

目錄:
1. 概述编辑
1.1 版本
| FineDataLink 版本 | 功能變動 |
|---|---|
| 4.0.9 |
1.2 應用場景
對於 API、WebService、OData API中回應資料傳回的 XML 格式資料、來自 XML 檔案的資料,使用者想要將其解析為行列格式資料,以供後續加工儲存。
1.3 功能簡介
FineDataLink 支援在「資料轉換」中使用「XML解析」算子將 XML 格式資料解析為行列格式資料,以供後續加工儲存。

2. 功能說明编辑
「XML解析」算子配置介面如下圖所示:
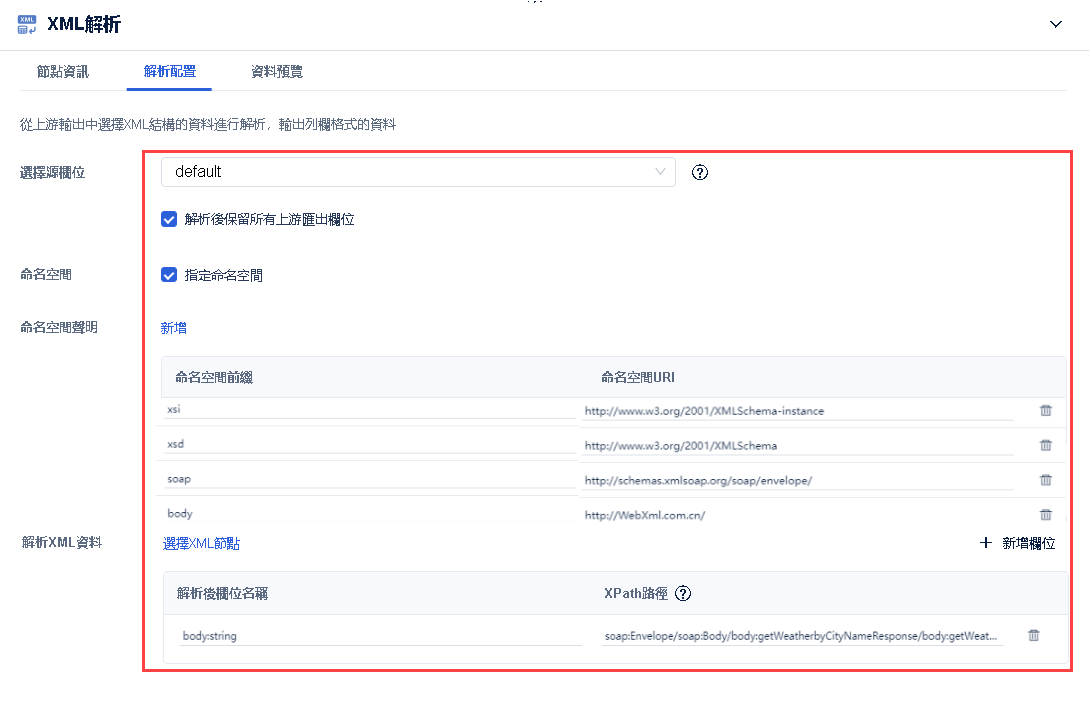
2.1 選擇源欄位
下拉列表內容為所有前置欄位名。
上游節點為 API 輸入且資料未展開為二維表時,源欄位預設為 default。
解析後保留所有上游匯出欄位:勾選後,將所有上游匯出欄位與解析產生的新欄位合併匯出。
2.2 命名空間
若 XML 中帶有命名空間,需要指定命名空間才能正確讀取到節點。
勾選「指定命名空間」後,展示命名空間列表;允許新增和刪除命名空間。
| 欄位名 | 說明 |
|---|---|
| 命名空間前綴 | 可編輯;不允許重名;對於實際 XML 中命名前綴相同的情況,請正確填寫 URI ,並將前綴命名成不同的兩個值,這樣程式可正常解析 |
| 命名空間URL | 可編輯;允許重複 |
當 XML 中存在預設命名空間時,需要手動寫一個自訂的命名空間前綴,填入「命名空間URL」後,才能正常解析。
範例:命名空間URL為http://111111,由於沒有「命名空間前綴」,需要自訂一個「命名空間前綴」例如 xlms,然後「命名空間URL」填寫http://111111,才能正常解析。
2.3 解析 XML 資料
2.3.1 選擇 XML 節點
點選「選擇XML節點」按鈕後,彈出XML節點選擇框。
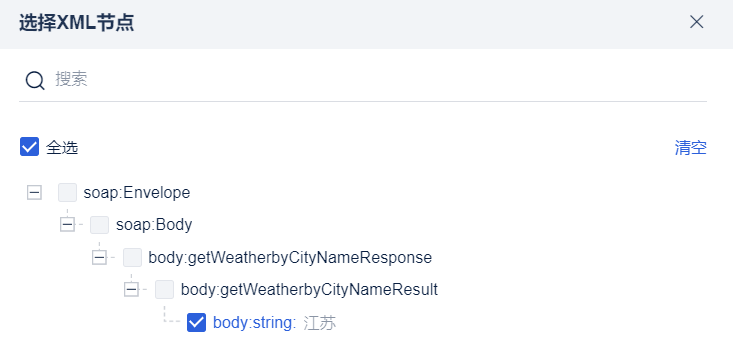
| XML 範例 | 多選樹內容 |
|---|---|
 | 末端節點定義:沒有子節點 所以黃色欄位為末端節點,剩下的欄位為非末端節點
非末端節點不允許被選中 勾選多個同名不同父的節點時,選擇生成的匯出欄位名稱後補1 比如選擇上例中/bookstore/store/title和/bookstore/book/title,此時選擇後匯出欄位的「解析後欄位名稱」為 title 和 title1,XPath 路徑為各自有效路徑 |

2.3.2 匯出欄位
列表項允許新增,允許刪除。
經過 XML 解析產生的欄位類型統一為字串(從上游帶來的欄位類型不變)。
| 欄位名 | 說明 |
|---|---|
| 解析後欄位名稱 | 可編輯;配置解析後的欄位名稱 注1:欄位名稱不允許重名 注2:不允許引用參數 |
| XPath 路徑 | 可編輯;展示&配置解析後欄位的 XPath 路徑運算式 不允許引用參數 允許手寫 XPath 路徑 |
手寫 XPath 支援的類型:「選取節點」類和「謂語」類
例如 XML 文檔如下:
選取節點
XPath 使用路徑運算式在 XML 文檔中選取節點。節點是透過沿着路徑或者 step 來選取的。
在下面的表格中,我們已列出了一些路徑運算式以及運算式的結果:
| 路徑運算式 | 結果 |
|---|---|
| bookstore | 選取 bookstore 元素的所有子節點。 |
| /bookstore | 選取根元素 bookstore。 注:假如路徑起始於正斜槓( / ),則此路徑始終代表到某元素的絕對路徑。 |
| bookstore/book | 選取屬於 bookstore 的子元素的所有 book 元素。 |
| //book | 選取所有 book 子元素,而不管它們在文檔中的位置。 |
| bookstore//book | 選擇屬於 bookstore 元素的後代的所有 book 元素,而不管它們位於 bookstore 之下的什麼位置。 |
| //@lang | 選取名為 lang 的所有屬性。 |
謂語
謂語用來尋找某個特定的節點或者包含某個指定的值的節點。
謂語被嵌在方括號中。
在下面的表格中,我們列出了帶有謂語的一些路徑運算式,以及運算式的結果:
| 路徑運算式 | 結果 |
|---|---|
| /bookstore/book[1] | 選取屬於 bookstore 子元素的第一個 book 元素 |
| /bookstore/book[last()] | 選取屬於 bookstore 子元素的最後一個 book 元素 |
| /bookstore/book[last()-1] | 選取屬於 bookstore 子元素的倒數第二個 book 元素 |
| /bookstore/book[position()<3] | 選取最前面的兩個屬於 bookstore 元素的子元素的 book 元素 |
| //title[@lang] | 選取所有擁有名為 lang 的屬性的 title 元素 |
| //title[@lang='eng'] | 選取所有 title 元素,且這些元素擁有值為 eng 的 lang 屬性 |
| /bookstore/book[price>35.00] | 選取 bookstore 元素的所有 book 元素,且其中的 price 元素的值須大於 35.00 |
| /bookstore/book[price>35.00]/title | 選取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值須大於 35.00 |
3. 特殊場景處理策略编辑
| 場景 | 處理策略 |
|---|---|
源XML資料存在多個根元素,舉例:
| 點選「選擇XML節點」時報錯:XML資料根節點缺失 自行寫XPath,預覽及運作時報錯:XML資料根節點缺失 |
| 配置的XPath不正確 | 解析出的欄位內容為空 |
配置的XPath非法 或者 命名空間前綴中填寫了非英文字母的字元 | 丟擲解析異常 |
命名空間前綴重複
| 命名空間前綴不可重複 此例中,將兩個 s 中的一個重新命名為其他名稱,並正常填寫對應 URI ,透過樹選的形式可正常解析 如果是手填路徑,需要按照重新命名後的命名空間前綴書寫路徑 |
源XML資料不完整,舉例:
| 點選選擇XML節點時報錯:XML資料格式不完整 自行寫XPath,預覽及運作時報錯:XML資料格式不完整 |



4. 範例编辑
「XML解析」算子使用範例請參見:XML解析示例