4.1.3 以及之后的版本支持的方案。
1. 概述编辑
1.1 应用场景
某企业现在需要将某业务工单数据全部取出以供业务分析使用。
API取数-按页数取数 中可以使用页数和内置参数 loopTimes 进行取数。
但是如果遇到接口中需要使用业务参数,需要遍历业务参数的同时也进行分页取数,则需要使用分页取数+循环容器的方案。
1.2 接口说明
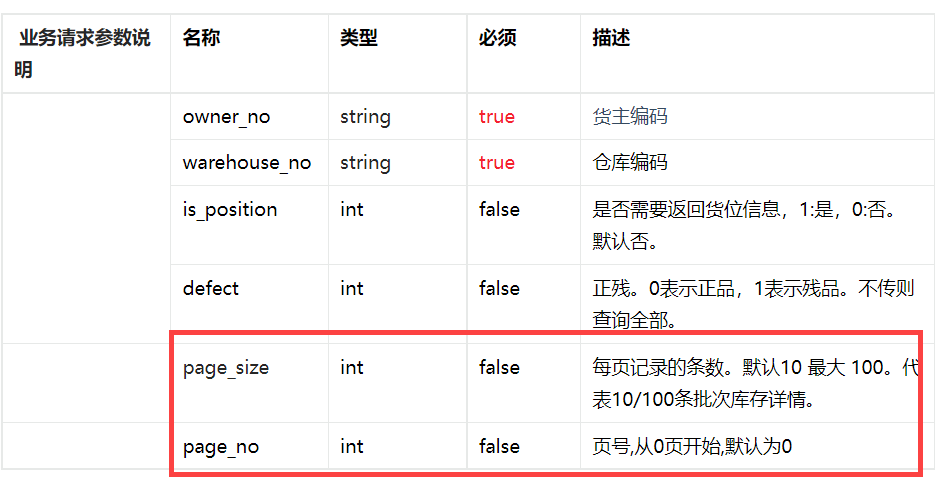
接口文档详情参见:慧策-WMS库存全量查询接口
1.3 实现思路
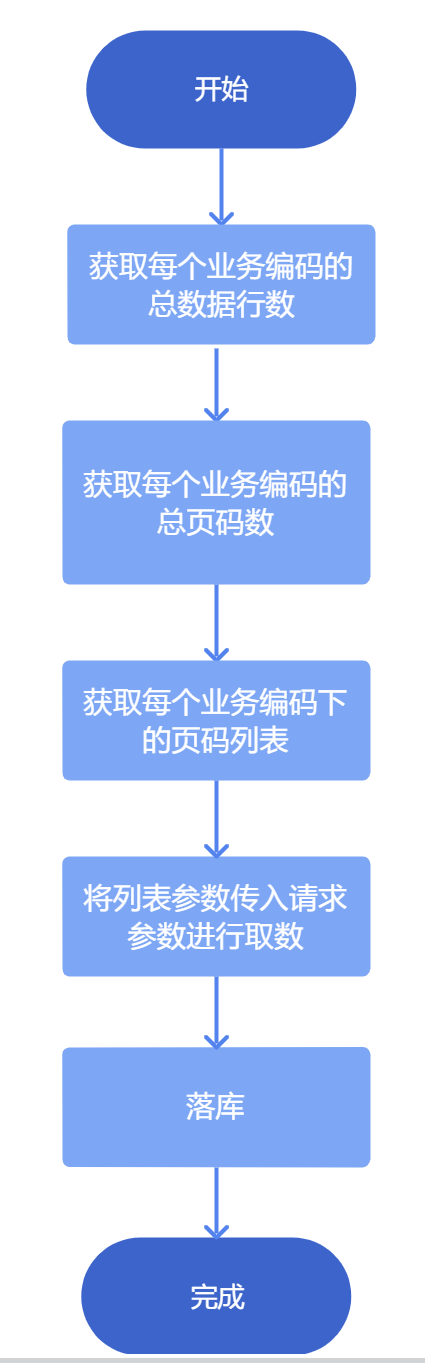
从数据库或者接口中获取库存编码和仓库编码的所有编码值,并将其设置为参数,便于后续循环写入接口请求中;
设置循环容器,让其中的接口遍历两个业务编码数据;
设置分页方式为页码分页,页码参数 ${pageNum} 设置初始值为 0,从第 0 页开始分页取数,分页的结束条件为当某次分页返回的响应值数据不等于自定义的 page_size 量,则表示数据已被取完,为接口请求参数中 page_no 赋值页码参数 ${pageNum},page_size 可自定义,但必须与结束条件设置的量相同,同时将两个编码字段也作为请求参数。
2. 操作步骤编辑
2.1 获取业务编码和总行数
由于接口中业务参数作为必填项,因此需要先在数据库中取出所有的业务参数,例如仓库编码 warehouse_no。
此处以获取一个业务参数为例,接口中的两个必填参数操作方法一致。
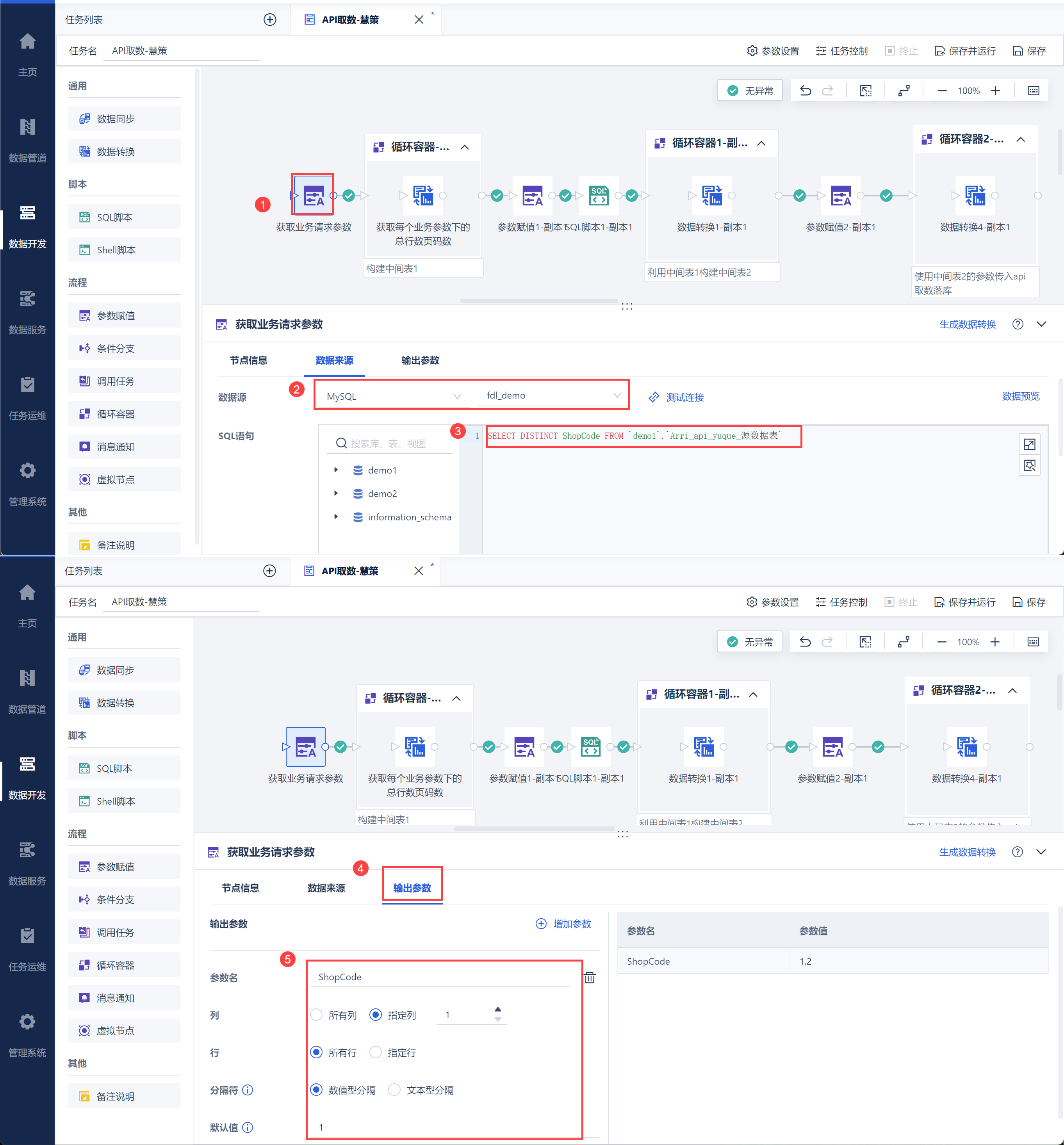
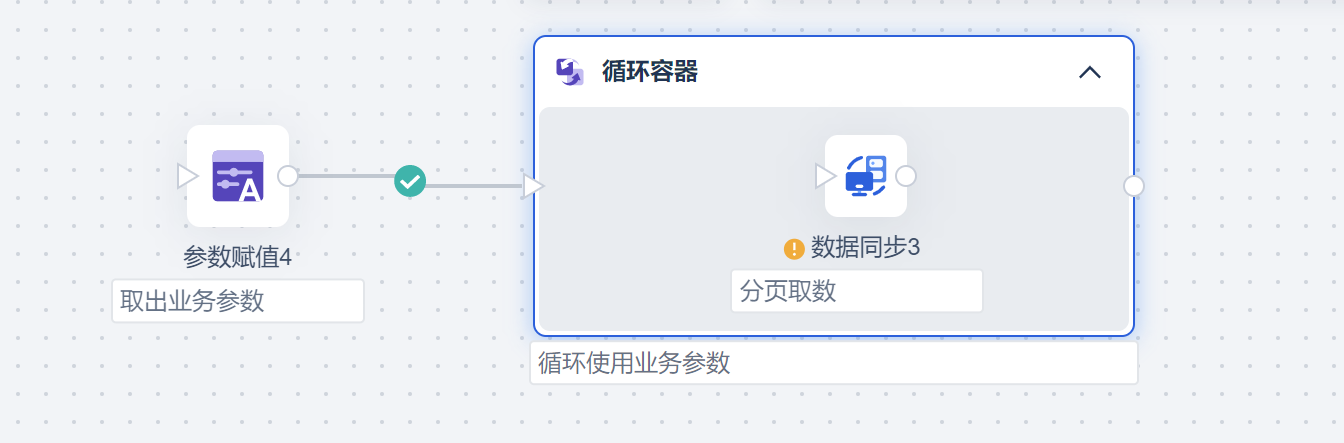
新建定时任务后,新增「参数赋值」节点,从数据库或者接口中获取所有的业务分类数据,例如这里获取所有仓库编码,并将其设置为参数 ShopCode,如下图所示:

2.2 循环写入业务参数
由于两个业务参数 owner_no 和 warehouse_no 均需要循环作为请求参数写入接口,因此使用循环容器,并设置循环条件为遍历两个业务参数,如下图所示:
注:此处示例一个参数,实际用户需要勾选两个参数作为遍历对象。

2.3 设置分页取数
在循环容器中拖入数据同步节点,输入接口 API,并开启分页取数。
接口请求参数如下图所示:
设置分页方式为「页码」,页码参数${pageNum},更新策略为页码参数初始值 0 ,增长间隔为 1,依次取出每页数据,如下图所示:
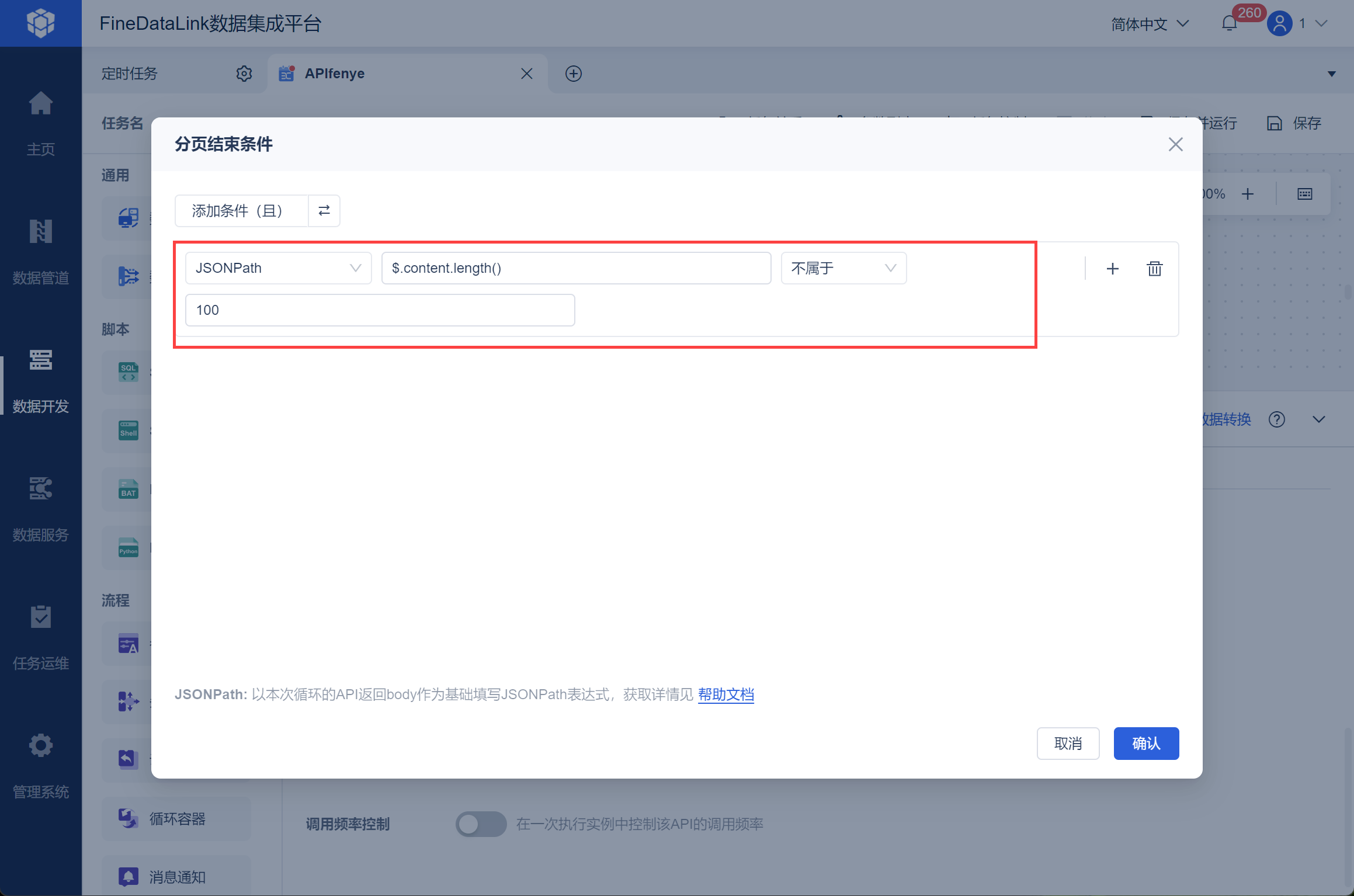
分页结束的条件为当每次接口响应返回值数据条数小于请求参数 page_size 大小,则停止分页,如下图所示:
注:$.content.length() 为返回的响应值 content 中数据长度。
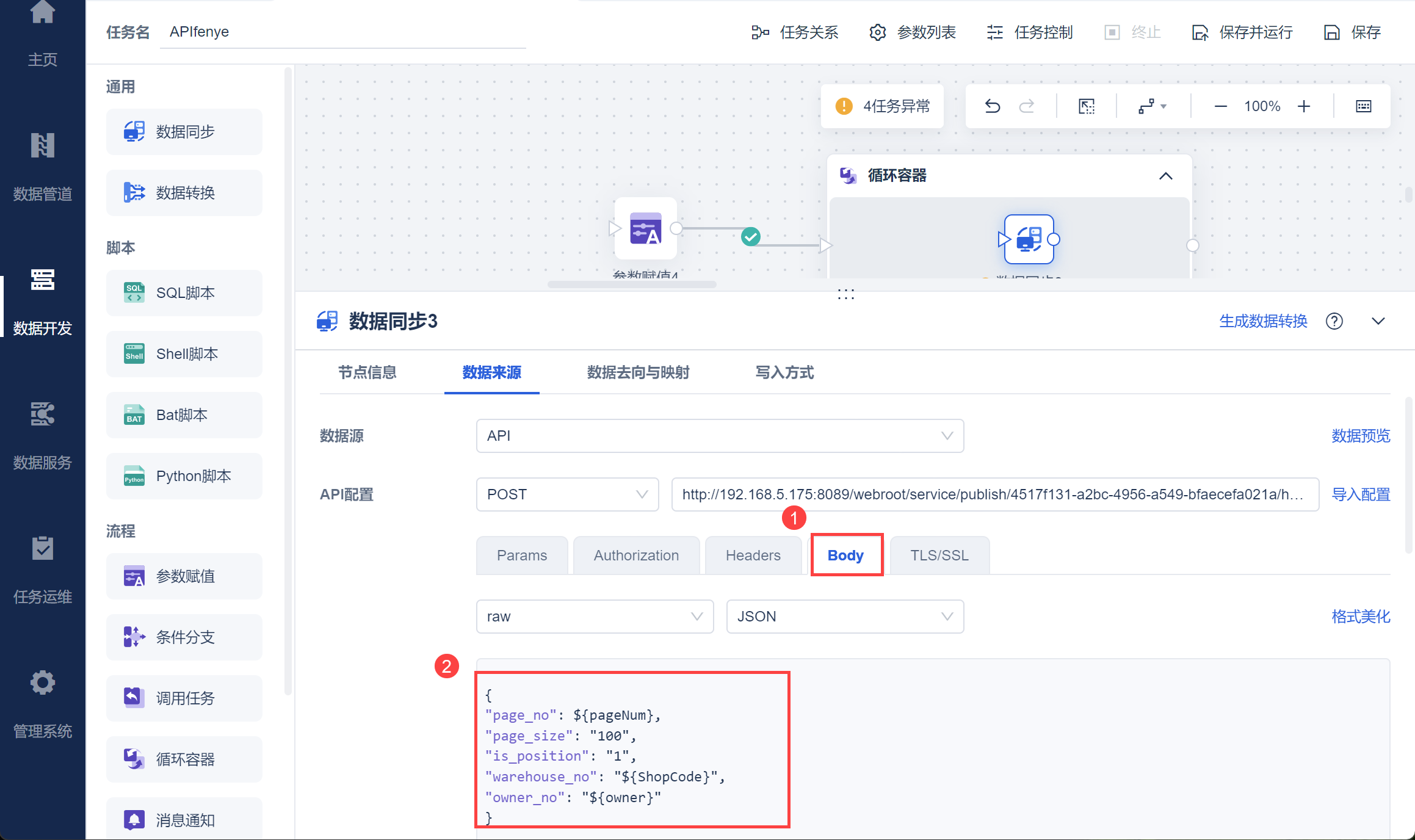
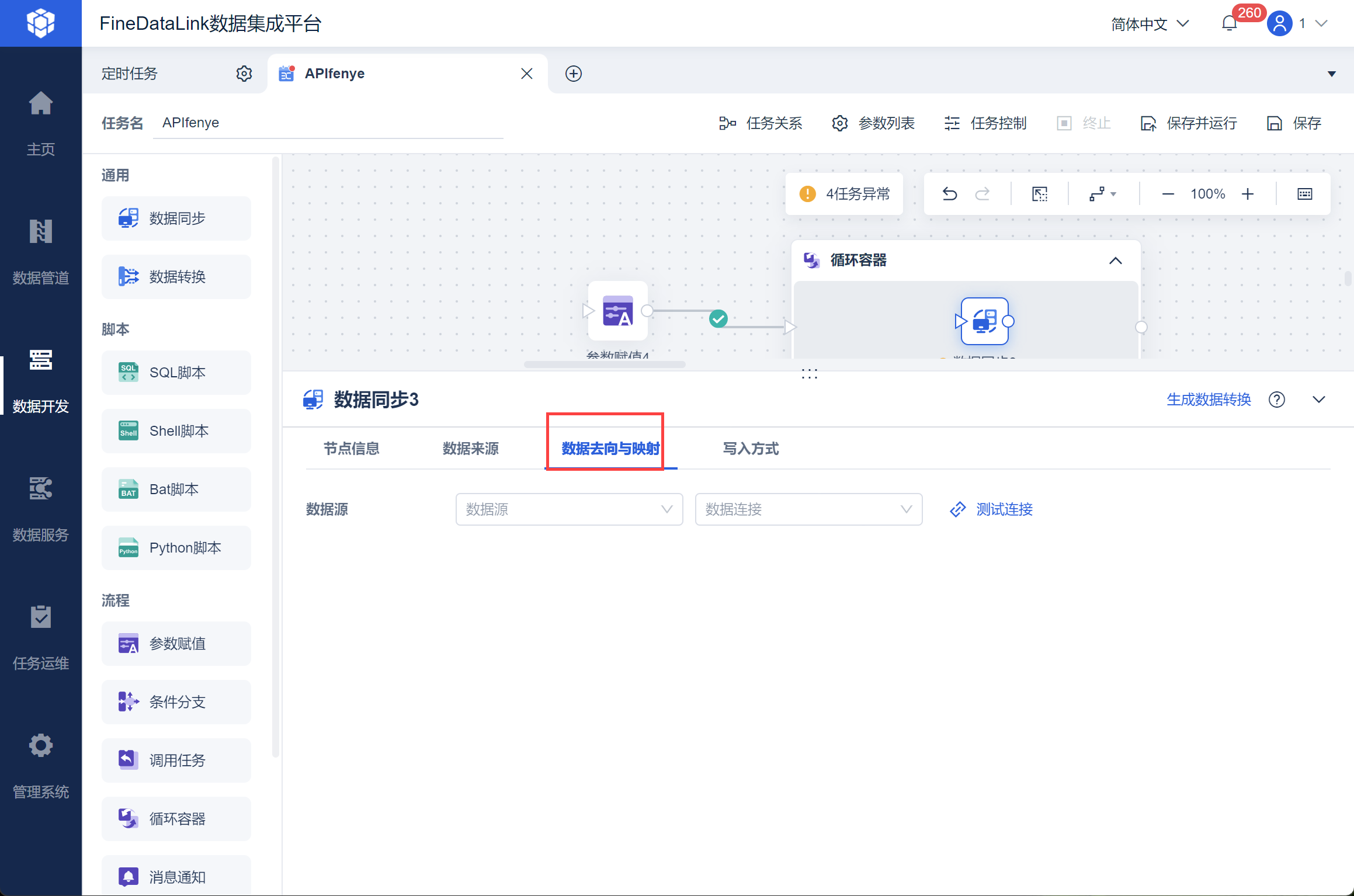
然后写入接口的请求参数 Body 值,其中 page_no 为分页页码参数 ${pageNum},page_size 可自由设置,且需要与分页结束条件中数值相同,然后将两个业务参数写入,如下图所示:
可以设置响应体,和写入端数据表,即可运行任务。
运行任务,即可看到数据库中取出的全量接口数据,如下图所示:

4.1.3 之前的版本支持的方案。
| 点击展开更多 |
1. 概述编辑1.1 应用场景某企业现在需要将某业务工单数据全部取出以供业务分析使用。 API取数-按页数取数 中可以使用页数和内置参数 loopTimes 进行取数。 但是如果遇到接口中需要使用业务参数,并且由于数据量大需要分页取出,由于每个业务参数都有不同的页码数,因此页码需要遍历,若条件循环中包含页码数参数,则无法将数据取出。 1.2 接口说明接口文档详情参见:慧策-WMS库存全量查询接口 1.3 实现思路从数据库或者接口中获取库存编码和仓库编码的所有编码值,并使用循环容器从 API 中取出所有的编码值对应的数据总条数 total; 使用公式计算每个编码值按照指定的page_size 得到的总页码数; 使用 SaprkSQL 获取所有编码值对应的页码列表page_no,方便后续作为遍历参数遍历进行 API 取数; 将page_size、page_no、两个编码字段作为请求参数,在 API 中进行取数,设置为遍历这些参数,取出所有的数据。 FineDataLink 中的数据处理过程,详情参见:https://demo.finedatalink.com/ 「API取数-慧策接口取数」。 2. 操作步骤编辑2.1 获取业务编码和总行数由于接口中业务参数作为必填项,因此需要先在数据库中取出所有的业务参数,例如仓库编码 warehouse_no。同时通过接口传入业务参数,获取每个的业务分类对应的总数据行数。 此处以获取一个业务参数为例,接口中的两个必填参数操作方法一致。 新建定时任务后,新增「参数赋值」节点,从数据库或者接口中获取所有的业务分类数据,例如这里获取所有仓库编码,并将其设置为参数 ShopCode,如下图所示:
使用循环容器将获取到的所有仓库编码依次作为请求参数传入接口,以此获取每个业务分类(仓库编码)下的总数据行数。 效果如下:ShopCode 为仓库编码、totalNum 为每个仓库的数据行数。
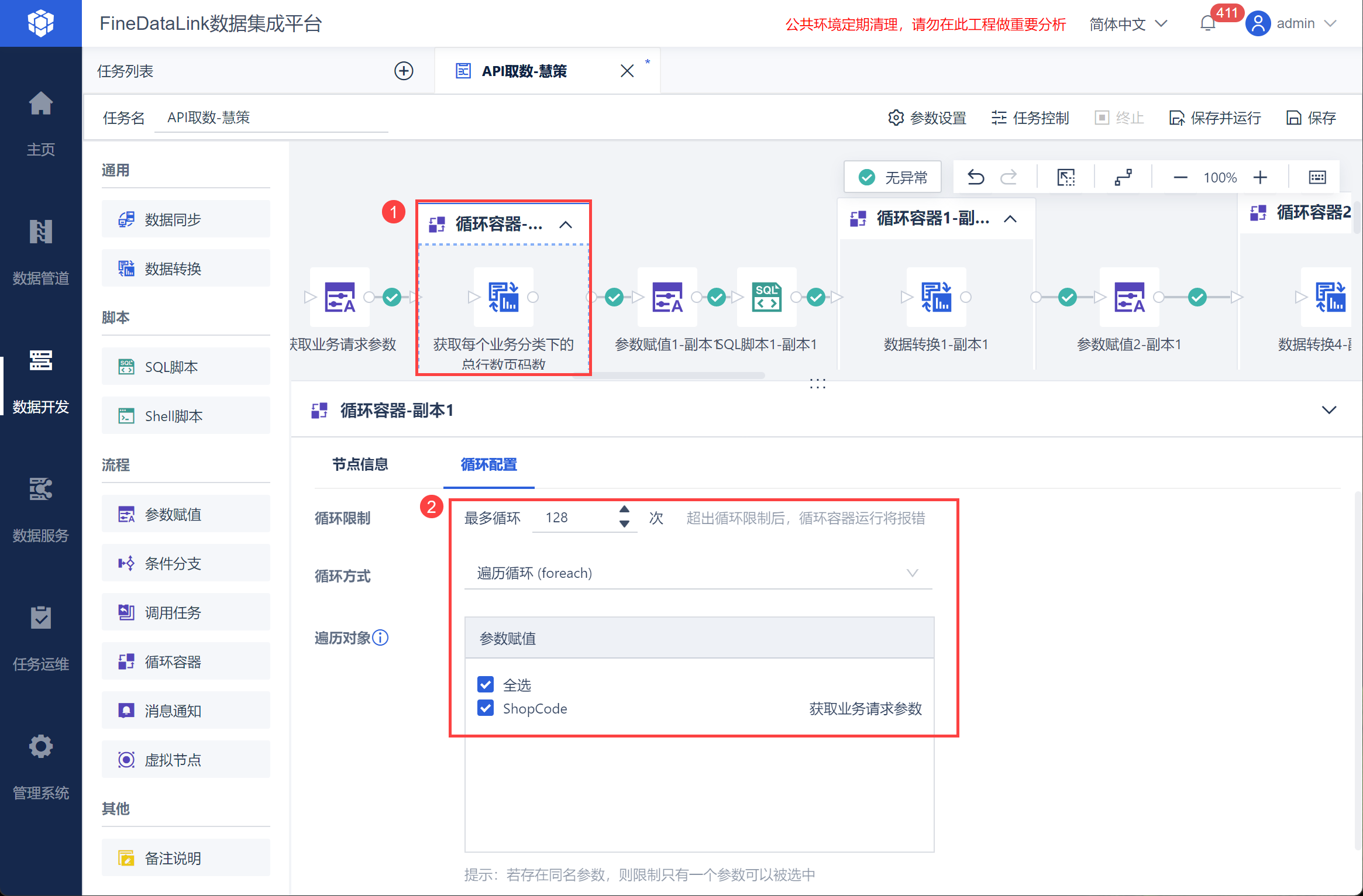
新增循环容器,并将数据转换拖入循环容器中,如下图所示:
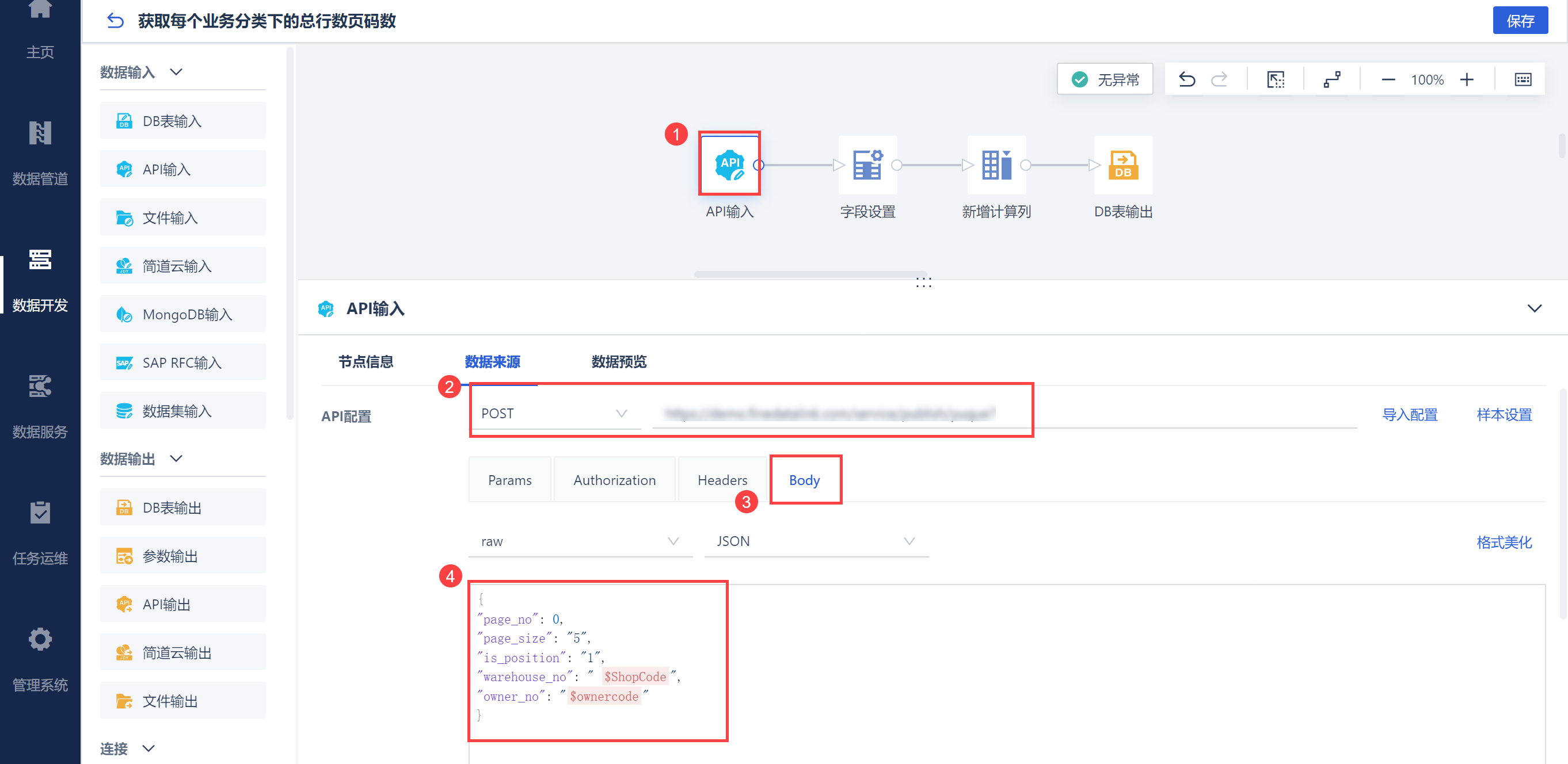
进入数据转换编辑界面,新增 API 输入算子,使用API 接口,将获取到的仓库编码 ShopCode 参数写入请求参数中,取出接口响应值:每个仓库编码对应的总数据行数,如下图所示:
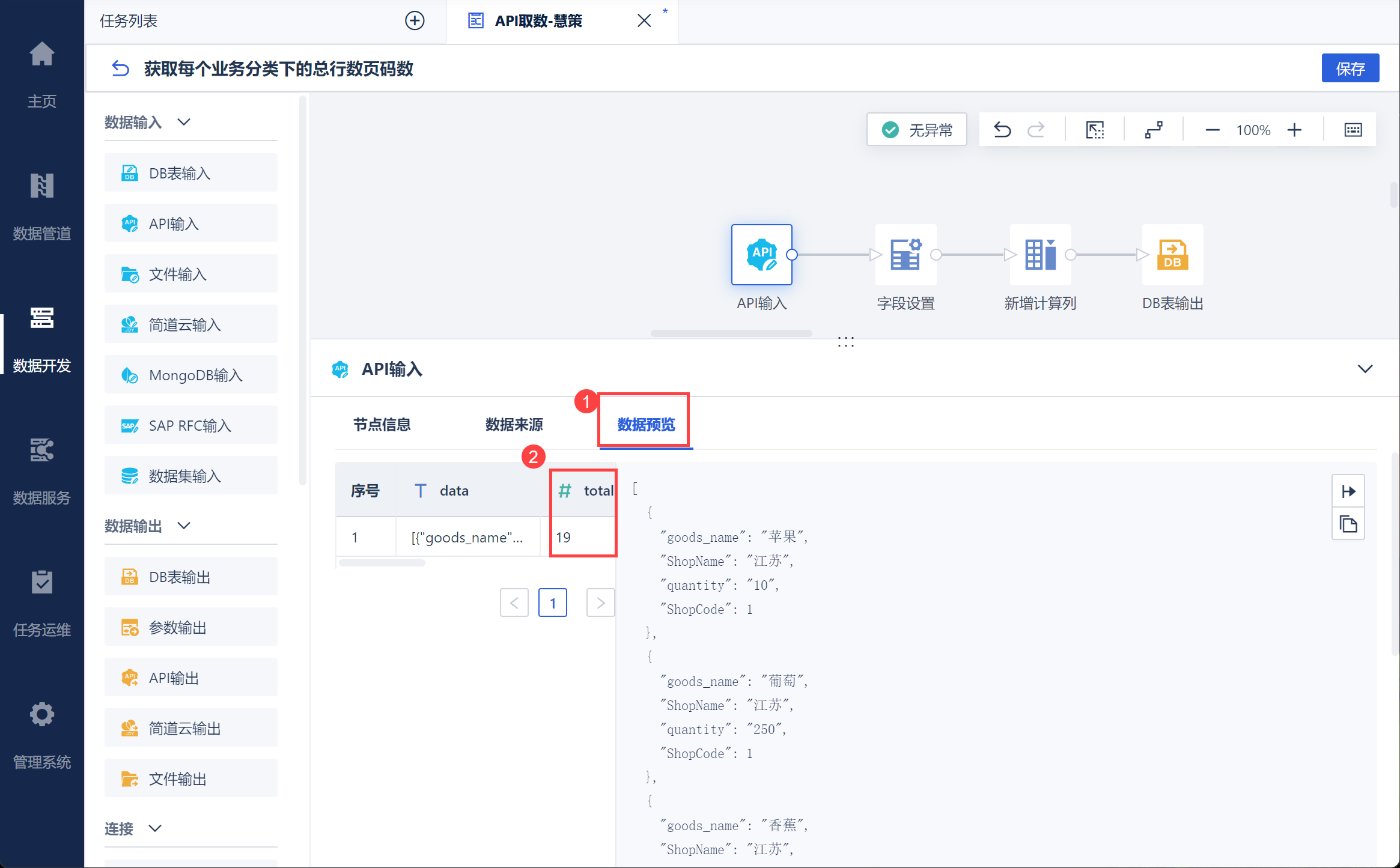
点击数据预览即可看到每个分类下的总数据行数,如下图所示: 注:此处由于前面参数赋值默认值填入的为 1,所以预览值为仓库编码为 1 的总数据行数。
在循环容器中设置遍历 ShopCode 参数,即将所有的仓库编码类型对应的总数据条数取出,如下图所示:
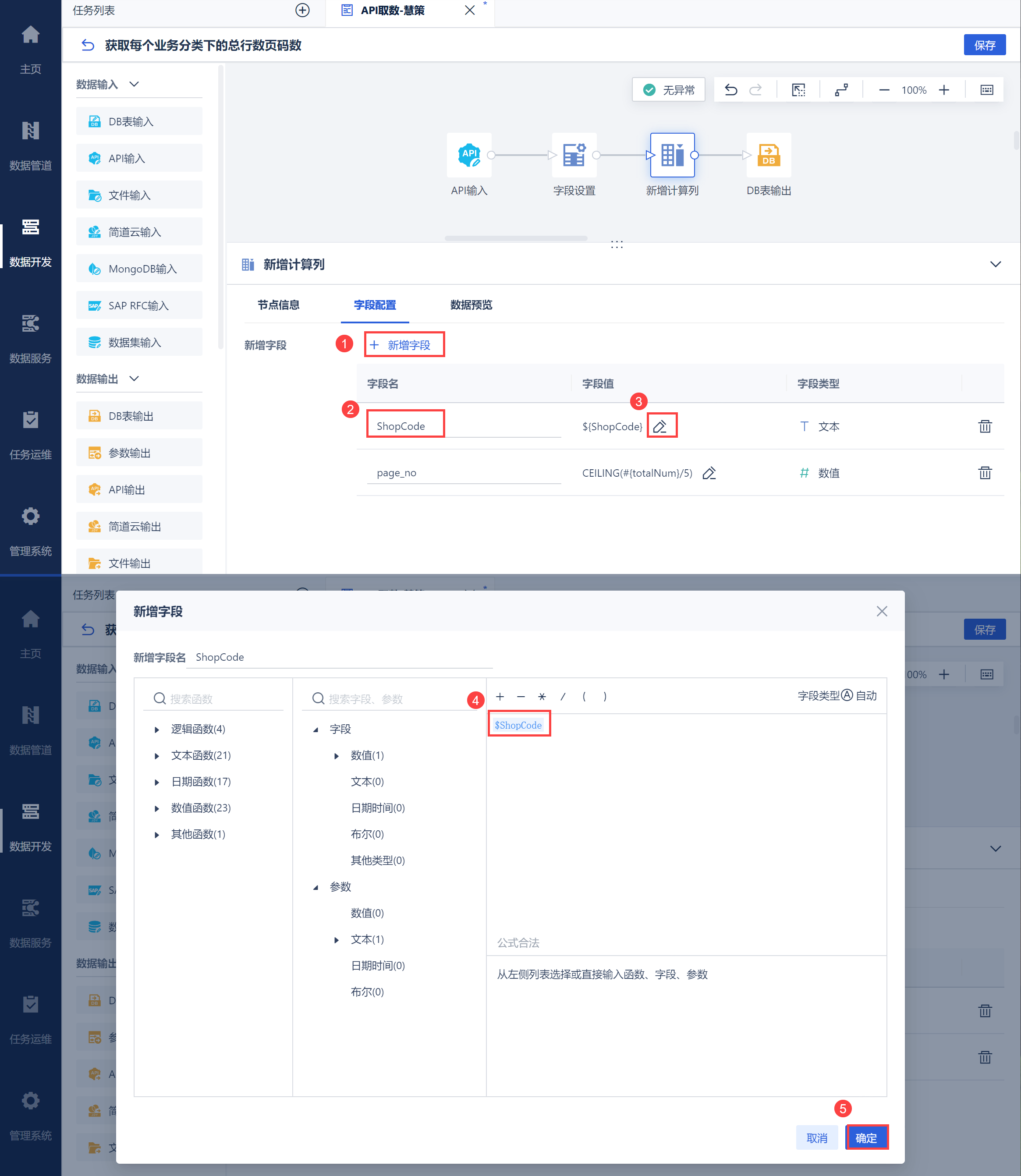
2.2 获取每个业务编码下总页码数再次进入「数据转换」节点中,使用「新增计算列」计算每个仓库编码类型下的页码数,例如每一页五条数据,求出每个仓库编码类型有几页数据。 效果如下:ShopCode 为仓库编码、page_no 为每个仓库的数据页码数(按照指定每页条数5条)
新增page_no页码数公式:CEILING(totalNum/5),对行数取向上取整。
同时保留仓库编码类型 ShopCode ,如下图所示:
将数据写入指定数据库,如下图所示:
2.3 获取每个业务编码下页码列表上一节已经获取了所有仓库编码、每个仓库类型对应的总数据行数、页码数,为了能在后续使用循环容器依次将请求参数写入,从而取出全部数据,因此需要获取每个仓库编码下的页码列表,如下图所示: 仓库编码有两个,其中编码 1 按照每页(page_size)5条数据,一共有4页数据,page_no 从1 到4 展示页数列表。
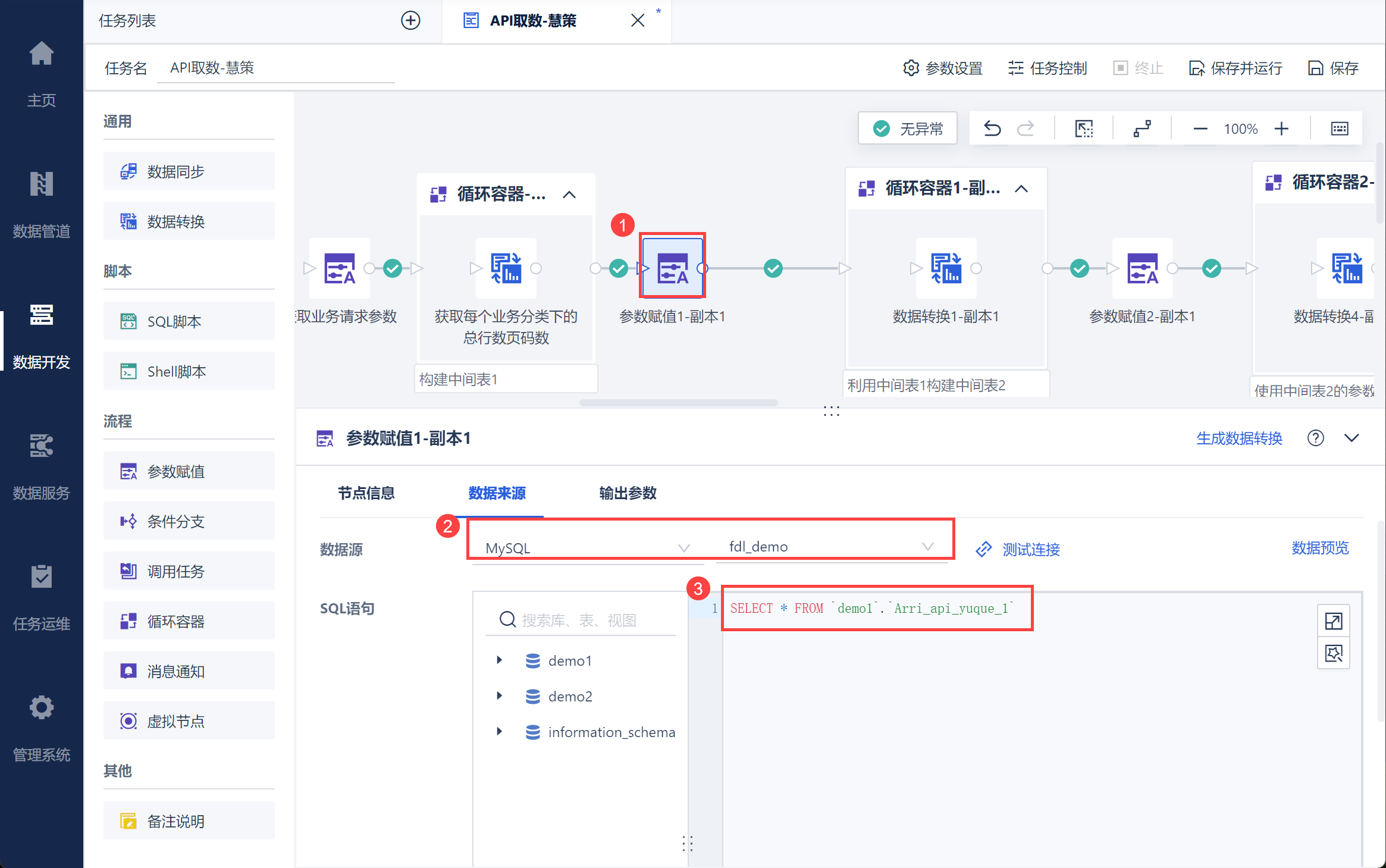
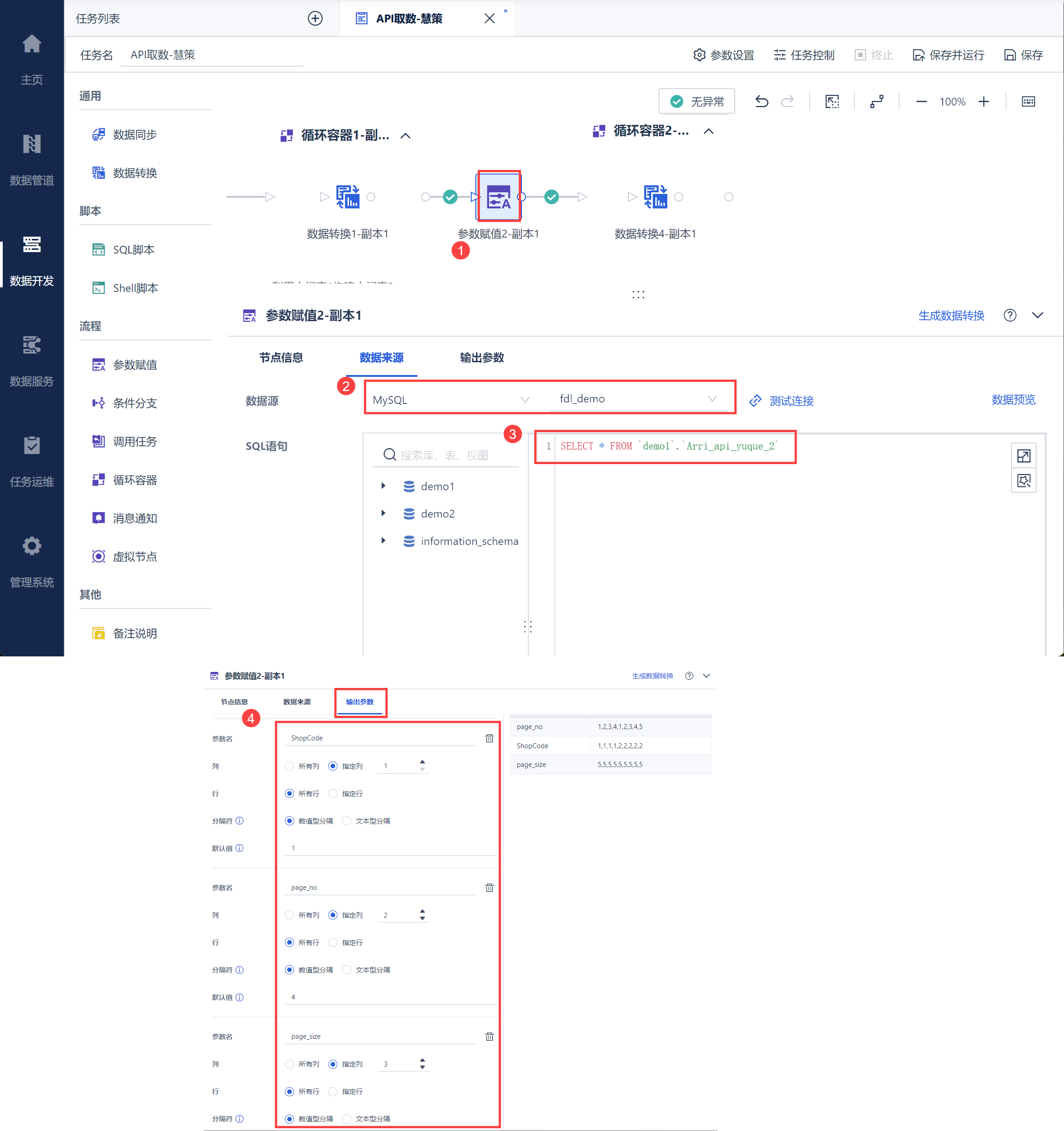
新建参数赋值节点,将 2,2 节写入数据库中的 ShopCode 编码和页码page_no 取出,如下图所示:
将其设置为参数,如下图所示:
新建循环容器,并将数据转换节点拖入循环容器中,如下图所示:
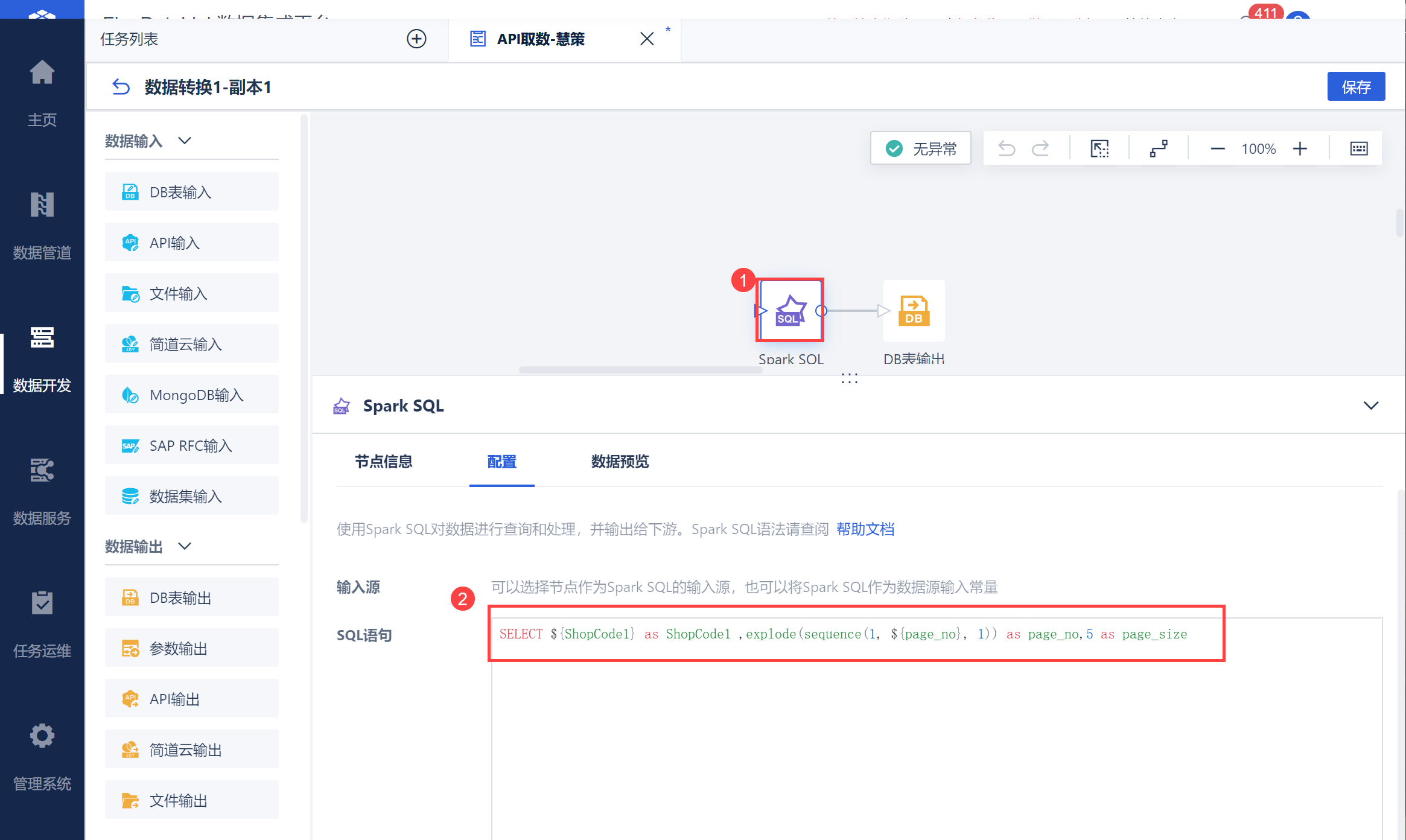
在数据转换中新增「sparkSQL」算子,输入语法获取每个仓库编码下的页码列表,如下图所示: SELECT ${ShopCode1} as ShopCode1 ,explode(sequence(1, ${page_no}, 1)) as page_no,5 as page_size
数据预览界面如下图所示:
然后将数据落库,便于后续作为API请求参数使用,如下图所示:
在循环容器中设置遍历对象为 ShopCode1 编码和页码 page_no,也就是循环取出所有的编码和对应的页码列表,如下图所示:
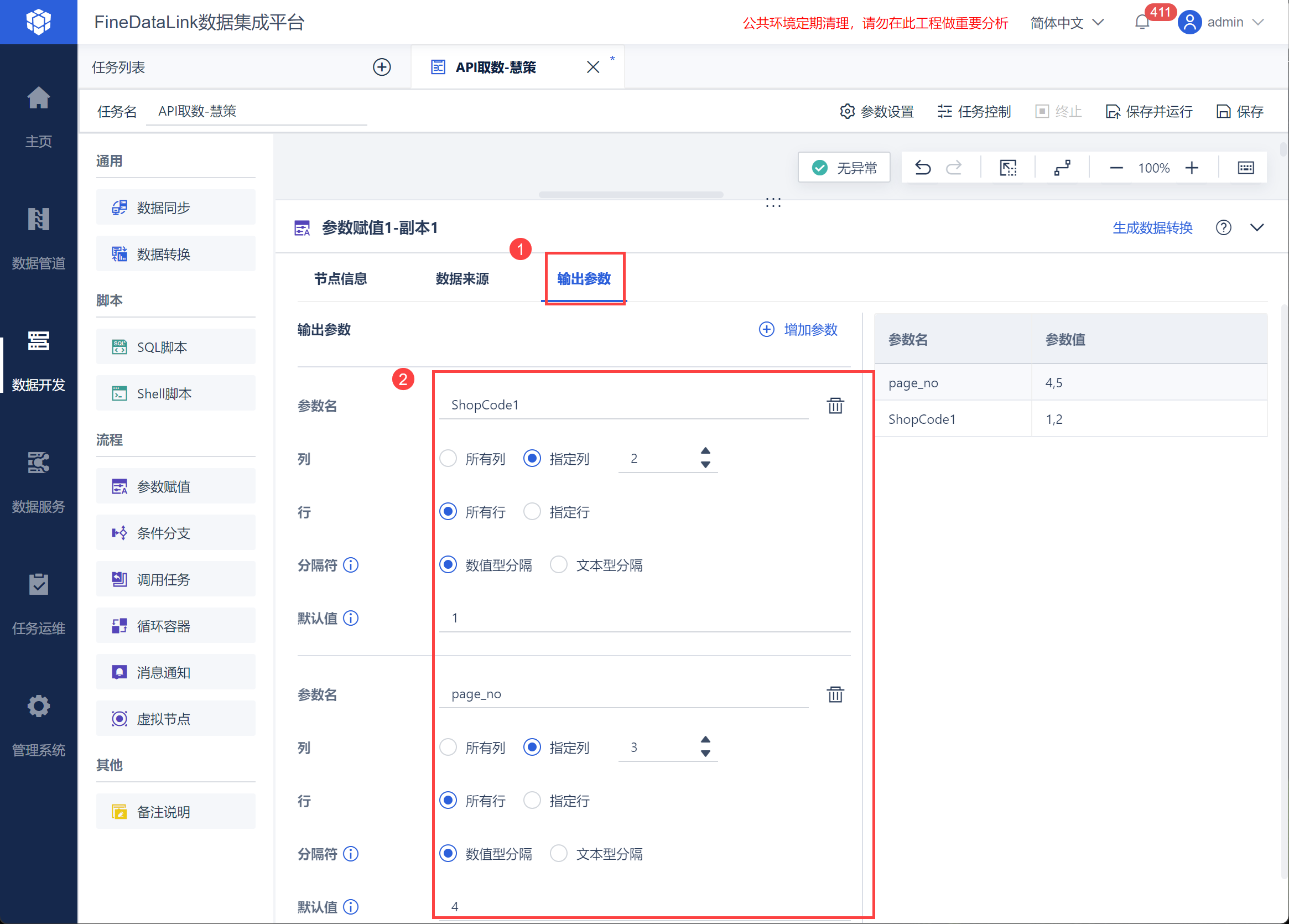
2.4 使用循环容器取数再次使用参数赋值,获取 2.3 节数据库中的业务编码和页码数列表,并将其设置为参数,如下图所示:
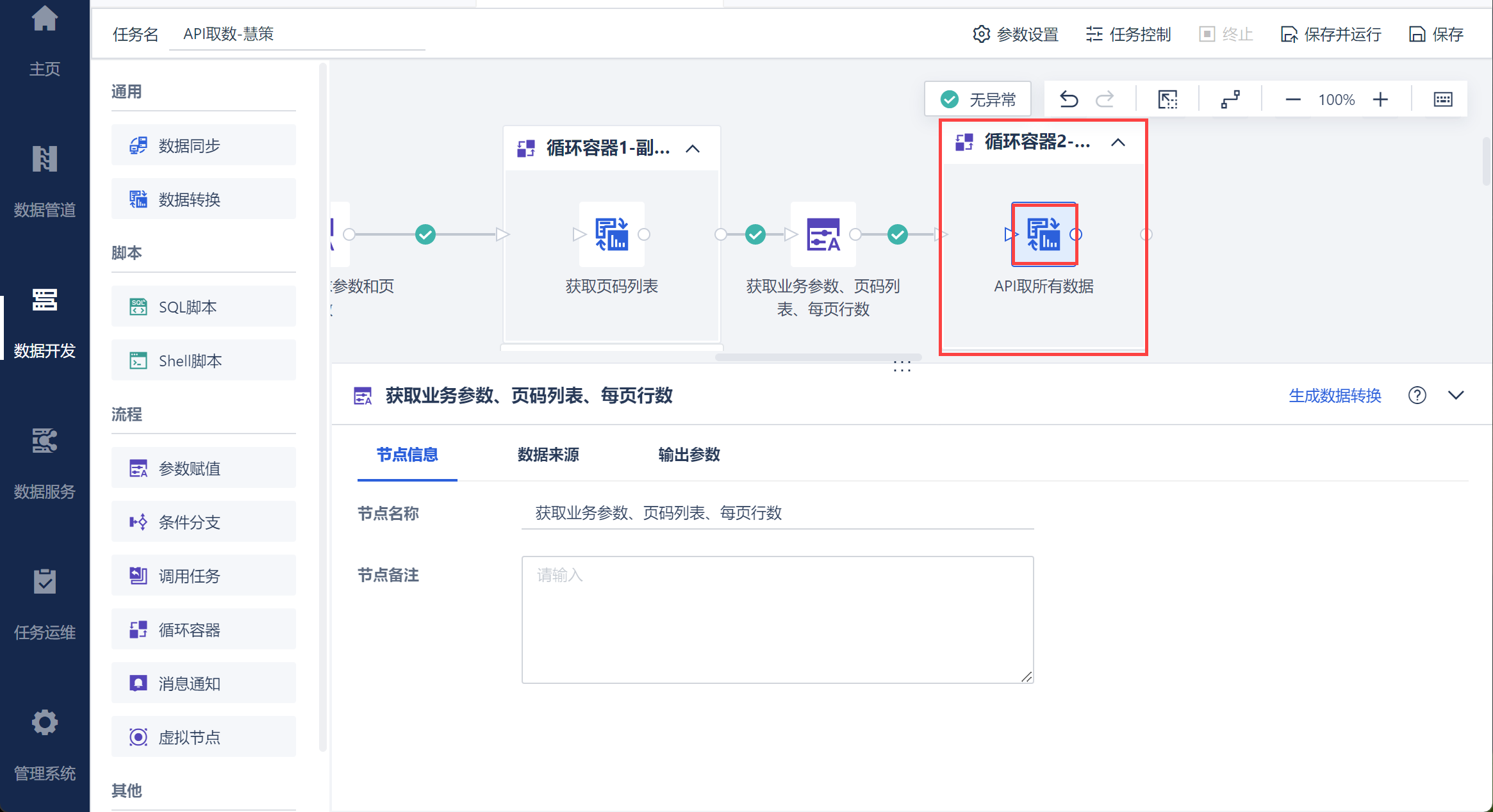
新增循环容器,并将数据转换拖入循环容器中,如下图所示:
进入数据转换编辑界面,输入 API 地址和配置信息,并输入请求参数,其中 page_no 、page_size、warehouse_no、owner_no 分别为设置的参数,如下图所示: 注:owner_no 生成步骤和warehouse_no 的 ShopCode 方法一致,这里不赘述。
在数据预览界面即可看到取出的响应值,如下图所示:
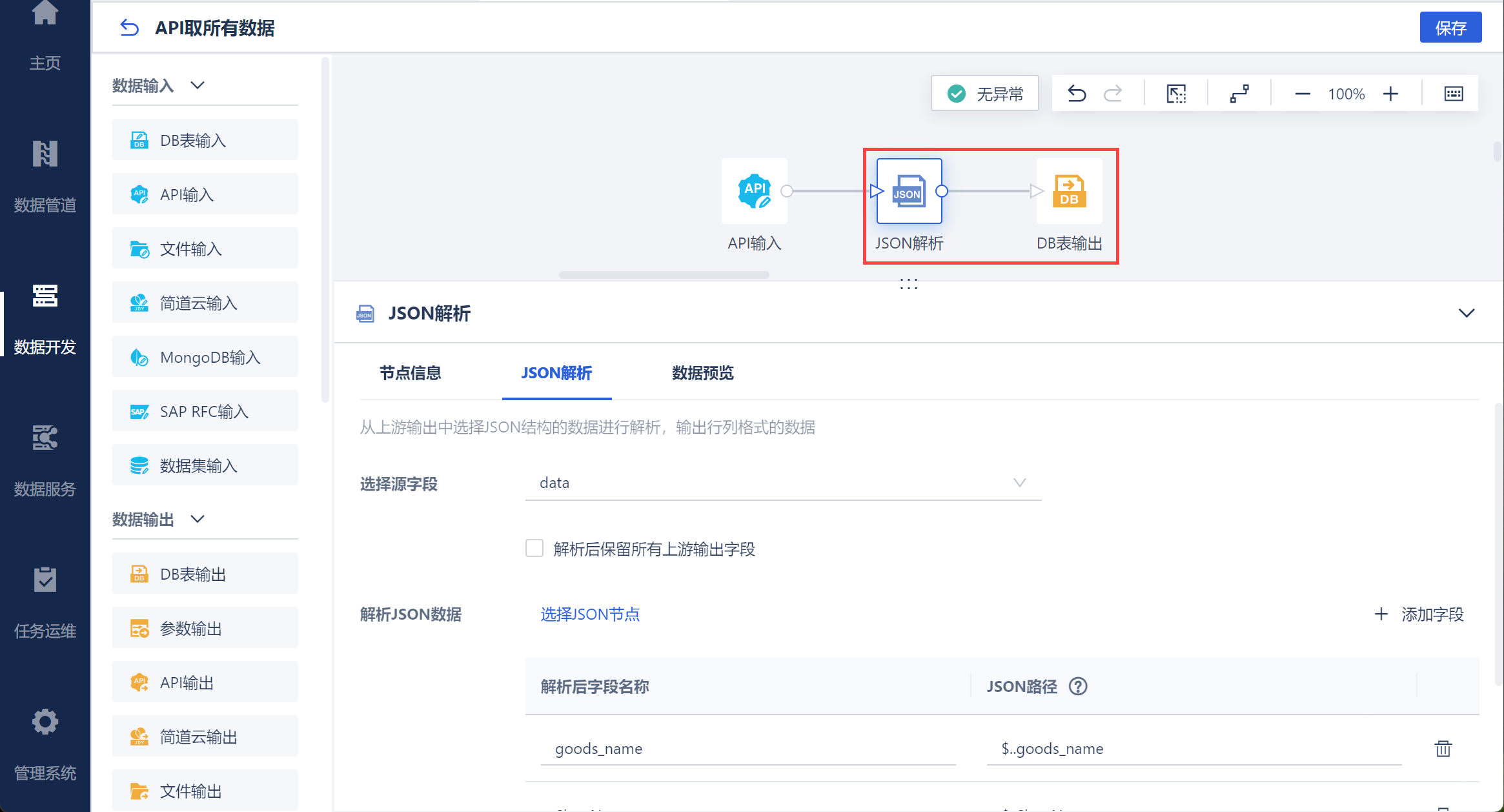
然后使用 JSON 解析将响应值处理为二维表,最后使用 DB 输出将数据落库,如下图所示:
在循环容器中设置遍历page_no 、page_size、warehouse_no、owner_no 参数,也就是一条条将每个业务编码下的页码数据作为参数读取,取出全量数据,如下图所示:
2.5 效果查看运行任务,即可看到数据库中取出的全量接口数据,如下图所示:
|