

1. 概述编辑
1.1 版本
| FineDataLink 版本 | 功能变动 |
|---|---|
| 1.9 | - |
| 4.2.10.3 | 新增「调用检测任务」节点 |
| 查看历史版本更新 | ||||||||||||||||||
|
1.2 功能简介
「定时任务」模块支持在可视化界面使用各个节点和算子进行数据的抽取、转换和装载,并可以通过定时调度功能自动运行定时任务,帮助您轻松构建离线数仓,保证数据生产的高效稳定。
注:定时任务部分相关概念说明详情参见:定时任务概念


基本特性说明如下表所示:
| 能力 | 说明 |
|---|---|
| 单表定时同步 | 任务调度专题 |
| 源表的全量/增量/变化数据同步到目标表中 | 数据同步方案概述 |
| 数据处理能力 | 可使用节点、算子对数据进行清洗;支持对数据进行复杂处理或计算 支持处理 多种数据源的数据,支持获取存储过程数据并进行处理 支持调用检测任务,对目标表数据进行质量检测,若检测不通过,通知给指定负责人 |
| 来源端表结构发生变化 | 能够提示来源端数据表的 DDL 变化,并且将变化通知给指定用户,用户需手动进行任务调整 |
2. 功能说明编辑
2.1 定时任务主要功能
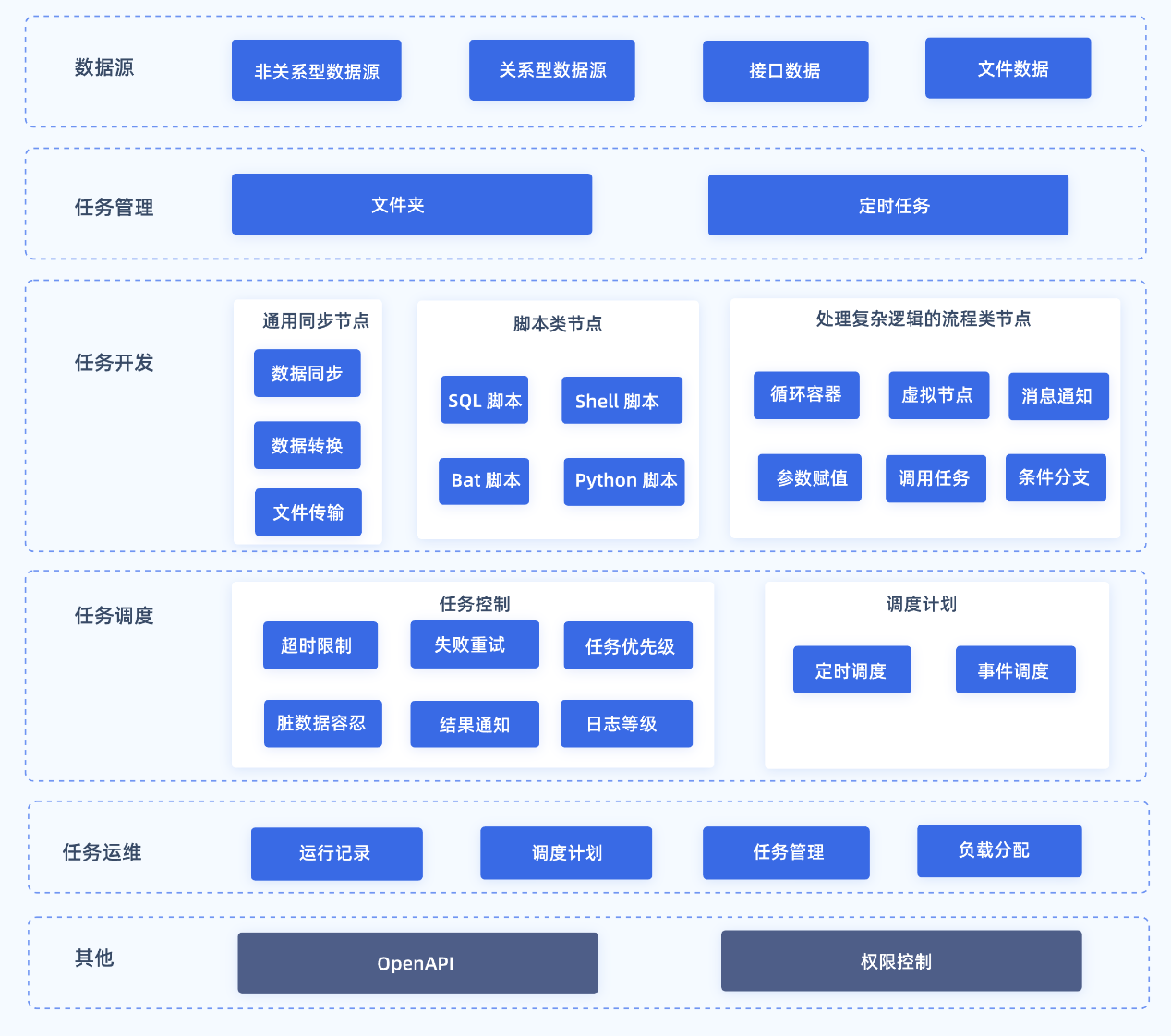
注:4.1.7.3 及之后版本,定时任务支持开发模式和生产模式,实现代码的隔离;开发模式的任务可一键发布上线,将任务发布为生产模式。详情请参见:开发模式与生产模式
| 类型 | 描述 |
|---|---|
| 数据源 | FineDataLink 数据开发>定时任务模块支持多种数据源,可以将多种来源数据进行数据处理和集成 详情请参见:定时任务支持的数据源 |
| 任务管理 | 定时任务中通过「定时任务」存放设计好的业务流程 通过「文件夹」对定时任务进行管理 |
| 任务开发 | 能力丰富:
操作简单:
体验完善: |
| 任务调度 | 任务控制: 支持设置任务超时限制;是否失败重跑 支持设置调度任务优先级;支持设置任务脏数据容忍情况;支持任务结果通知;支持设置任务日志等级 调度计划: 支持设置调度任务的开始日期、执行频率。 支持设置任务的调度依赖,例如设置任务 A、任务 B 执行成功后再执行任务 C 详细说明: |
| 任务运维 | 支持灵活调度、运行状态实时监控,便捷的操作将会释放运维人员巨大的工作量 详细介绍请参见:运维中心概述 |
| 其他 |
|
2.2 节点介绍
FineDataLink 数据开发>定时任务模块提供多种类型的节点,多种节点配合使用,满足您不同的数据处理需求。
节点是组成定时任务的基本单位,多个节点通过线条连接后可确定执行流程,进而组成一个完整的定时任务。FineDataLink 目前有如下节点:
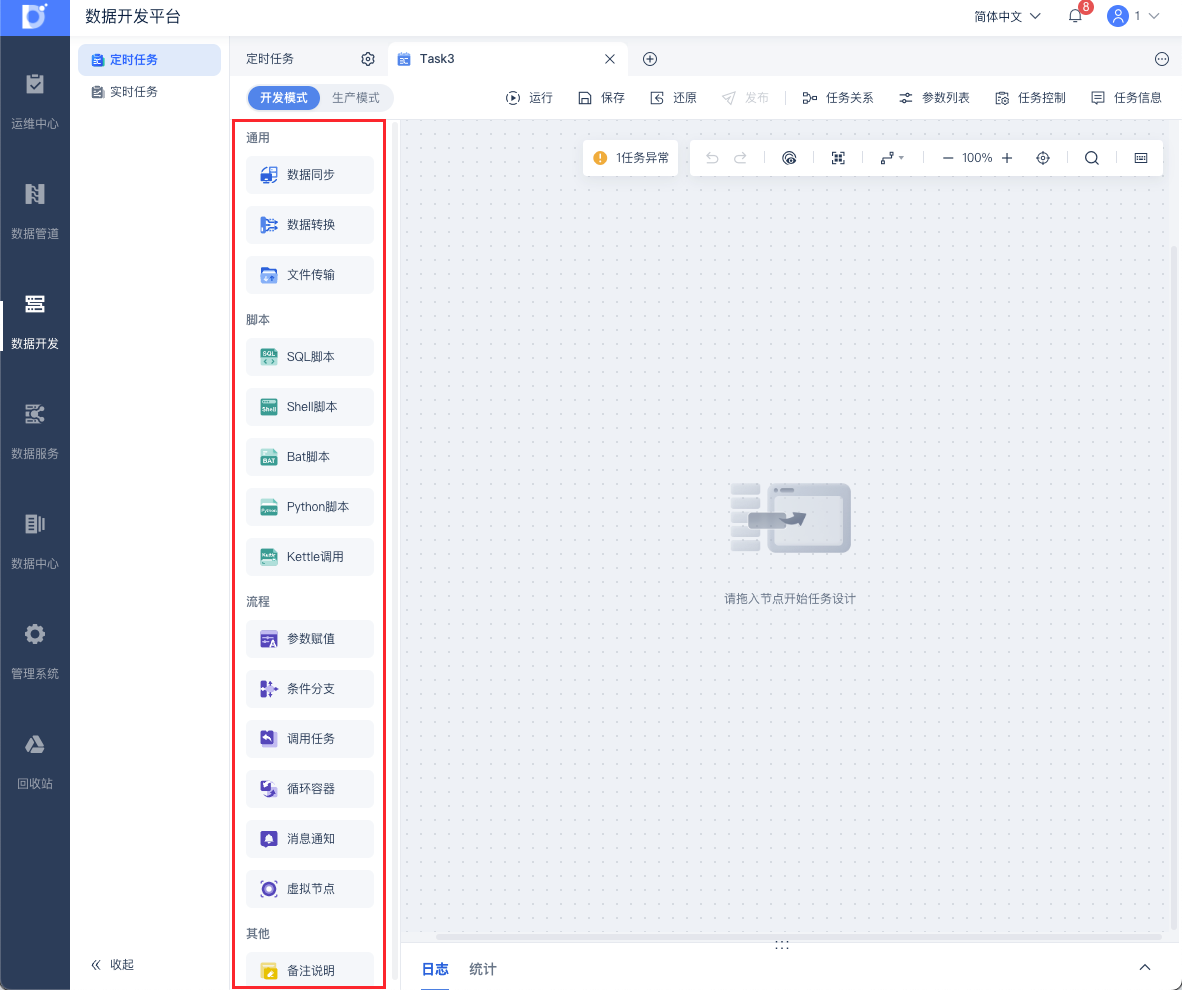
| 分类 | 说明 | 节点名称 | 应用场景 |
|---|---|---|---|
| 通用 | 用于数据同步 | 数据同步 | 将数据从一个数据库抽取到另一个数据库 |
| 用于复杂数据清洗计算 | 数据转换 | 可执行数据关联、同步删除数据等操作 | |
| 多种类型的下载/上传文件 | 文件传输功能说明 | 在API接口/本地/SFTP/FTP之间进行文件下载/上传,实现文件移动 注:仅对文件流本身做同步,而非取文件内容数据。 | |
| 数据同步与数据转换的区别请参见:数据同步与数据转换的区别 | |||
| 脚本 | 通过控制脚本语法实现数据处理 | SQL脚本 | 写 SQL 语句对数据库中的数据进行处理 |
| Shell脚本 | 通过执行 shell 脚本,对接外部的独立数据处理过程,例如调用Kettle任务、调用Python计算任务等 | ||
| Python脚本 | 支持直接调用 Python 脚本 | ||
| Bat 脚本 | 支持调用远程 Windows 环境中的 Bat 脚本文件 | ||
| Kettle调用 | 使用SSH连接,调用指定路径下的 kettle 任务 | ||
| 流程 | 进行复杂逻辑处理的流程节点 | 参数赋值 | 用参数承载上游节点运行的结果,然后在下游节点中使用该结果 |
| 条件分支 | 基于一个来自于上游或者系统的条件,判断是否继续运行下游节点或者运行下游节点里面的哪一个 | ||
| 虚拟节点 | 希望多个节点可以并行运行后再转到下游节点,可借助该节点实现 | ||
| 调用定时任务 | 可以在当前任务中调用其他任务,这样可以直接设置任务间执行的依赖关系,实现跨任务编排 | ||
| 调用检测任务 | 可在定时任务中调用 数据检测任务 | ||
| 消息通知 | 可将任务调度结果以企业微信群机器人/邮件/钉钉/短信的形式通知给指定用户 | ||
| 循环容器 | 可满足循环取数的场景 | ||
| 其他 | 任务备注说明 | ETL任务和节点添加备注 | 需要为节点或任务添加备注,例如在任务中备注该任务的具体使用场景。 |
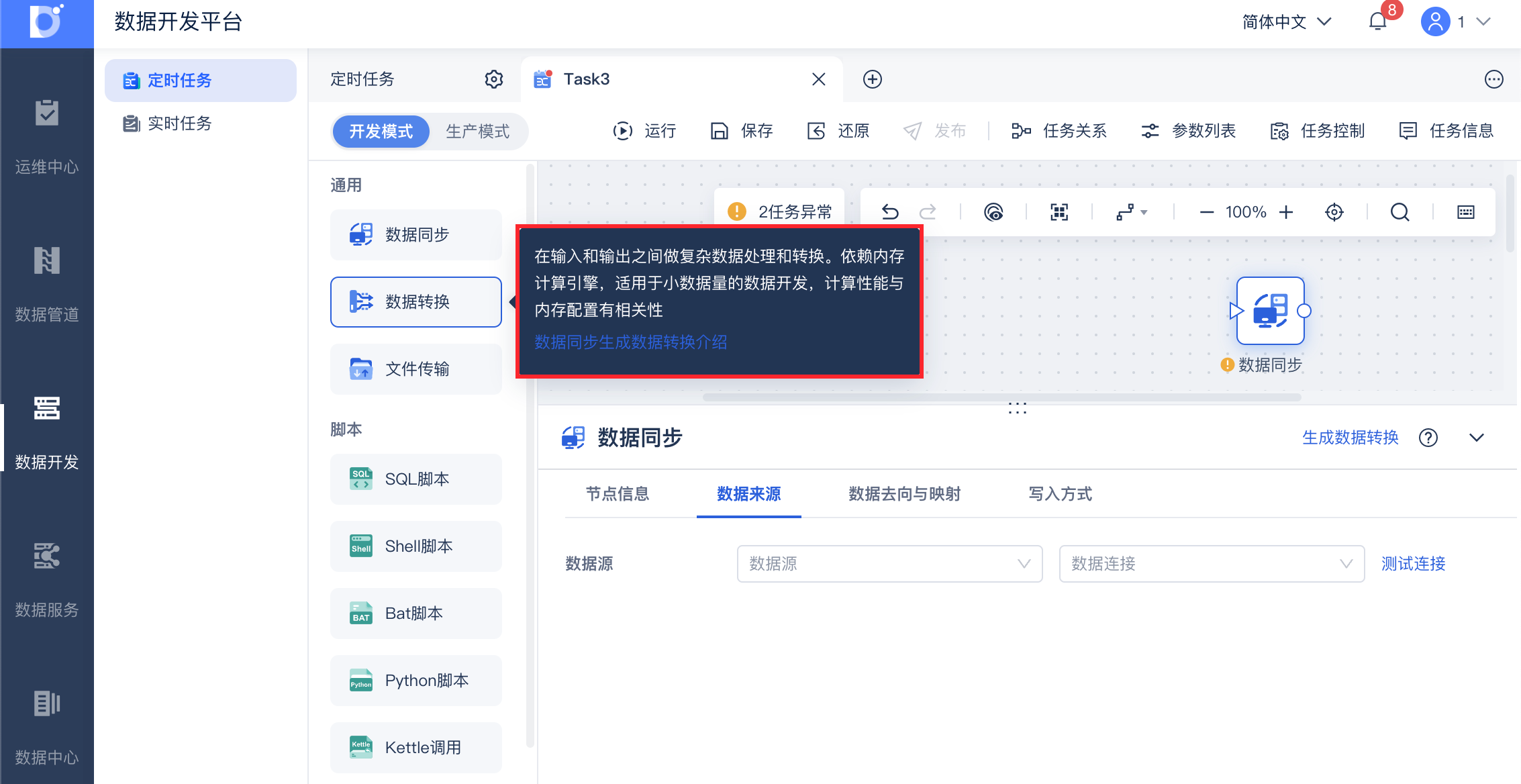
鼠标悬浮至节点列表,会出现节点的用法解释,用户可快速查看当前节点任务用法。如下图所示:
2.3 操作流程
一个定时任务的开发和使用流程如下图所示:

| 顺序 | 说明 | 文档 |
|---|---|---|
| 1 | 配置定时任务设计时,数据读取和数据写入的数据源 | [通用]配置数据连接 |
| 2 | 创建定时任务,并进行定时任务的开发 | 参考各节点功能文档 |
| 3 | 通过手动执行任务,根据任务运行日志进行任务调试 | |
| 4 | 发布任务 | 开发模式与生产模式 |
| 5 | 设置定时任务调度执行情况 | |
| 6 | 对已经设置的定时任务进行任务管理和资源控制 |
3. 内容扩展编辑
| 分类 | 说明 | 参考文档 |
|---|---|---|
| 设计任务前需知 | 了解定时任务模块能做什么 | 定时任务能力说明 |
| 了解 FDL 中可使用的快捷键 | FineDatalink快捷键介绍 | |
| 定时任务采样量与写入量说明 | |
| 设计任务时需知 | 根据实际场景,选择数据同步方案 | 数据同步方案概述 |
| 定时任务支持读取、创建、写入分区表 | 读取、创建、写入分区表 | |
| 当进行定时任务开发时,能够提示来源端数据表的 DDL 变化,并且将变化通知给指定用户 | 定时任务DDL同步 | |
| 定时任务中,支持调用数据库存储过程 | 定时任务调用数据库存储过程 | |
| 定时任务设计区域中,支持单个/多个节点的复制粘贴 | 节点支持复制粘贴 | |
| 支持在设计定时任务时,为节点或任务添加备注 | 备注 | |
| 用户希望定时任务执行失败后,可以自定义错误处理流程。比如定时任务执行失败后,在企业微信群中通知 | 连线执行判断 | |
| 调试任务需知 | 支持设置节点时,选择运行到此处,便于查看上游配置结果和调试 | 运行至此节点 |
| 4.1.6.3 及之后版本,定时任务禁止被多人同时编辑 | 任务禁止被多人同时编辑 | |
| 支持禁用节点及下游节点 | 节点支持禁用 | |
可视化展示父子任务层级调用关系,用户可查看该定时任务被哪些任务调用,以及该任务调用了哪些任务 可视化展示任务间调度依赖关系,辅助事件调度决策 | 任务关系 | |
| 用户有多名开发人员,为防止自己的定时任务被他人误操作修改,希望能对定时任务进行版本追溯和退回原任务设置,降低工作量返工 | 定时任务版本管理 | |
| 任务运维指导 | 当用户设计好定时任务后,可以管理定时任务、监控任务运行状态和查看任务运行日志等 本文列举定时任务的常见运维操作 | 定时任务运维指导 |
| 其他功能说明 | FineDataLink 支持将定时任务从 A 系统中导出并导入至 B 系统 | 定时任务导入导出 |
FineDataLink 支持在「数据转换」的输入型算子中进行「样本设置」,即在预览界面,设置用多少数据去参与运算,便于进行计算后的预览结果校验。 | 定时任务数据量说明 | |
| 最佳实践 | 多节点、算子配合使用实现复杂场景;API取数最佳实践;与FR、BI、简道云配合使用案例等 | 最佳实践合集 |
4. 注意事项编辑
4.1 SQL 语句注释说明
4.0.17 版本之前,FineDataLink 忽略对 SQL 语句注释的处理;4.0.17 及之后版本,SQL 语句的注释交给数据库执行。
用户需注意 SQL 语句注释的书写规范:单行注释之后要有一个空格;Hive 数据源不支持多行注释。