

1. 概述编辑
1.1 版本
| 运维平台版本 | 功能变更 |
|---|---|
| V1.5.5 | - |
| V1.5.8 | 1)功能更名 「系统运行状态」更名为「系统资源监控」 2)展示内容优化 精选新增高频关注指标,剔除部分冗余指标 仪表盘重新划分为:全项目状态总览、基础资源监控、线程池监控 移除「全项目状态总览」中的「运行时长/在线用户/负载分/工程磁盘余量」指标 3)联动交互优化 顶部运维项目筛选按钮联动,基础资源监控和线程池监控中,默认仅展示所选项目的信息 部分组件支持联动跳转「日志管理>性能监控>性能堆栈」,进行必要的堆栈分析 |
1.2 功能简介
应用场景:
系统资源监控仪表盘,主要用于关注应用的全局状态情况概览,包括了各组件与应用的连通性,应用整体的运行状况,使用情况等。
同时也提供应用的历史运行信息,核心用于关注整个应用的可用状态,如果是应用集群,将汇总展示各个节点的状态。
功能入口:
管理员登录FineOps运维平台,点击「监控与告警>总览」,即可查看「系统资源监控」。
仪表盘分为三个部分:全项目状态总览、基础资源监控、线程池监控。
2. 使用前提编辑
2.1 运维项目要求
仪表盘中的数据,由相关exporter指标收集组件提供。
1)容器化部署的帆软项目,默认安装了相关组件。
2)非容器化部署的帆软项目,在接入运维平台时,支持安装相关组件。
请确保参考「接入已有非容器化项目」文档,安装了相关日志信息采集和服务器信息采集组件。
2.2 运维平台要求
仪表盘功能,由这些运维组件提供:grafana、prometheus
因此如需正常查看相关仪表盘,需要确保这些组件正常运行。
管理员登录运维平台,点击「运维管理>运维组件」,可启动相关组件。

3. 全项目状态总览编辑
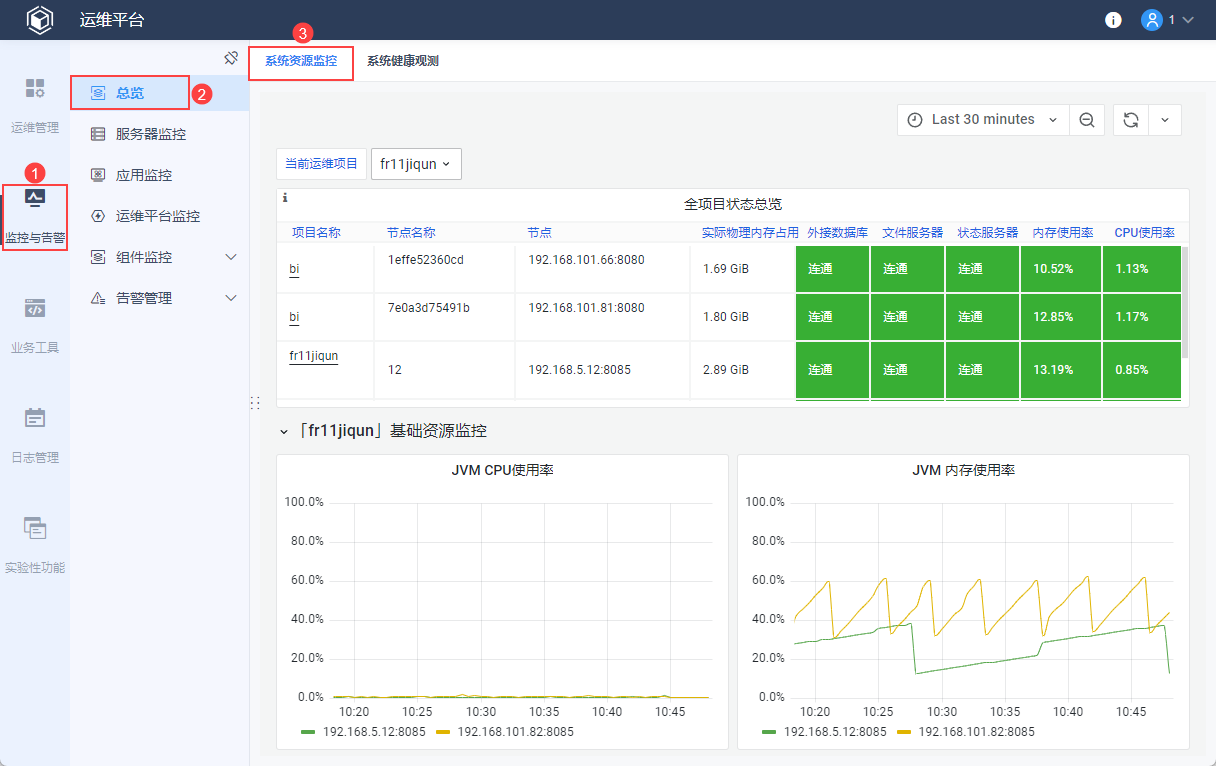
1)仪表盘示例:
展示运维平台对接的所有运维项目的总览信息,如果出现异常指标将标红/标黄显示,通过点击项目名称可以联动下方明细指标。
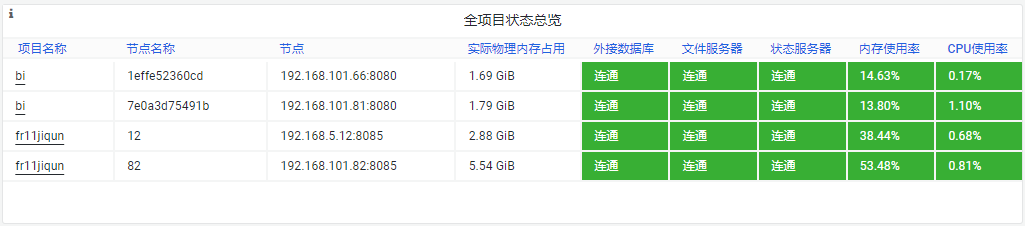
2)仪表盘指标说明:
| 指标 | 具体说明 |
|---|---|
| 项目名称 | 当前查看的运维项目的名称 点击可联动下方基础资源监控、线程池监控的明细指标 |
| 节点名称 | 当前查看的应用的节点名称 |
| 节点 | 当前查看的应用节点的IP和端口号 |
| 实际物理内存占用 | 当前查看的应用,实际占用的物理内存大小 单位:GiB |
| 外接数据库 | 应用与外接数据库的连接状态 结果可能为:连通、断开、未设置(未使用外接)和部分节点异常(集群) |
| 文件服务器 | 应用与文件服务器的连接状态 结果可能为:连通、断开、未设置(未使用文件服务器)和部分节点异常(集群) |
| 状态服务器 | 应用与状态服务器的连接状态 结果可能为:连通、断开、未设置(未使用状态服务器)和部分节点异常(集群) |
| 内存使用率 | 内存使用率 = 当前使用的内存 / 可以使用的最大内存 当前使用的内存:当前使用的内存大小(字节) 最大内存:可以使用的最大内存(字节),分配给 JVM 的最大内存 |
| CPU使用率 | CPU使用率 = 采集时刻 CPU 使用率 |
4. 基础资源监控编辑
1)仪表盘示例:
与「应用状态总览」联动,展示选中的运维项目的基础资源信息。
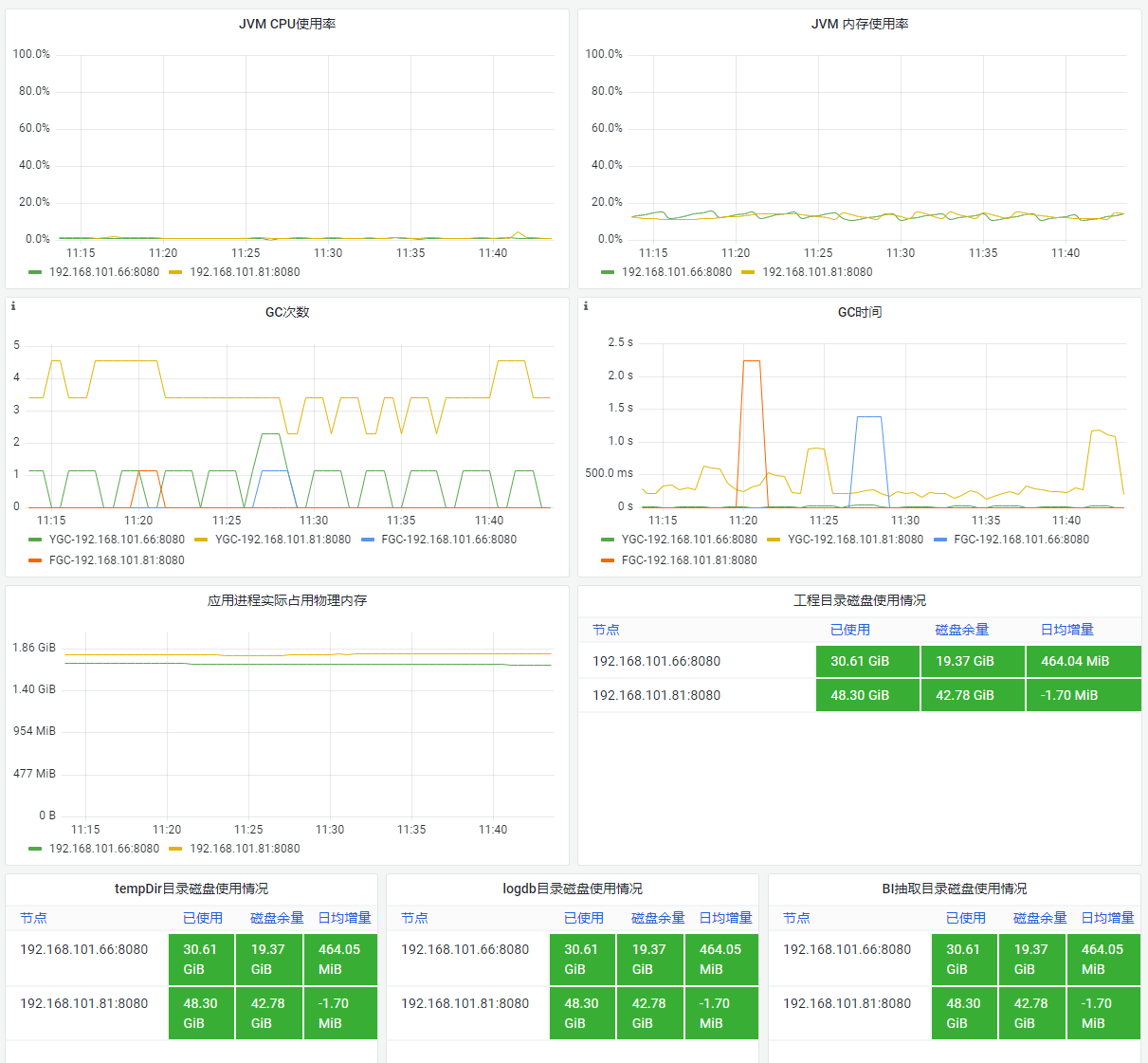
2)仪表盘指标说明:
| 指标 | 具体说明 |
|---|---|
| 在线用户数 | 当前查看的应用,目前在线用户数量 |
| 文件打开数 | 启动应用的用户会有最大文件打开数的限制,当前应用文件打开数接近最大文件打开数时,可能会导致后续的访问出现报错,需要修改启动用户的最大文件打开数限制 |
| 各应用目录磁盘使用情况 | 展示应用相关的root目录、工程目录、备份目录、temp目录、schedule目录和logs目录所在的磁盘空间使用率情况,当使用率超过80%时会飙红显示,可用磁盘空间不足可能会影响应用的正常运行甚至宕机,需要尽快进行磁盘清理或扩容 |
| JVM负载 | JVM的负载变化情况,负载是帆软根据gc信息计算得出的应用压力量化方式,相比内存能够更真实的反映应用的压力情况,负载过高说明应用压力大 当负载超过80时需要关注是否存在异常 |
| JVM内存使用率 | JVM的内存使用率变化情况,反映应用的客观内存占用情况,可能包含可被gc回收的内存占用 |
| JVMCPU使用率 | JVM的CPU使用率变化情况,反映应用的CPU占用情况 |
| 应用进程实际占用物理内存 | 随时间变化,应用实际占用的物理内存大小 单位:GiB |
| GC次数 | 随时间的gc次数变化情况,gc次数越多通常gc负荷越大 |
| GC时间 | 应用每秒花在gc上的时间变化情况,反应gc的负荷和应用的吞吐量,gc时间越长,应用吞吐量越小 |
| 历史运行状态 | 与「应用状态总览」联动 选中的运维项目的历史状态信息 |
| 系统运行时长 | 应用上次持续运行的时长 |
| 上次宕机信息 | 上次应用宕机的时间 |
| 近一个月节点总宕机记录 | 帆软系统近一个月的宕机记录,用于回溯历史异常情况考虑 |
| 近一个月的高风险卡顿次数 | 近一个月帆软系统的高负载高风险(负载分大于100分/120)次数记录 |
5. 线程池监控