

1. 应用场景编辑
用户想要同步钉钉通信录中的用户信息。
2. 方案一编辑
4.1.3 以及之后的版本支持的方案。
2.1 实现思路
2.1.1 接口说明
本文方案主要使用的是 获取部门用户详情 接口,要使用该接口,需要获取:Query参数(access_token)、Body 参数(dept_id;cursor;size,size 为分页大小,最大为 100)。
dept_id 通过 循环获取所有部门ID 获得,得到 dept_id 字段。
cursor 为分页查询的游标,最开始传 0 ,后续传返回参数中的 next_cursor 值。
size 自定义即可,最大为 100 。
2.1.2 方案说明
实现过程如下图所示:
| 序号 | 说明 |
|---|---|
| 准备工作:参考 循环获取所有部门ID 方案,获得 dept_id 字段 | |
| 1 | 为调用 获取部门用户详情 接口做准备,准备参数access_token、dept_id 1)参数赋值节点:获取 access_token 2)参数赋值节点:将 dd_dep 的 dept_id 字段设置为参数,便于后续作为请求参数写入 获取部门用户详情 接口取数 |
| 2 | 调用 获取部门用户详情 接口,获取用户数据,用户数据如下图所示:
设置分页取数方式为「游标」,更新初始值0,更新值为返回参数中的 next_cursor,每次分页按照游标参数${cursor}取数。 分页结束条件为,当最后一次返回参数中,has_more 为 false 则表示没有数据了,停止分页取数。 |

2.2 操作步骤
2.2.1 准备工作
参考 循环获取所有部门ID 方案,得到 dd_dep 表,本文方案需要用到 dd_dep 表的 dept_id 字段。
需要确定应用是否有 通讯录部门成员读权限,本文示例使用的应用是企业内部应用。
本文方案主要使用的是 获取部门用户详情 接口,要使用该接口,需要获取:Query参数(access_token)、Body 参数(dept_id、cursor)。
2.2.2 获取 access_token
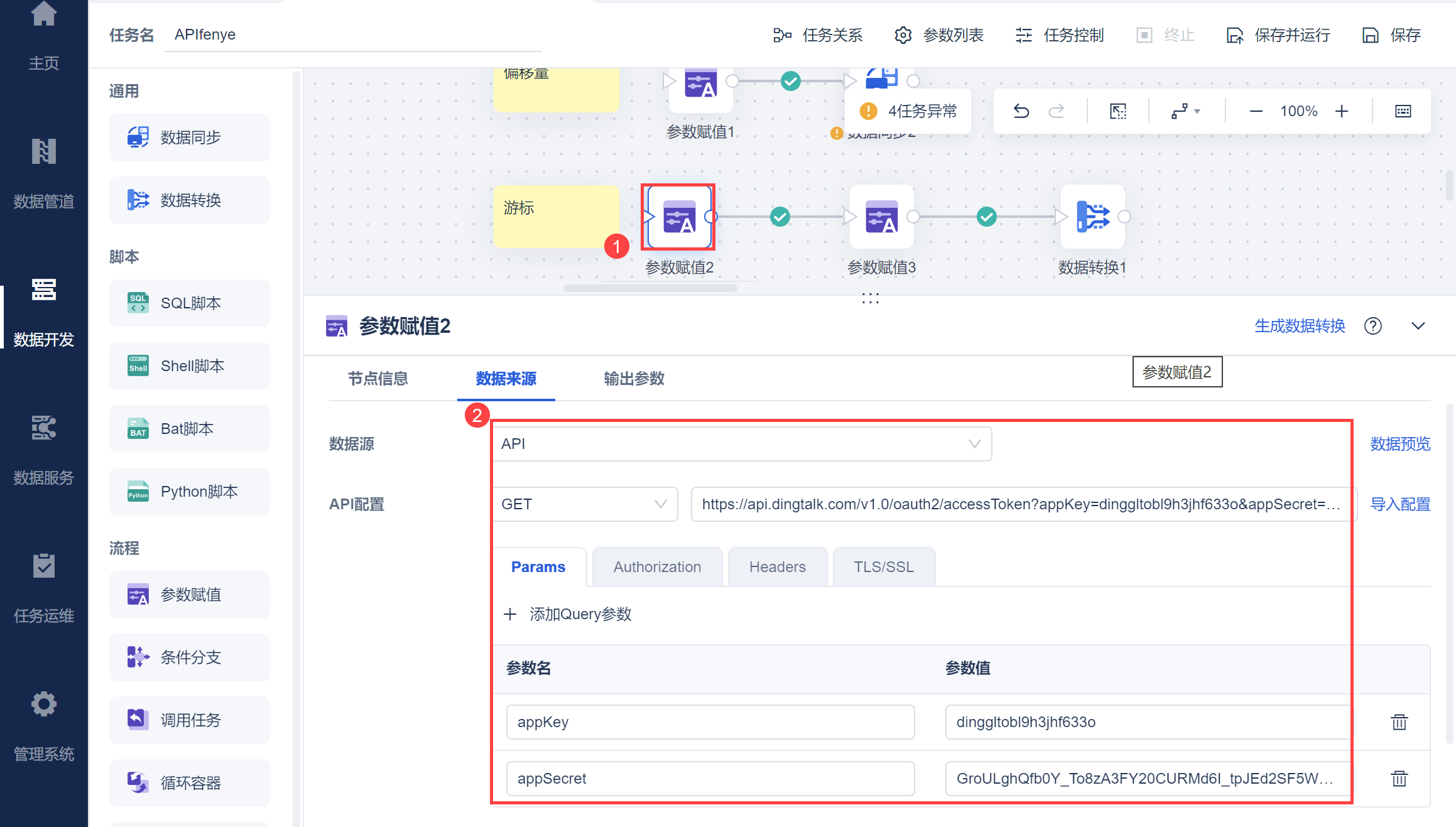
新建定时任务,拖入「参数赋值」节点,使用 获取企业内部应用的access_token 接口获取 access_token。如下图所示:
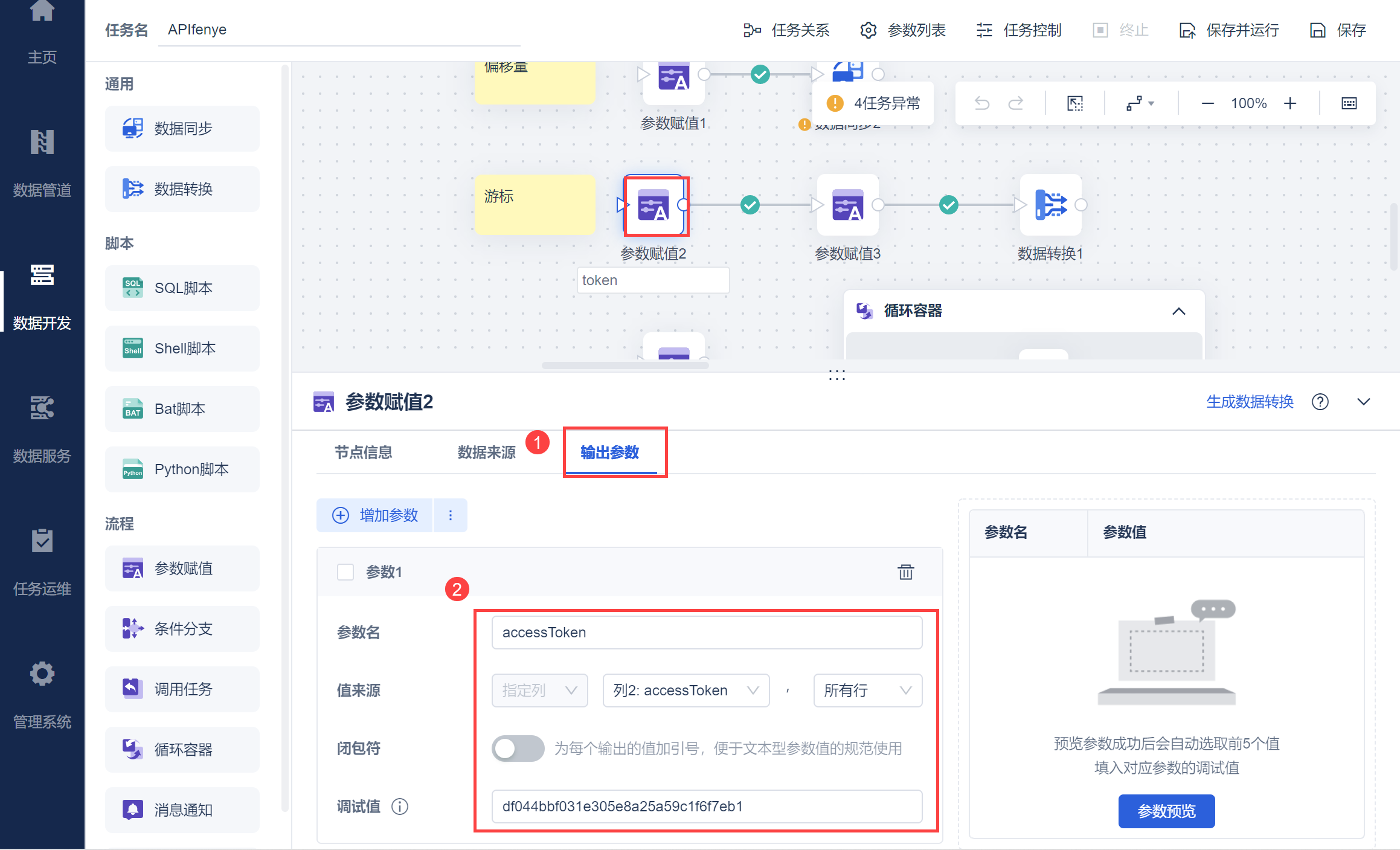
将 access_token 作为参数输出。如下图所示:
2.2.3 将 dept_id 输出为参数
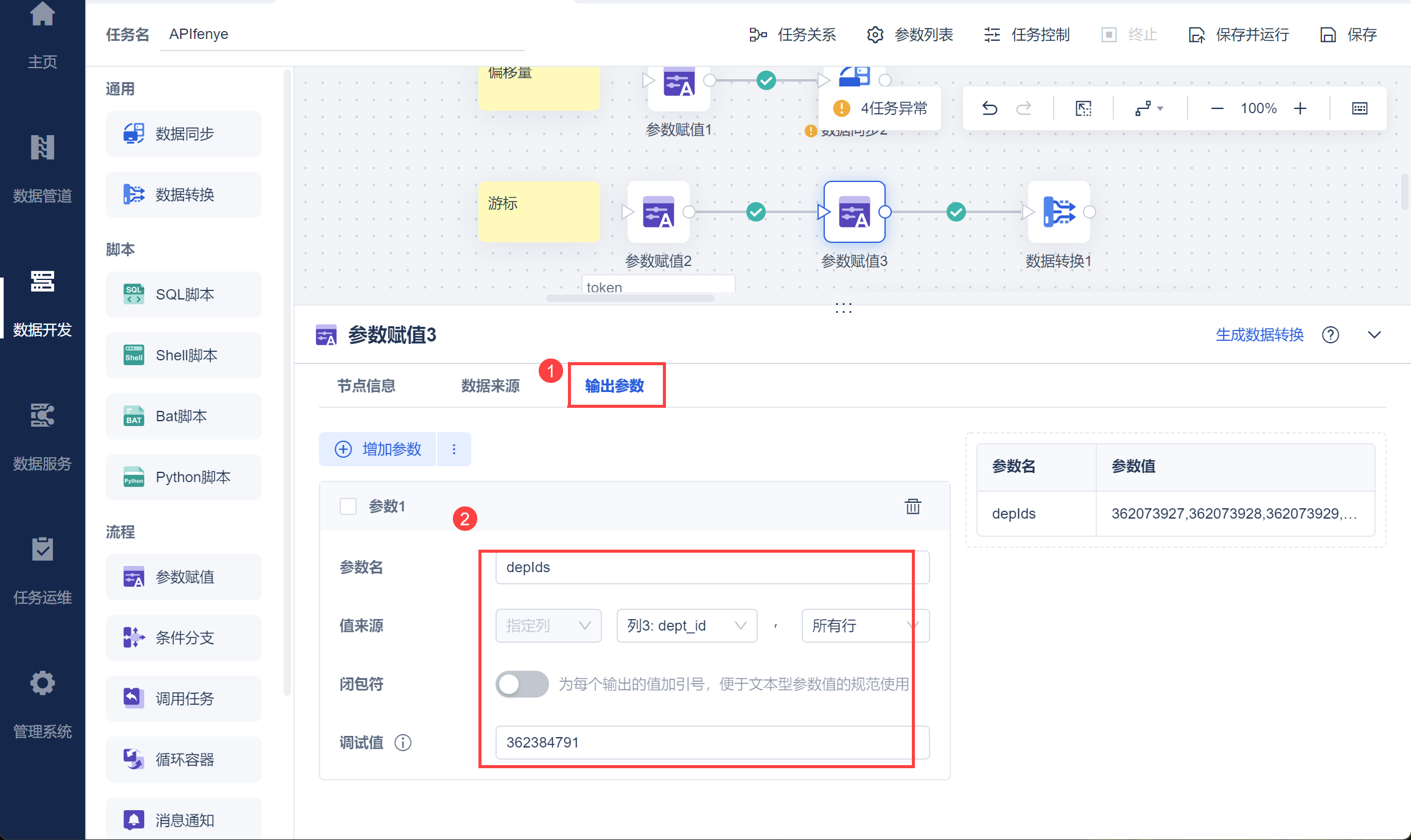
将 dd_dep 的 dept_id 字段设置为参数,便于后续作为请求参数写入 获取部门用户详情 接口取数。
使用参数赋值节点,查询出API取数-钉钉获取所有部门ID获取的 dd_dep表中 dept_id 字段,如下图所示:
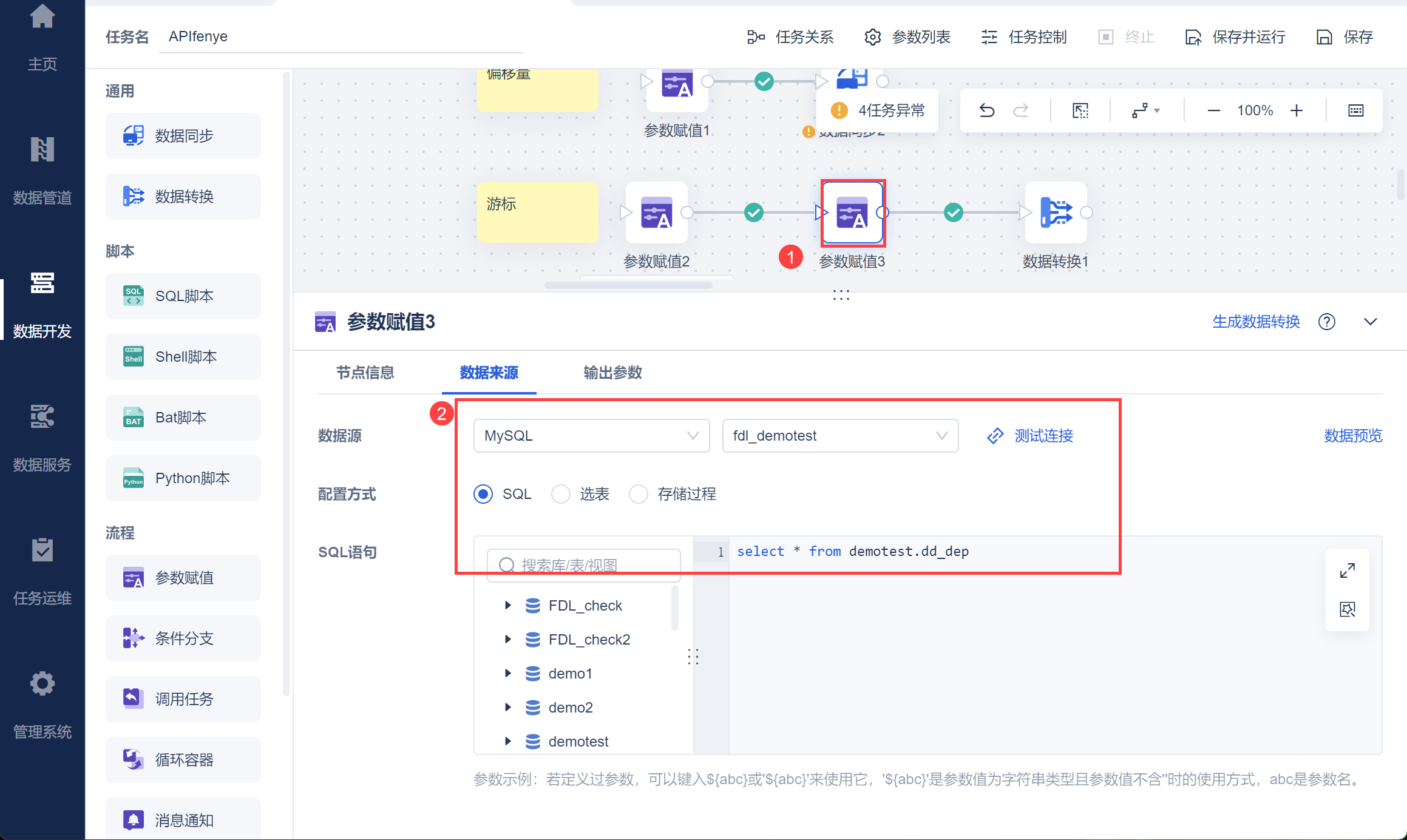
将其设置为参数 depIds,如下图所示:
2.2.4 分页取数
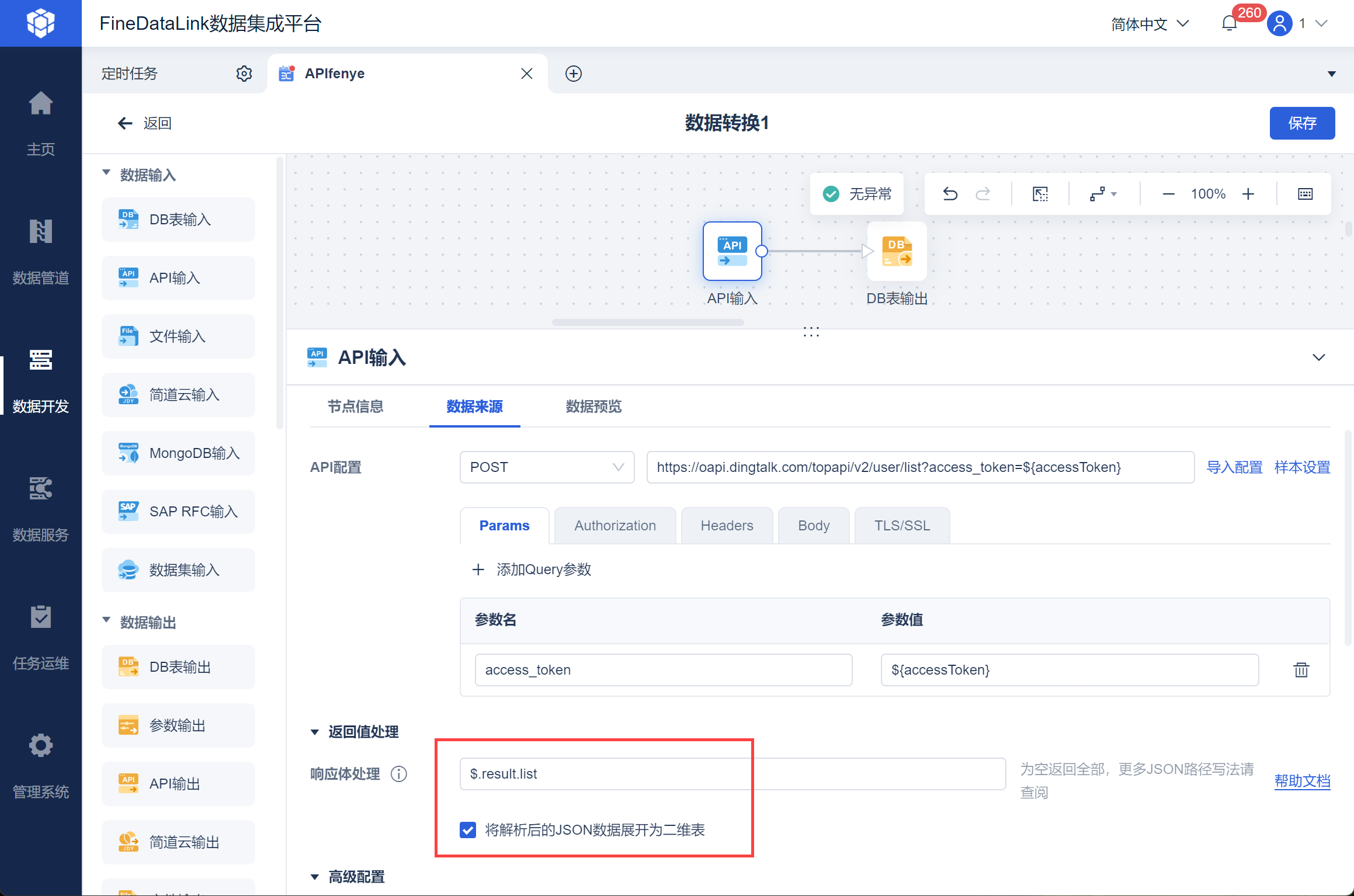
新增数据转换节点,进入编辑界面后,拖入 API 输入算子,并调用获取用户信息接口,并写入 Query 参数,如下图所示:

勾选高级配置下的分页取数,并设置取数条件。
分页方式选择游标,更新策略为初始值为 0,也就是分页参数${cursor} 首次为0
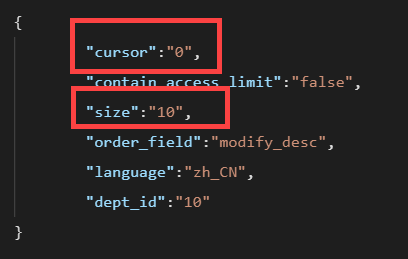
更新值,也就是下一次取的 ${cursor} 值为响应参数 next.cursor,这个值要使用 JSONPath 表达式解析,如下图所示:
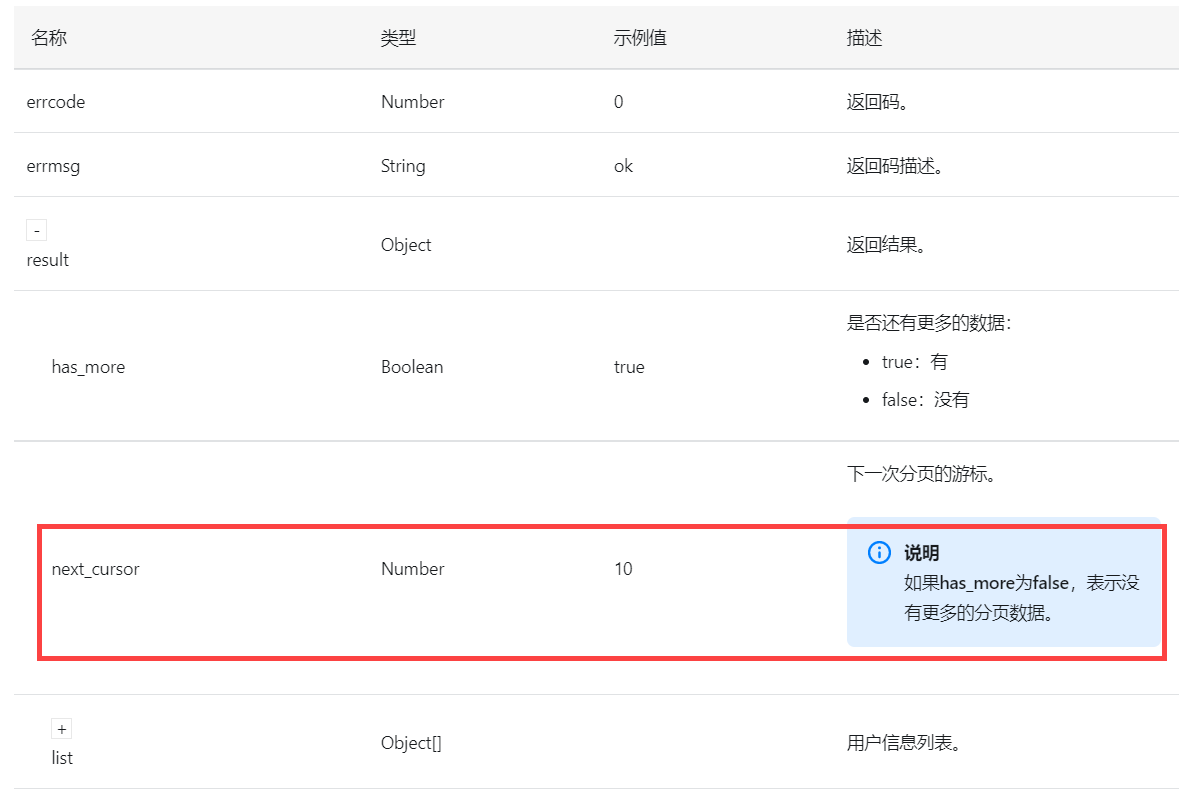
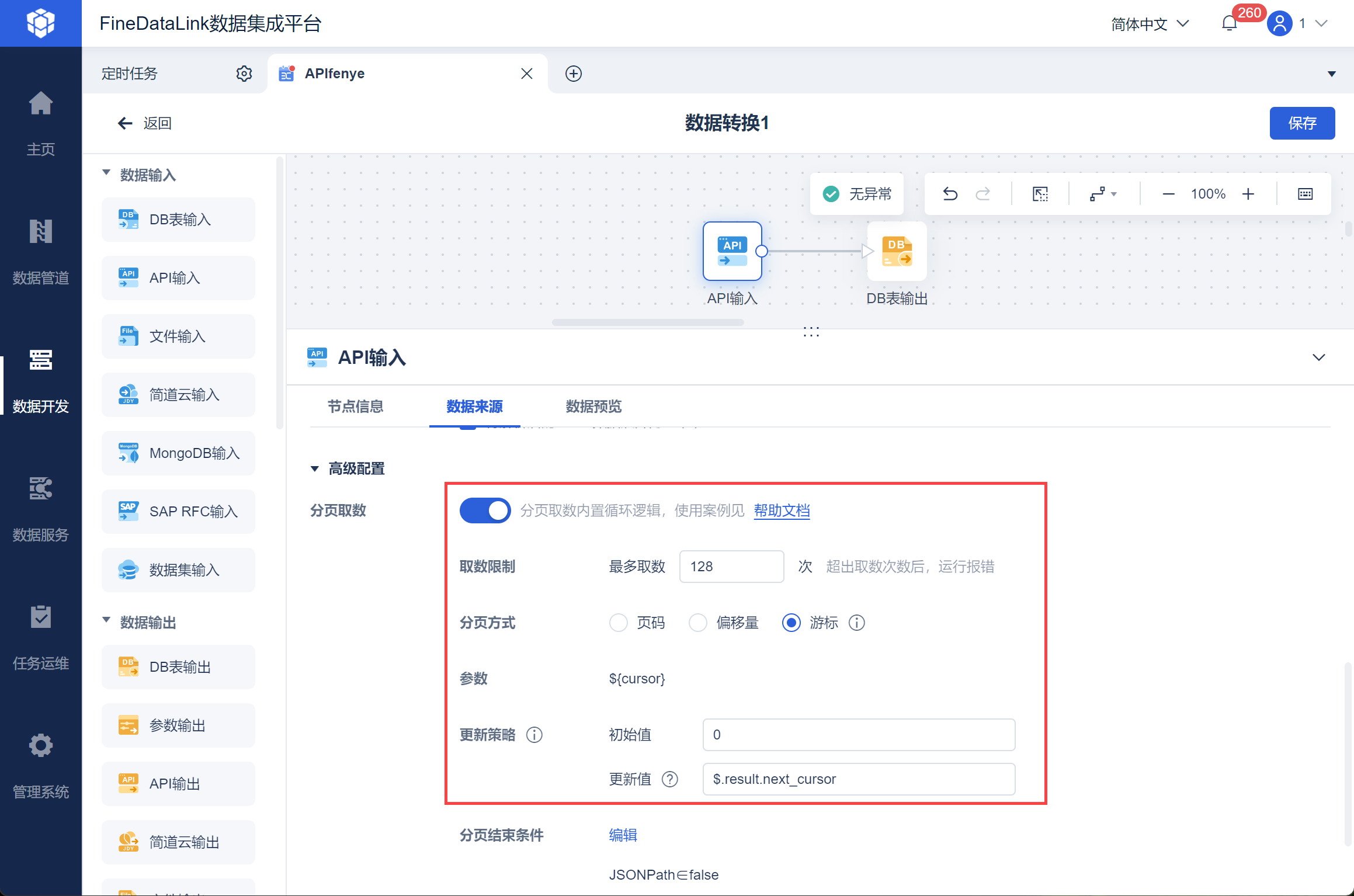
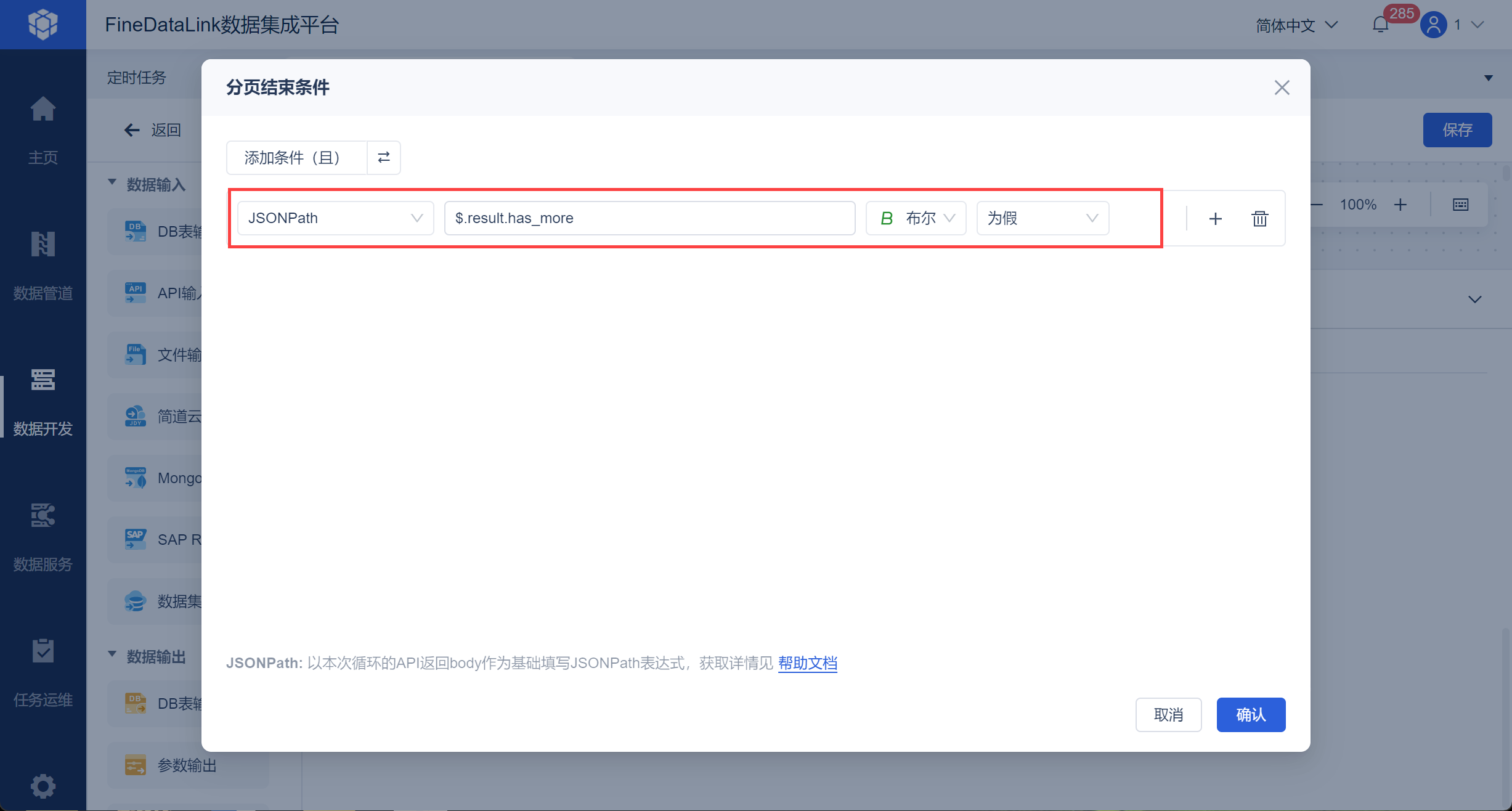
设置分页结束条件为 下一次的响应值中 JSONPath 解析参数 has_more,当其为 false,也就是没有更多数据的时候,停止分页取数,如下图所示:
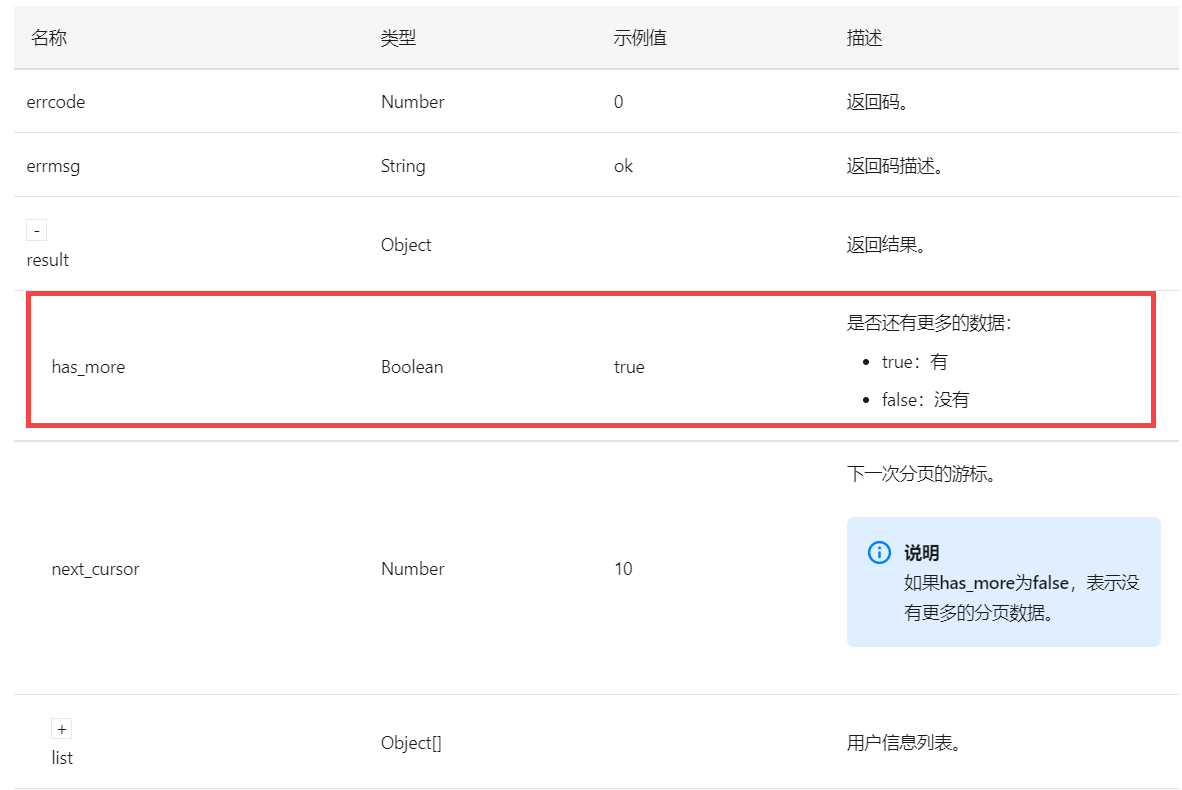
该参数值为布尔类型,如下图所示:
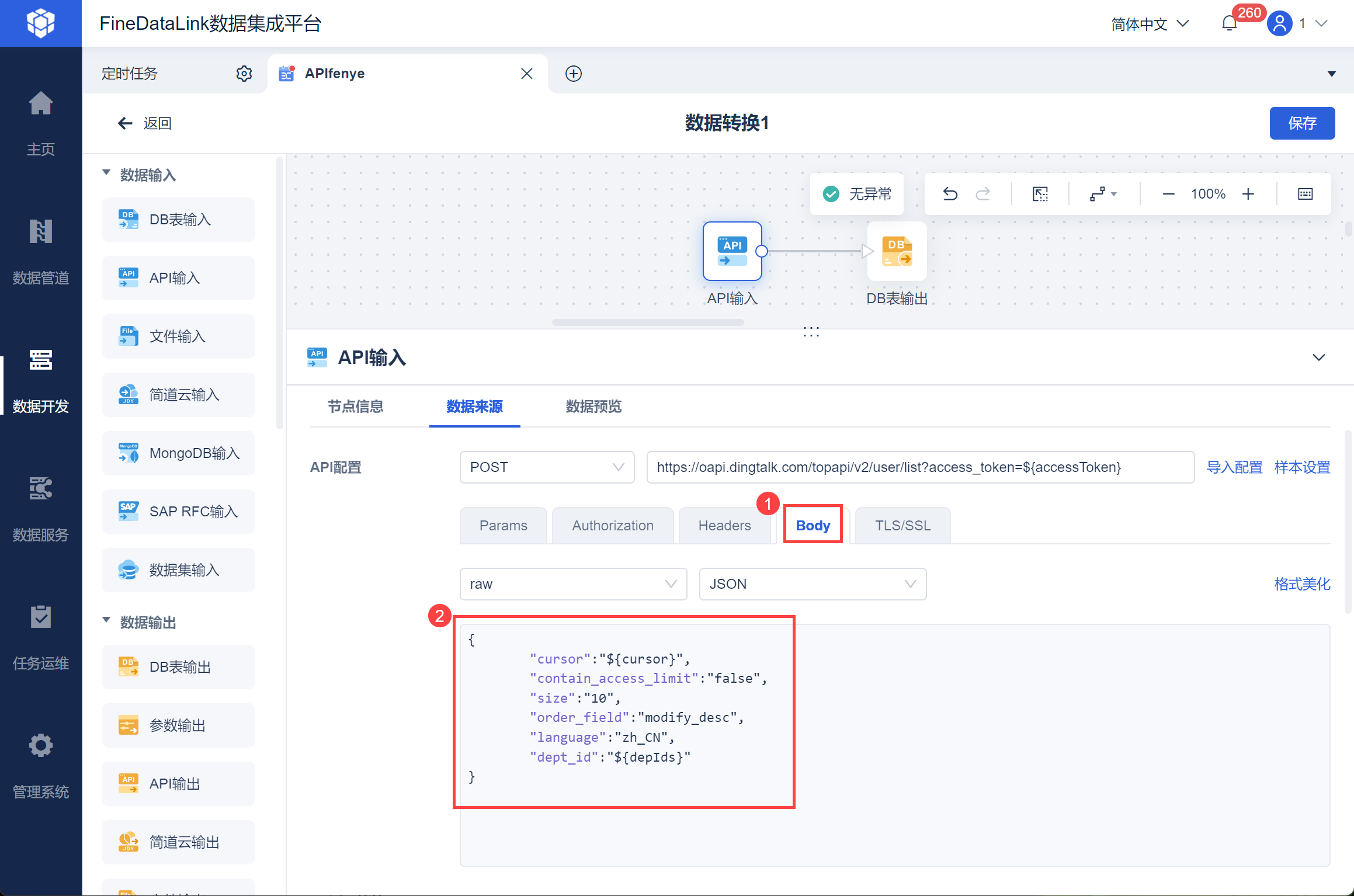
然后在请求参数 Body 中,设置游标 cursor 为分页取数设置的 ${cursor} 参数,并且 dep_id 为 2.2.3 节设置的参数 ${depIds} ,如下如所示:
其后可以新增 JSON 解析算子,解析取出的用户信息,获取想要的数据,或者直接在响应体处理中解析 JSON ,如下图所示:
然后即可使用 DB 表输出,将取出的数据写入指定的数据库中。
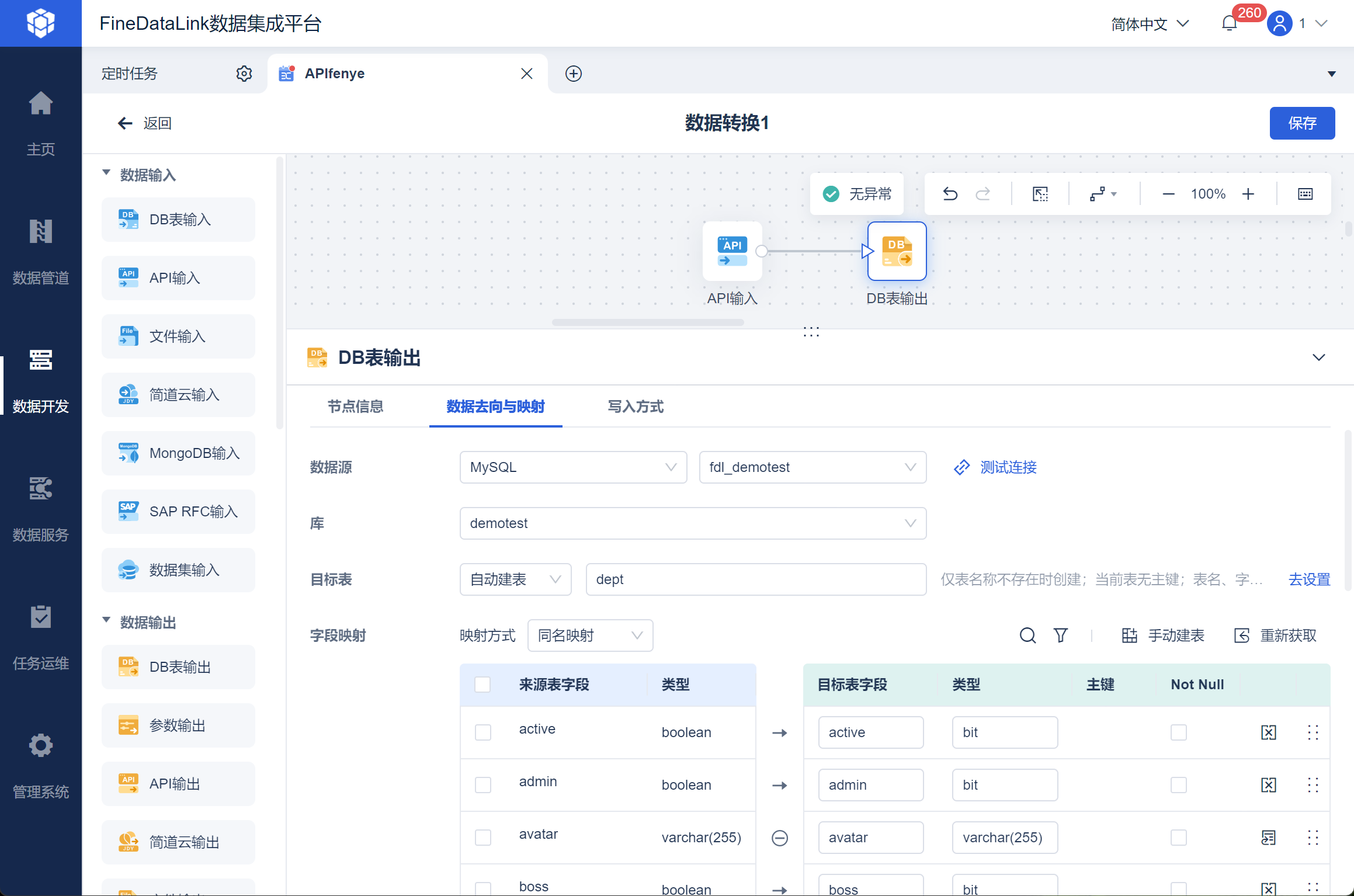
3. 方案二编辑
4.1.3 之前的版本支持的方案。
3.1 实现思路
3.1.1 接口说明
本文方案主要使用的是 获取部门用户详情 接口,要使用该接口,需要获取:Query参数(access_token)、Body 参数(dept_id;cursor;size,size 为分页大小,最大为 100)。
dept_id 通过 循环获取所有部门ID 获得,得到 dept_id 字段。
cursor 为分页查询的游标,最开始传 0 ,后续传返回参数中的 next_cursor 值。
size 自定义即可,最大为 100 。
3.1.2 方案说明
实现过程如下图所示:

| 序号 | 说明 |
|---|---|
| 准备工作:参考 循环获取所有部门ID 方案,获得 dept_id 字段 | |
| 1 | 为调用 获取部门用户详情 接口做准备,准备参数access_token、dept_id、cursor(参数列表中添加任务参数) 1)参数赋值节点:获取 access_token 2)数据同步节点:将 dd_dep 的 dept_id 字段写入到 dd_dep_temp 表中;若某部门下用户数小于 100 ,调用 获取部门用户详情 接口一次性将数据取完后,应该将本次循环所用的 dept_id 删除,下次循环用下一个 dept_id 取数,dd_dep 表为部门表,后续可与用户表关联,不能随意删除数据,所以新建临时表 dd_dep_temp 3)参数赋值1节点:取 dd_dep_temp 表中 dept_id 字段的第一个值 |
| 2 | 调用 获取部门用户详情 接口,获取用户数据,用户数据如下图所示:
|
| 3 | 若has_more为false,即该部门ID下数据已取完: 1)SQL脚本节点:删除本次循环所用的 dept_id 2)数据转换1节点:参数 next_cursor 置0 3)参数赋值3节点:将 dd_dep_temp 表的行数输出为参数
|
| 4 | 若has_more为true,即该部门ID下数据未取完: 参数赋值2节点:依然使用本次循环的 dept_id 做下次循环 |
| 循环执行条件:参数 nextDepId 不为空 | |

3.2 操作步骤
3.2.1 准备工作
参考 循环获取所有部门ID 方案,得到 dd_dep 表,本文方案需要用到 dd_dep 表的 dept_id 字段。
需要确定应用是否有 通讯录部门成员读权限,本文示例使用的应用是企业内部应用。
本文方案主要使用的是 获取部门用户详情 接口,要使用该接口,需要获取:Query参数(access_token)、Body 参数(dept_id、cursor)。
3.2.2 添加任务参数
cursor 参数为分页查询的游标,最开始传 0 ,后续传返回参数中的 next_cursor 值。本节为 cursor 赋予初始值 0 。
新建定时任务,点击右上角「参数列表」,添加参数 nextCursor ,类型为数值,值为 0 。如下图所示:

3.2.3 获取 access_token
新建定时任务,拖入「参数赋值」节点,使用 获取企业内部应用的access_token 接口获取 access_token。如下图所示:

将 access_token 作为参数输出。如下图所示:

3.2.4 将 dept_id 输出为参数
将 dd_dep 的 dept_id 字段写入到 dd_dep_temp 表中。
若某部门下用户数小于 100 ,调用 获取部门用户详情 接口一次性将数据取完,应该将本次循环所用的 dept_id 删除,下次循环用下一个 dept_id 取数,dd_dep 表为部门表,不能随意删除数据,所以新建临时表 dd_dep_temp。
1)拖入「数据同步」节点,将 dd_dep 表中的 dept_id 字段写入到 dd_dep_temp 中,写入方式选择清空目标表,再写入数据。如下图所示:
SELECT dept_id FROM `wendy`.`dd_dep`

2)右键点击「参数赋值」节点,选择「运行节点及下游」,在数据库中新增 dd_dep_temp 表,便于后续步骤中将 dd_dep_temp 表中的 dept_id 输出为参数。如下图所示:

3)拖入「参数赋值」节点,将 dd_dep_temp 表中的第一个 dept_id 字段输出为参数 nextDepId 。如下图所示:
SELECT dept_id FROM `wendy`.`dd_dep_temp` LIMIT 1

3.2.5 调用接口取出用户数据

循环容器中,调用 获取部门用户详情 接口,获取用户数据,用户数据如下图所示:

若 has_more 非空:将 has_more、next_cursor 输出为参数,为下次循环准备。
若 has_more 为空、userid 非空,输出用户信息到 userid_test (用户信息表中)。
3.2.6 调用接口
1)拖入「循环容器」节点,「循环容器」内拖入「数据转换」节点,进入「数据转换」节点。
2)拖入「API输入」算子,调用 获取部门用户详情 接口,获取用户数据,Body 内引用 nextDepId、nextcursor 参数。如下图所示:

点击「数据预览」,如下图所示:
用户信息在 result 字段中,需要进行解析。

3.2.7 解析数据
1)拖入「JSON解析」节点,解析 result 字段,选择节点:has_more、dept_id_list、mobile、name、userid、job_number、title、next_cursor。
需注意,当 has_more 字段为 false 时,是没有 next_cursor 字段的,因此,建议在 dd_dep 表中找到超过 100 用户数的部门ID,赋值给 2.2.3 节中参数 nextDepId 。

2)点击「数据预览」,如下图所示:

3.2.8 新增一列depids
用户信息表后续可能与部门表 dd_dep 关联,所以本节新增一列 depids,用于后续作为左右合并的依据,使用「Spark SQL」算子实现。如下图所示:

3.2.9 结果输出
1)拖入「参数输出」算子、「DB表输出」算子,将这两个算子分别与「Spark SQL」算子相连。
2)右键点击「Spark SQL」算子,选择数据分发,若has_more非空,将 has_more、next_cursor 输出为参数,为下次循环准备;若has_more为空、userid非空,输出用户信息到 userid_test (用户信息表中)。

3)使用「参数输出」算子,将has_more、next_cursor 输出为参数。如下图所示:

4)使用「DB表输出」算子,将用户信息输出到userid_test (用户信息表中),写入方式选择直接将数据写入目标表,userid 设为主键,主键冲突策略选择主键相同,覆盖目标表的数据。如下图所示:

5)点击右上角「保存」按钮。
3.2.10 用户数量超过100
若 has_more 为true,即该部门ID下数据未取完,依然使用本次循环的 dept_id 做下次循环。

1)拖入「条件分支」节点,拖入「SQL脚本」节点、「参数赋值」节点,「SQL脚本」节点、「参数赋值」节点分别与「条件分支」节点相连。
2)设置「条件分支」节点,若 has_more 为 true ,执行「参数赋值」节点;若 has_more 为 false,执行「SQL脚本」节点。如下图所示:

3)设置「参数赋值」节点,依然使用本次循环的 dept_id 做下次循环。如下图所示,输出参数 nextDepId 。

3.2.11 用户数量未超过100

若has_more为false,即该部门ID下数据已取完:
1)SQL脚本节点:删除本次循环所用的 dept_id。
2)数据转换1节点:参数 next_cursor 置0。
3)参数赋值3节点:将 dd_dep_temp 表的行数输出为参数。
参数赋值4节点:若行数大于0(dept_id 未取完),输出 dept_id ,供下次循环。
数据转换2节点:若行数小于等于0(dept_id 已取完) ,下次循环的 dept_id 置空。
删除本次循环所用的 dept_id
本次循环所用的 dept_id 已将用户数据取完,下次循环需要用到下个 dept_id ,所以我们将本次循环所用的 dept_id 删除。如下图所示:
DELETE FROM `wendy`.`dd_dep_temp` WHERE dept_id = '${nextDepId}'
参数 next_cursor 置0
将参数 next_cursor 置0,为下次循环准备。
1)拖入「数据转换」节点,进入「数据转换」节点。
2)拖入「Spark SQL」算子,将参数 next_cursor 置0。如下图所示:
select 0 as default_cursor

3)拖入「参数输出」算子,将 0 赋值给参数 nextCursor 。如下图所示:

4)点击右上角「保存」按钮。
根据部门ID临时表的行数作判断
将部门ID临时表(dd_dep_temp)的行数输出为参数:
若行数大于0(dept_id 未取完),输出 dept_id ,供下次循环。
若行数小于等于0(dept_id 已取完) ,下次循环的 dept_id 置空。
1)拖入「参数赋值」节点,将部门ID临时表(dd_dep_temp)的行数输出为参数count。如下图所示:

2)拖入「条件分支」节点、「参数赋值」节点、「数据转换」节点,将「参数赋值」节点、「数据转换」节点分别与「条件分支」节点相连。
3)设置「条件分支」节点,若 count 小于等于0,执行「数据转换」节点;若 count 大于 0,执行「参数赋值」节点。如下图所示:

4)若 count 大于0(dept_id 未取完),输出 dept_id ,供下次循环。设置「参数赋值」节点,输出参数 nextDepId 。如下图所示:

5)若 count 小于等于0(dept_id 已取完),下次循环的 dept_id 置空 。
进入「数据转换」节点,拖入「Spark SQL」算子,筛选出空数据,如下图所示:

拖入「参数输出」算子,将空数据赋值给参数nextDepId,由于调试值不能为空,此处随意填一个值即可,调试值不参与实际运行。如下图所示:

6)点击右上角「保存」按钮。
设置循环容器
设置「循环容器」节点,循环方式选择条件循环,执行条件为参数 nextDepId 不为空。如下图所示:

3.2.12 效果查看
「循环容器」节点执行情况如下图所示:
某部门ID下有 303 个用户,分四次写入。

3.2.13 后续步骤
用户若想定期执行任务:
1)需要在最前面加个节点,清空 userid_test 数据。如下图所示:

2)设置 执行频率 即可。