

1. 描述编辑
Hadoop 是个很流行的分布式计算解决方案,Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。
下面介绍的是在平台中新建数据连接,若需要在设计器中新建,点击 [设计器]JDBC连接数据库。
2. 操作步骤编辑
2.1 拷贝 JAR 包到 FR 工程
| 数据库版本 | 驱动包 |
|---|---|
| hive_1.1; | Hive1.1.rar |
| Hadoop_Hive_1.2;hive2.3; hive2.1.2; | Hadoop Hive.zip |
下载对应的驱动包,并将该驱动包放置到%FR_HOME%\webapps\webroot\webroot\WEB-INF\lib下,重启报表服务器。
2.2 平台中新建数据连接
管理员登录决策平台,点击管理系统>数据连接,点击新建数据连接>更多数据连接,选择Hadoop Hive,点击确定,如下图所示:
注:如果非管理员用户想要配置数据连接,需要管理员给其分配管理系统下数据连接节点的权限,具体操作请查看 数据连接控制。
第一步:输入数据库的对应信息,可选择填入连接池属性信息(连接池属性介绍可点击 [平台]数据连接 ),如下图所示:
| 驱动器 | URL |
|---|---|
| org.apache.hive.jdbc.HiveDriver | jdbc:hive2://hostname:port/databasename |
1)若不勾选 Kerberos 认证,则输入数据库的对应信息,如下图所示:

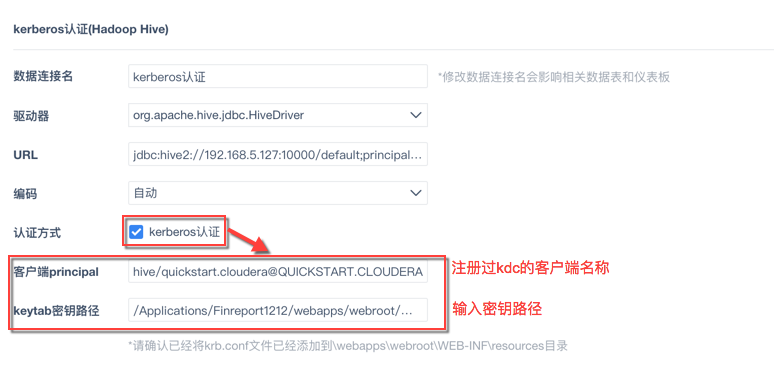
2)若勾选 Kerberos 认证,则需填入注册过 kdc 的客户端名称、keytab 密钥路径和 Kerberos 认证对应 URL
(例如 jdbc:hive2://192.168.5.127:10000/default;principal=hive/quickstart.cloudera@QUICKSTART.CLOUDERA),
具体操作请查看 [平台]数据连接Kerberos认证
第二步:测试连接,若测试连接成功则表示成功连接上数据库,如下图所示:
然后点击右上角的【保存】,该数据连接即添加成功,如下图所示: