以下为 4.1.3 以及之后的版本方案。
1. 概述编辑
1.1 应用场景
某企业现在需要将某业务数据全部取出以供业务分析使用。
由于数据量比较大,不可能一次性取全量数据,因此需要使用参数。
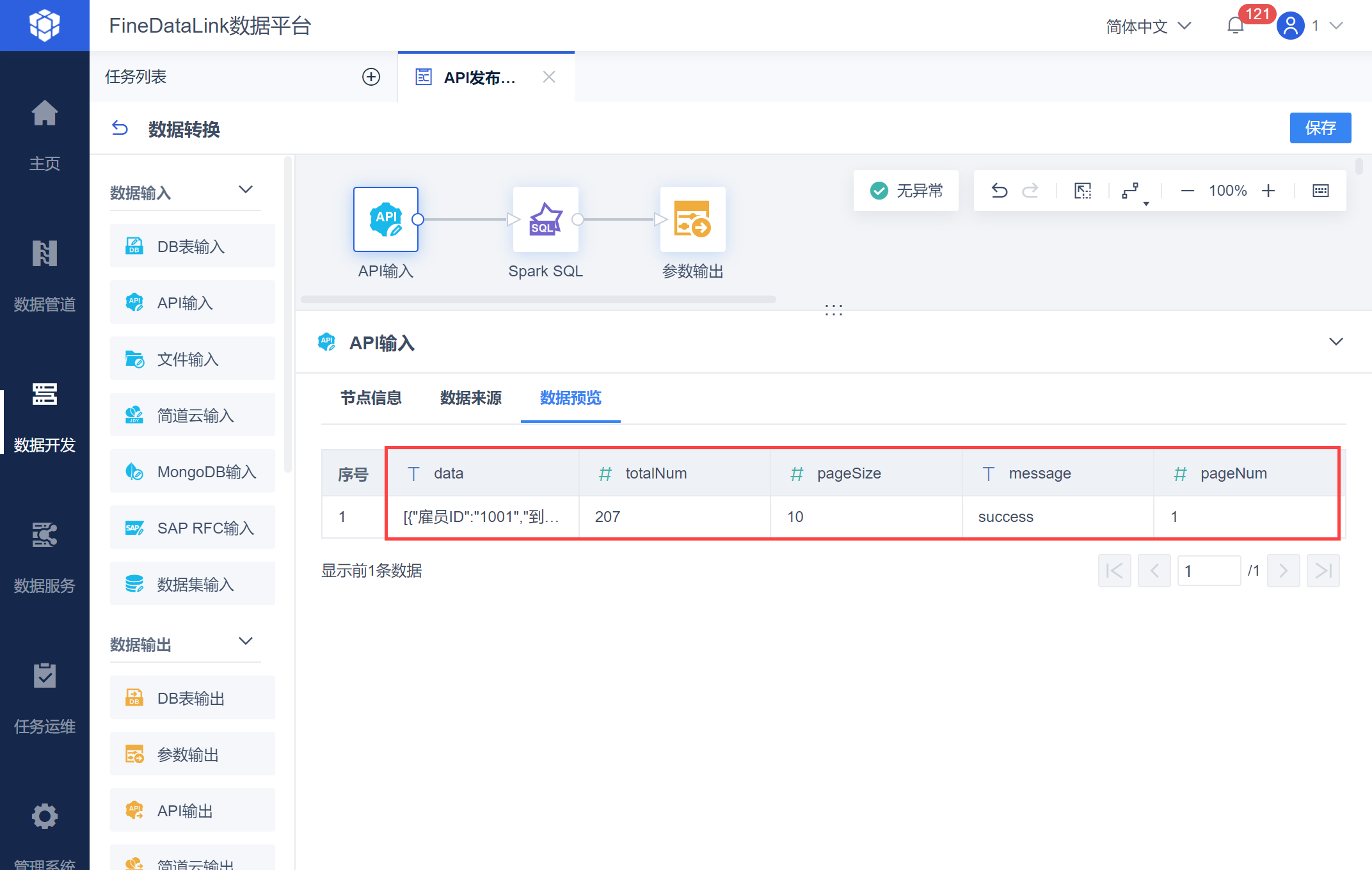
接口文档中 pageNum 表示数据页数;pageSize 表示在每一页的数据条数。
和API取数-按页数取数 不同的是,接口返回值中没有总页数 total_pages,需要手动计算。
1.2 接口说明
需要取数的 API 接口说明如下:
请求说明:
| 请求方式 | POST |
|---|---|
| ContentType | application/json |
请求body参数:
| 名称 | 类型 | 是否必填 | 描述 | |
|---|---|---|---|---|
| paging | pageNum | int | 是 | 分页参数 pageNum 为页数,数值可自定义。 |
| pageSize | int | 是 | pageSize 为每页数据条数,数值可自定义 | |
| params | object | 否 | 自定义参数 | |
请求示例:
{
"paging": {
"pageNum": 1,
"pageSize": 10
},
"params": [{
"name": "dtime",
"value": "2010-07-13 00:00:00"
}]
}
返回值参数:
| 名称 | 类型 | 描述 |
|---|---|---|
| data | object | 返回用户使用接口取出的数据 |
| totalNum | int | 返回取出数据的总数据条数 |
| pageSize | int | 返回取出数据的每页数据条数 |
| pageNum | int | 数据页数,即从第几页开始取 |
| message | string | success,则返回成功 失败时具体原因会在Messege中体现 |
1.3 实现思路
接口取数时,通常不会一次性取出全量数据,因此使用参数,分批从接口中取出全量数据。
从接口中获取 pageNum 和 pageSize 返回值,并使用 SparkSQL 计算出数据总页数 total_pages,将其作为参数,也就是需要执行的次数;
使用分页取数,翻页方式选择「页码」,并设置 ${pageNum}页数参数,首次执行 pageIndex 页码数为 1 ,然后增长间隔为1,递增执行取出每一页的数据,当页数pageNum<=totalpages 继续执行,当页数pageNum>totalpages 时,停止执行。
2. 操作步骤编辑
2.1 设置 API 基本信息
新建一个定时任务,由于需要将 API 数据解析计算后获取总页数值作为参数,因此需要使用「数据转换」节点。
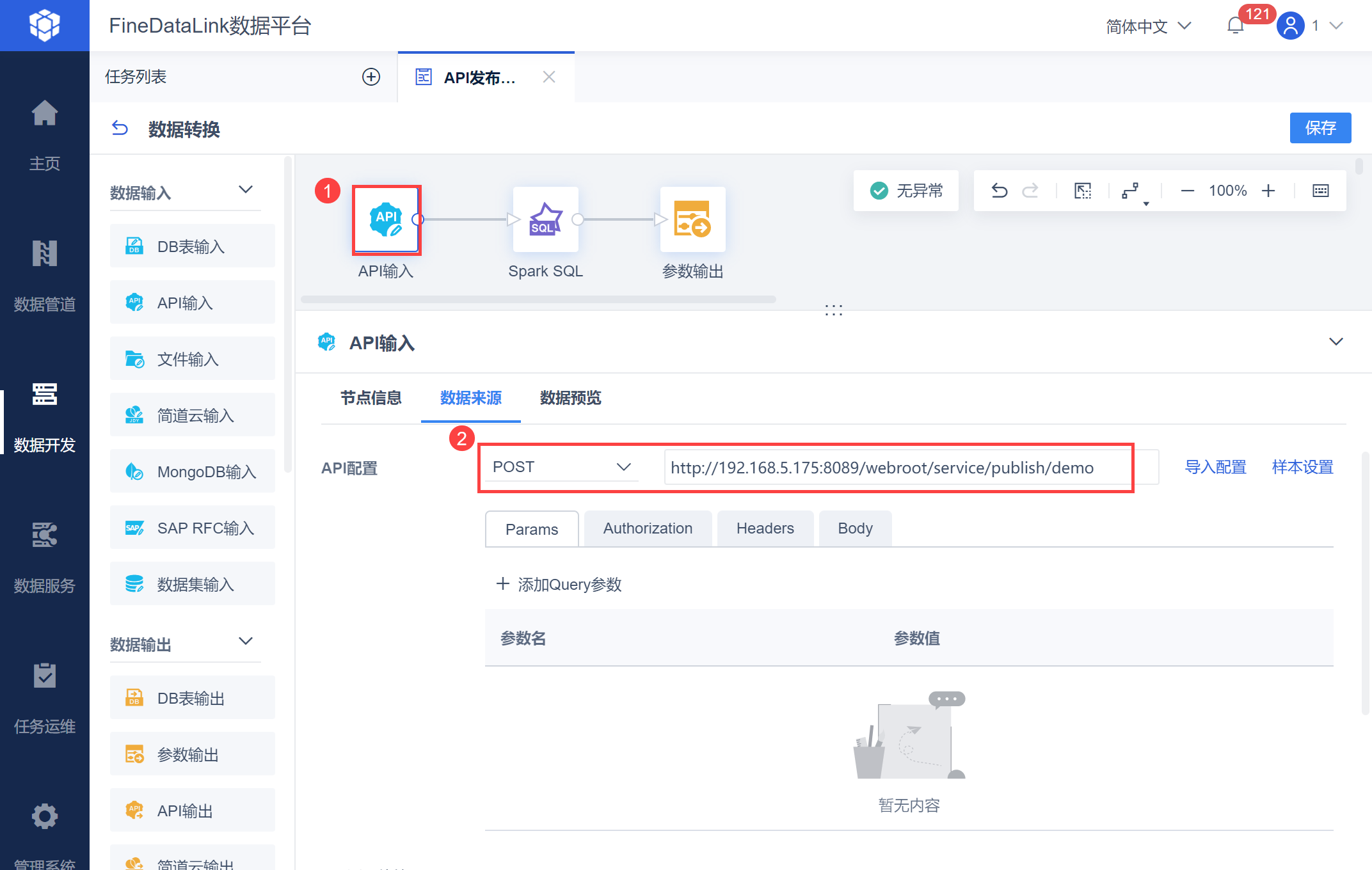
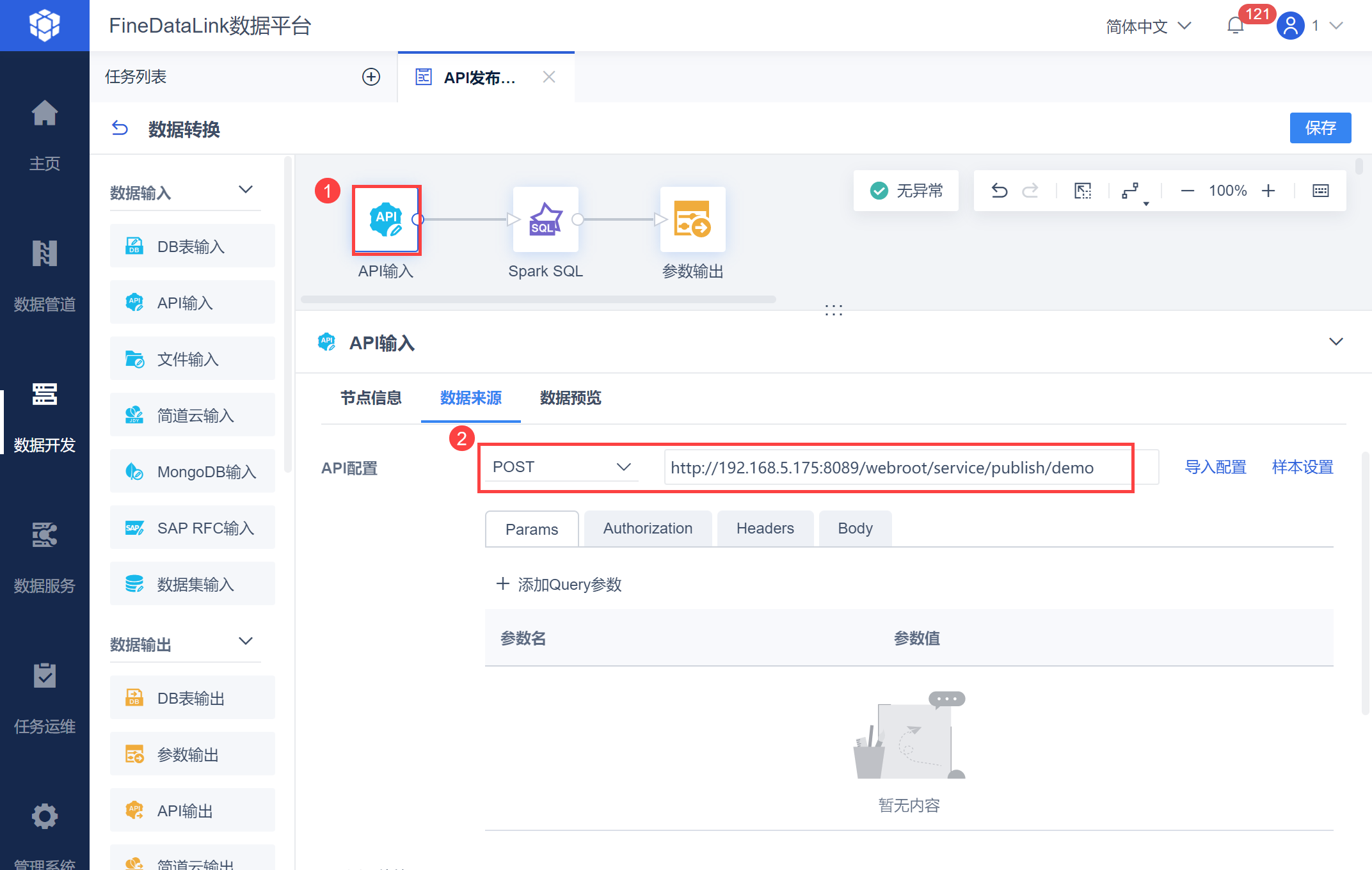
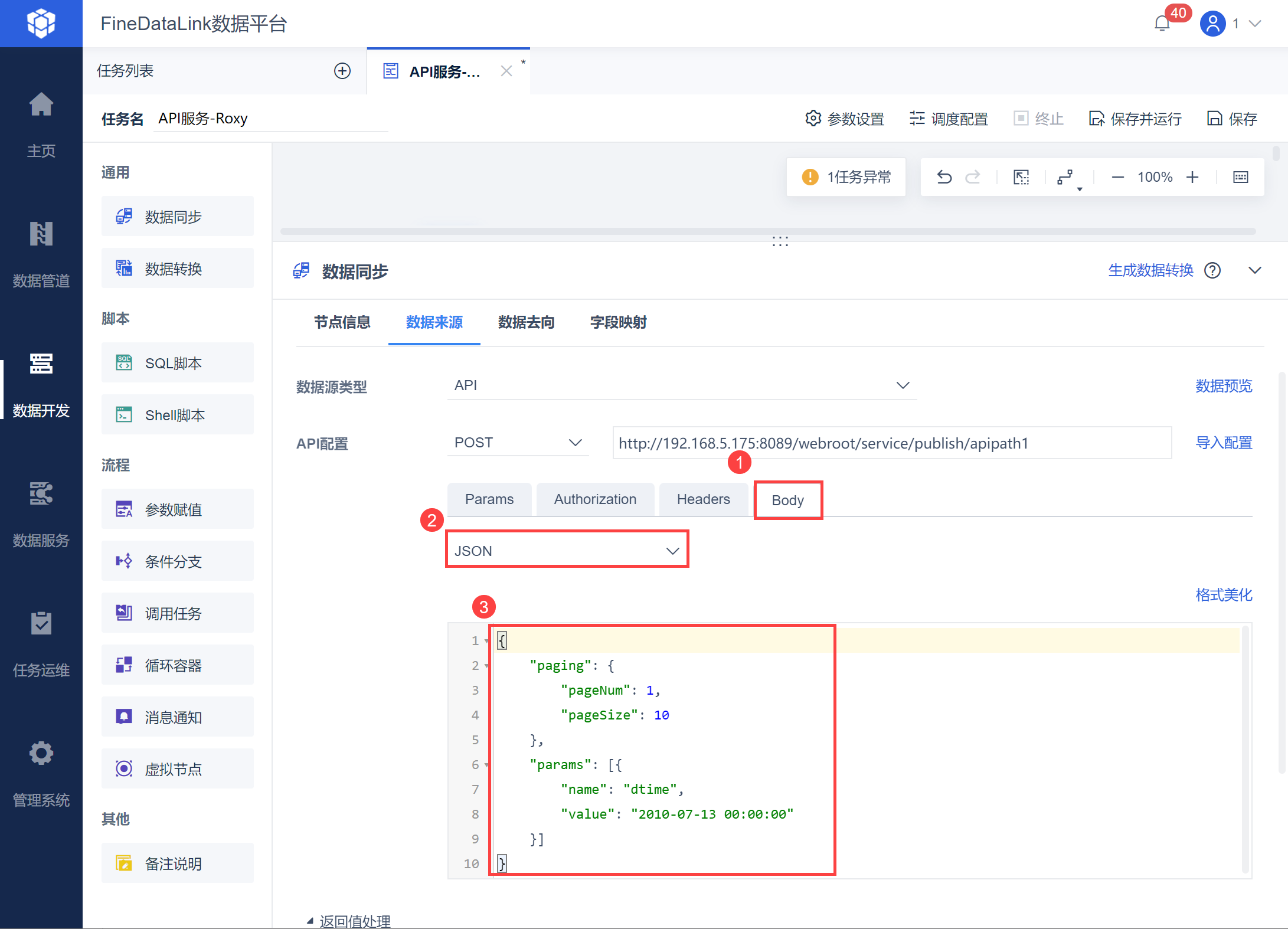
在数据转换中,选择「API输入」并选择POST请求方式,输入复制的API链接,如下图所示:
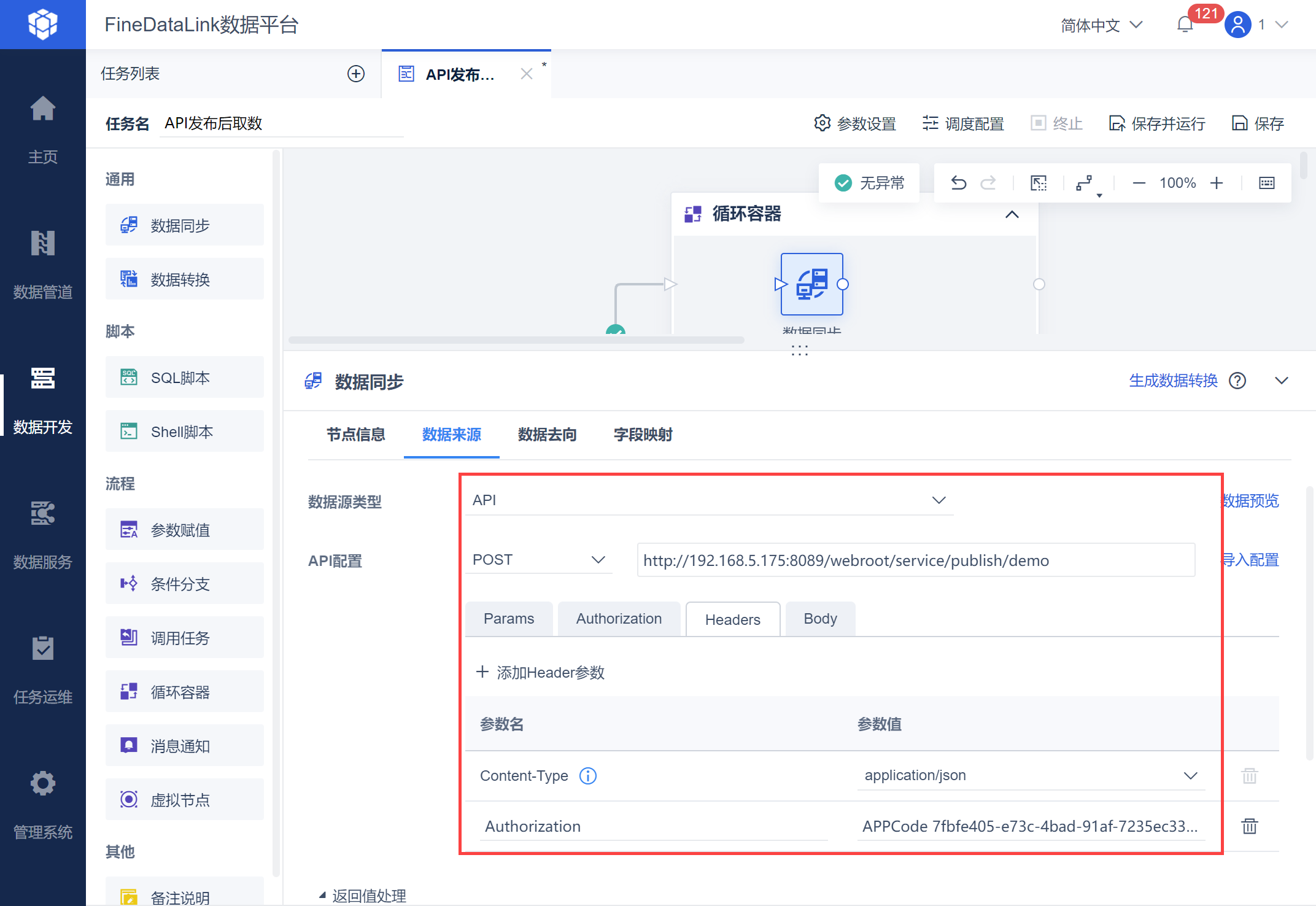
若有认证,则设置认证方式。
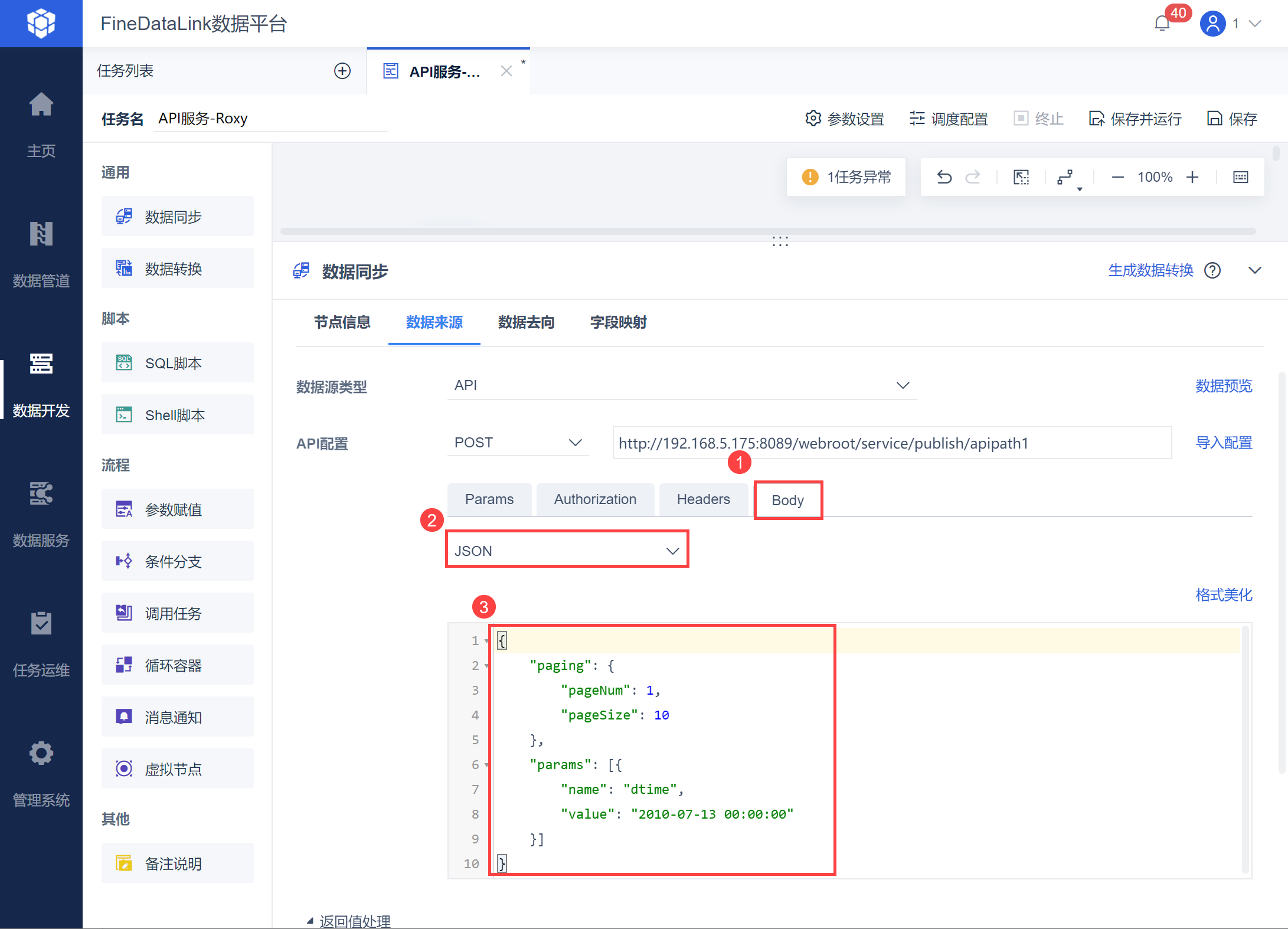
然后在Body 中输入 json 数据,如下图所示:
示例取出 2010-07-13 00:00:00 之后的数据,因此自定义参数 dtime 的 value 直接写成 2010-07-13 00:00:00,将 pageSize 设置为 10,也就是每页数据限制为 10 条,从第一个开始取数,查看返回值中,每页 10 条数据计算总页数为多少。
{
"paging": {
"pageNum": 1,
"pageSize": 10
},
"params": [{
"name": "dtime",
"value": "2010-07-13 00:00:00"
}]
}
解析后的返回值如下图所示:
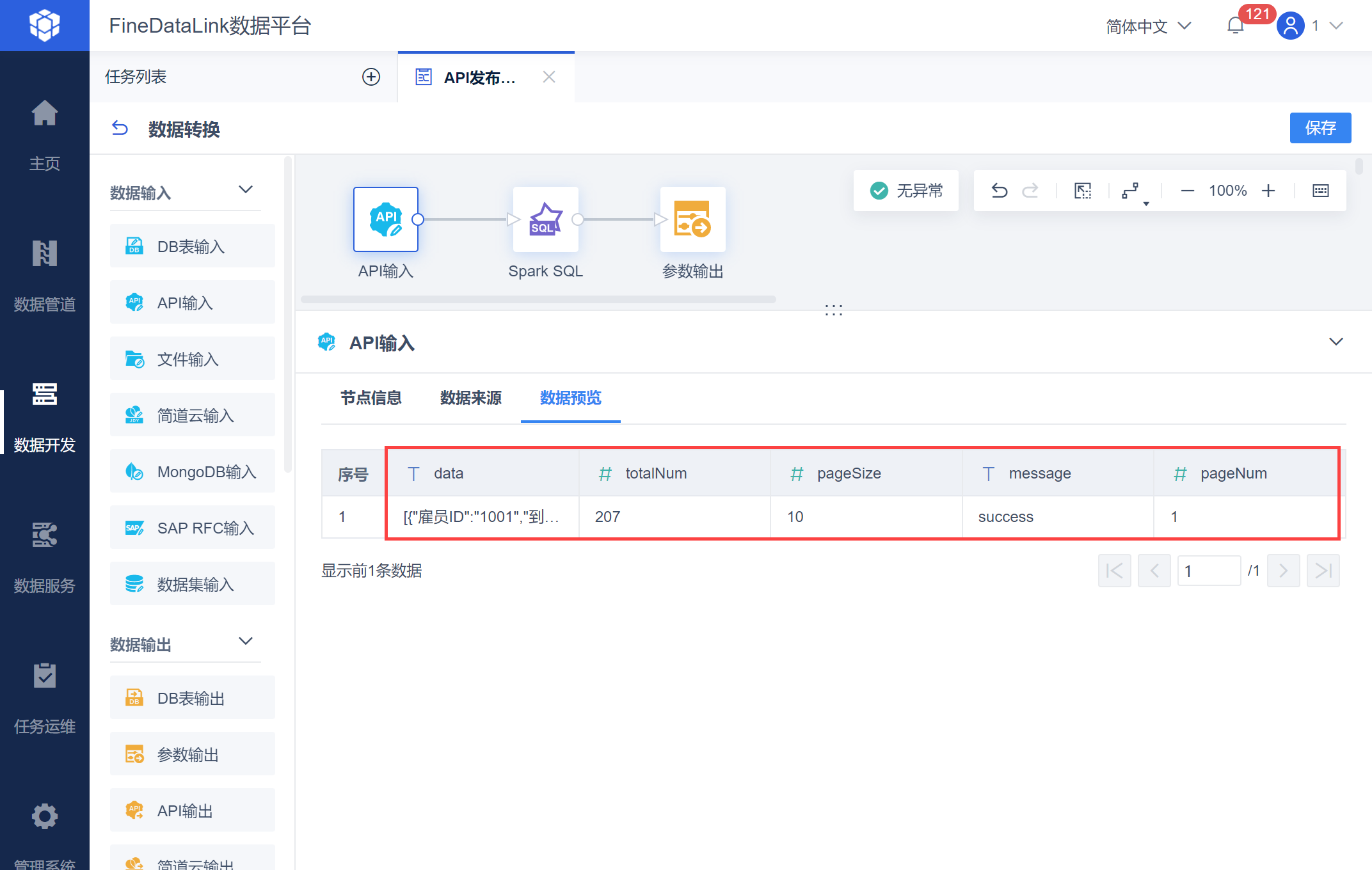
2.2 获取数据总页数
使用获取到的 totalNum:返回总数据条数和 pageSize:每页数据条数进行计算,获取总页数。
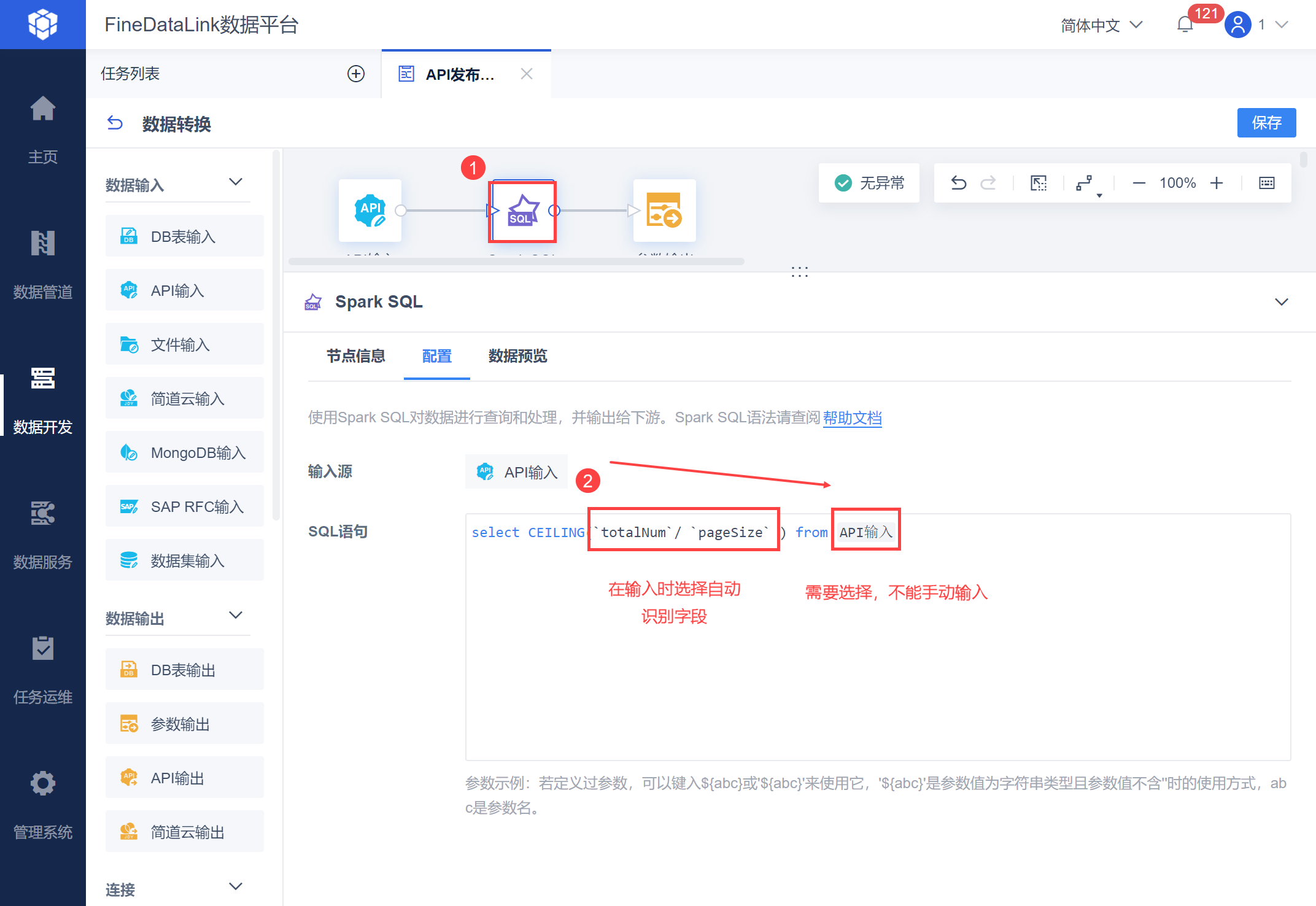
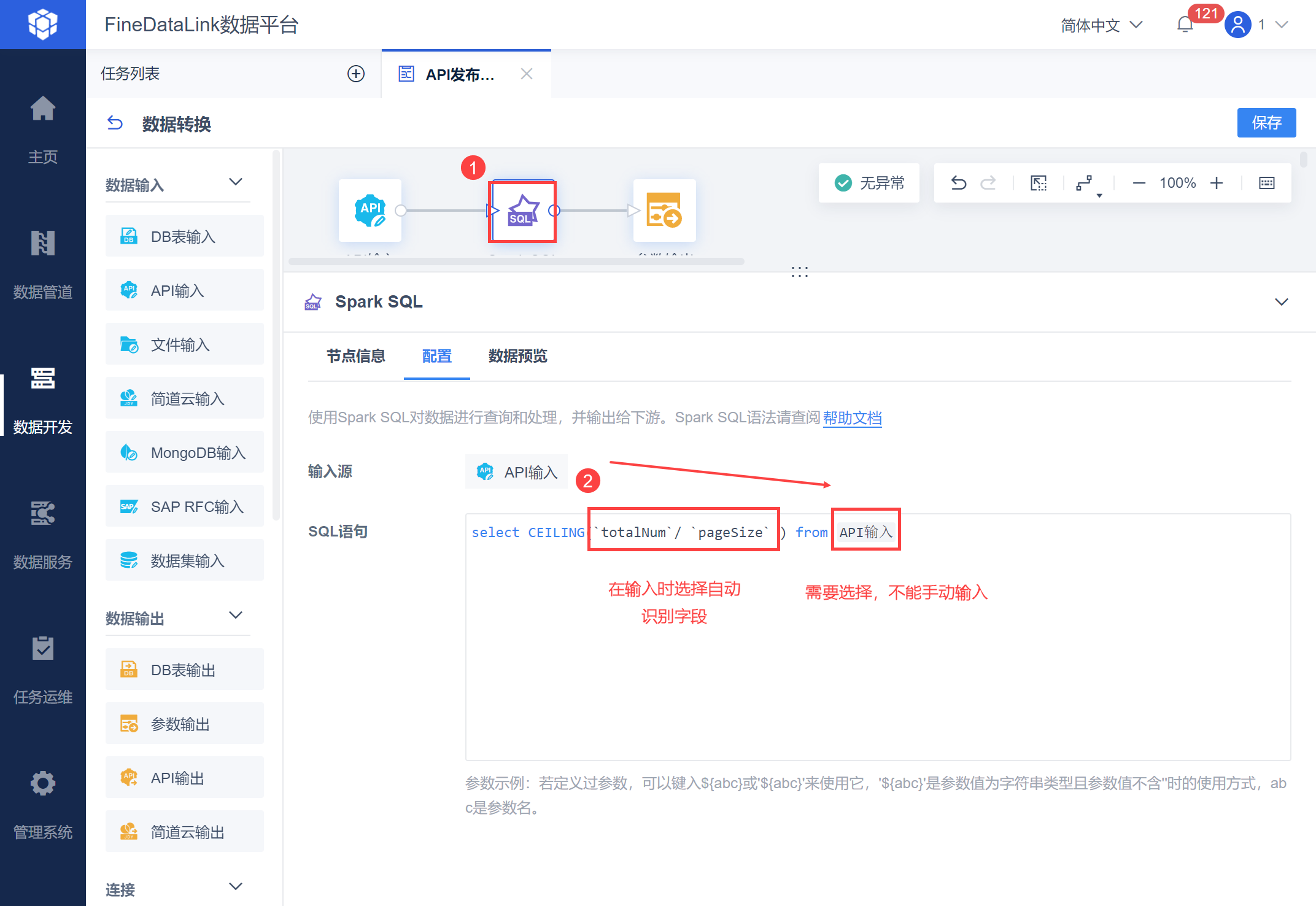
使用 SparkSQL 输入如下公式:
select CEILING(`totalNum`/ `pageSize` ) from API输入
注:totalNum、pageSize 都需要在输入时选择自动识别出的字段,不能手动输入。
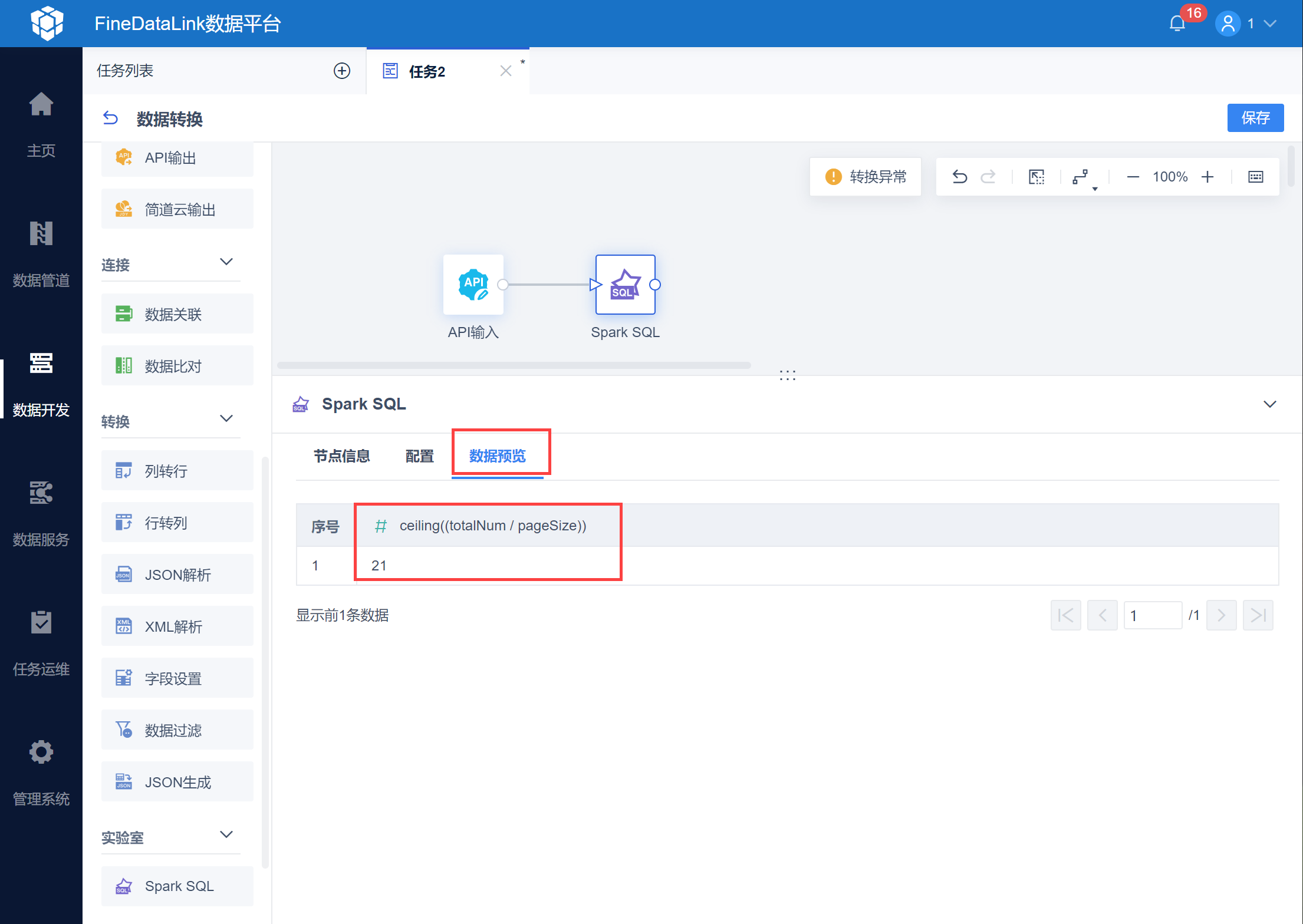
在数据预览界面就可以看到计算出的总页数,如下图所示:
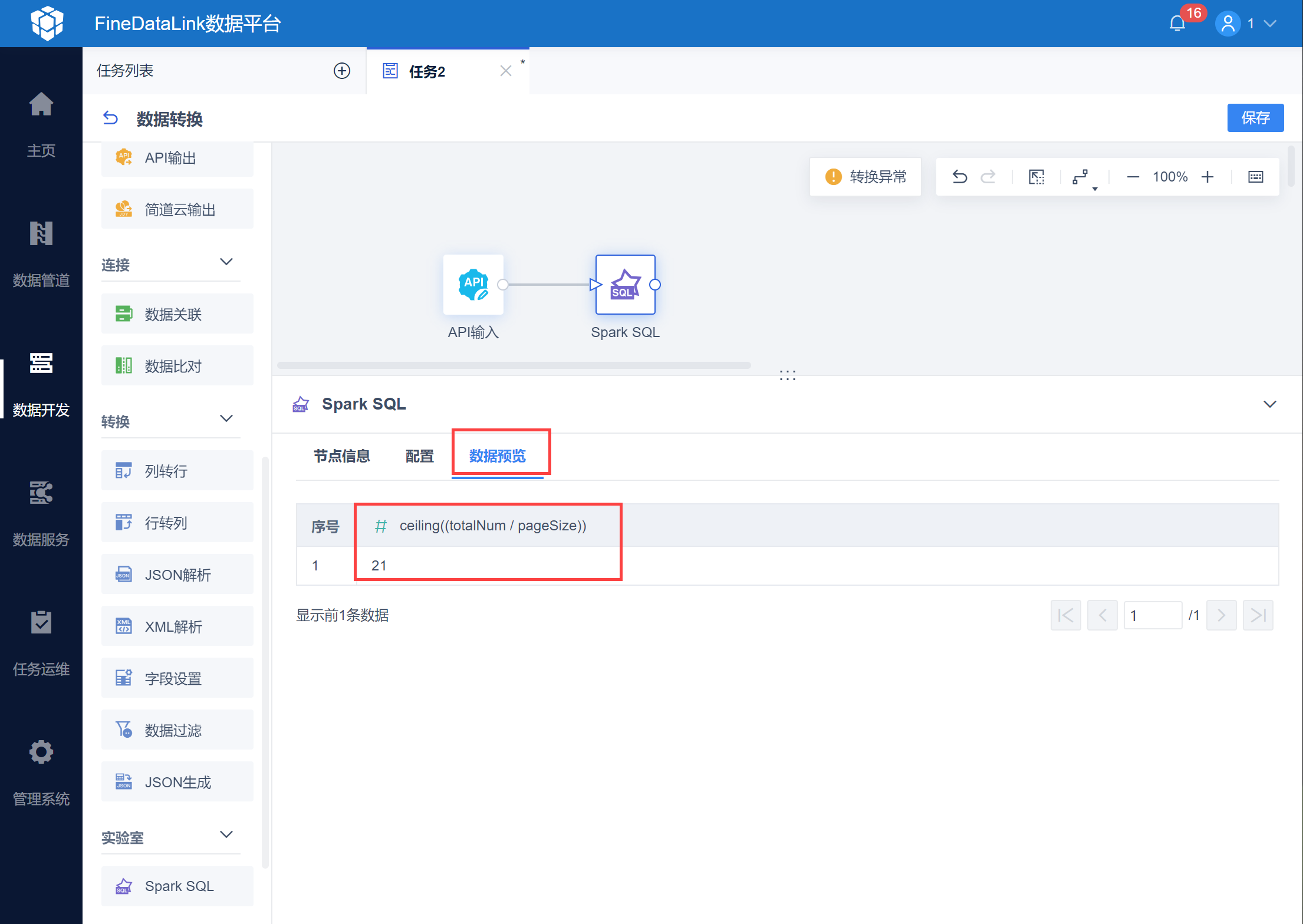
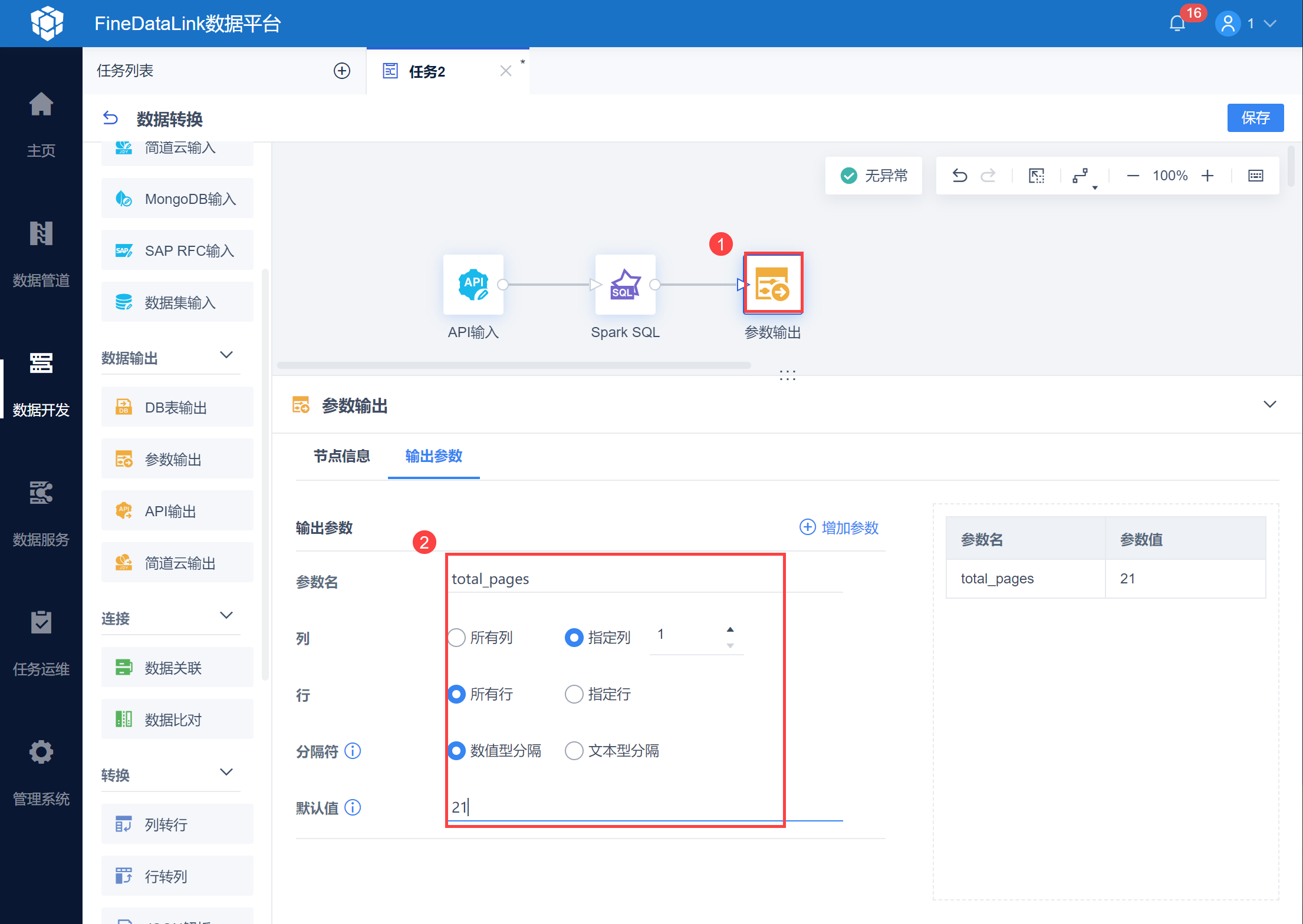
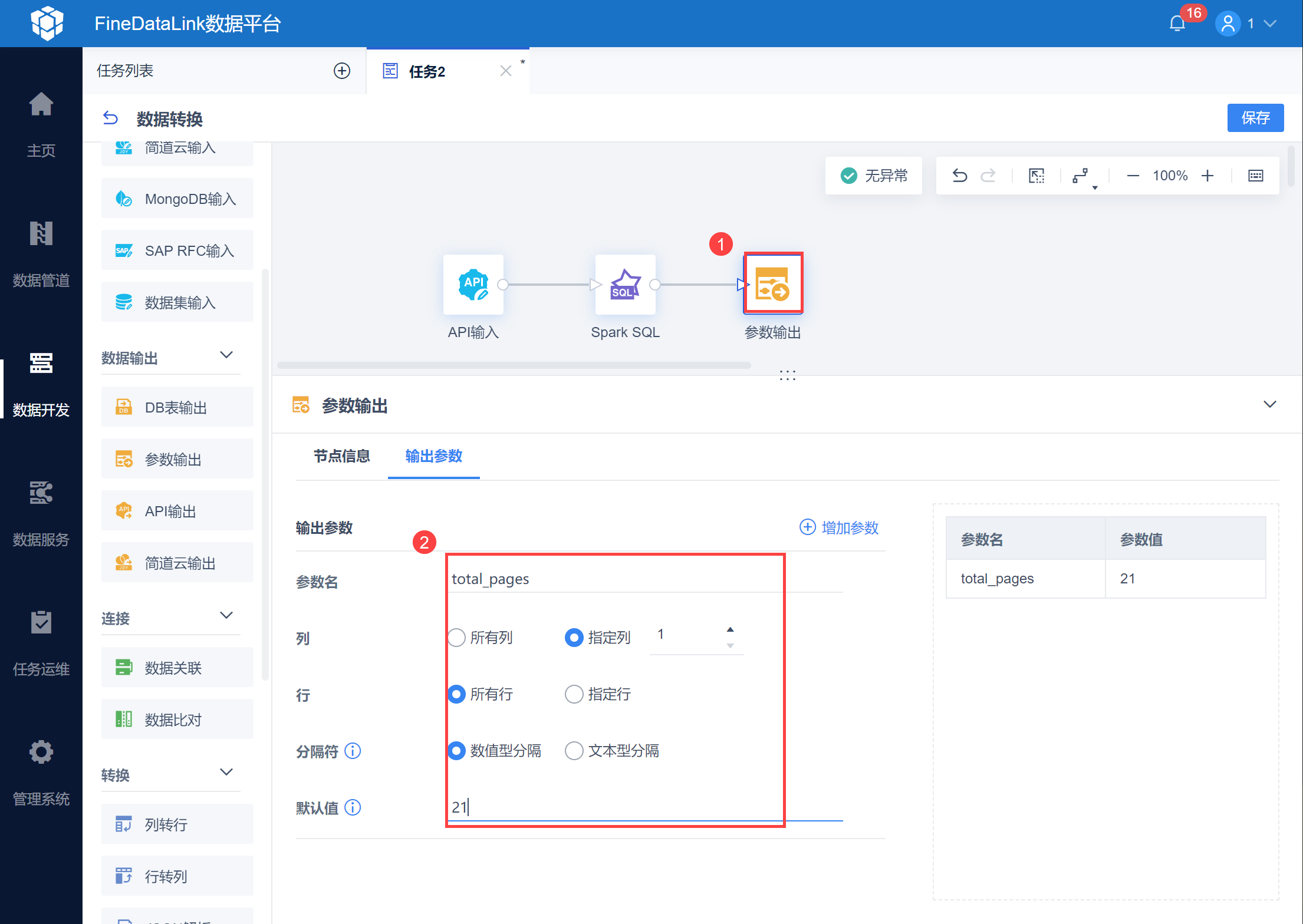
使用参数输出,将总页数设置为参数 total_pages ,如下图所示:
2.3 分批取数
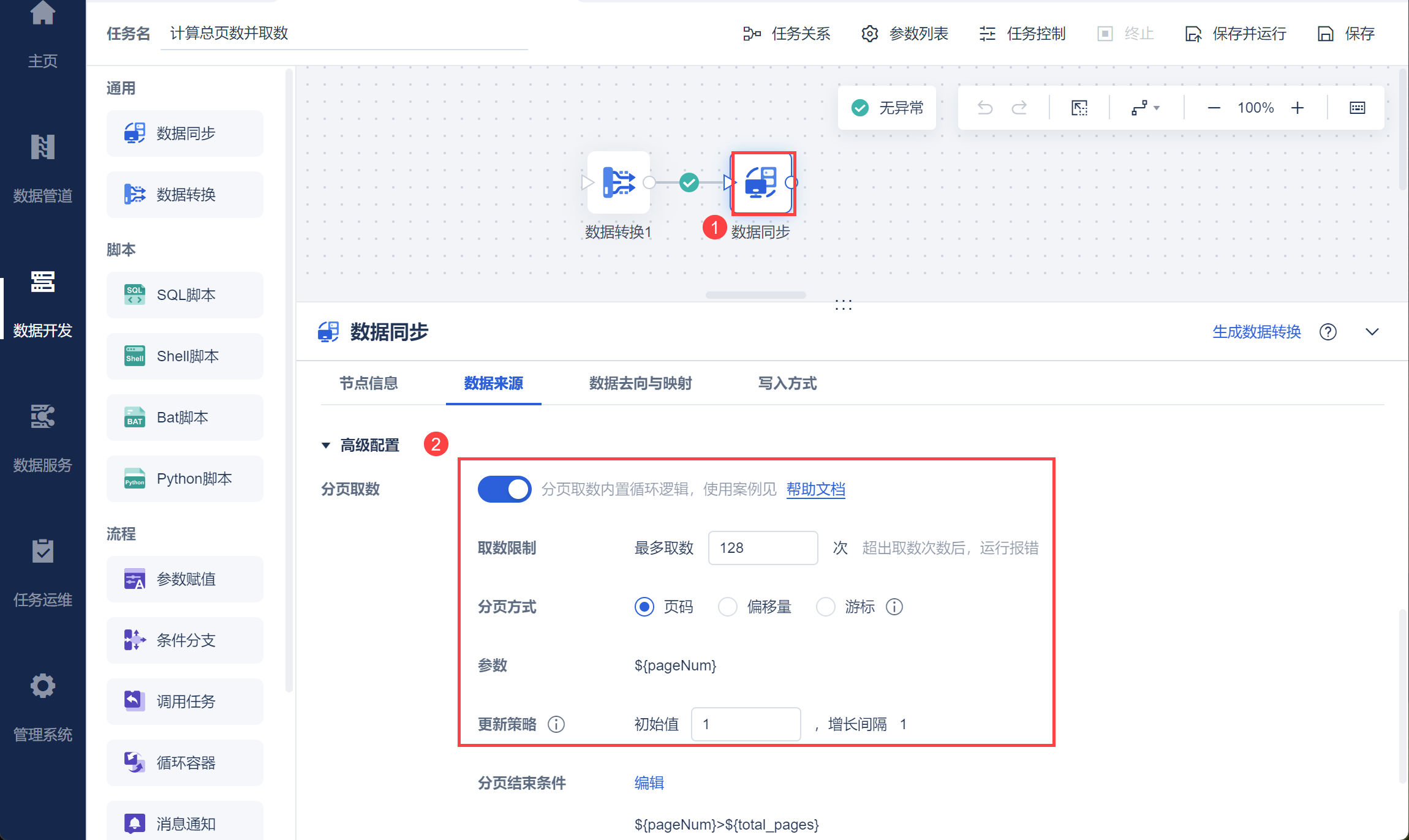
新增数据同步节点,选择 API 数据源后,勾选「分页取数」,设置取数逻辑,分页方式选择「页码」,更新策略为初始值 1 ,增长间隔 1,即按照设置的更新策略从第一页开始递增 ${pageNum}页数参数,从接口取数。该参数即可实现按照页数递增取出所有的数据。如下图所示:
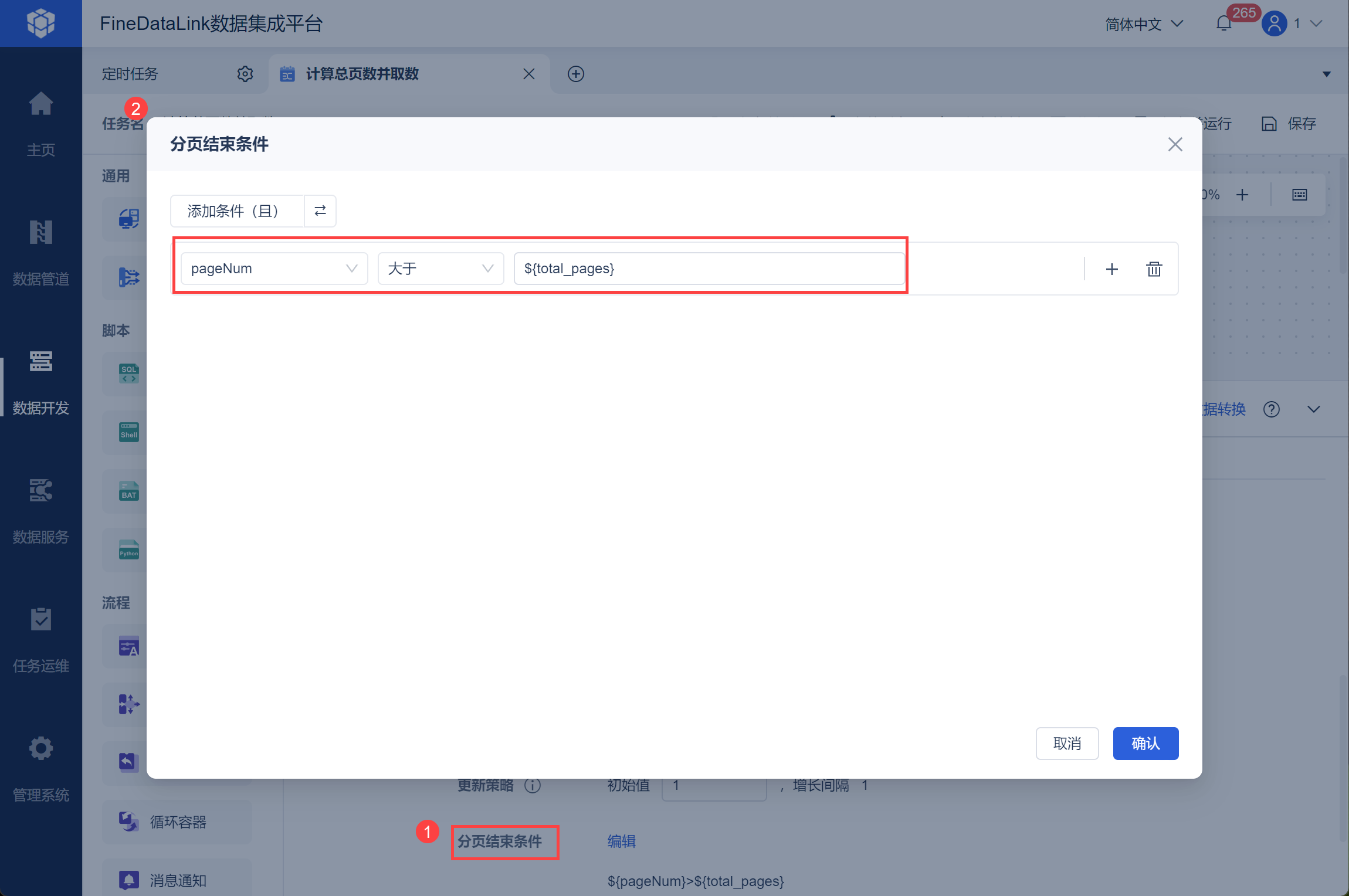
当页数参数 ${pageNum} 递增到大于总页数参数,则${total_pages},则分页结束,如下图所示:
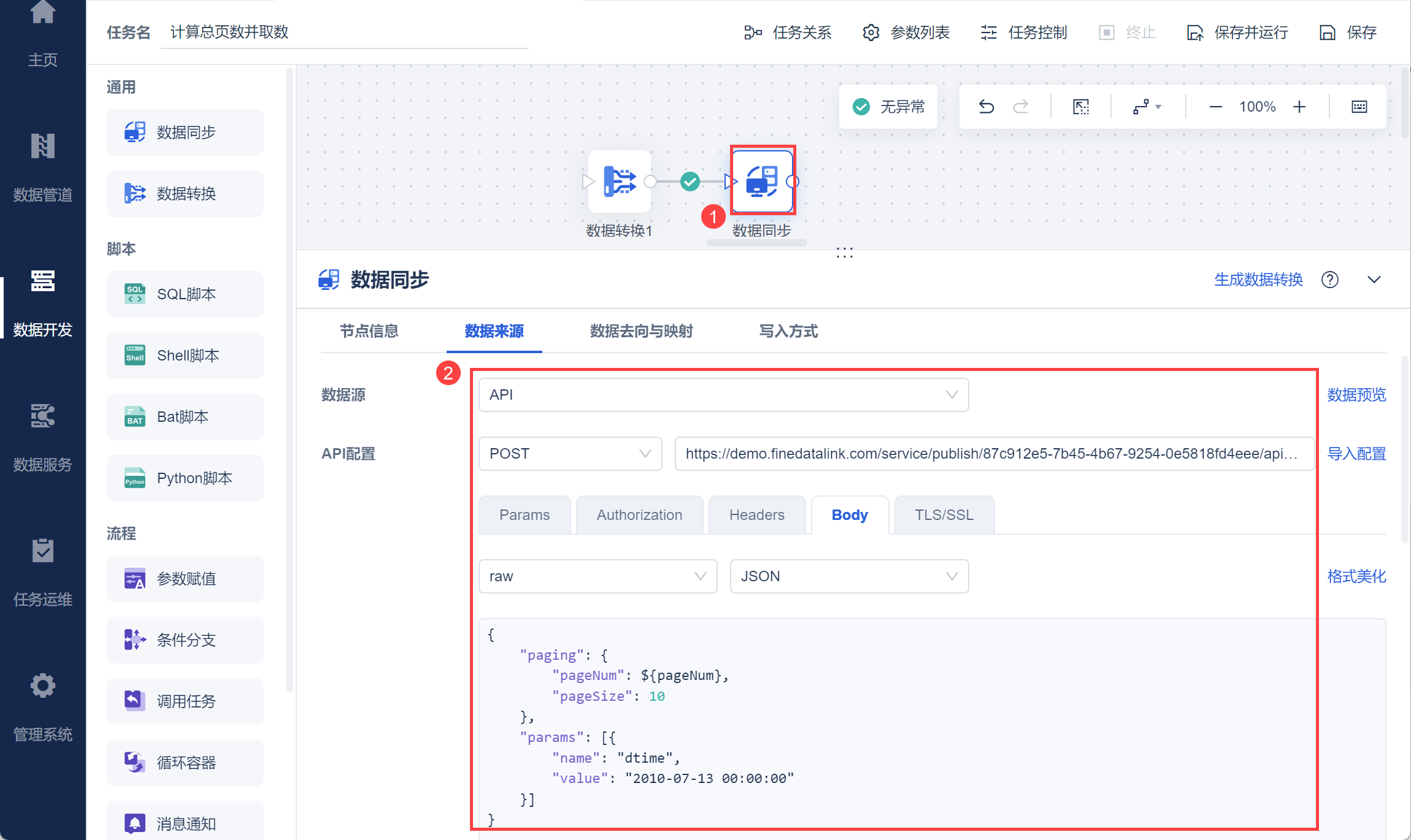
在数据同步中写入 API 配置,并设置参数名:pageSize,参数值:10,pageNum 使用分页参数 ${pageNum} ,也就是按照每页 10 条数据,从第一页开始递增从接口取数,如下图所示:
注:此处为了保证总页数一致,设置的 pageSize 需要与 2.2 节相同。
由于返回值为 JSON 格式,可以使用 JSON 格式取出指定的数据,如下图所示:
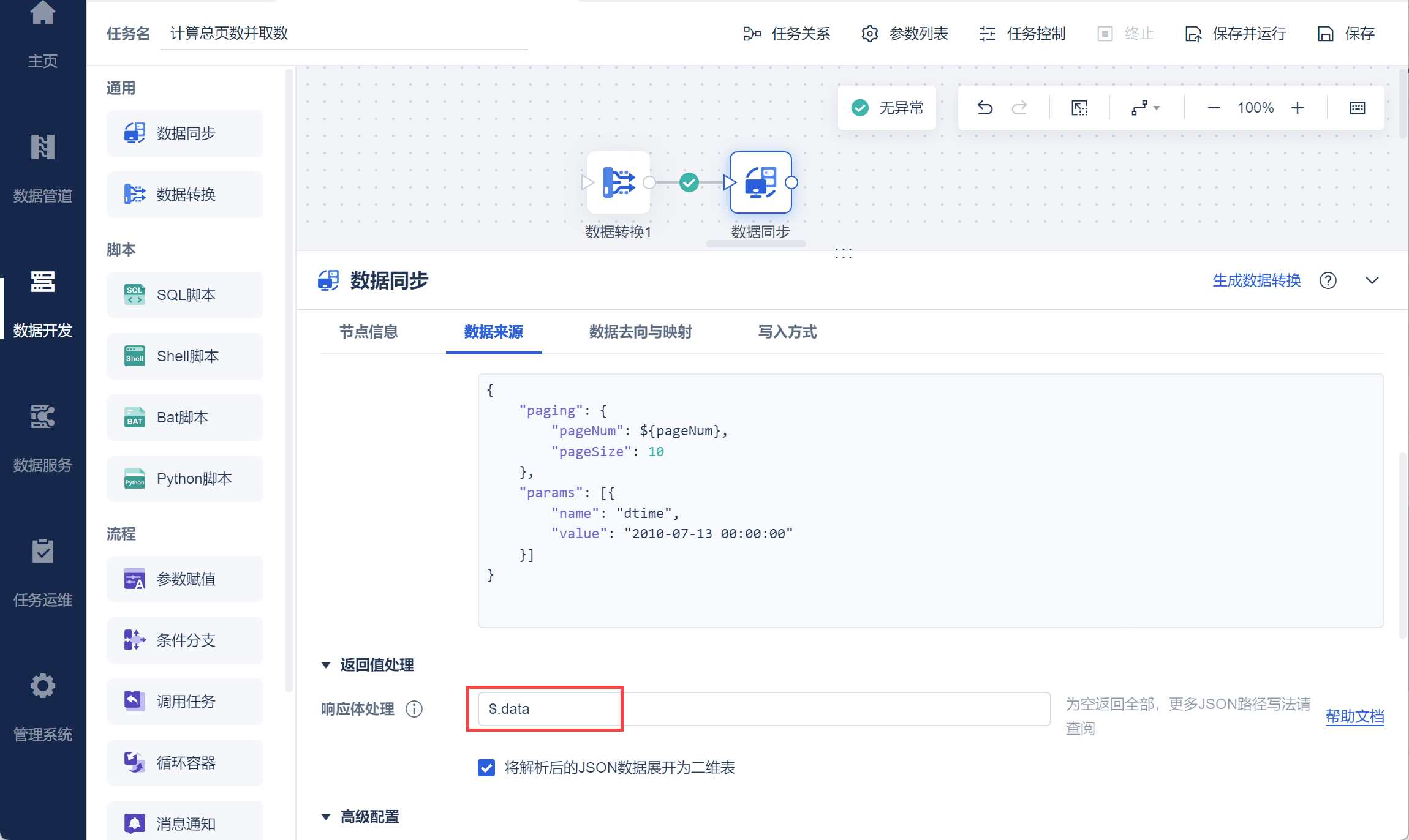
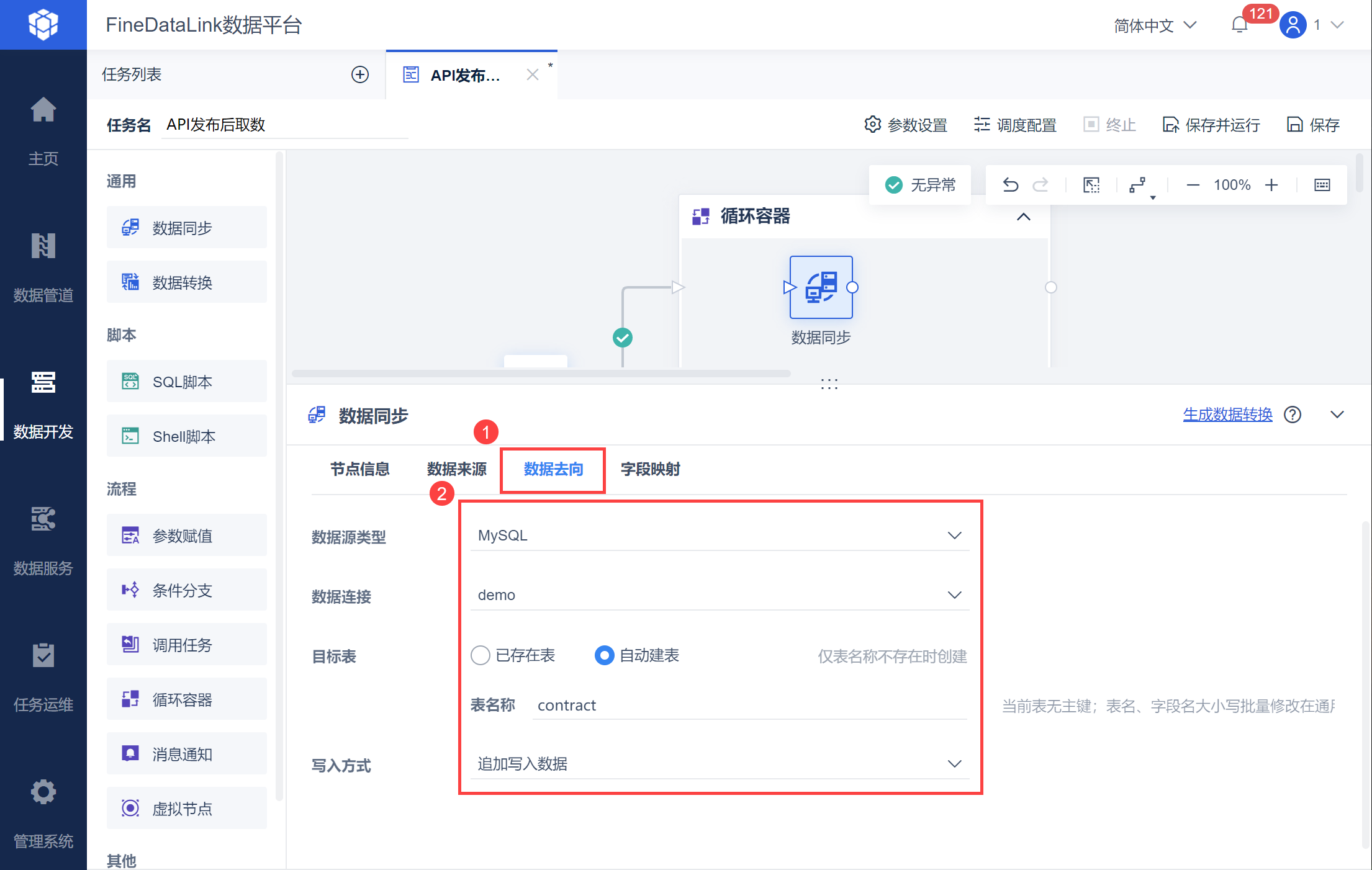
在数据去向中设置指定的输出数据库以及数据表,如下图所示:
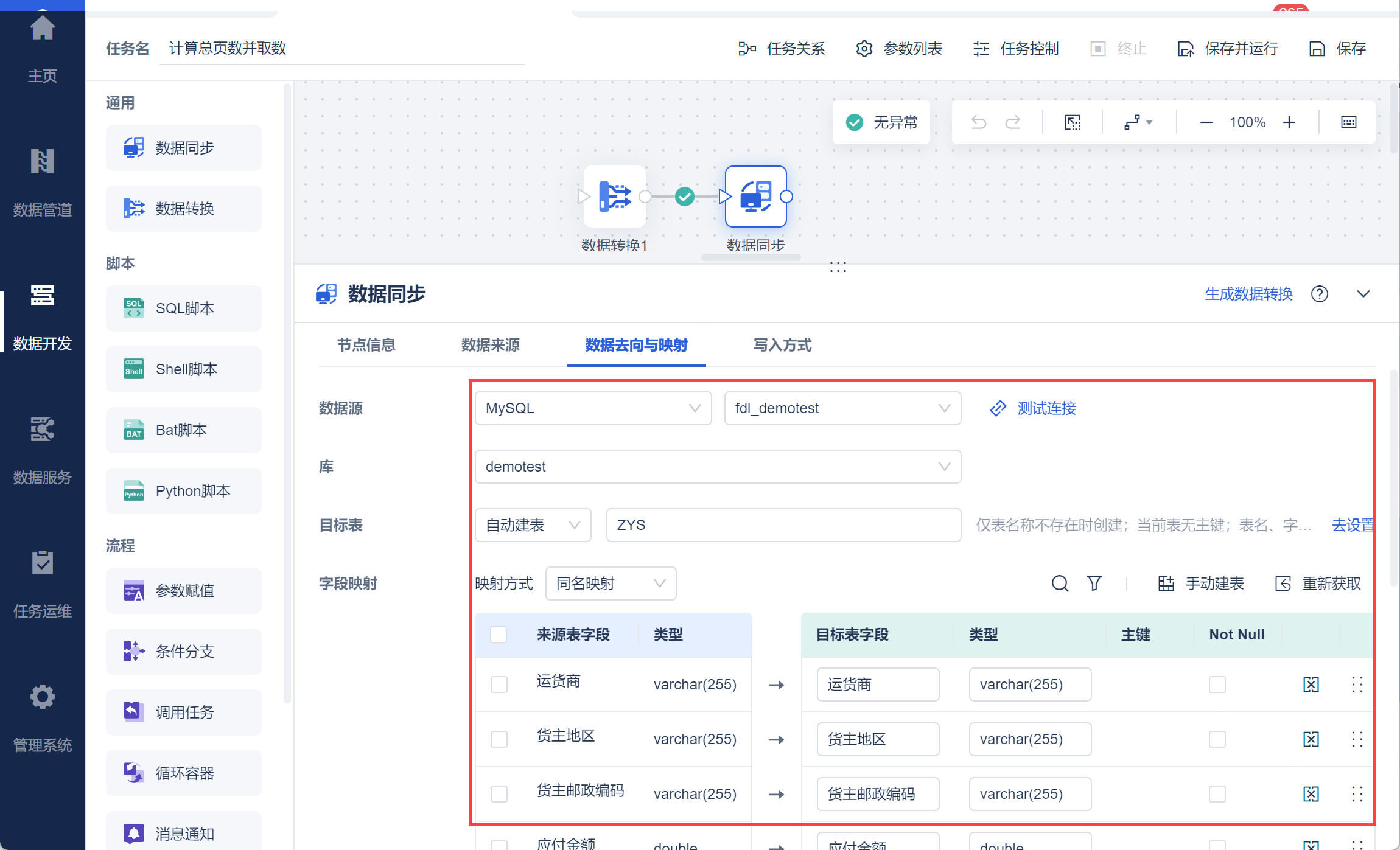
2.4 效果查看
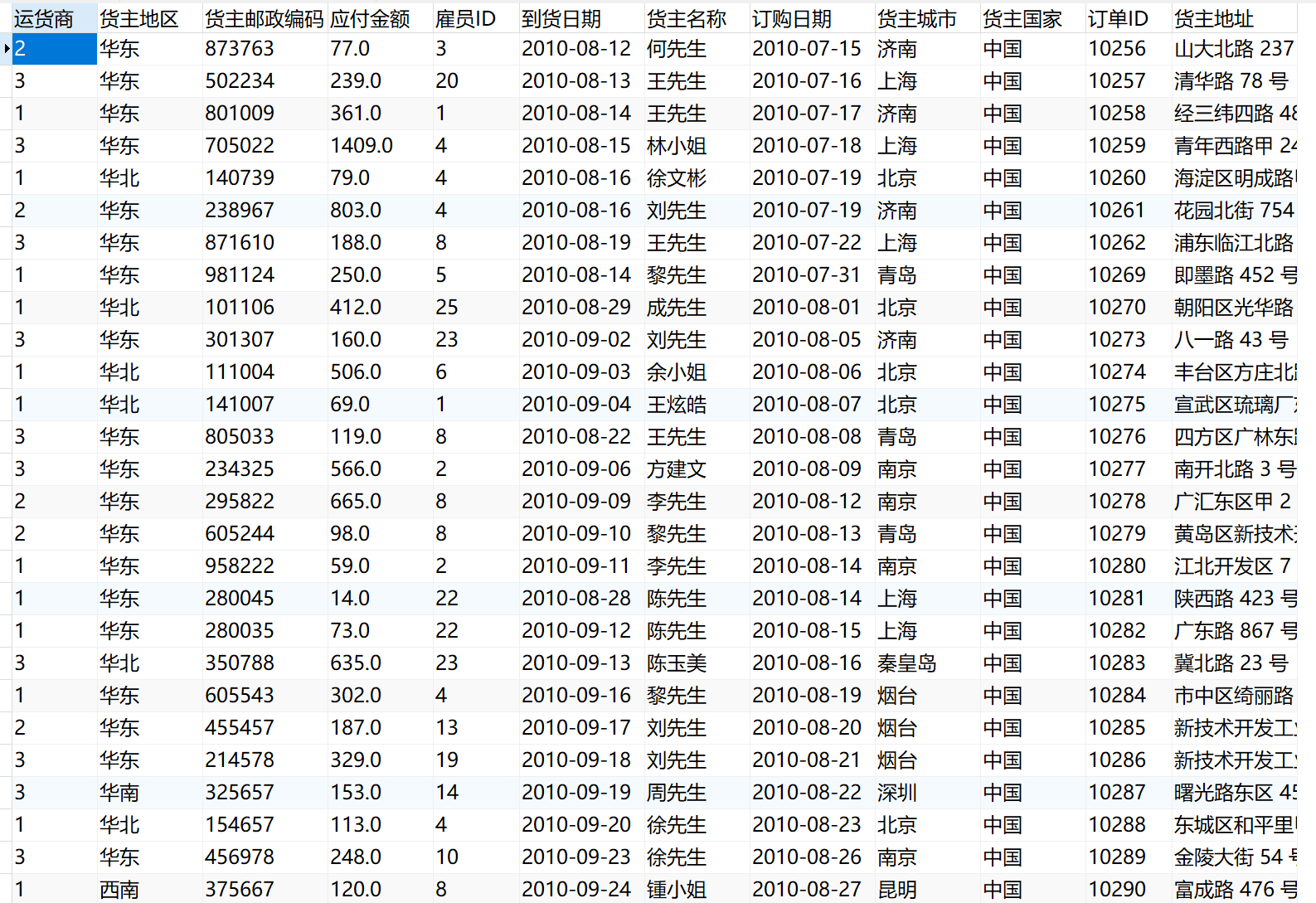
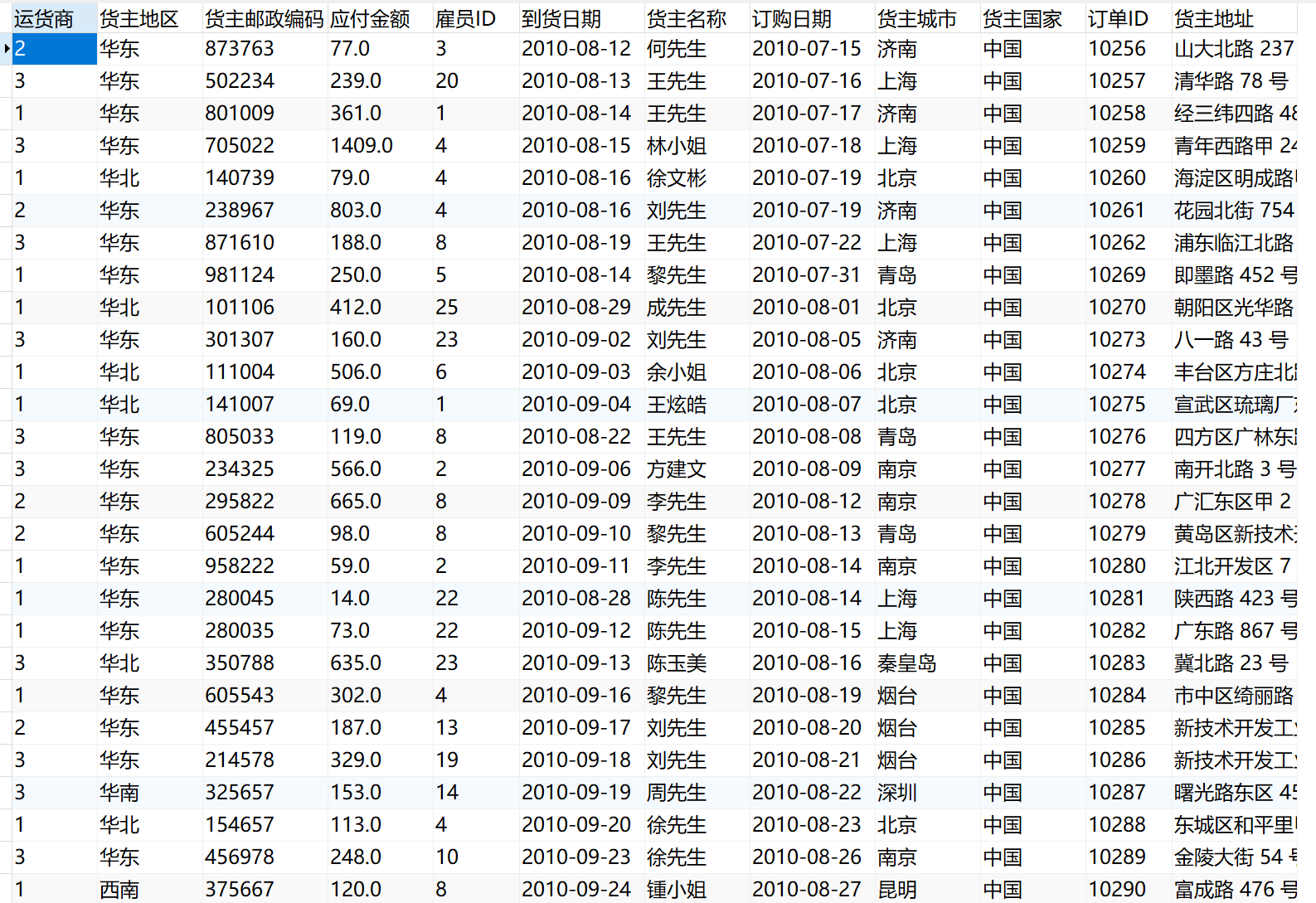
保存并运行任务后,此时在数据库中即可取出全部工单数据,如下图所示:
以下为 4.1.3 之前的版本方案。
| 点击展开更多 | |||||||||||||||||||||||||||||||||||||||||
1. 概述编辑1.1 应用场景某企业现在需要将某业务数据全部取出以供业务分析使用。 由于数据量比较大,不可能一次性取全量数据,因此需要使用参数。 接口文档中 pageNum 表示数据页数;pageSize 表示在每一页的数据条数。 和API取数-按页数取数 不同的是,接口返回值中没有总页数 total_pages,需要手动计算。 1.2 接口说明需要取数的 API 接口说明如下: 请求说明:
请求body参数:
请求示例: 返回值参数:
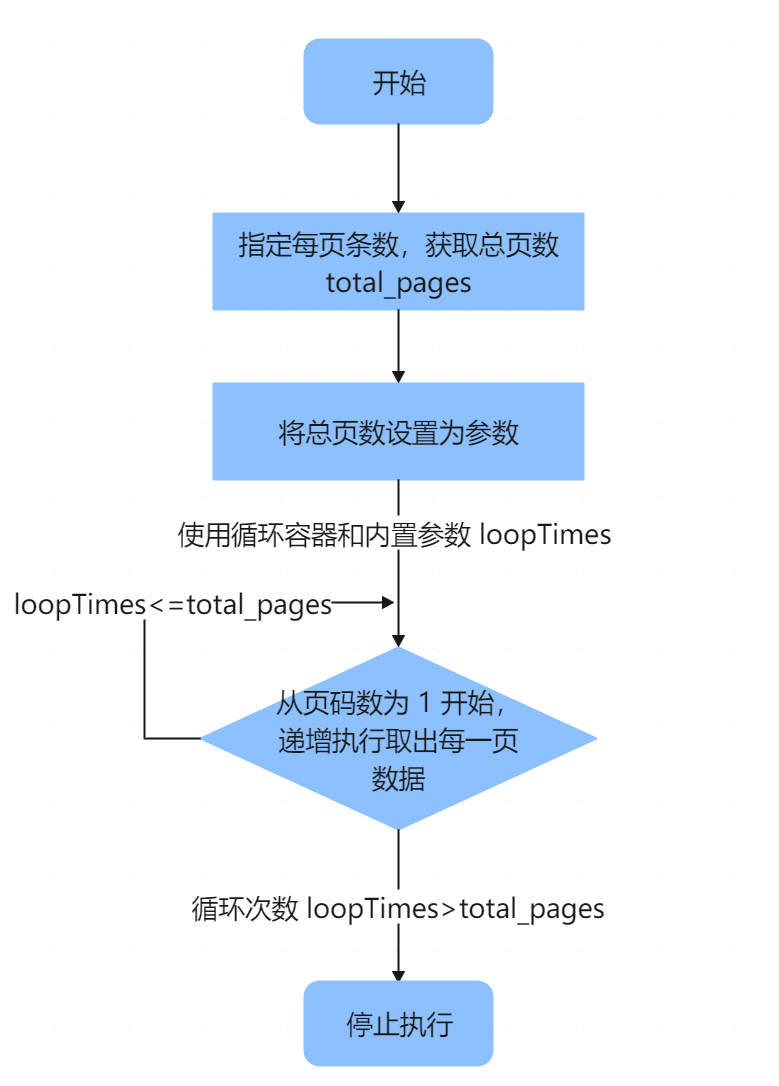
1.3 实现思路接口取数时,通常不会一次性取出全量数据,因此使用参数,分批从接口中取出全量数据。 从接口中获取 pageNum 和 pageSize 返回值,并使用 SparkSQL 计算出数据总页数 total_pages,将其作为参数,也就是需要执行的次数; 使用循环容器和内置参数 loopTimes,首次执行 pageNum 页码数为 1 ,然后递增执行取出每一页的数据,当循环次数 loopTimes<=total_pages 继续执行,当循环次数 loopTimes>total_pages 时,停止执行。
FineDataLink 中的数据处理过程,详情参见:https://demo.finedatalink.com/ 「API取数-计算总页数并按页取数」。
2. 操作步骤编辑2.1 设置 API 基本信息新建一个定时任务,由于需要将 API 数据解析计算后获取总页数值作为参数,因此需要使用「数据转换」节点。 在数据转换中,选择「API输入」并选择POST请求方式,输入复制的API链接,如下图所示:
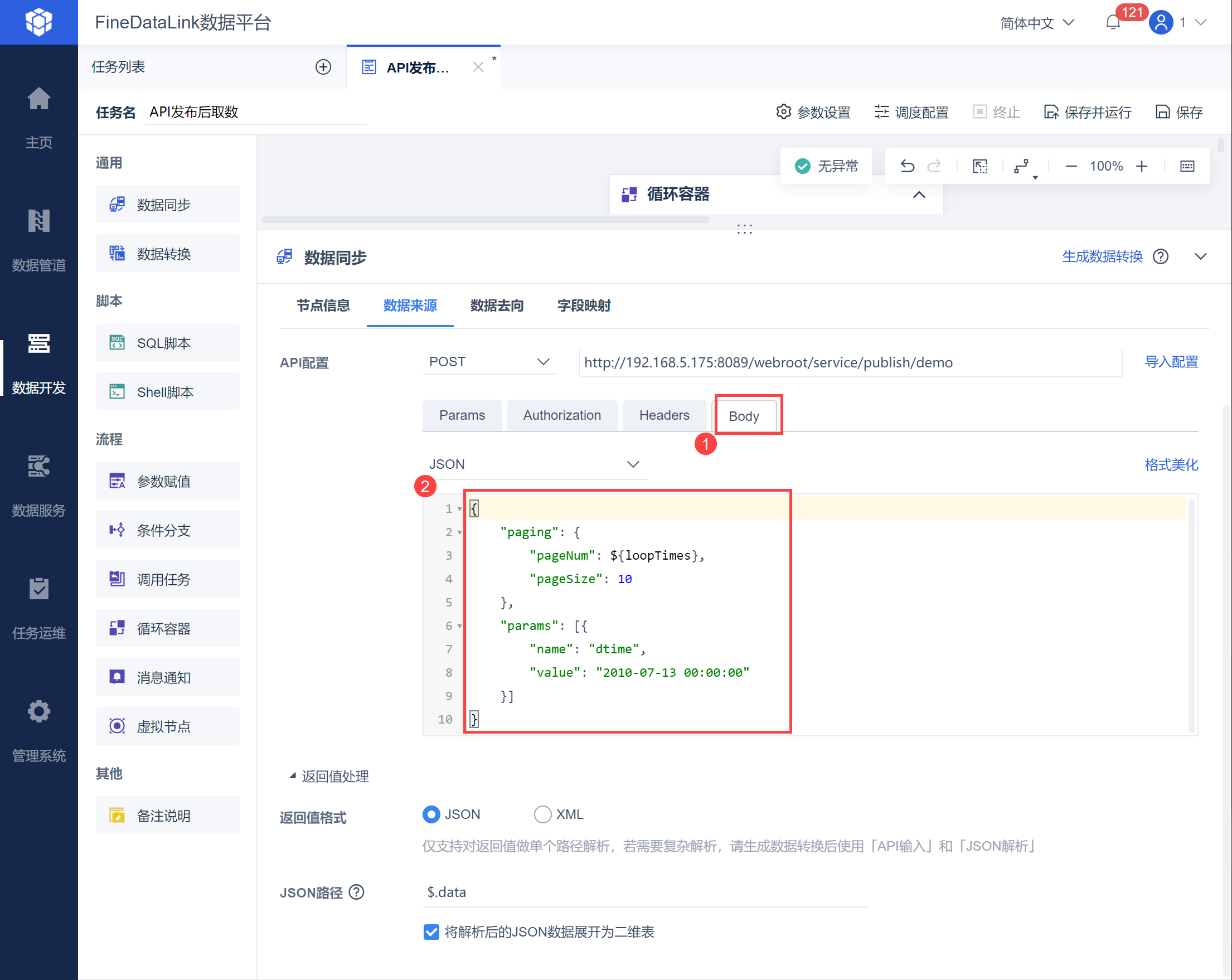
若有认证,则设置认证方式。 然后在Body 中输入 json 数据,如下图所示: 示例取出 2010-07-13 00:00:00 之后的数据,因此自定义参数 dtime 的 value 直接写成 2010-07-13 00:00:00,将 pageSize 设置为 10,也就是每页数据限制为 10 条,从第一个开始取数,查看返回值中,每页 10 条数据计算总页数为多少。
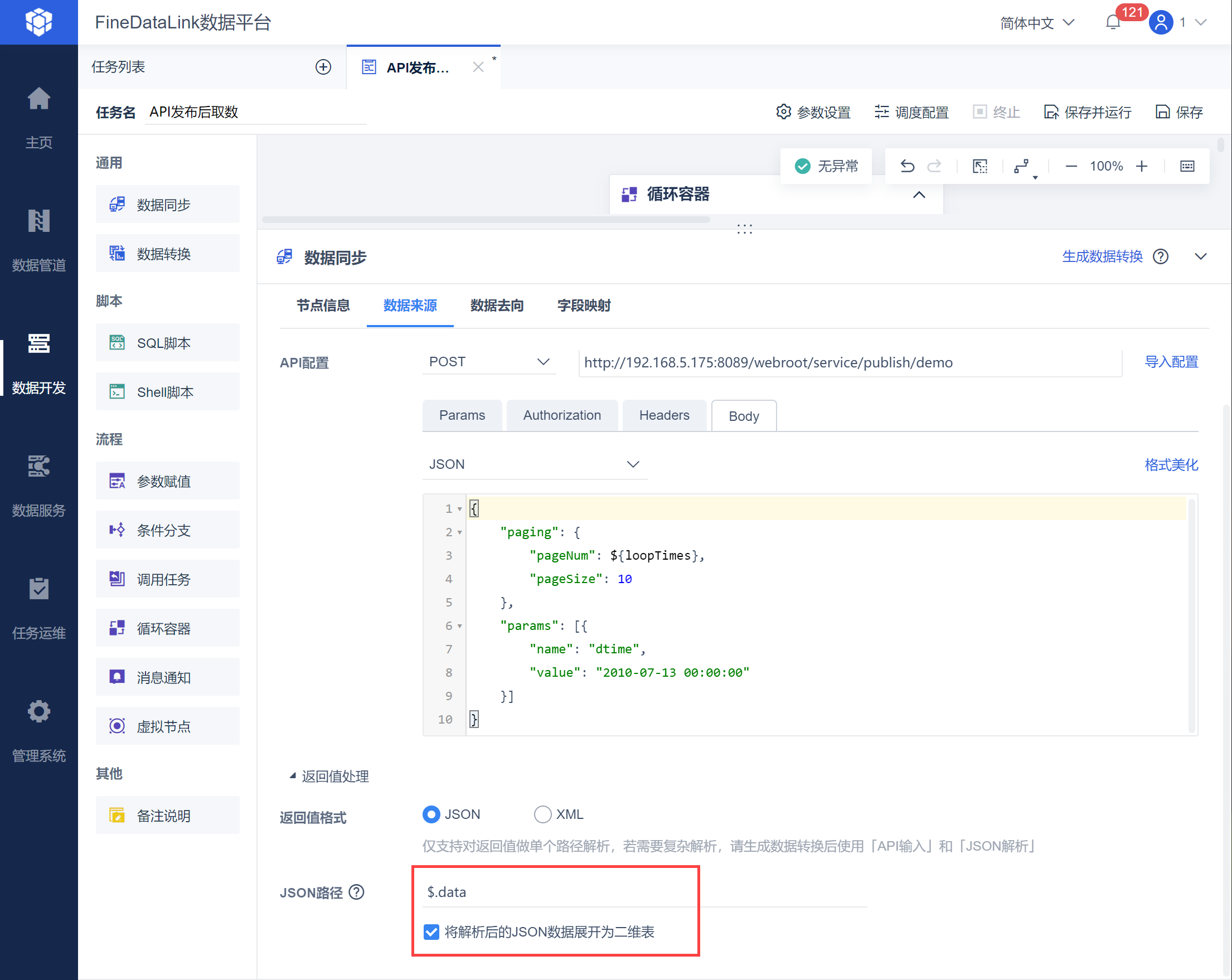
解析后的返回值如下图所示:
2.2 获取数据总页数使用获取到的 totalNum:返回总数据条数和 pageSize:每页数据条数进行计算,获取总页数。 使用 SparkSQL 输入如下公式: select CEILING(`totalNum`/ `pageSize` ) from API输入 注:totalNum、pageSize 都需要在输入时选择自动识别出的字段,不能手动输入。
在数据预览界面就可以看到计算出的总页数,如下图所示:
使用参数输出,将总页数设置为参数 total_pages ,如下图所示:
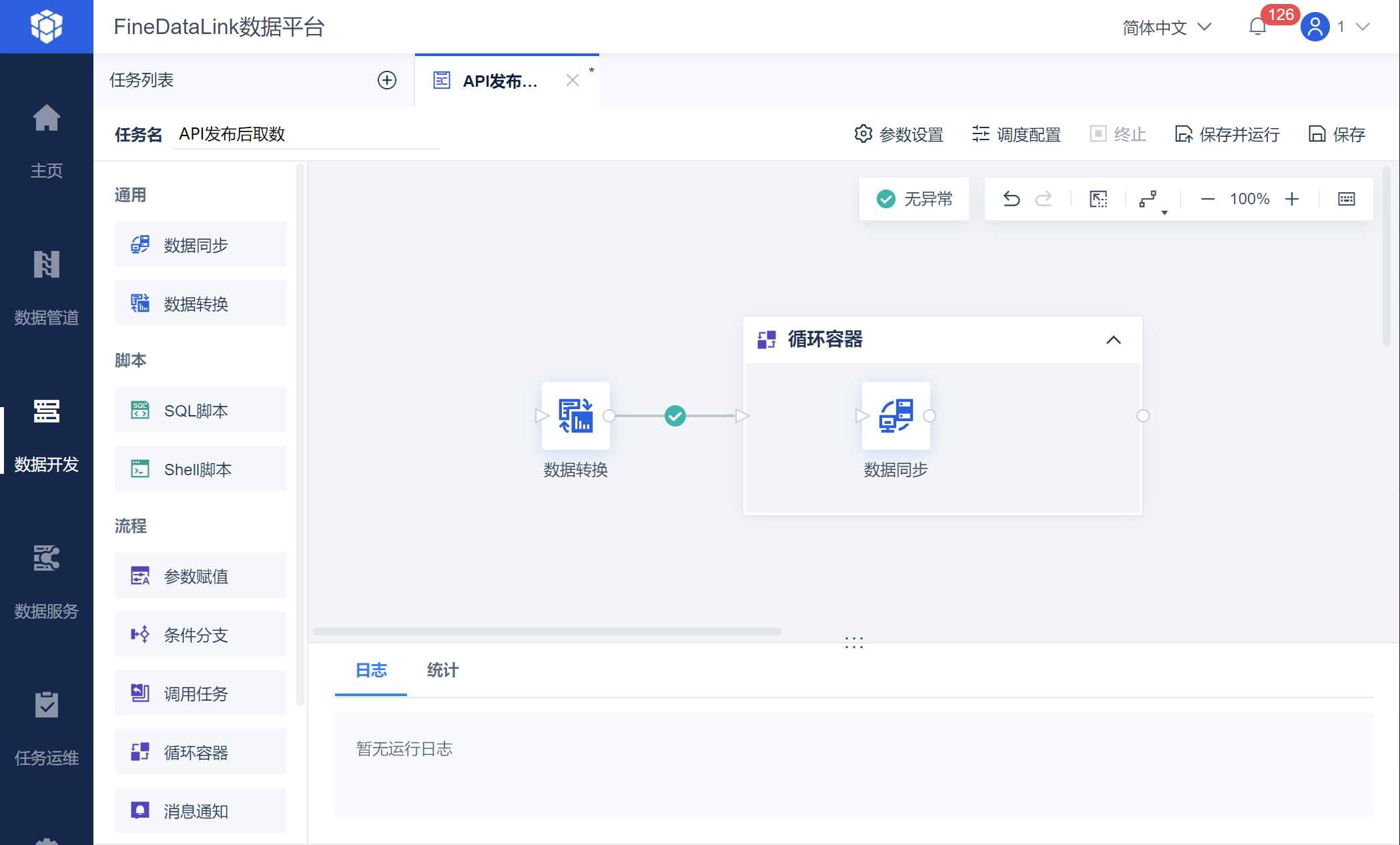
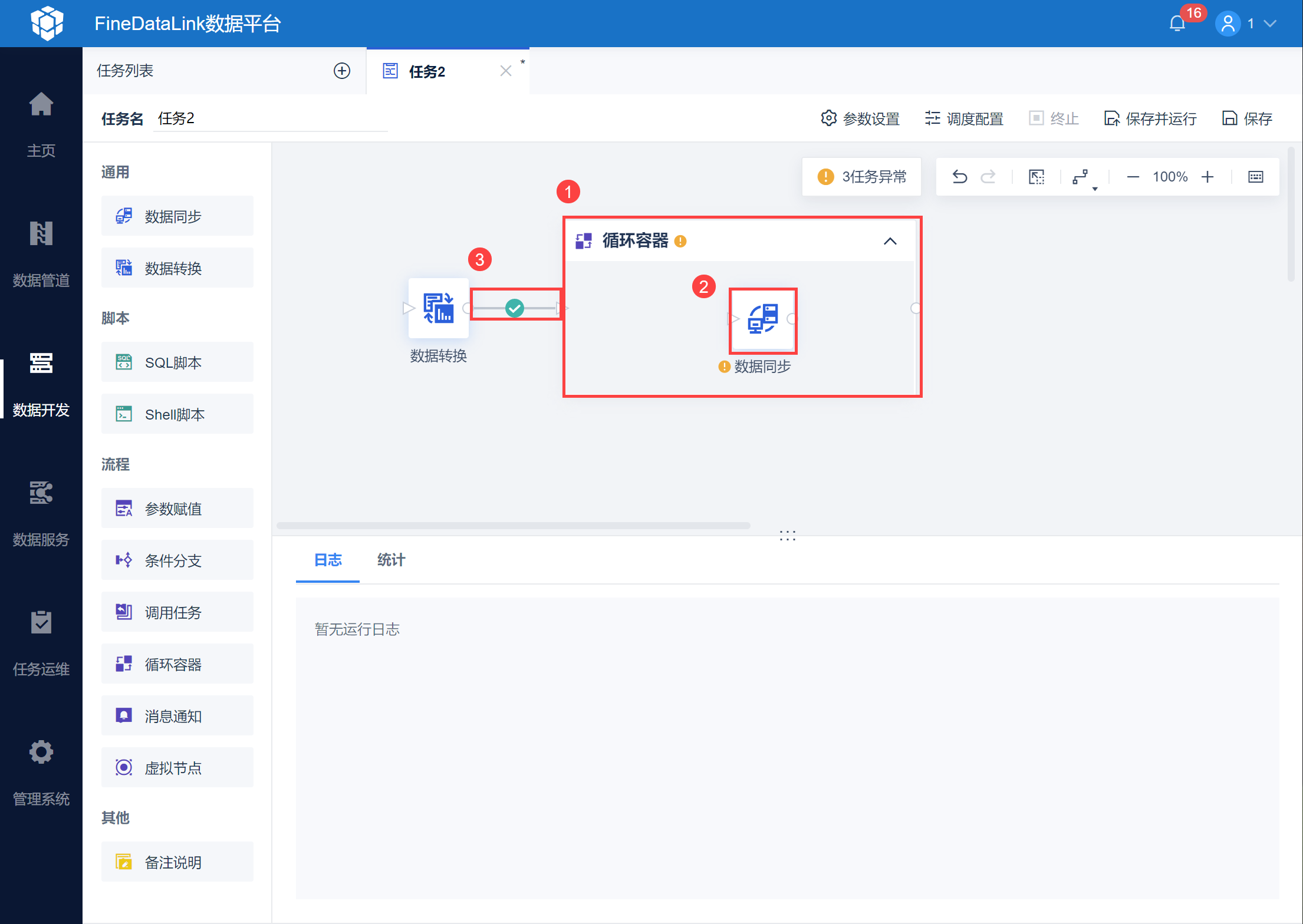
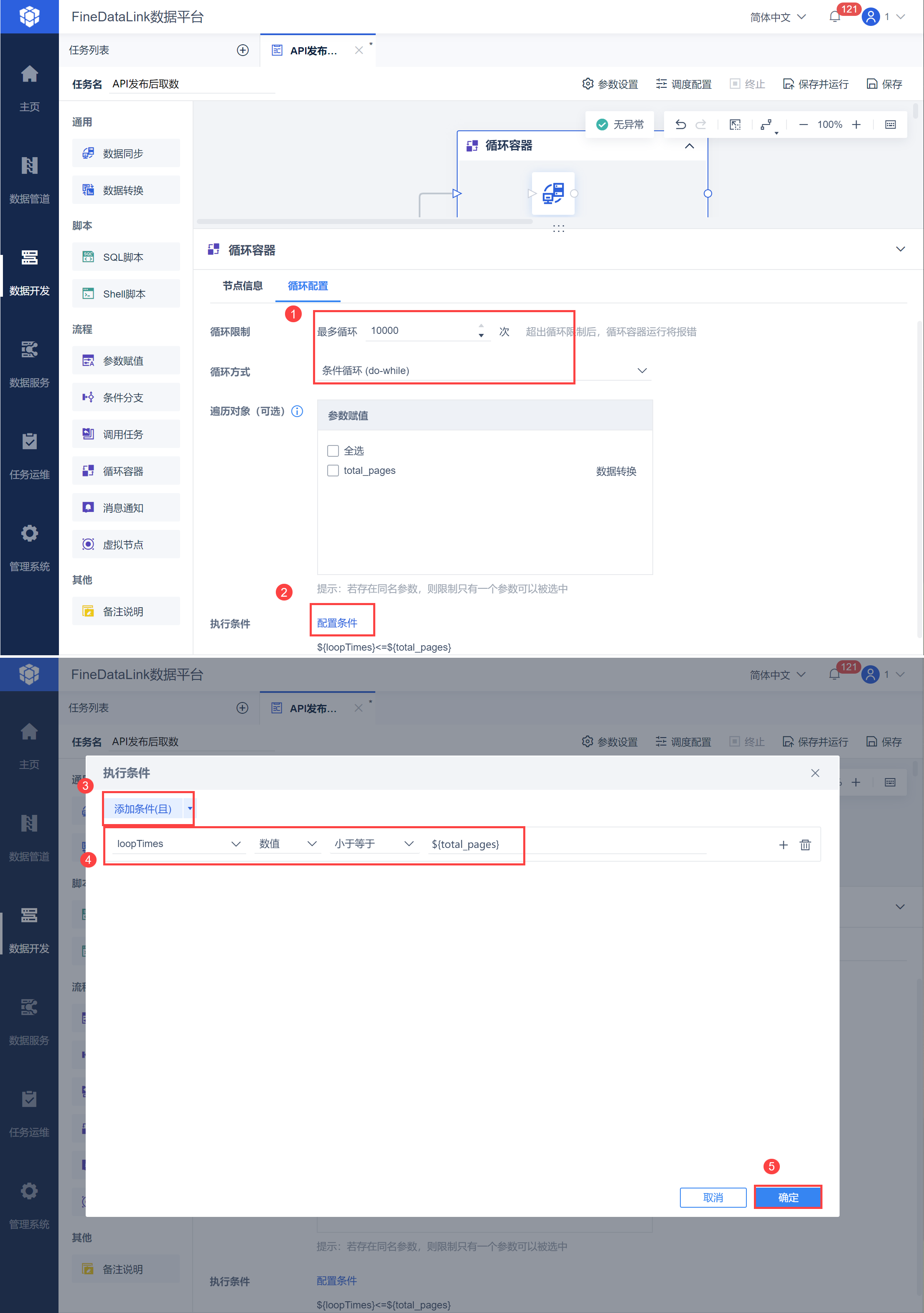
2.3 分批取数由于需要进行页数分批取出所有数据,因此使用循环容器功能。 保存数据转换节点设置后,进入任务开发界面,拖入循环容器节点,然后再拖入数据同步节点至循环容器中,与上游的数据转换相连,如下图所示:
在数据同步中仍然进行 API 取数的设置,如下图所示:
loopTimes 为循环容器内置参数,容器内当前循环次数,初次为 1 ,后续每次循环递增加。该参数即可实现按照页数递增取出所有的数据。 在 Body 中设置 pageSize:10,pageNum 使用内置参数${loopTimes},也就是按照每页 10 条数据,从第一页开始递增从接口取数,如下图所示:
由于返回值为 JSON 格式,可以使用 JSON 格式取出指定的数据,如下图所示:
在数据去向中设置指定的输出数据库以及数据表,如下图所示:
点击循环容器节点,设置循环次数,并设置循环方式为「条件循环」,点击配置条件为 loopTimes<=${total_pages},如下图所示: 此时即可实现当递增的页数大于总页数时,跳出循环停止执行,从而取出所有的数据。
2.4 效果查看执行任务后,即可在数据库中查看到取出的数据,如下图所示:
| |||||||||||||||||||||||||||||||||||||||||