1. 概述编辑
1.1 应用场景
帆软提供「运维平台」工具,帮助企业解决以下痛点:
1)管理员缺少运维知识,不知道如何对帆软应用(如FineReport、FineBI等)进行运维。
2)系统运维人员仅负责监控服务器的运行状态,不关注帆软相关应用的运行情况,且不了解业务,无法深度解决运维问题。
3)客户缺少手段/人员监控帆软应用本身的运行状态,不了解帆软应用配置,不清楚帆软业务相关指标是否有风险。
4)应用运维管理复杂,出现问题可能需要多方协调才能远程服务器进行问题处理,并且运维要依靠命令行的方式,运维门槛高。
5)多项目管理混乱,多个项目的统一运维管理难度大。
1.2 产品定位
帆软运维平台对接promethues开源体系,支持帆软应用及相关组件的相关监控,内置各种开箱即用的监控仪表盘,可监控帆软相关服务的运行情况。
帆软运维平台提供多种运维功能,支持通过运维平台实现应用巡检及快速修复,给帆软应用提供更可靠的保障服务,降低运维难度及成本。
运维平台的优势如下:
| 相比于 | 优势 | 详述 |
|---|---|---|
| 客户自有运维手段 | 开箱即用 | 支持一键容器化部署运维平台服务、帆软应用及各个相关组件。 支持自动接入监控,提供完善的监控仪表盘和基础告警 无需复杂配置接入,实现开箱即用 |
| 深入业务应用 | 运维平台的监控内容深度结合帆软应用 监控仪表盘提炼并聚合了最适用于帆软应用的关键指标 减少无效指标信息干扰,更快洞悉服务状态及指标异常 | |
| 低成本运维 | 低上手成本,低操作成 本传统的运维方式需要远程到服务器上进行各项命令行操作,安全性差且操作麻烦 运维平台内置各类运维工具,可远程低成本运维帆软应用 | |
| 托管式运维 | 由帆软专业的运维团队进行运维平台的管理及使用,进行定期巡检、告警响应,提供业务连续性保障,客户无需自己关注及处置异常 | |
| 工程智能运维功能 | 全面应用指标监控 | 解决应用运行状态黑盒场景,更全面的指标帮助了解及监控帆软应用的运行状况 |
1.3 功能特性
| 模块 | 描述 |
|---|---|
| 健康诊断 | 对监控的服务的运行环境及各项配置进行定期检查,及时发现服务运行风险,采取针对性的有效措施。 |
| 运维工具 | 实现对帆软应用的远程运维,可以远程监测应用业务状态并通过运维工具实现及时排障,快速恢复可用等。 |
| 监控仪表板 | 开箱即用的监控仪表盘,针对帆软应用的特性,提供针对性的关键指标,实现对于应用、组件、服务器的压力监控,便于回溯异常时间,辅助判断服务压力及运行状况 |
| 告警配置 | 对于特定异常情况提前通过多种渠道告警,以提醒报警联系人采取必要的问题解决措施 |
| 日志查询 | 提供应用日志的关键字查询功能,快速筛选检索关键错误信息,提高问题定位效率 |
2. 工具部署使用编辑

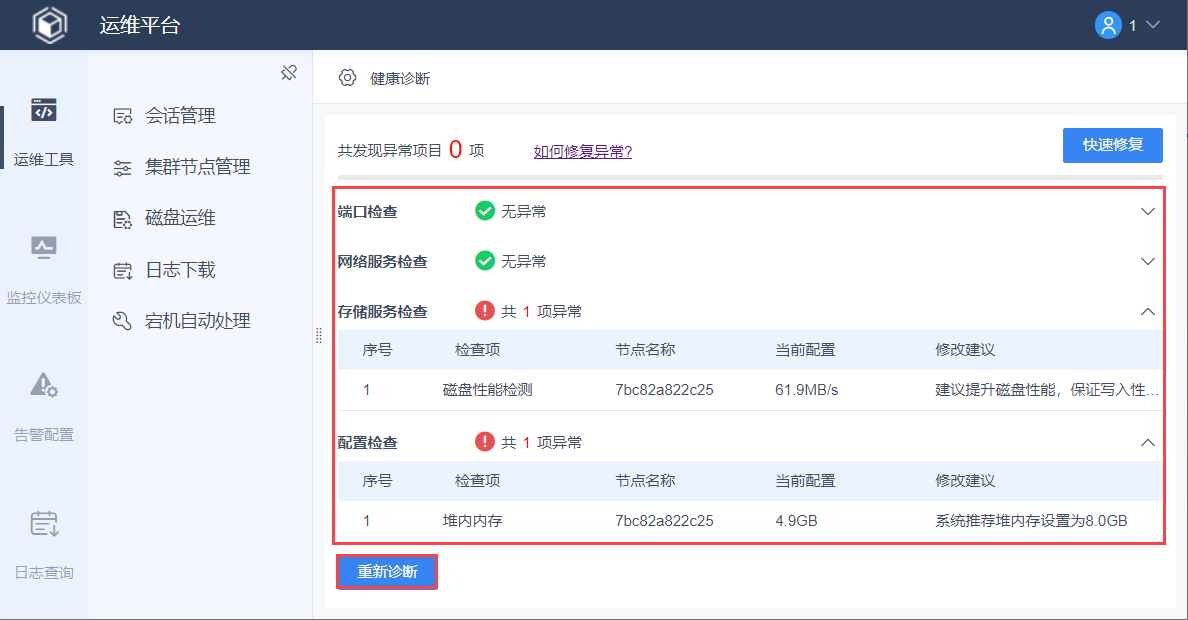
3. 健康诊断编辑
「运维平台」的默认首页为「健康诊断」功能,此功能是运维平台巡检的总入口。
3.1 配置目标应用
使用「健康诊断」功能前,必须确保运维平台已配置了需要被诊断的「目标应用」。
否则提示「提示:诊断前请先点击上方”健康诊断“左侧按钮设置诊断应用URL」,如下图所示:

管理员登录「运维平台」,默认进入「健康诊断」页面,点击左上角「全局配置」按钮,输入目标应用相关配置项。
点击「保存」后,自动进行测试连接,若能成功连接目标应用,则跳出提示框「测试连接成功」,点击「确定」即可。

目标应用相关配置项如下表所示:
| 配置项 | 说明 |
|---|---|
| 目标应用地址 | 需要被监控的帆软应用地址 形如http://IP:port/webroot/decision |
| 应用部署方式 | 目前仅支持「容器化部署」方式 「非容器化部署」的应用运维监控,敬请期待 |
| 运维接口秘钥 | 需要被监控的帆软应用的运维接口秘钥 |
3.2 诊断内容
管理员点击「开始诊断」按钮,会对应用的「端口、网络服务、存储服务、配置」四类问题进行诊断。如果存在异常将显示在页面上。
进行修复/更改后,管理员可再次点击「重新诊断」按钮,「运维平台」会重新对目标应用进行诊断,输出最新结果。
注:检查项具体内容请参考:运维监控指导手册 第三章。
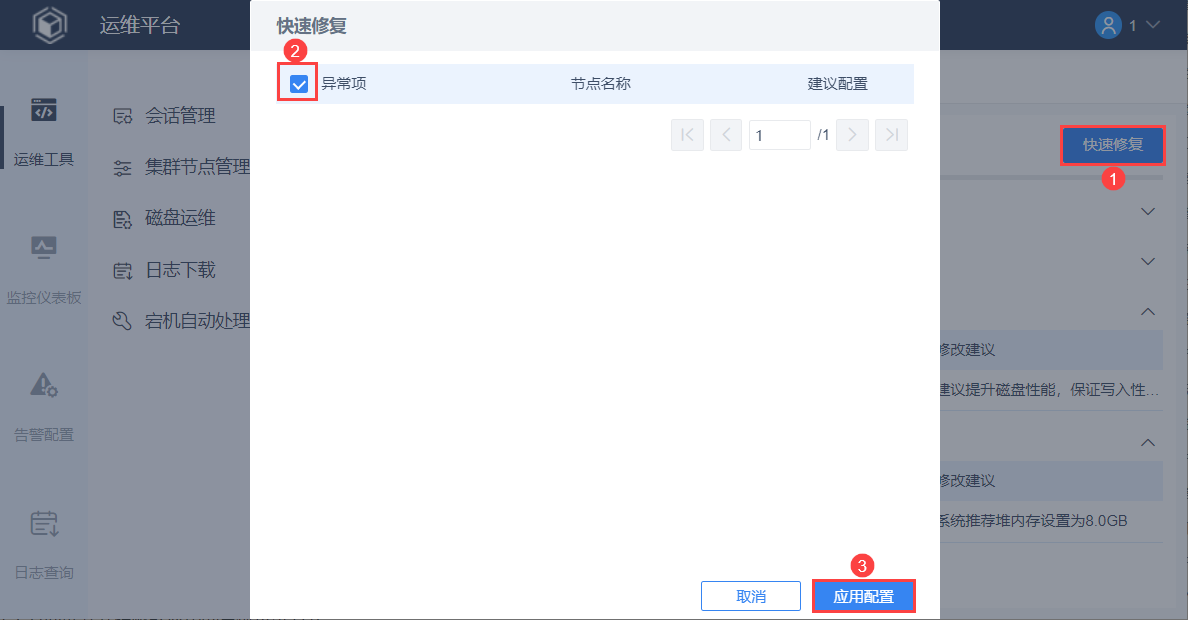
3.3 快速修复
部分异常配置支持快速修复。
管理员点击「快速修复」按钮,勾选需要配置的检查项,点击「应用配置」,即可一键配置异常项的值。
配置成功后,跳出提示「应用配置成功,重启服务器后生效」。报表工程重启后,可以发现刚刚的异常项均已成功配置。
注:若没有文件读写权限或者无法修改配置文件时,提示「应用配置失败:没有配置文件读写权限」,点击「确定」,则修改失败。
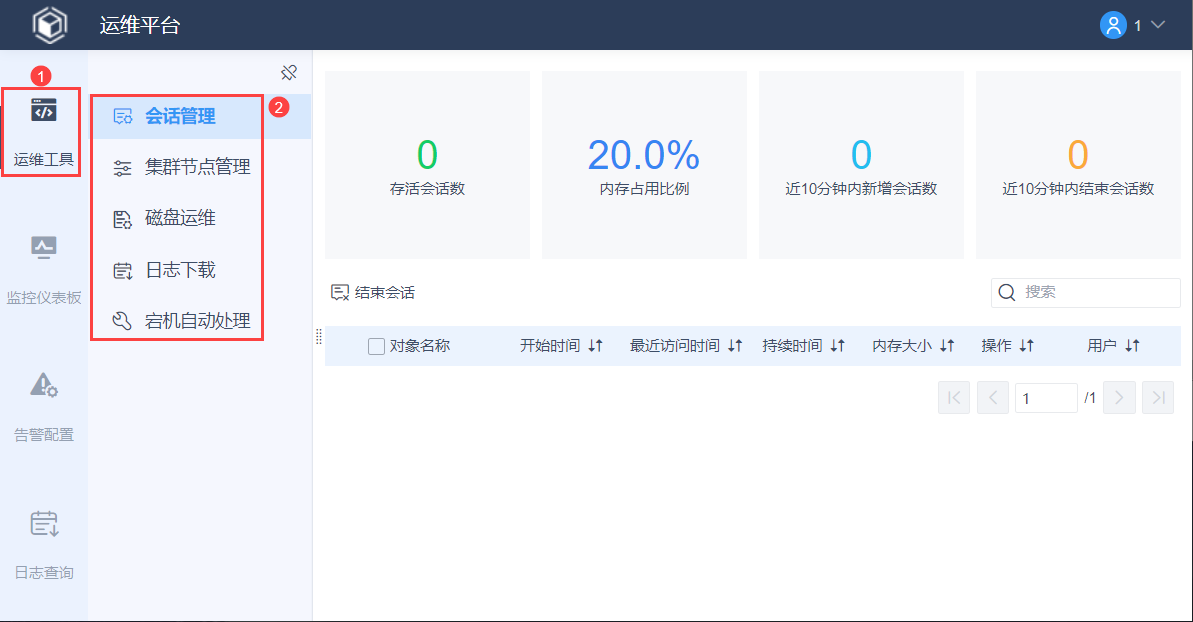
4. 运维工具编辑
运维工具主要分为以下五个功能:
| 功能 | 说明 | 帮助文档 |
|---|---|---|
| 会话管理 | 用户在帆软应用中,打开一张目录中的模板,即为一个会话。 管理员可通过「会话管理」查看应用中会话占用情况,并支持对于异常会话手动进行中止。 | 负载管理 第三章 |
| 集群节点管理 | 管理员可通过「集群节点管理」查看应用节点运行是否正常,并管理节点名称等。 | 配置开启集群 第三章 |
| 磁盘运维 | 提供磁盘垃圾检测及清理的功能,帮助减少应用的磁盘空间占用,点击「开始扫描」检测应用中的垃圾,并选择进行清理 | 磁盘清理 |
| 日志下载 | 用于下载应用相关日志以及应用环境信息 | 下载日志 |
| 宕机自动处理 | 用于监测应用的健康状态,当应用出现宕机时自动进行dump、堆栈输出,方便进行问题定位,同时自动重启应用保证业务的可用性。同时提供历史宕机原因的分析。 | 宕机处理 |
5. 监控仪表板编辑
运维平台提供「主仪表盘、服务器监控、外接数据库监控、Redis监控、Nginx监控和应用监控」六个仪表盘
仪表板中的操作按钮,目前仅支持查询,不会保存记忆上次的查询项。仅建议使用以下两个按钮,其他的操作按钮不建议使用。
| 按钮 | 说明 |
|---|---|
 | 左侧下拉框是用于选择监控仪表盘的时间范围 右侧按钮用于快捷扩大查询时间范围 |
 | 左侧按钮用于刷新数据 右侧下拉框用于配置自动刷新频率 |
5.1 主仪表盘
主仪表盘用于关注应用的全局状态情况概览,包括了各组件与应用的连通性,应用整体的运行状况,使用情况等。
同时也提供应用的历史运行信息,核心用于关注整个应用的可用状态,如果是应用集群,将汇总展示各个节点的状态。

仪表板指标具体说明如下表所示:
| 指标 | 具体说明 |
|---|---|
| 当前系统在线用户数 | 当前应用系统的在线用户人数 |
| 外接数据库连接状态 | 应用与外接数据库的连接状态,结果可能为:连通、断开、未设置(未使用外接)和部分节点异常(集群) |
| 文件服务器连接状态 | 应用与文件服务器的连接状态,结果可能为:连通、断开、未设置(未使用文件服务器)和部分节点异常(集群) |
| 状态服务器连接状态 | 应用与状态服务器的连接状态,结果可能为:连通、断开、未设置(未使用状态服务器)和部分节点异常(集群) |
| 最大文件打开数/应用文件打开数 | 启动应用的用户会有最大文件打开数的限制,当前应用文件打开数接近最大文件打开数时,可能会导致后续的访问出现报错,需要修改启动用户的最大文件打开数限制(集群时会根据节点情况显示多个值) |
| 各应用目录磁盘使用情况 | 展示应用相关的root目录、工程目录、备份目录、temp目录、schedule目录和logs目录所在的磁盘空间使用率情况,当使用率超过80%时会飙红显示,可用磁盘空间不足可能会影响应用的正常运行甚至宕机,需要尽快进行磁盘清理或扩容 |
| JVM负载 | JVM的负载变化情况,负载是帆软根据gc信息计算得出的应用压力量化方式,相比内存能够更真实的反映应用的压力情况,负载过高说明应用压力大 |
| JVM内存使用率 | JVM的内存使用率变化情况,反映应用的客观内存占用情况,可能包含可被gc回收的内存占用 |
| JVMCPU使用率 | JVM的CPU使用率变化情况,反映应用的CPU占用情况 |
| 应用进程实际占用物理内存 | 应用进程实际占用系统物理内存的情况 |
| GC次数 | 随时间的gc次数变化情况,gc次数越多通常gc负荷越大 |
| GC时间 | 应用每秒花在gc上的时间变化情况,反应gc的负荷和应用的吞吐量,gc时间越长,应用吞吐量越小 |
| 系统运行时长 | 帆软系统持续运行的时长(即距离上次启动的时间,如果是集群将会显示多个节点的不同值) |
| 上次宕机时间 | 上次帆软系统宕机的时间(如果是集群则为上次单节点宕机的时间) |
| 近一个月的宕机记录 | 帆软系统进近一个月的宕机记录,用于回溯历史异常情况考虑 |
| 近一个月的高风险开顿 | 近一个月帆软系统的高负载高风险(负载分大于100分/120)次数记录 |
5.2 服务器监控
服务器监控仪表盘主要用于监控帆软应用及相关组件运行的服务器的状态,方便及时关注服务器的各项指标情况,避免影响应用的正常运行,可通过instance选择对应的服务器指标数据

仪表板指标具体说明如下表所示:
| 指标 | 具体说明 |
|---|---|
| CPU使用率及配置信息 | 显示CPU性能情况和当前的CPU使用率,如CPU使用率过高说明计算压力较大,需要提升CPU性能或排查具体计算任务 |
| 内存使用率及内存信息 | 显示当前内存使用率、总物理内存和已用内存,如内存过高可能会导致宕机,需要加大物理内存或中止部分占用内存较多的进程 |
| 根目录磁盘使用率及磁盘信息 | 显示当前根目录的磁盘使用率、磁盘总量和磁盘使用量,如磁盘使用率过高可能导致宕机或使用异常,需要加大磁盘空间或进行磁盘清理 |
| 系统信息 | 展示系统的版本、以及各项环境信息,便于运维人员确定环境信息并排查问题 |
| 根目录磁盘每秒读写速率BPS、根目录磁盘每秒读写请求数量IOPS | 根目录磁盘的每秒读取/写入速率BPS和根目录磁盘每秒读取/写人请求数量IOPS,反映了磁盘读写性能消耗情况 |
| CPU等待磁盘IO完成时间的百分比 | 展示一段时间内的CPU等待磁盘IO完成时间的百分比曲线,此项数值较高说明当前系统的磁盘使用率非常高,并且cpu的大部分时间处于等I/O的状态,这个时候,往往说明I/O遇到了瓶颈 |
| 磁盘IO的CPU使用率 | 展示一段时间内被磁盘IO消耗的CPU比率的曲线 |
| inode使用率 | (仅linux)展示服务器一段时间的inode使用率, |
| 当磁盘还未存满,但inode已经分配完时会出现无法在磁盘新建文件的情况 | |
| 最大文件打开数/应用文件打开数 | 启动应用的用户会有最大文件打开数的限制,当前应用文件打开数接近最大文件打开数时,可能会导致后续的访问出现报错,需要修改启动用户的最大文件打开数限制 |
| 网络上行/下行速率 | 展示服务器一段时间内的每秒网络上行/下行速率,用于判断服务器网络的压力情况 |
| TCP连接数 | 各种状态下的TCP连接数包括LISTEN、SYN_SENT、ESTABLISHED、SYN_RECV、FIN_WAIT1、CLOSE_WAIT、FIN_WAIT2、LAST_ACK、TIME_WAIT、CLOSING、CLOSED |
5.3 应用监控
应用监控仪表盘用于监控帆软应用的运行情况,不同于主仪表盘,应用监控仪表盘可以针对单个节点的运行状态的详细数据进行查询。
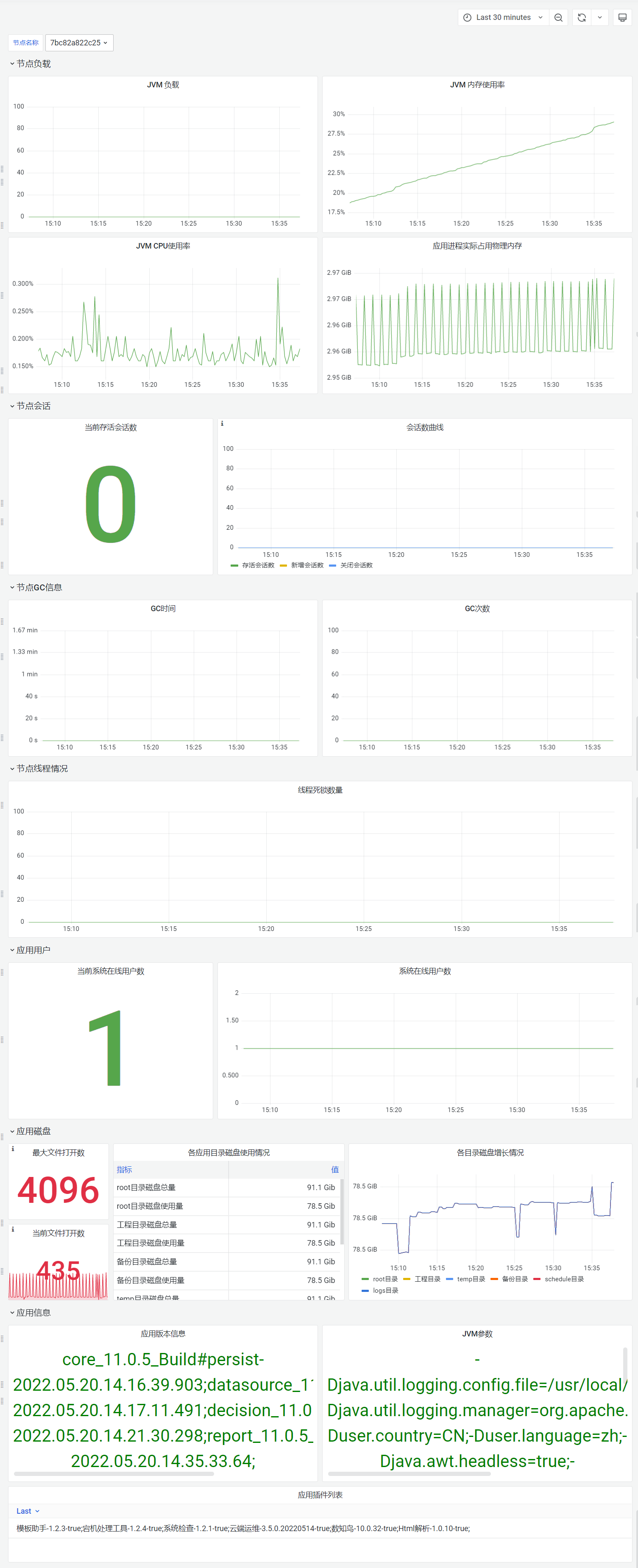
仪表板指标具体说明如下表所示:
| 指标 | 具体说明 |
|---|---|
| JVM负载 | JVM的负载变化情况,负载是帆软根据gc信息计算得出的应用压力量化方式,相比内存能够更真实的反映应用的压力情况,负载过高说明应用压力大 |
| JVM内存使用率 | JVM的内存使用率变化情况,反映应用的客观内存占用情况,可能包含可被gc回收的内存占用 |
| JVMCPU使用率 | JVM的CPU使用率变化情况,反映应用的CPU占用情况 |
| 应用进程实际占用物理内存 | 应用进程实际占用系统物理内存的情况 |
| 节点会话情况 | 当前存活会话数,以及存活会话、新增会话和关闭会话数的变化曲线,可以用于了解应用的并发峰值情况 |
| 节点GC信息 | 节点的GC时间和GC次数,反应gc的负荷和应用的吞吐量,gc时间越长,应用吞吐量越小 |
| 节点线程死锁情况 | 如果节点出现线程死锁,可能会出现宕机等使用异常,需要关注并排查故障 |
| 用户情况 | 当前在线用户数和在线用户曲线,可以用于判断系统最大在线用户数 |
| 最大文件打开数/应用文件打开数 | 启动应用的用户会有最大文件打开数的限制,当前应用文件打开数接近最大文件打开数时,可能会导致后续的访问出现报错,需要修改启动用户的最大文件打开数限制(集群时会根据节点情况显示多个值) |
| 各应用目录磁盘使用情况 | 展示应用相关的root目录、工程目录、备份目录、temp目录、schedule目录和logs目录所在的磁盘空间使用情况,以及各个目录所在磁盘大小的增长情况,如果剩余空间不足10GB可能会影响应用的正常运行甚至宕机,需要尽快进行磁盘清理或扩容 |
| 应用信息 | 包括启动应用的系统用户、应用版本信息、应用的插件列表以及JVM的参数信息,便于进行问题的排查定位 |
5.4 外接数据库监控
外接数据库监控主要用来监控外接数据库的压力情况,避免因为外接数据库的不稳定而影响帆软系统的正常使用。
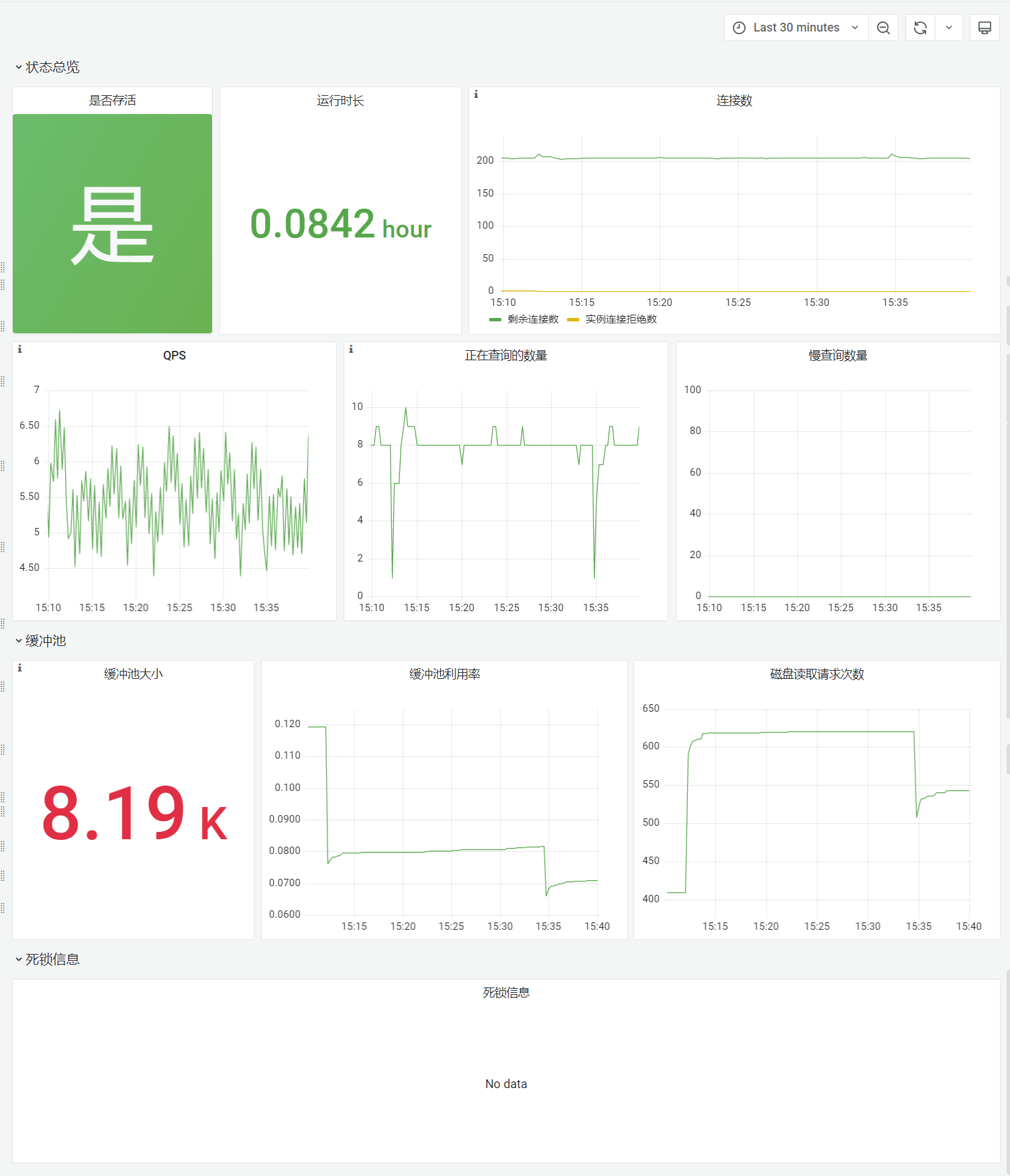
仪表板指标具体说明如下表所示:
| 指标 | 具体说明 |
|---|---|
| 数据库存活状况 | 包括mysql是否存活以及mysql的上次启动时间距离当前的市场 |
| 连接数 | 展示mysql的剩余连接数和实例拒绝连接数,如果剩余连接数不足可能会出现应用访问异常 |
| QPS | 展示mysql每秒处理的请求数量,用来判断mysql的压力情况 |
| 正在查询的数量 | 展示mysql正在查询的语句数量,持续增长可能说明mysql超负荷 |
| 慢查询数量 | 展示mysql的慢查询数量,如果慢查询数量持续增长可能影响mysql的性能及可用性,需要关注具体慢查询的情况 |
| 缓冲池 | 展示缓冲池大小、缓冲池利用率和磁盘读取请求次数,内存允许的情况下缓冲池越大性能越好,磁盘读取请求次数持续增长可能出现mysql性能差,磁盘io压力大等问题 |
| 死锁信息 | 展示数据库的死锁信息: ts:检测到死锁的时间戳 thread:产生死锁的线程id,这个id和show processlist里面的线程id是一致的 txn_id:innodb的事务ID txd_time:死锁检查到前,事务执行时间 user:执行transcation的用户名 db:发生死锁的DB名 tbl:死锁发生的表名 idx:产生死锁的索引名(在上面这个demo里面, 我们直接走的主键,加的记录锁) lock_type:锁的类型(记录锁,gap锁,next-key锁) lock_mode:锁模式(S,X) wait_hold:是否等着锁释放,一般死锁都是两个wait victim:该会话是否做了牺牲,终止了执行 query:造成死锁的SQL语句 |
5.5 Redis监控
Redis监控仪表盘用于监控帆软系统使用的Redis状态服务器的运行情况。
仪表板指标具体说明如下表所示:
| 指标 | 具体说明 |
|---|---|
| redis是否存活 | redis的存活状态 |
| 运行时长 | redis本次启动后的持续运行时长 |
| Redis信息 | 包括redis的版本,是单机还是集群,集群的节点情况等等,方便快速了解redis的环境信息帮助定位和排查 |
| redis的内存情况 | redis分配的内存和使用情况,通常来说redis内存占用比较小,如果出现内存使用率很高,那么可能存在异常 |
| redis的内存碎片率 | 内存碎片率表示「Redis向操作系统中申请的内存」 与「分配器分配的内存总量」的比值 指数>1表明有内存碎片,越大表明越多,<1表明正在使用虚拟内存,虚拟内存其实就是硬盘,性能比内存低得多,这是应该增强机器的内存以提高性能。 大于1.5表示,系统分配的内存大于Redis实际使用的内存,Redis没有把这部分内存返还给系统,产生了很多内存碎片。在Redis 4.0版以前,只能通过安全重启解决这个问题。Redis 4.0及以上版本可以支持内存自动清理。 小于1表示,系统分配的内存小于Redis实际使用的内存,而Redis很有可能在使用Swap了!使用swap是相当影响性能的。 |
| 客户端连接个数 | 用于查看当前redis的客户端连接个数,默认的客户端连接数最大限制为10000,如果连接数过高,会影响redis吞吐量。>5000 时通常就需要进行告警 |
| redis每秒执行的命令数 | 展示一段时间内redis每秒执行命令数的曲线 |
| 每秒查找数据库键成功/失败的次数 | 展示每秒查找数据库的hit/miss的次数,用于参考根据业务需求调优Redis配置 |
| 过期/未过期数据库键数 | 展示redis中过期/未过期数据库键数,用于参考根据业务需求调优Redis配置 |
5.6 Nginx监控
Nginx监控仪表盘用于监控帆软系统使用的Nginx服务器的运行情况,重点关注的是请求情况
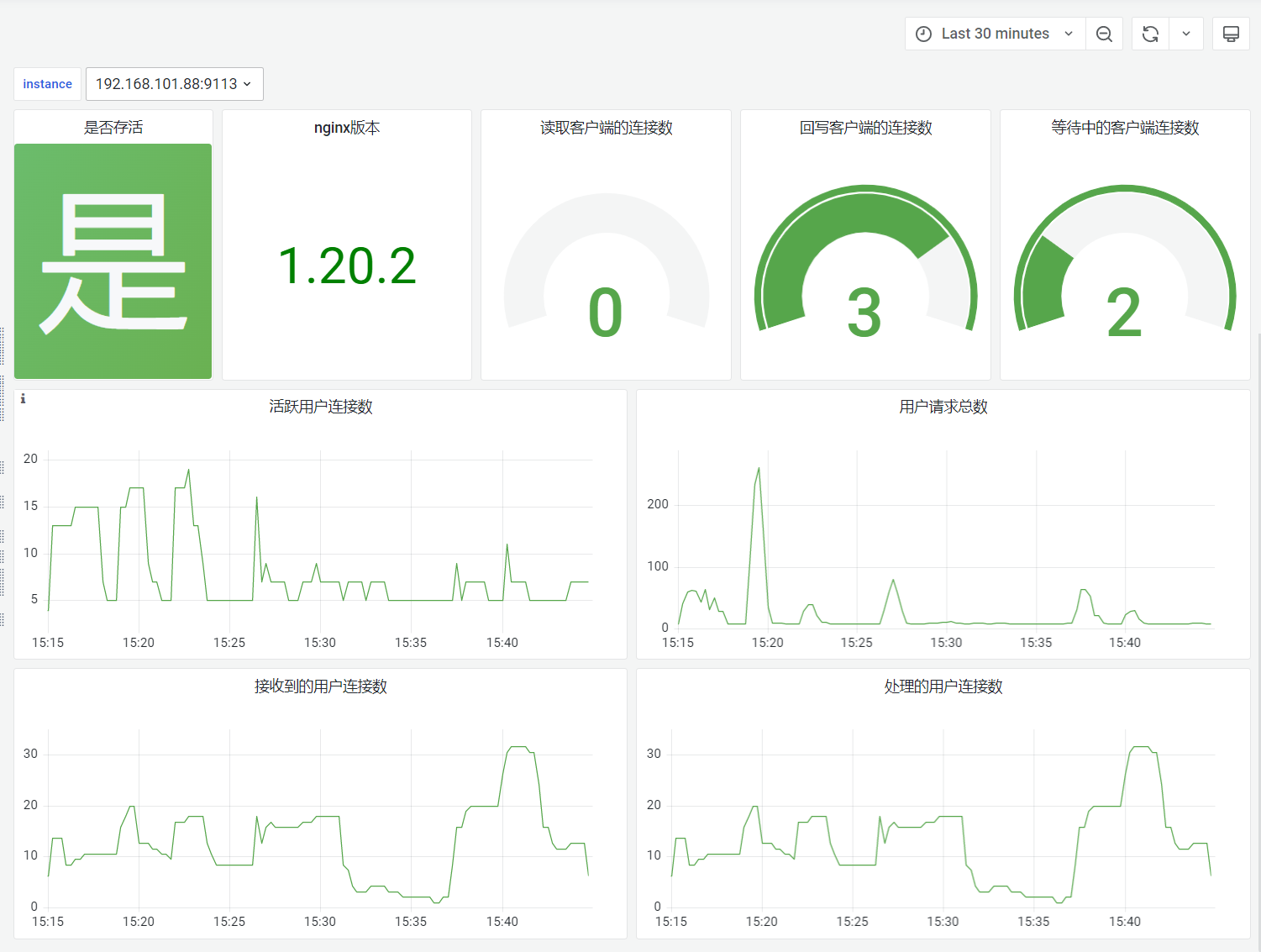
仪表板指标具体说明如下表所示:
| 指标 | 具体说明 |
|---|---|
| Nginx是否存活 | Nginx的存活状态 |
| Nginx版本信息 | Nginx的版本信息,便于排查问题 |
| 各种状态的当前客户端连接数 | 展示当前读取、回写和等待中的客户端连接数 |
| 活跃用户连接数 | 展示一段时间内活跃的用户连接数变化的情况 |
| 用户请求总数 | 展示一段时间内的用户请求总数变化情况 |
| 接收到/处理的用户连接数 | 展示一段时间内接收到/处理的用户连接数变化情况 |
6. 告警配置编辑
当前版本暂不支持自定义告警规则,系统直接内置了三个告警规则
当前版本支持两种告警方式:邮箱以及webhook。
6.1 告警规则
目前不支持用户自定义告警规则,运维平台内置了三个规则,触发告警规则后会根据配置的告警方式提醒对应责任人。
1)规则1:应用高负载告警
判断逻辑:应用负载分高于100/120或连续两次获取指标失败时进行告警
2)规则2:应用宕机告警
判断逻辑:应用连续三次负载分高于100/120或连续2分钟获取指标失败时进行告警
3)规则3:磁盘空间不足告警
判断逻辑:各目录磁盘剩余空间不足10G且总磁盘空间能够正常获取时进行告警
6.2 邮箱告警
如需使用邮箱告警,需配置发件人和收件人。
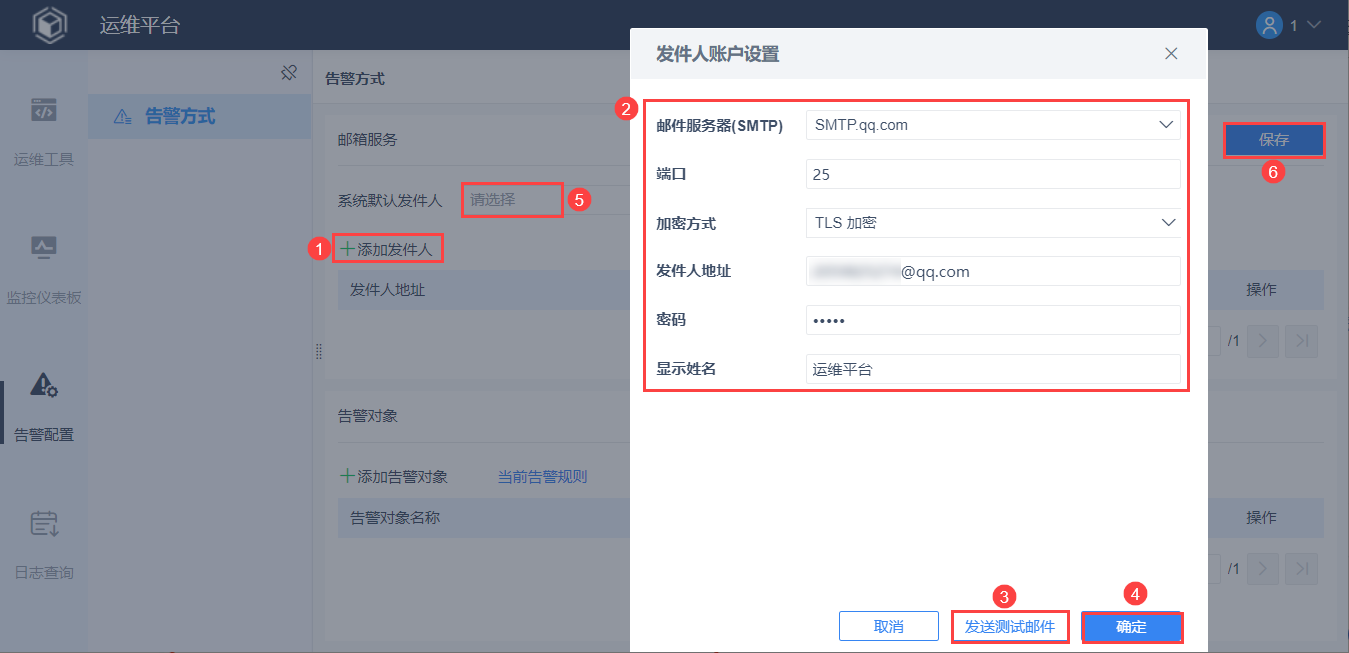
1)配置发件人
发邮件,需要有一个发件人,否则发送动作无法完成。
管理员点击「添加发件人」,配置发件人账户,点击「确定」,设置「系统默认发件人」,点击「保存」。如下图所示:
注1:发件人邮箱类型不同,配置步骤可能不完全相同,具体请参见:邮箱。
注2:配置完成后,请点击「发送测试邮件」,确保邮箱可使用。
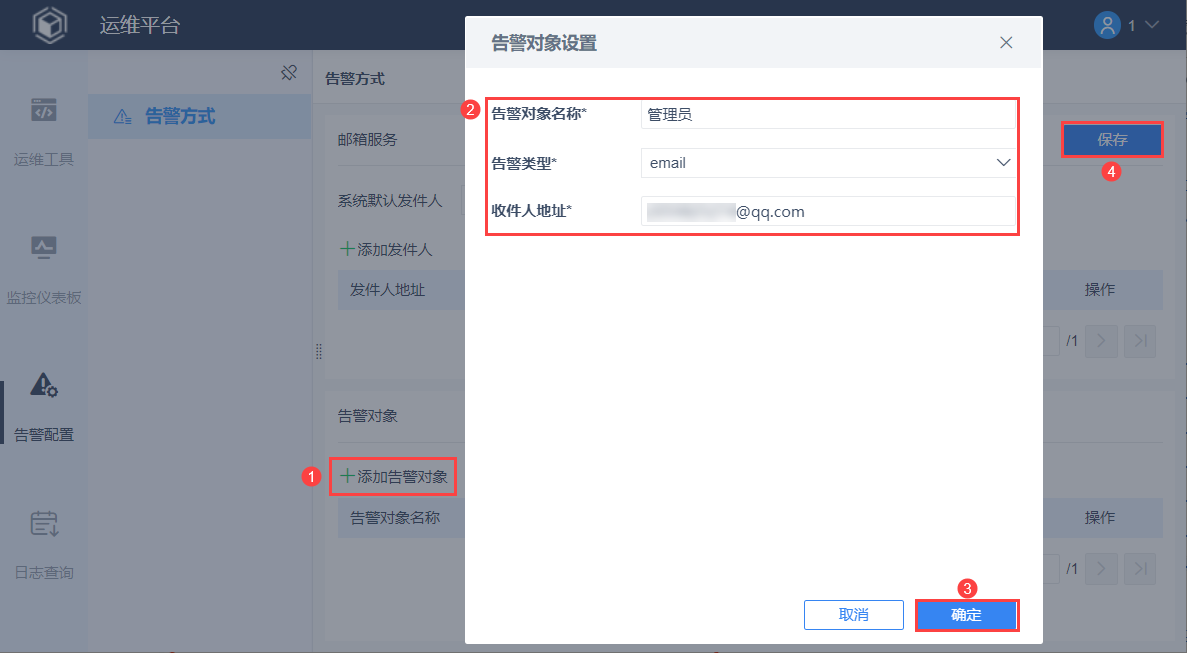
2)配置告警收件人
发邮件,需要配置收件人,接受告警信息。
管理员点击「添加告警对象」,设置告警类型为「email」,设置告警对象名称和收件人地址,点击「确定」,点击「保存」。如下图所示:
6.3 webhook告警
管理员也可以提供一个Webhook 的url,当有新数据的告警消息时,运维平台会往这个 url 发数据,提醒用户告警。
管理员点击「添加告警对象」,设置告警类型为「webhook」,设置告警对象名称和 Webhook 的相关接口信息,点击「确定」,点击「保存」。如下图所示:
注:若 Webhook 的接口存在验证,需要配置用户名及密码。

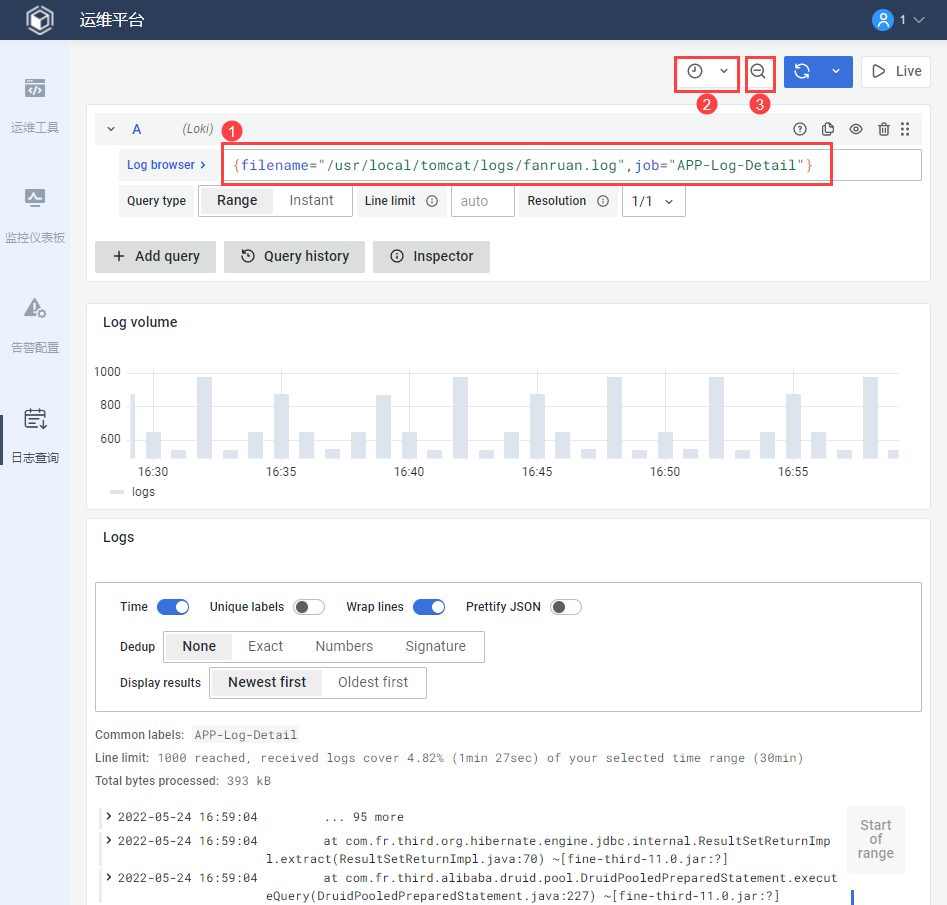
7. 日志查询编辑
运维平台提供「日志查询」功能。
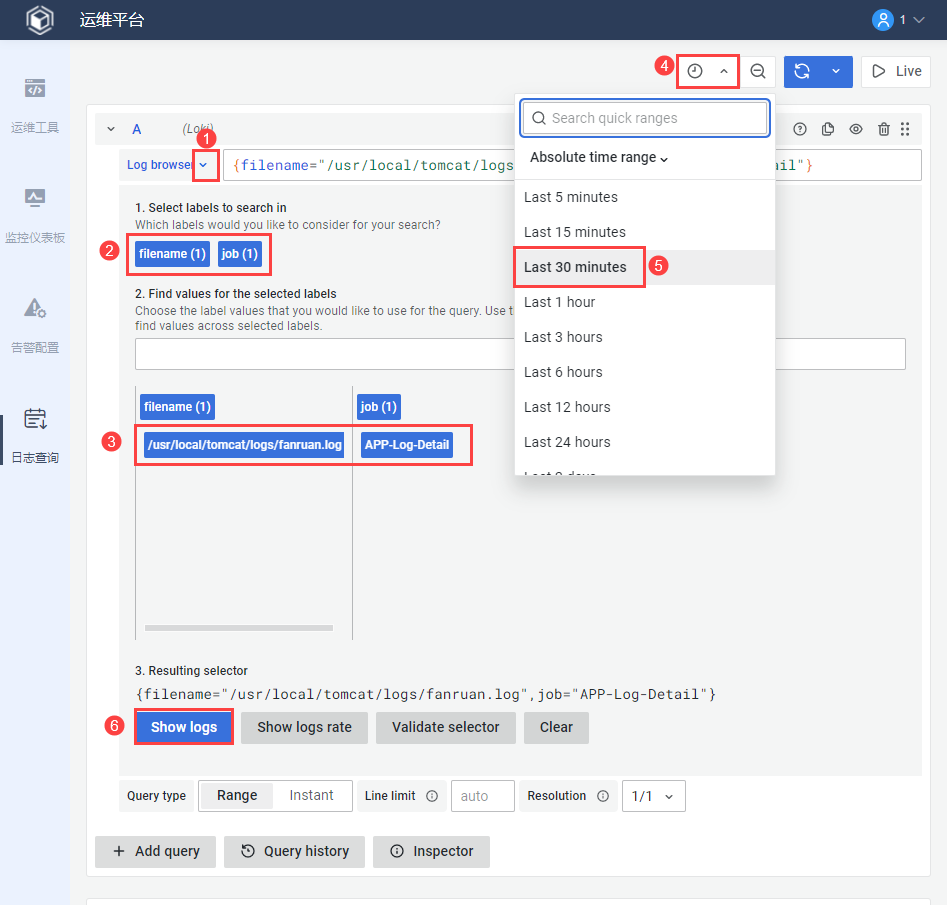
7.1 直接查询
支持直接查询应用日志,可以选择指定日志对象,查询时间范围内的日志详情。
7.2 语法查询
如需进行关键字筛选,可直接输入语法,选择时间范围,即可精细化语法查询
示例语法:{filename="/usr/local/tomcat/logs/fanruan.log",job="APP-Log-Detail"}|="error"
语法解释:
查询/usr/local/tomcat/logs/fanruan.log日志
job是"APP-Log-Detail"
「|="error"」表示查询关键字包含error的日志