

1. 并发数编辑
1.1 问题描述
由于 FineDataLink 中定时任务需要占用内存和并发资源等,因此用户可能需要根据实际的使用情况进行任务调整。
阅读此部分,你可以解决和理解如下问题:
问题一:如何配置数据同步任务的并发数?
问题二:为什么我的定时任务跑的比较慢,实际运行的并发数不够?
问题三:为什么我的定时任务并发数配置的很高,但是任务运行速度仍然很慢?
1.2 解释说明
并发数是指可以从源端并行读取和向目标存储端并行写出数据的最大线程数。
并发数详细说明参见:并发控制
为了提高数据同步的效率,可以适当调整任务的并发数,以缩短数据搬迁需要的时间。在产品中配置位置如图所示:
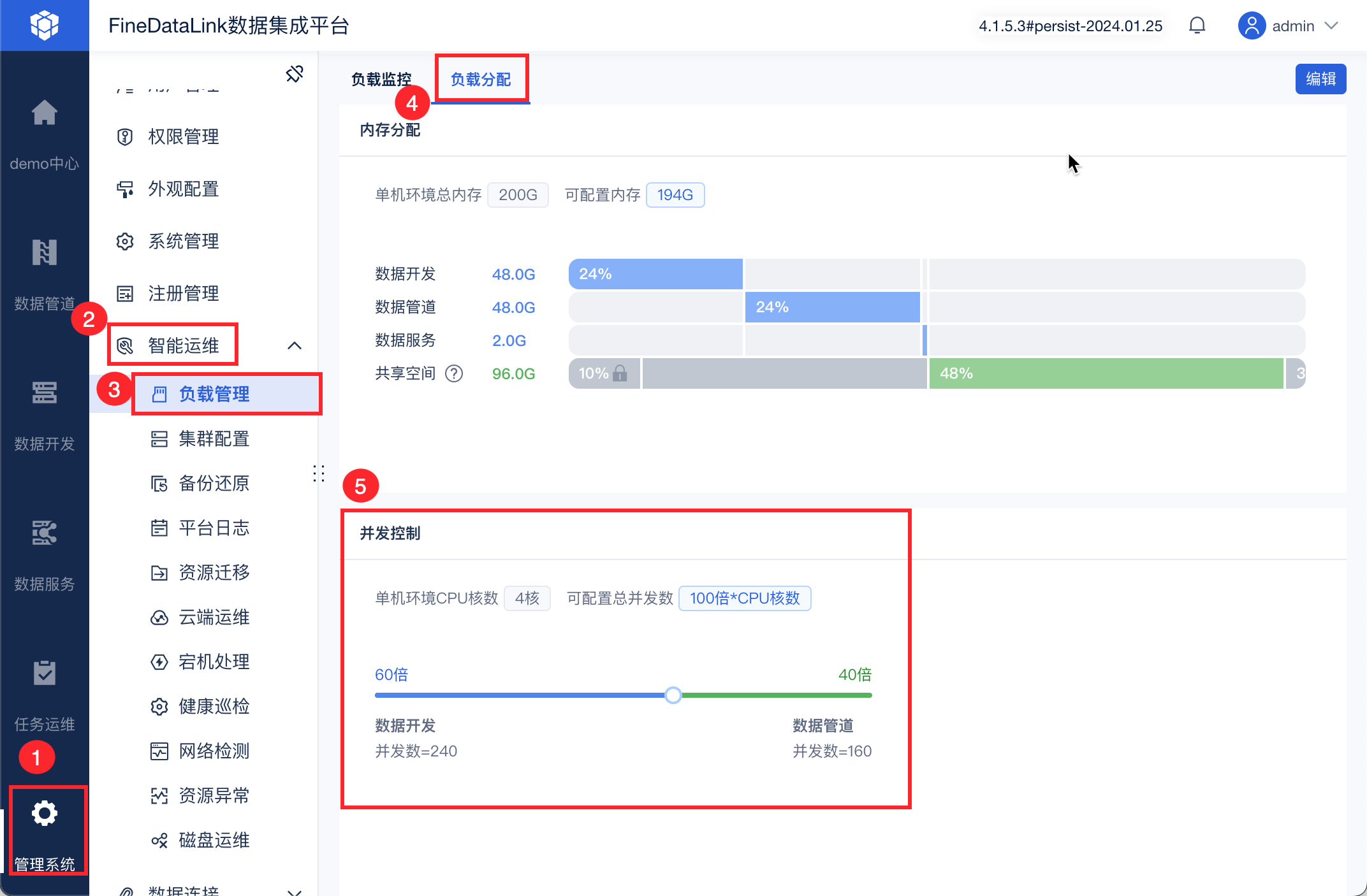
1.3 任务并发数配置最佳实践
任务并发数越大,任务运行需要抢占的资源越多,,即前面提交任务先抢占资源运行,后提交的任务后抢占资源运行。建议合理配置任务并发数,避免大并发任务长时间运行,进而阻塞后续任务获得资源得到执行。
小数据量的数据表建议配置小并发,小并发需要的执行资源比较少,有利于任务快速抢占碎片资源得到运行。由于数据量比较小执行耗时可以控制在合理的范围内。
同一个数据源上同步任务,建议错峰运行,可以降低对数据源访问的并发压力。
2. 脏数据限制编辑
2.1 问题描述
阅读此部分,您可以解决和理解如下问题:
问题一:什么是数据同步的脏数据?
问题二:如何配置数据同步任务脏数据限制?
问题三:数据同步速率和脏数据有哪些关联关系?
2.2 解释说明
脏数据限制能力用来控制任务在遇到脏数据时的行为,所谓脏数据是指数据条目在写入目标数据源过程中发生了异常,则此条数据被视为脏数据。由于各类异构系统对数据处理的复杂和差异性,目前策略是写入失败的数据均被归类于脏数据。在一些数据同步场景,脏数据的出现会导致任务同步效率下降,以关系数据库写出为例,默认是执行batch批量写出模式,在遇到脏数据时会退化为单条写出模式(以找出batch批次数据具体哪一条是脏数据,保障正常数据正常写出),但单条写出效率会远低于batch写出模式,故遇到大量脏数据时会拖慢任务运行的最终效率。
目前数据集成绝大多数通道支持脏数据阈值限制能力,对于支持脏数据阈值限制的通道,常见配置场景介绍如下:
不配置脏数据限制:表示容忍所有出现的脏数据,遇到脏数据不会导致任务失败,任务配置errorLimit留空。
配置脏数据限制为0:表示不容忍任何脏数据,在出现超出1条脏数据时,任务会失败退出。
配置脏数据限制为一个正整数N:表示最多容忍N条脏数据,在脏数据超过N条时,任务会失败退出。
2.3 最佳实践
关系数据库(MySQL、SQL Server、PostgreSQL、Oracle、Polardb、Polardb-X等)、Hologres、ClickHouse、AnalyticDB for MySQL等对于数据要求比较敏感的场景,建议配置脏数据限制为0,以及时发现数据质量风险。
对于数据要求不敏感的场景,建议不配置脏数据限制,或者配置一个业务上合理的脏数据阈值上限,以降低您日常脏数据处理运维负担。
关键任务配置任务失败和延迟告警,以及时发现线上问题。
可重跑的任务建议配置任务失败自动重跑,以降低偶发环境问题对任务的影响。