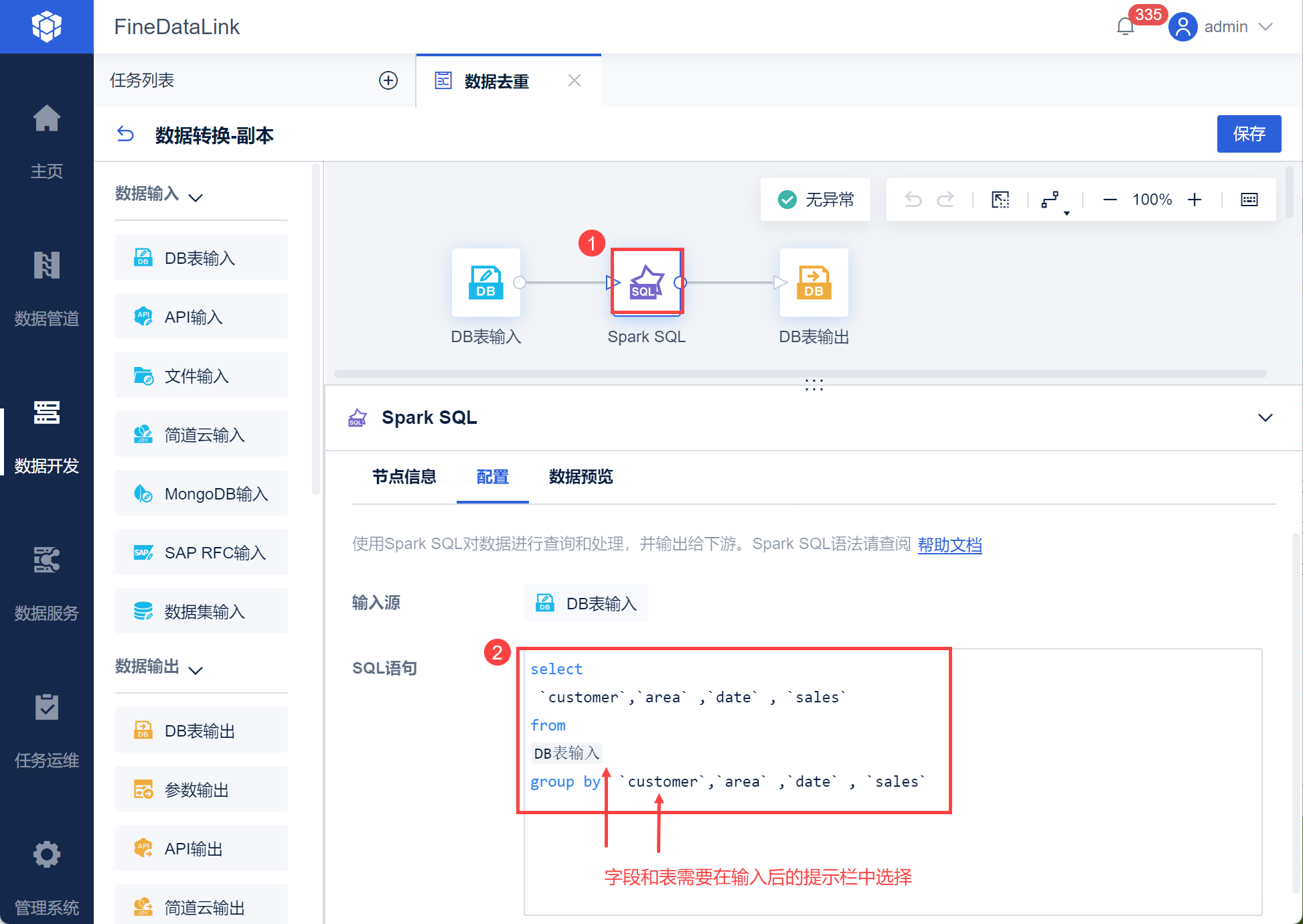
2)新增Spark SQL ,使用 group by 语法对数据进行去重,如下图所示:
select
`customer`,`area` ,`date` , `sales`
from
DB表输入
group by `customer`,`area` ,`date` , `sales`
注:其中查询的数据表、字段需要根据输入提示手动选择,不能直接输入。
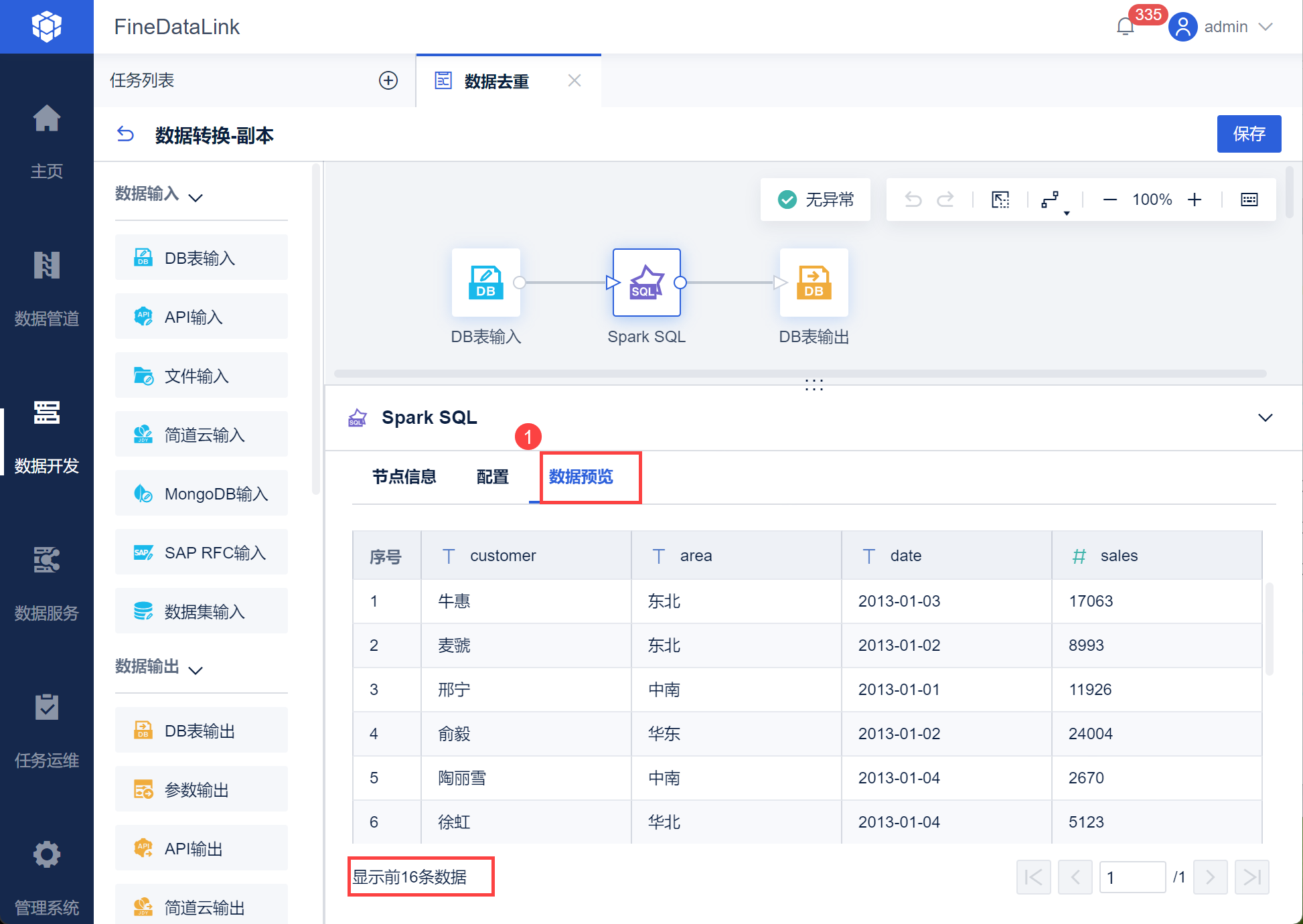
点击数据预览,即可查看到去重后的数据,如下图所示:
然后使用 DB 表输出将去重后的数据输出至指定数据表即可,如下图所示: