1. 概述编辑
1.1 应用场景
公司内部使用企业微信,行政部门想要统计每月员工的打卡数据,将这些数据取出至指定数据库使用。
1.2 接口信息
首先将「通讯录同步」的企业微信人员 userid 和 department 信息从接口中取出,使用 获取成员ID列表 接口直接获取用户的 userid 和 department 数据。
然后调用 获取打卡月报数据 接口,获取指定员工指定时间段内的打卡月报统计数据。
1.3 实现思路
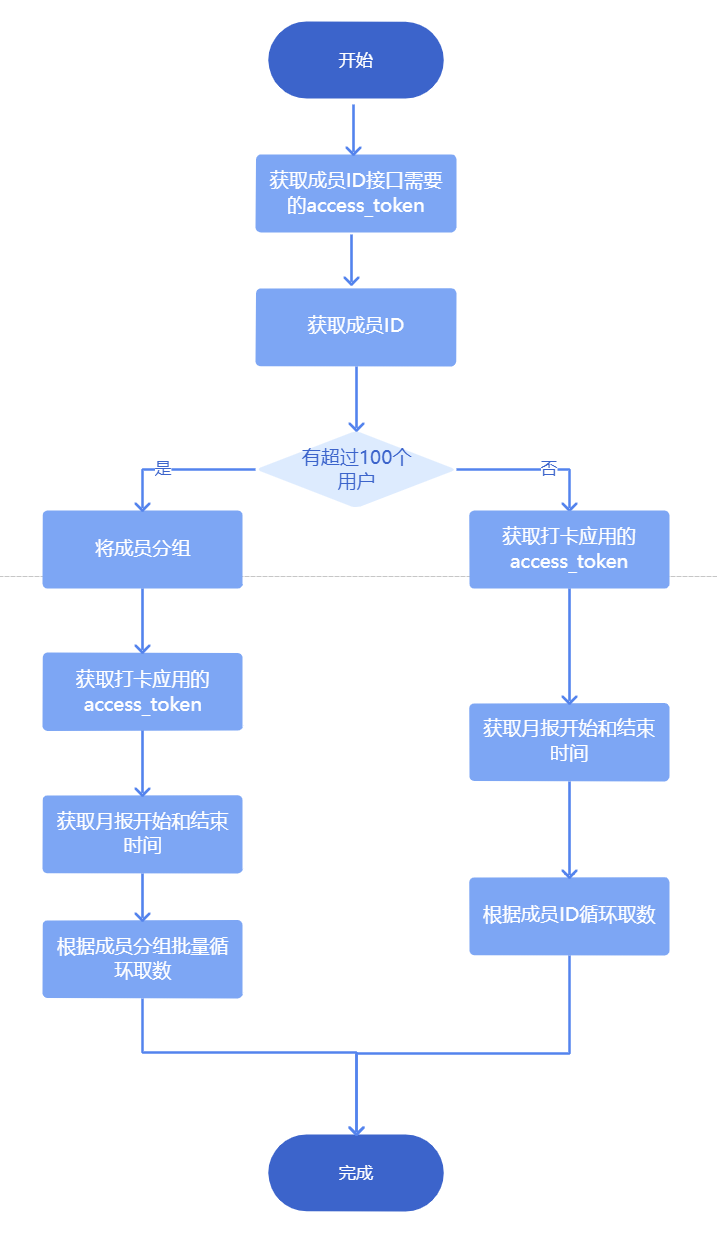
2. 操作步骤编辑
本示例介绍成员数量较多情况下的方案,若不需要对用户进行分组,则直接将用户的 userid 设置为参数,并在循环容器中取数即可。
2.1 获取 access_token 并设置为参数
2.1.1 获取access_token
由于获取月报打卡数据首先需要企业微信成员用户的 userid,因此需要为了使用 获取成员ID列表 接口获取成员ID,需要先获取 acces_token,获取 access_token 是调用企业微信 API 接口的第一步,相当于创建了一个登录凭证,其它的业务 API 接口,都需要依赖于 access_token 来鉴权调用者身份。
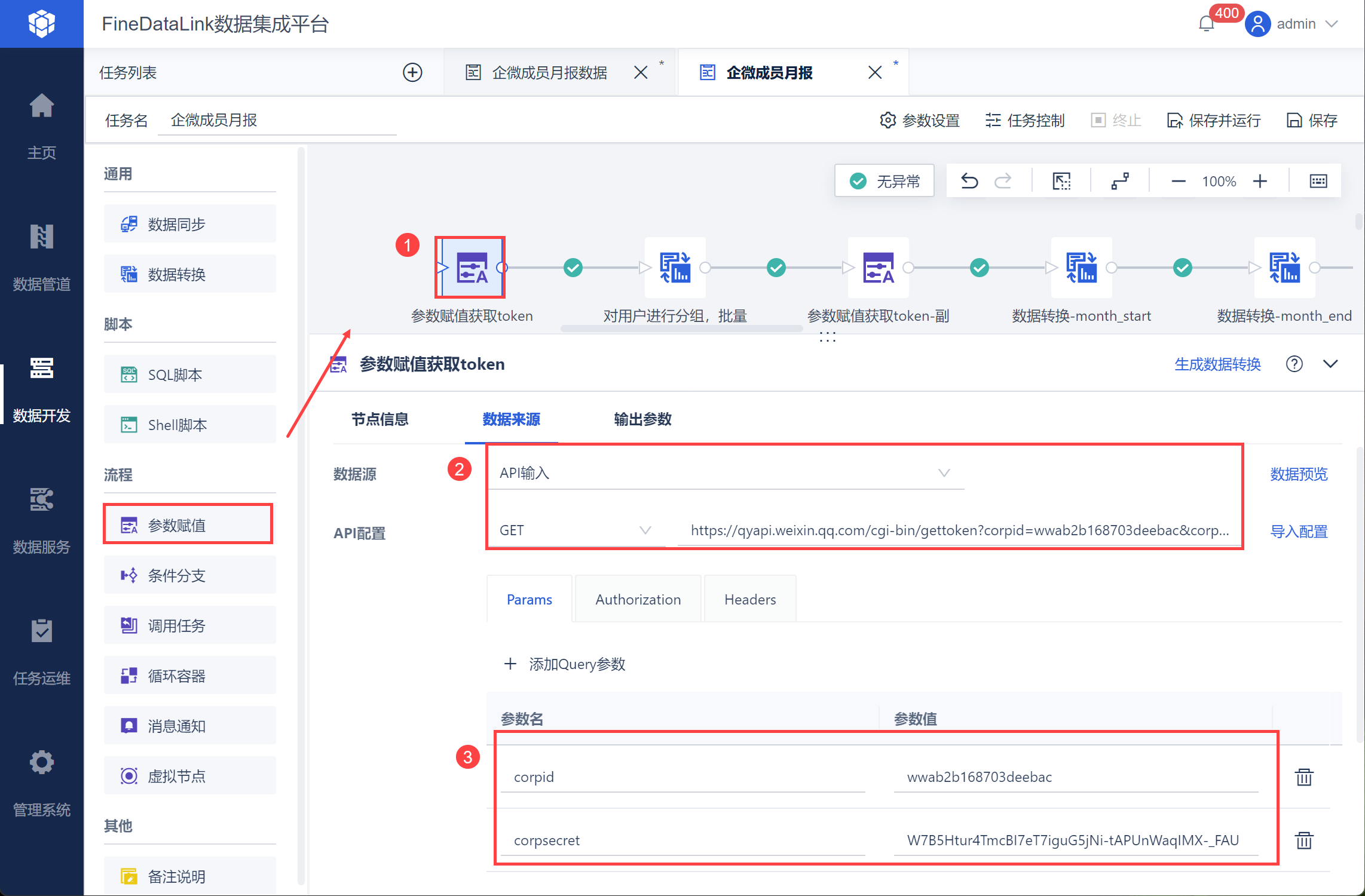
使用参数赋值节点,在节点信息中修改名称为「获取token」,选择数据源类型为「API」,将企业微信接口 获取 access_token url 和参数写入对应位置,:https://qyapi.weixin.qq.com/cgi-bin/gettoken?corpid=ID&corpsecret=SECRET,如下图所示:
注:corpsecret 一定要是通讯录管理secret,详情参见:通讯录管理
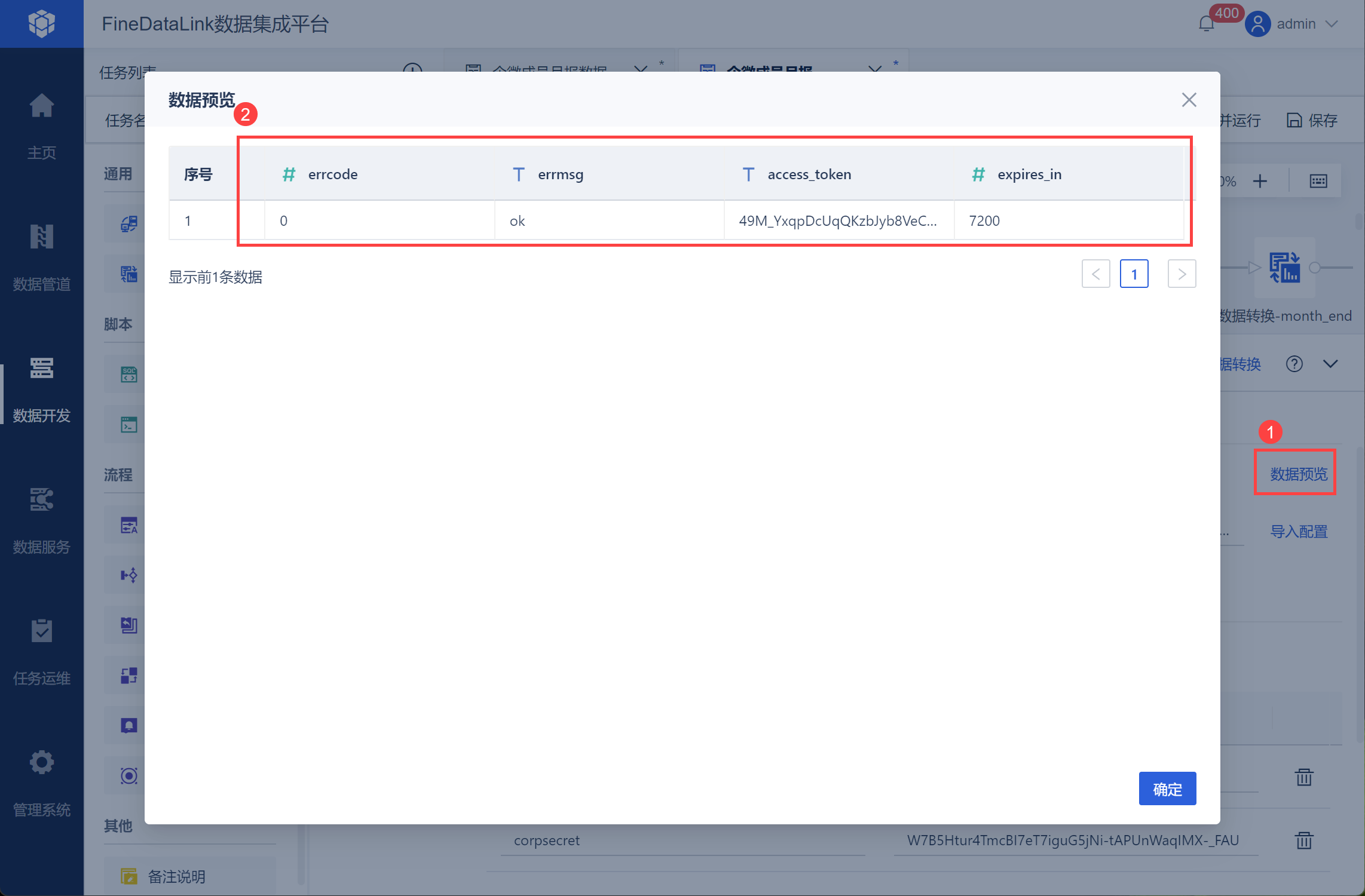
点击「数据预览」即可看到获取的 access_token,如下图所示:
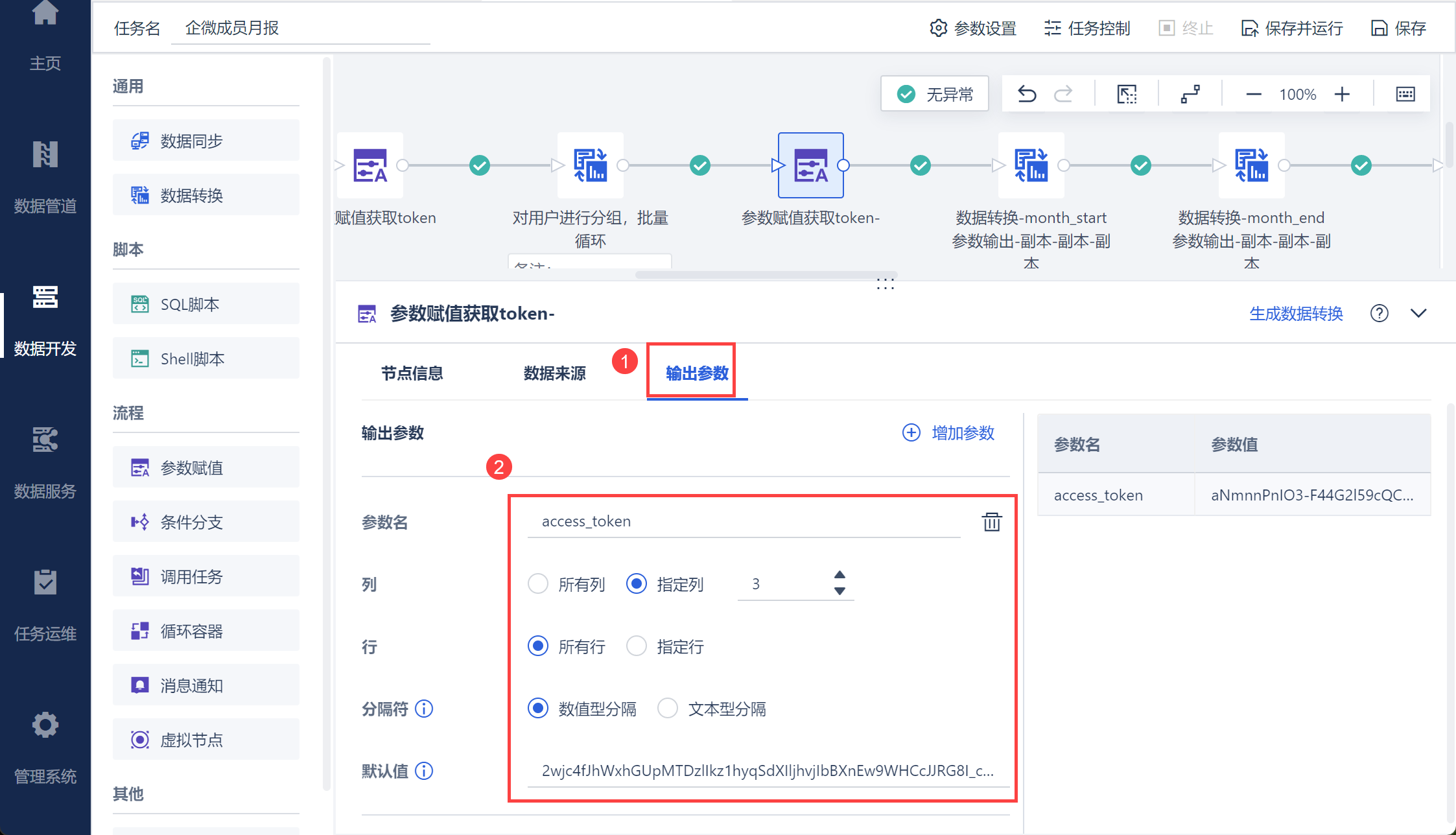
2.1.2 将 access_token 设置为参数
为了便于后续其他接口使用获取到的 token 值,因此将其设置为参数。
点击「输出参数」设置参数名为 access_token1,将 access_token 设置为参数,如下图所示:

2.2 获取成员ID
通过 获取成员ID列表 接口,获取所有的企业微信成员 userid 和 department。
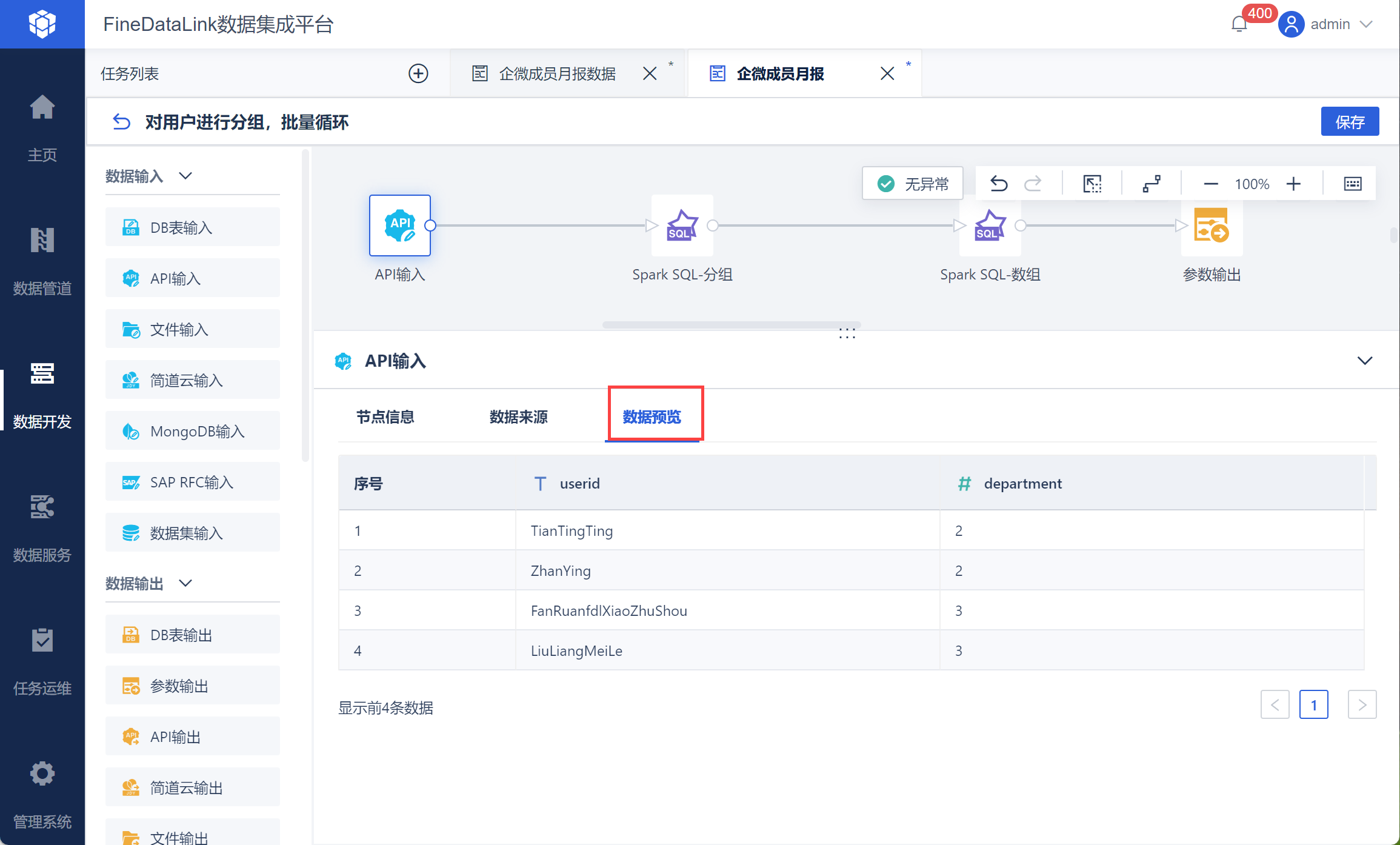
新增「数据转换」节点,在节点信息中可以修改名称。进入数据转换编辑界面,新增API 输入算子,将企业微信接口 获取成员ID列表url 和参数写入对应位置:https://qyapi.weixin.qq.com/cgi-bin/user/list_id?access_token=${token},并取出$.dept_user 数组,如下图所示:

点击数据预览即可看到取出的 userid 和 department 数据,如下图所示:
2.3 将成员分组
由于 获取打卡月报数据 接口 useridlist 用户列表参数,最多可传输100个用户,如果当前企业有超过100个用户,需要先对从获取成员ID列表接口中读取的数据对成员进行分组,再循环读取成员月报打卡数据。
在 API 输入后新增 SparkSQL 节点,输入一下语法,即将 userid 分成两组,并命名为 group_id:
SELECT userid , ceil(row_number() OVER (ORDER BY userid ) / 2) as group_id
FROM API输入
注1:如果用户数较多,可以将 SparkSQL 中 2 调大,减少分组次数。
注2:API输入表需要点击输入源,不能手动输入。
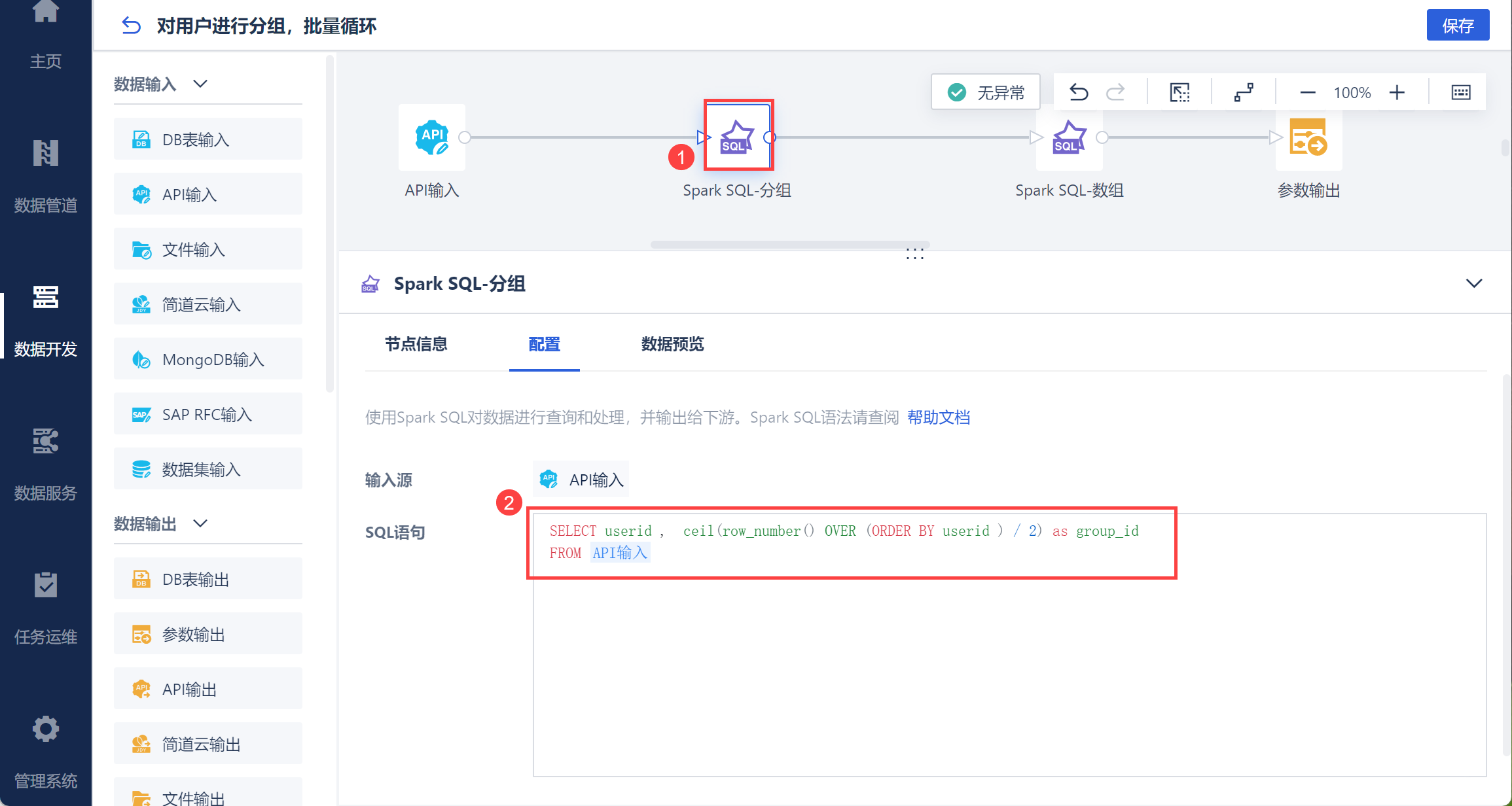
点击「数据预览」获取到新的分组列 group_id,如下图所示:
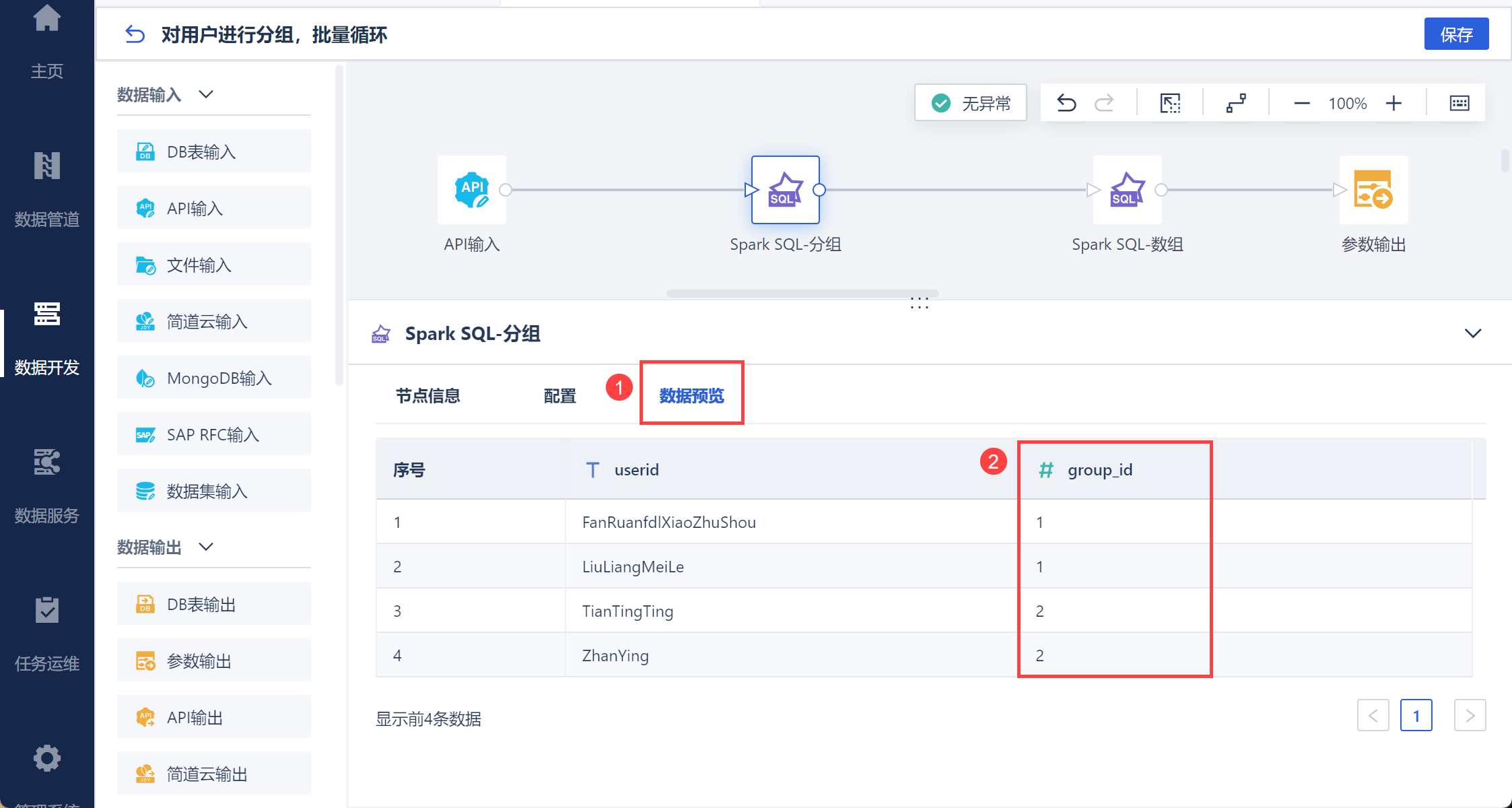
由于分组后的成员 userid 会在后续使用循环容器中依次传入取出打卡数据,我们这里按照 group_id 分组将 userid 分成多个数组,以便后续按照 group_id 将 userid 批量传入循环容器,如下图所示:
SQL 语句:
select
`group_id` ,
concat('"', concat_ws('","',collect_list(userid )) , '"') as list
from
Spark SQL-分组
group BY
`group_id`
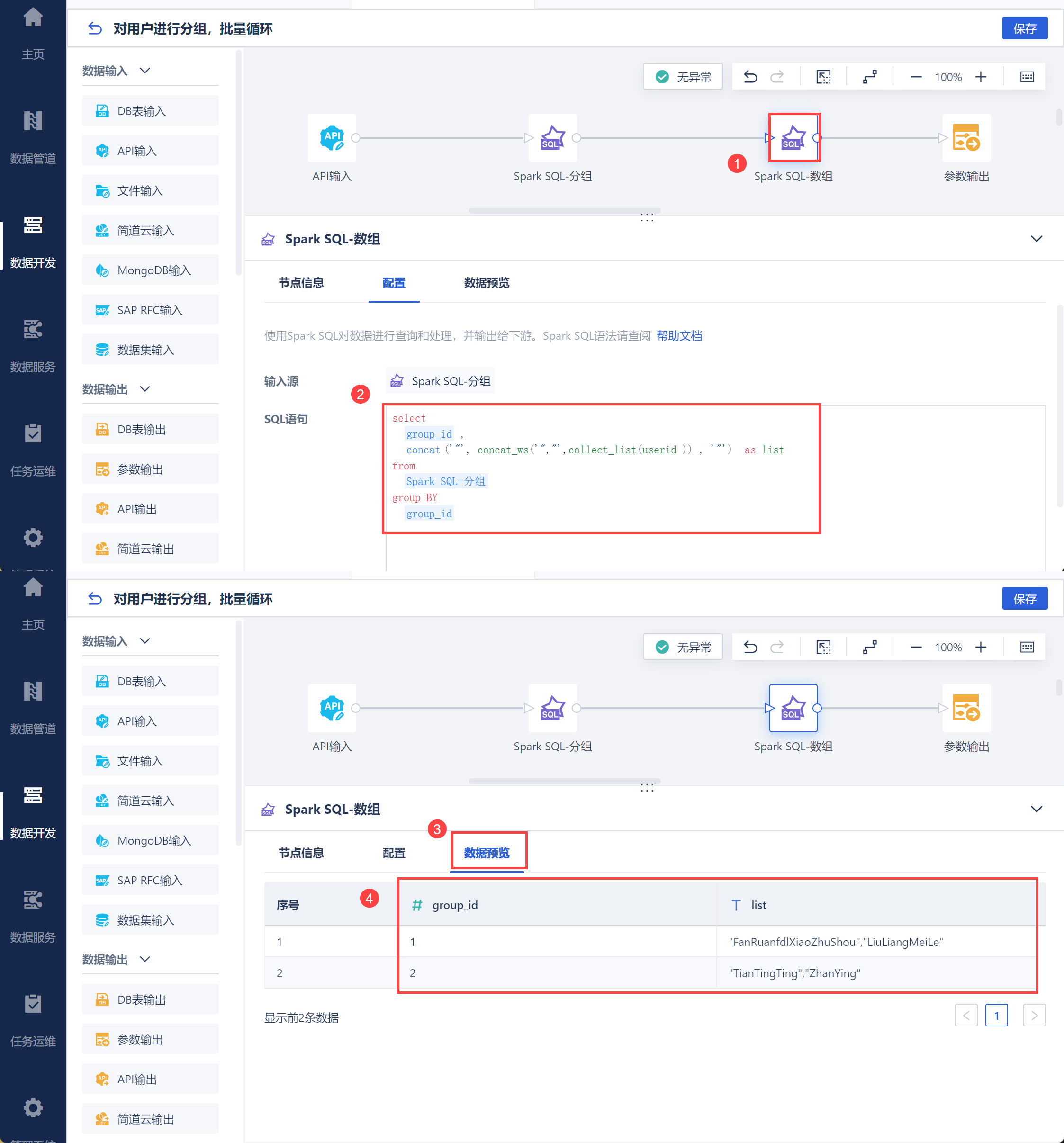
新增「参数输出」算子,将分好组的 userid 设置为参数,如下图所示:

注:若不需要对用户进行分组,则直接将用户的 userid 设置为参数即可,后续 2.6 节循环容器中取数带入该参数即可。
2.4 使用打卡应用的Secret获取access_token
由于获取打卡月报数据 接口中的 access_token 使用打卡应用的Secret获取,因此再次使用参数赋值,如下图所示:
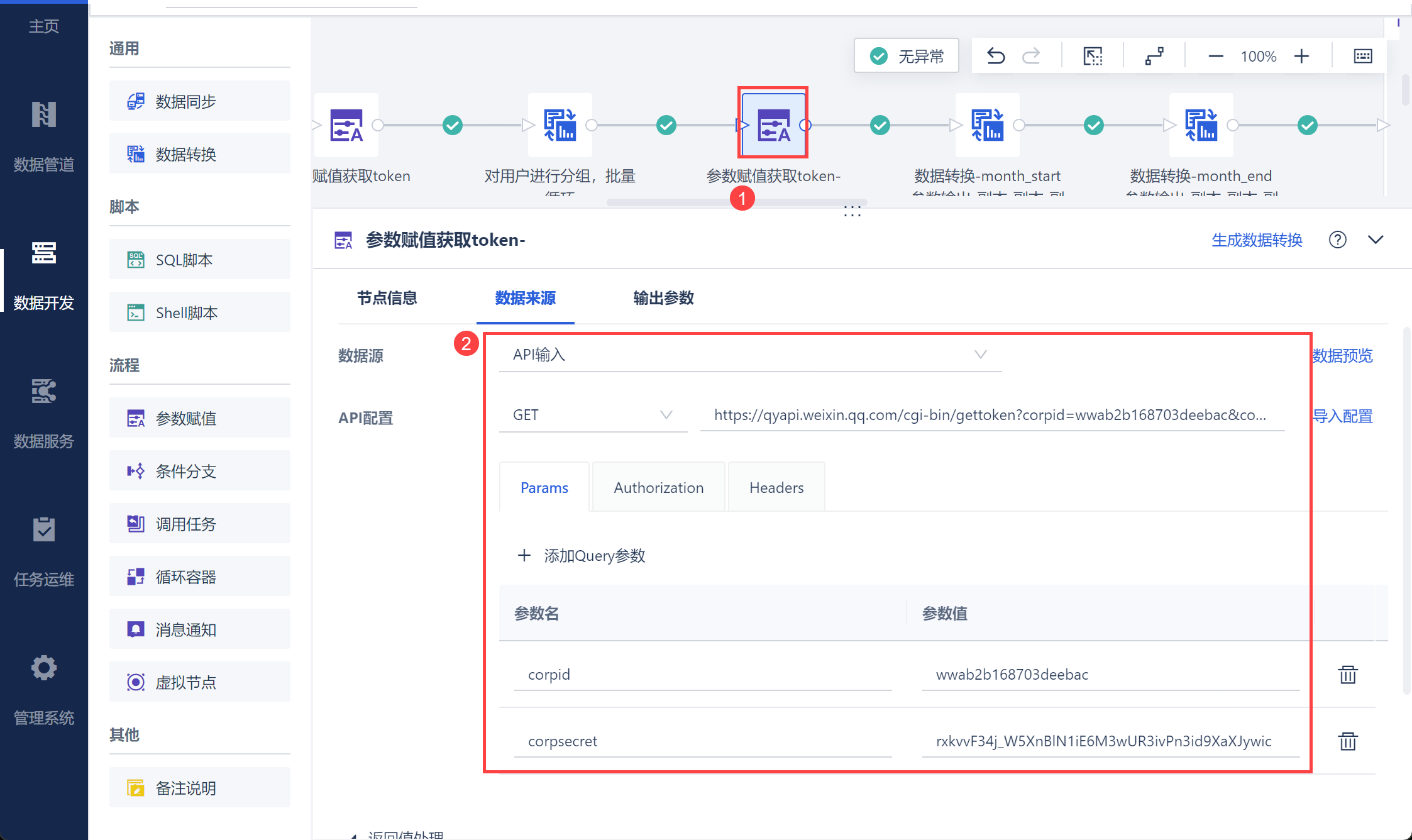
将其设置为参数,便于后续取出打卡数据,如下图所示:
2.5 获取月报开始和结束时间
获取打卡月报数据 需要获取月报的开始时间和结束时间,因此使用 SparkSQL 创建开始时间和结束时间,并将其设置为参数,如下图所示:
新建「数据转换」节点,进入编辑界面后新建 SparkSQL ,输入语句获取当前月份第一天的时间戳,如下图所示:
语句:
SELECT unix_timestamp(date_trunc('month', current_date())) AS month_start
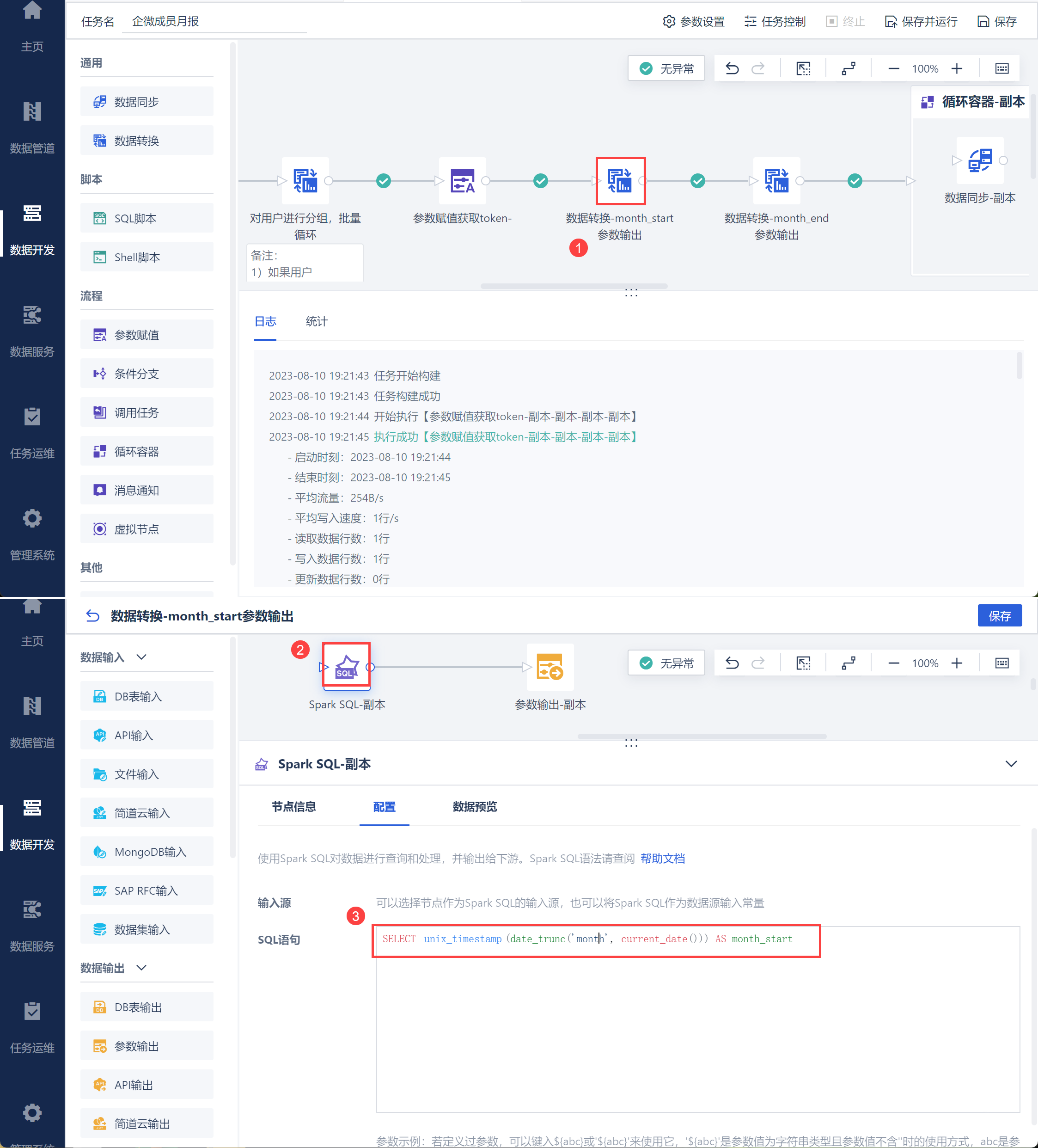
点击数据预览,即可看到当前月份第一天的时间戳,并新增「参数输出」算子,将其设置为参数 month_start,如下图所示:

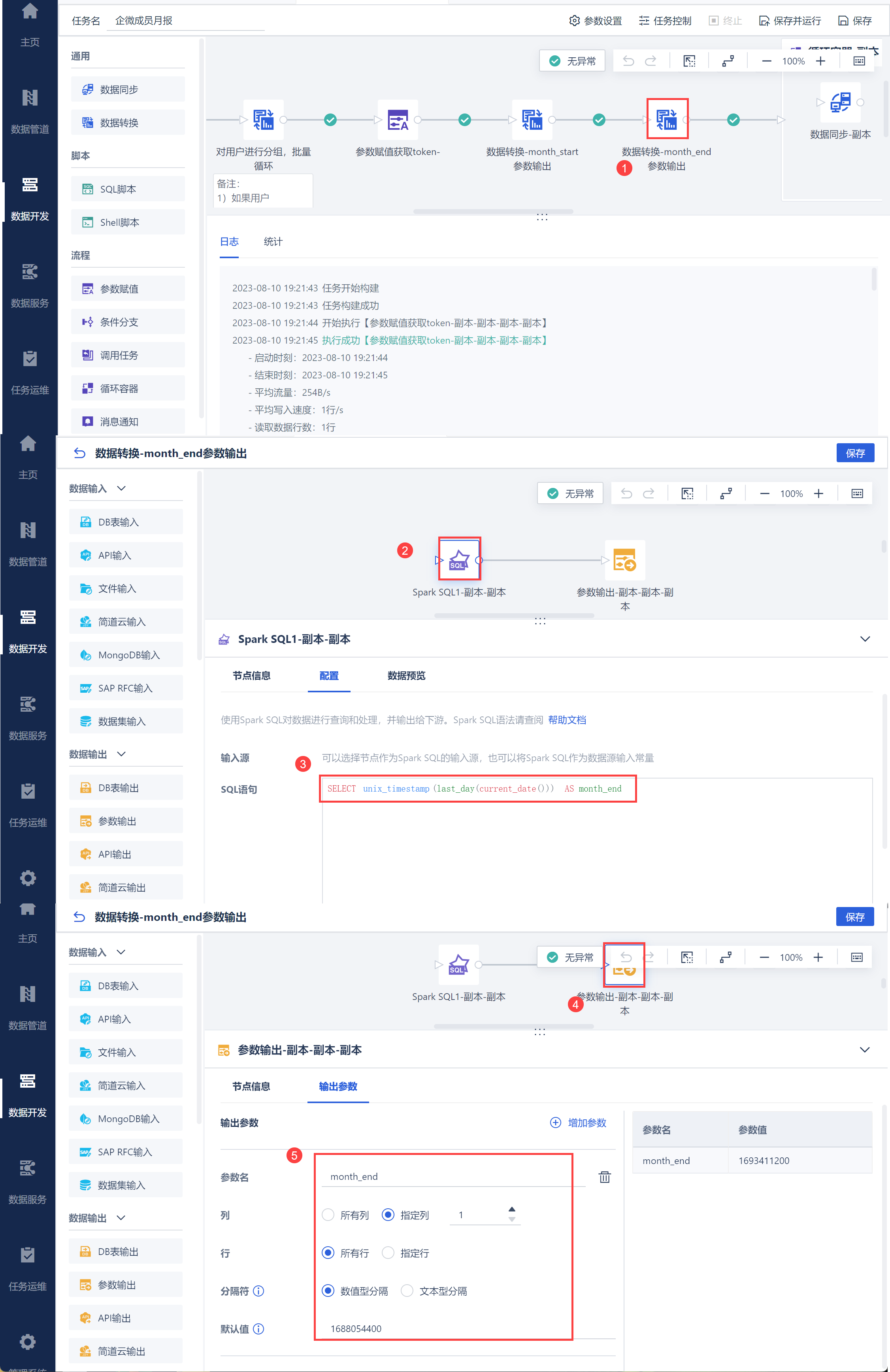
同理,设置月报结束时间为当月最后一天的时间戳,并将其设置为参数 month_end ,如下图所示:
SQL语句:
SELECT unix_timestamp(last_day(current_date())) AS month_end
2.6 根据成员分组批量循环取数
新增「循环容器」节点。连线相连并勾选遍历对象为 list,也就是按照 3.2 节的分组批量传入接口取出不同用户的月报打卡数据,如下图所示:
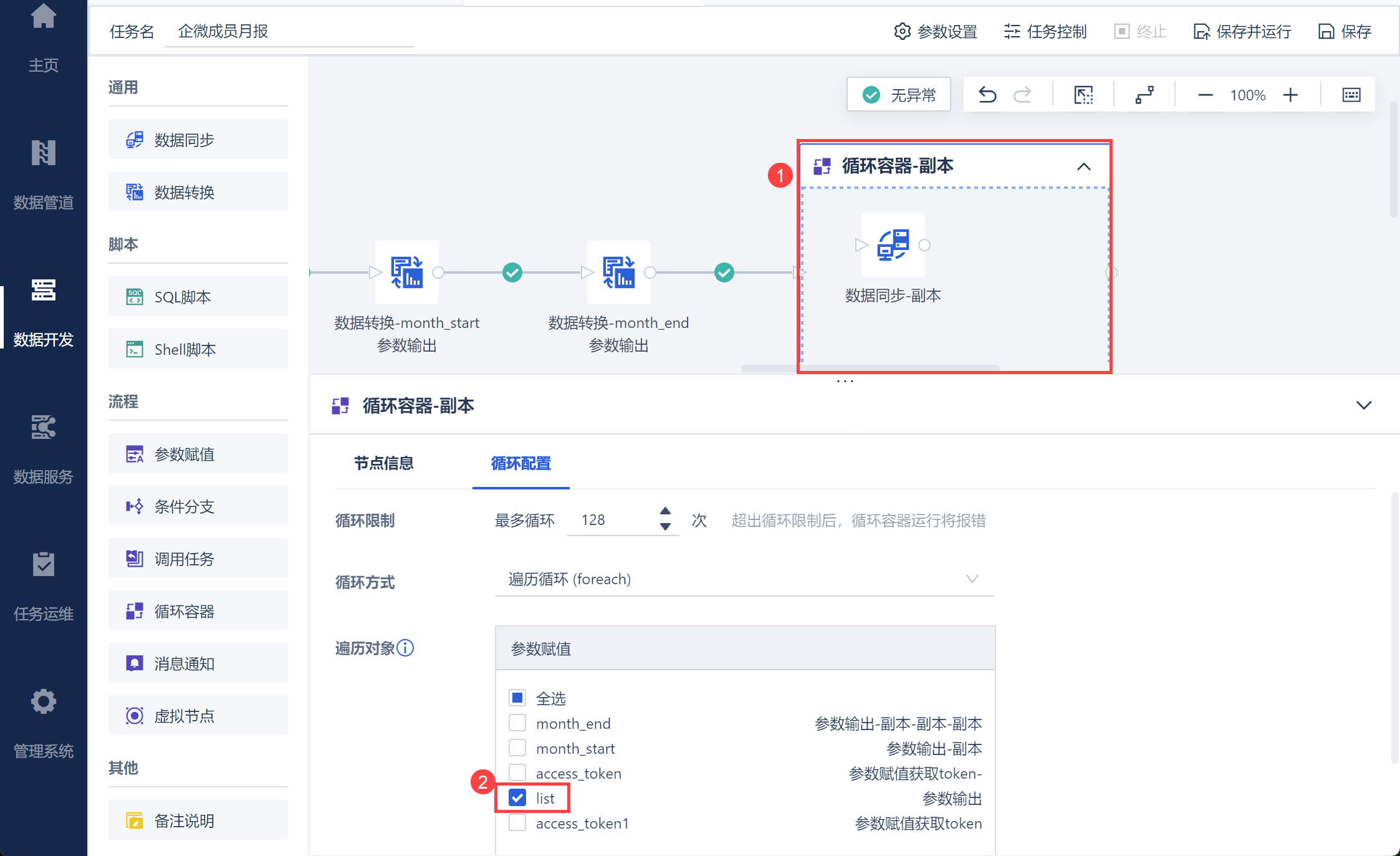
在循环容器中拖入「数据同步」节点,输入 获取打卡月报数据 接口,并写入 2.4 节获取的打卡应用 access_token,如下图所示:

在 Body 中选择格式,并输入请求,然后再返回值中设置需要取出的 JSON 部分即可,如下图所示:
请求语句:
{
"opencheckindatatype": 3,
"starttime": ${month_start},
"endtime": ${month_end},
"useridlist": [${list}]
}
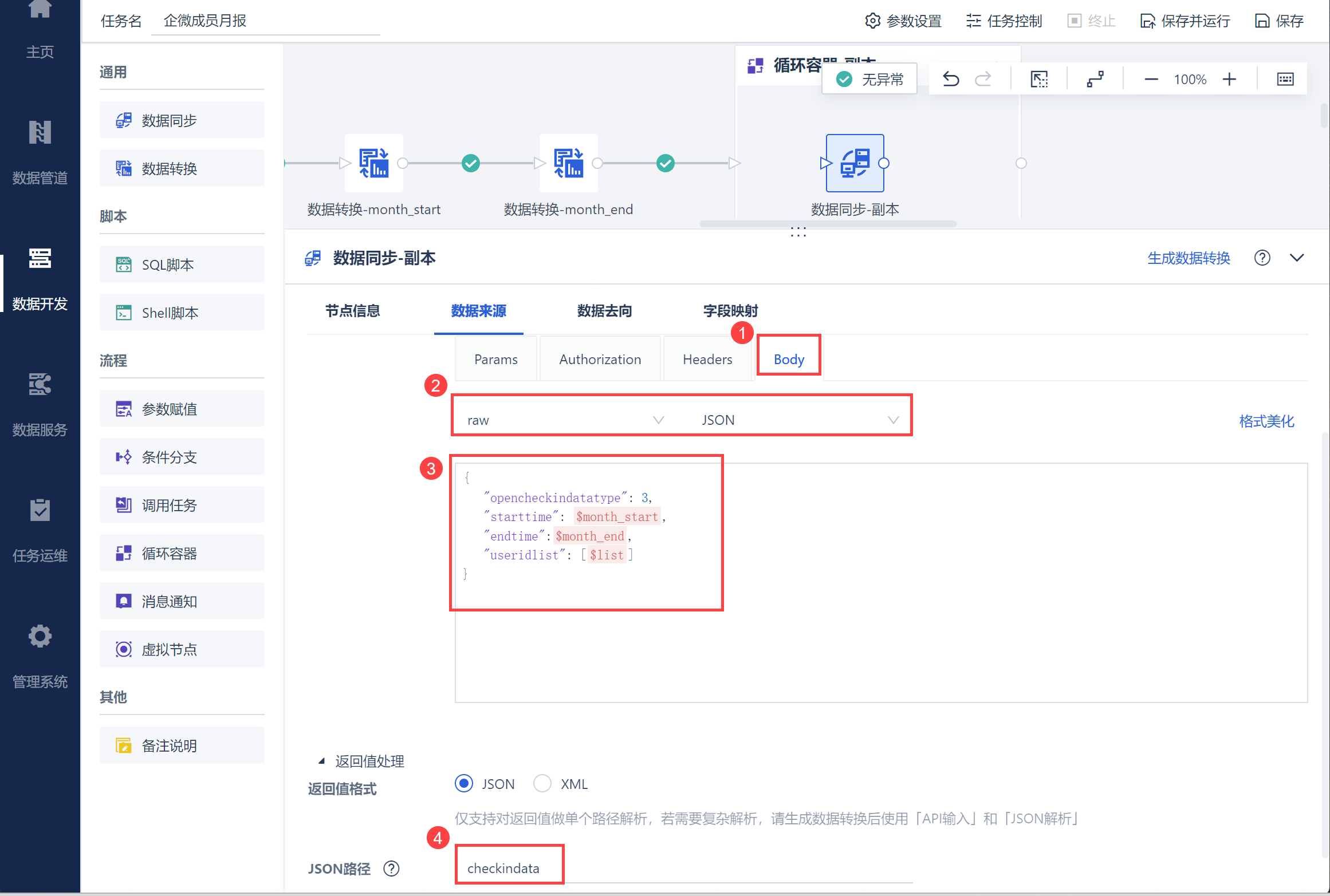
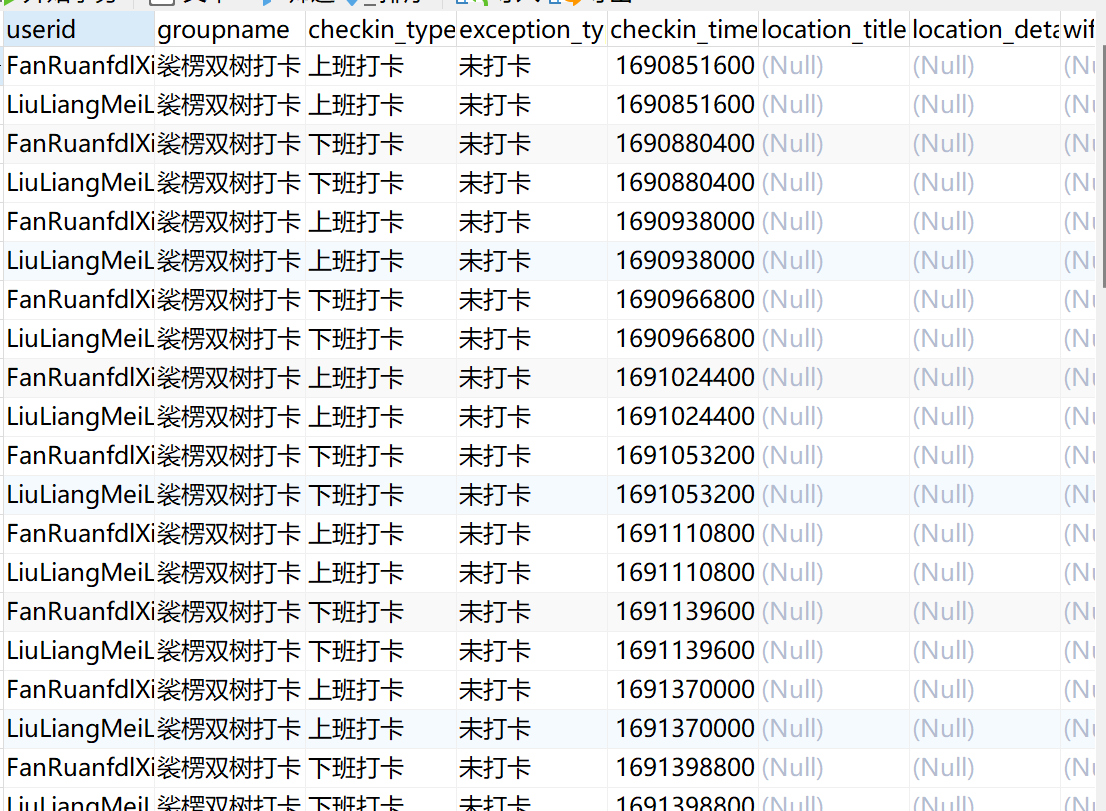
点击「数据预览」即可看到取出的打卡数据,如下图所示:
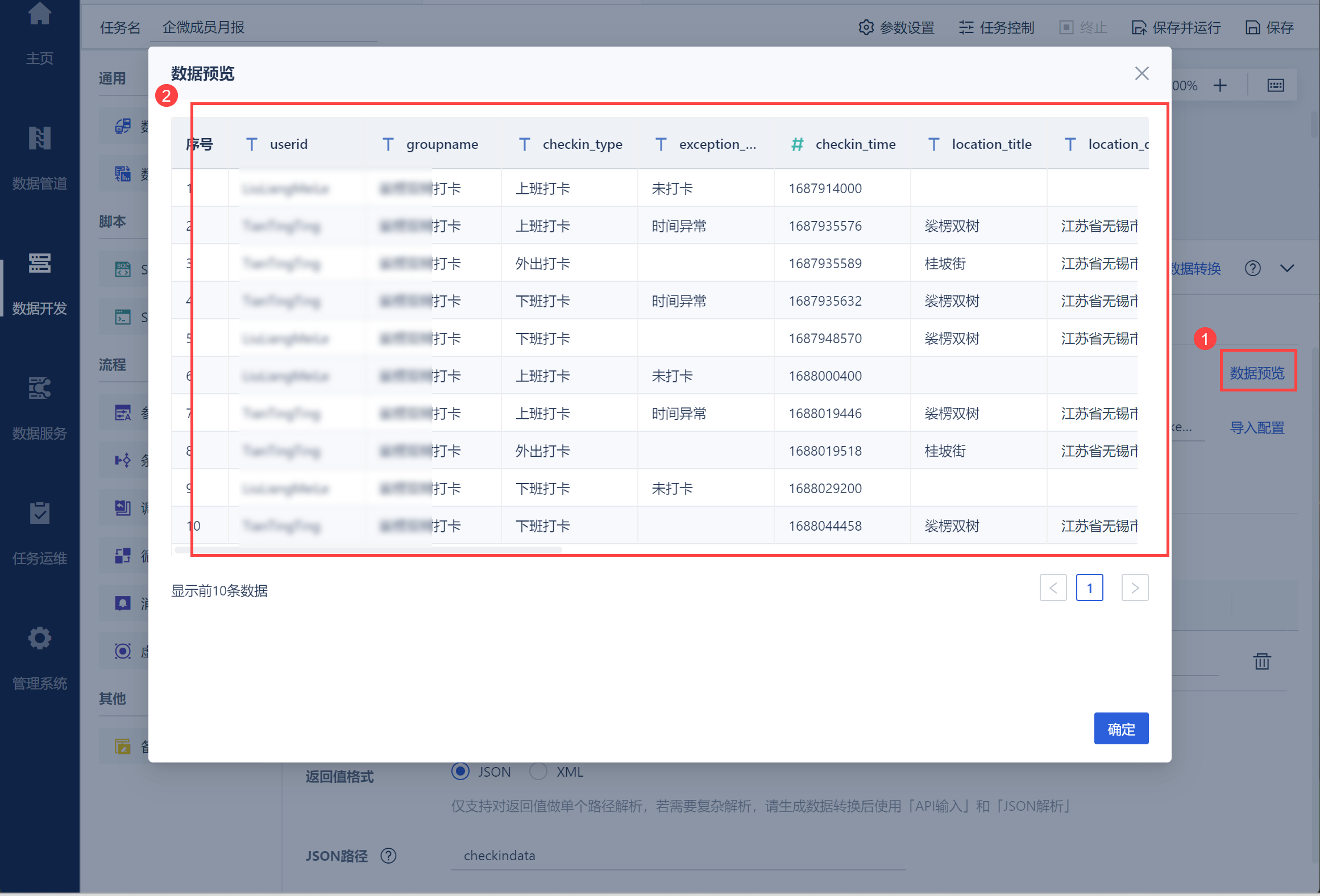
然后将数据输出至指定数据库即可,如下图所示:

2.7 运行任务
保存并运行任务即可看到数据库中取出的月报打卡数据,如下图所示: